SPSS Statistics
Interpretatie en rapportage van de output van een binomiale logistische regressie-analyse
SPSS Statistics genereert vele tabellen met output bij het uitvoeren van een binomiale logistische regressie. In deze sectie tonen we u alleen de drie belangrijkste tabellen die nodig zijn om de resultaten van de binomiale logistische regressieprocedure te begrijpen, ervan uitgaande dat er geen aannames zijn geschonden. Een volledige uitleg van de output die u moet interpreteren wanneer u uw gegevens controleert op de aannamen die nodig zijn om binomiale logistische regressie uit te voeren, vindt u in onze uitgebreide handleiding.
In deze “snelstartgids” richten we ons echter alleen op de drie belangrijkste tabellen die u nodig hebt om de resultaten van uw binomiale logistische regressie te begrijpen, ervan uitgaande dat uw gegevens al voldoen aan de aannamen die nodig zijn voor binomiale logistische regressie om u een geldig resultaat te geven:
Verklaarde variantie
Om te begrijpen hoeveel variatie in de afhankelijke variabele door het model kan worden verklaard (het equivalent van R2 in meervoudige regressie), kunt u de onderstaande tabel “Model Summary” raadplegen:
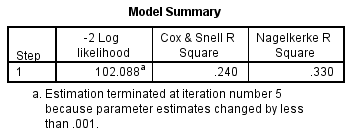
Deze tabel bevat de Cox & Snell R Square- en Nagelkerke R Square-waarden, die beide methoden zijn om de verklaarde variatie te berekenen. Deze waarden worden soms pseudo R2-waarden genoemd (en zullen lagere waarden hebben dan bij meervoudige regressie). Zij worden echter op dezelfde manier geïnterpreteerd, maar met meer voorzichtigheid. De verklaarde variatie in de afhankelijke variabele op basis van ons model varieert dus van 24,0% tot 33,0%, afhankelijk van het feit of u respectievelijk de Cox & Snell R2- of Nagelkerke R2-methode gebruikt. Nagelkerke R2 is een modificatie van Cox & Snell R2, waarvan de laatste geen waarde van 1 kan bereiken. Daarom verdient het de voorkeur de Nagelkerke R2-waarde te rapporteren.
Voorspelling van de categorie
Binomiale logistische regressie schat de waarschijnlijkheid dat een gebeurtenis (in dit geval het hebben van hartaandoeningen) zich voordoet. Als de geschatte waarschijnlijkheid dat de gebeurtenis zich voordoet groter is dan of gelijk is aan 0,5 (beter dan evenveel kans), classificeert SPSS Statistics de gebeurtenis als opgetreden (bijv. hartaandoening aanwezig). Als de waarschijnlijkheid kleiner is dan 0,5, classificeert SPSS Statistics de gebeurtenis als niet voorkomend (bijv. geen hartaandoening). Het is zeer gebruikelijk binomiale logistische regressie te gebruiken om te voorspellen of gevallen correct kunnen worden geclassificeerd (d.w.z. voorspeld) op basis van de onafhankelijke variabelen. Daarom moet er een methode komen om de doeltreffendheid van de voorspelde classificatie te toetsen aan de werkelijke classificatie. Er zijn vele methoden om dit te beoordelen, waarbij het nut vaak afhangt van de aard van de uitgevoerde studie. Alle methoden draaien echter om de waargenomen en voorspelde classificaties, die worden gepresenteerd in de “Classificatietabel”, zoals hieronder weergegeven:
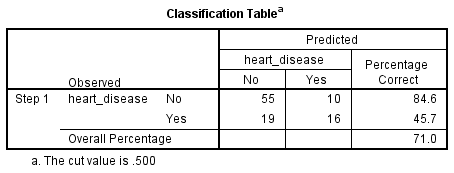
Vooreerst valt op dat de tabel een subscript heeft waarin staat: “De cut value is .500”. Dit betekent dat als de kans dat een geval in de categorie “ja” wordt ingedeeld groter is dan .500, dat geval in de categorie “ja” wordt ingedeeld. Zo niet, dan wordt het geval ingedeeld in de categorie “neen” (zoals eerder vermeld). Hoewel de classificatietabel heel eenvoudig lijkt, geeft hij in feite veel belangrijke informatie over uw binomiale logistische regressieresultaat, waaronder:
- A. De procentuele nauwkeurigheid bij de classificatie (PAC), die het percentage gevallen weergeeft dat correct kan worden geclassificeerd als “geen” hartaandoening met de onafhankelijke variabelen toegevoegd (niet alleen het algemene model).
- B. Gevoeligheid, die het percentage gevallen weergeeft dat het waargenomen kenmerk had (bijv, “ja” voor hartaandoeningen) die correct door het model werden voorspeld (d.w.z. ware positieven).
