Wanneer zou je deze test moeten gebruiken? (vervolg…)
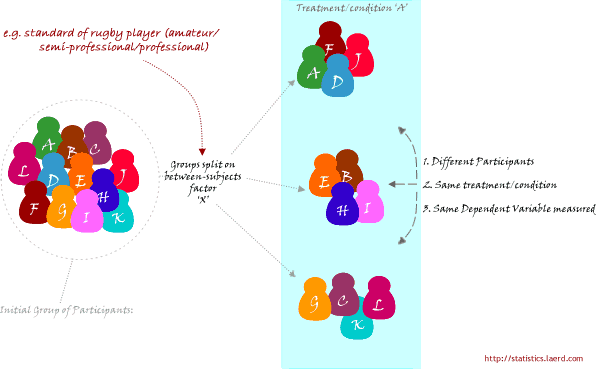
Een tweede onderzoeksopzet bestaat uit het werven van een groep individuen en hen vervolgens in groepen te verdelen op basis van een of andere onafhankelijke variabele. Ook hier wordt elk individu slechts in één groep ingedeeld. Deze onafhankelijke variabele wordt soms een attribuutonafhankelijke variabele genoemd, omdat u de groep verdeelt op basis van een kenmerk dat zij bezitten (b.v. hun opleidingsniveau; elk individu heeft een opleidingsniveau, zelfs als dat “geen” is). Elke groep wordt dan gemeten op dezelfde afhankelijke variabele nadat ze dezelfde taak of conditie (of helemaal geen) hebben ondergaan. Een onderzoeker is bijvoorbeeld geïnteresseerd in de vraag of er verschillen zijn in beenkracht tussen amateur-, semi-professionele en professionele rugbyspelers. De kracht/sterkte gemeten op een isokinetische machine is de afhankelijke variabele. Dit type onderzoeksopzet wordt schematisch weergegeven in onderstaande figuur:
Waarom geen groepen vergelijken met meervoudige t-tests?
Iedere keer dat je een t-test uitvoert, is er een kans dat je een Type I-fout maakt. Deze fout is meestal 5%. Door twee t-tests uit te voeren op dezelfde gegevens heb je de kans dat je “een fout maakt” verhoogd tot 10%. De formule voor het bepalen van de nieuwe foutmarge voor meervoudige t-tests is niet zo eenvoudig als het vermenigvuldigen van 5% met het aantal tests. Als u echter slechts een paar meervoudige vergelijkingen maakt, zijn de resultaten zeer vergelijkbaar als u dat doet. Zo zouden drie t-tests 15% zijn (eigenlijk 14,3%) enzovoort. Dit zijn onaanvaardbare fouten. Een ANOVA controleert voor deze fouten, zodat de Type I-fout op 5% blijft en u er zekerder van kunt zijn dat elk statistisch significant resultaat dat u vindt niet gewoon het uitvoeren van veel tests is. Zie onze gids over hypothesetests voor meer informatie over Type I-fouten.