- C. Specificiteit, d.w.z. het percentage gevallen dat het waargenomen kenmerk niet had (d.w.z. “nee” voor hartaandoeningen) en ook correct werd voorspeld als hebbend het waargenomen kenmerk niet (d.w.z, echte negatieven).
- D. De positieve voorspellende waarde, d.w.z. het percentage correct voorspelde gevallen “met” het waargenomen kenmerk, vergeleken met het totale aantal gevallen waarvan werd voorspeld dat ze het kenmerk hadden.
- E. De negatieve voorspellende waarde, d.w.z. het percentage correct voorspelde gevallen “zonder” het waargenomen kenmerk, vergeleken met het totale aantal gevallen waarvan werd voorspeld dat ze het kenmerk niet hadden.
Als u niet zeker weet hoe u de PAC, sensitiviteit, specificiteit, positief voorspellende waarde en negatief voorspellende waarde uit de “Classificatietabel” moet interpreteren, leggen wij u dat uit in onze uitgebreide binomiale logistische regressiegids.
Variabelen in de vergelijking
De tabel “Variabelen in de vergelijking” toont de bijdrage van elke onafhankelijke variabele aan het model en de statistische significantie ervan. Deze tabel wordt hieronder weergegeven:
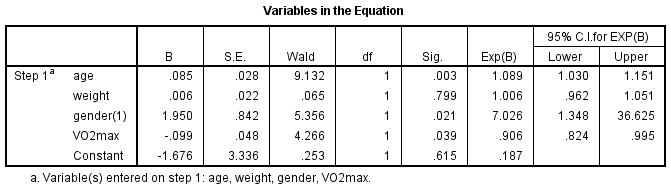
De Wald-test (“Wald”-kolom) wordt gebruikt om de statistische significantie voor elk van de onafhankelijke variabelen te bepalen. De statistische significantie van de test wordt gevonden in de “Sig.”-kolom. Uit deze resultaten kunt u zien dat leeftijd (p = .003), geslacht (p = .021) en VO2max (p = .039) significant aan het model/voorspelling toevoegden, maar dat gewicht (p = .799) niet significant aan het model toevoegde. U kunt de informatie in de tabel “Variabelen in de vergelijking” gebruiken om de kans te voorspellen dat een gebeurtenis zich voordoet op basis van een verandering van één eenheid in een onafhankelijke variabele wanneer alle andere onafhankelijke variabelen constant worden gehouden. Uit de tabel blijkt bijvoorbeeld dat de kans op een hartziekte (“ja”-categorie) 7,026 keer groter is voor mannen dan voor vrouwen. Als u niet zeker weet hoe u odds ratio’s kunt gebruiken om voorspellingen te doen, lees dan over onze uitgebreide gidsen op onze pagina Functies:
Het geheel samenvatten
Op basis van bovenstaande resultaten zouden we de resultaten van het onderzoek als volgt kunnen rapporteren (N.B., dit omvat niet de resultaten van uw aannametests):
- Algemeen
Er werd een logistische regressie uitgevoerd om de effecten van leeftijd, gewicht, geslacht en VO2max op de waarschijnlijkheid dat deelnemers een hartaandoening hebben, vast te stellen. Het logistische regressiemodel was statistisch significant, χ2(4) = 27,402, p < .0005. Het model verklaarde 33,0% (Nagelkerke R2) van de variantie in hartziekten en classificeerde 71,0% van de gevallen correct. Mannen hadden 7,02 keer meer kans op een hartaandoening dan vrouwen. Toenemende leeftijd werd geassocieerd met een verhoogde kans op hartaandoeningen, maar toenemende VO2max werd geassocieerd met een vermindering van de kans op hartaandoeningen.
In aanvulling op de bovenstaande schrijfopdracht moet u ook het volgende opnemen: (a) de resultaten van de veronderstellingstests die je hebt uitgevoerd; (b) de resultaten van de “Classificatietabel”, waaronder sensitiviteit, specificiteit, positief voorspellende waarde en negatief voorspellende waarde; en (c) de resultaten van de tabel “Variabelen in de vergelijking”, waaronder welke van de voorspellende variabelen statistisch significant waren en welke voorspellingen kunnen worden gedaan op basis van het gebruik van odds ratio’s. Als je niet zeker weet hoe je dit moet doen, laten we het je zien in onze uitgebreide binomiale logistische regressiegids. We laten je ook zien hoe je de resultaten van je veronderstellingstests en binomiale logistische regressie-uitvoer opschrijft als je dit moet rapporteren in een proefschrift/thesis, opdracht of onderzoeksverslag. We doen dit volgens de Harvard- en APA-stijlen. U kunt meer te weten komen over onze verbeterde inhoud op onze Functies: Overzicht pagina.