Categorische variabelen kunnen staan voor de ontwikkeling van een ziekte, een toename van de ernst van een ziekte, sterfte, of een andere variabele die uit twee of meer niveaus bestaat. Om de associatie tussen twee categorische variabelen met R- en C-niveaus samen te vatten, maken we kruistabellen, of RxC-tabellen (“rij “x “kolom” of contingentietabellen), die de waargenomen frequenties van categorische uitkomsten bij verschillende groepen proefpersonen samenvatten. We zullen ons hier concentreren op 2 x 2 tabellen.
In het algemeen vatten 2 x 2 tabellen de frequentie van gezondheidsgerelateerde (of andere) gebeurtenissen onder verschillende groepen samen, zoals hieronder geïllustreerd, waarbij groep 1 patiënten kan voorstellen die een standaardtherapie hebben gekregen, en groep 2 patiënten die een nieuwe experimentele therapie hebben gekregen.
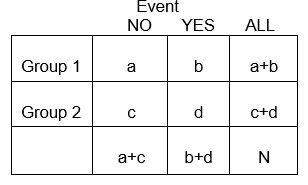
Voorbeeld:
De primaire uitkomstvariabele in de Kawasaki-onderzoeken was de ontwikkeling van kransslagaderafwijkingen (CA), een dichotome variabele. Een van de doelstellingen van de studie was het vergelijken van de waarschijnlijkheid van het ontwikkelen van CA-afwijkingen bij behandeling met aspirine (ASA) of gammaglobuline (GG).

We zouden misschien graag willen weten of de frequentie van kransslagaderafwijkingen tussen deze twee groepen verschilde, d.w.z, werd een van deze groepen geassocieerd met minder afwijkingen. Het antwoord op vragen als deze hangt af van een vergelijking van de frequenties van deze gezondheidsgebeurtenissen in de twee behandelingsgroepen. Afhankelijk van de opzet van de studie kan men ofwel de waarschijnlijkheid van gebeurtenissen vergelijken ofwel de kans dat een gebeurtenis zich voordoet.
Kans en waarschijnlijkheid van het ontwikkelen van CA in elk van de behandelingsarmen
De waarschijnlijkheid wordt berekend als het aantal “ja”-waarden in elke behandelingscategorie gedeeld door het totale aantal in de behandelingscategorie.
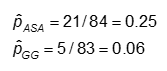
De waarschijnlijkheid is #Ja / #Nee. Hier,
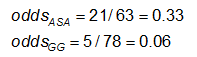
Let er altijd op of de uitkomst in de rijen of in de kolommen staat; het is heel gemakkelijk om deze door elkaar te halen!
Wanneer we naar de associatie tussen een binaire variabele en een continue uitkomst keken, hebben we de associatie samengevat in termen van verschil in gemiddelden. Welke statistiek is geschikt om het verschil tussen twee groepen met betrekking tot de kans op een binaire gebeurtenis weer te geven? Er zijn ten minste drie manieren om de associatie samen te vatten:
Risicoverschil RD = p1 – p2
Relatief Risico (Risico Ratio) RR = p1 / p2
Odds Ratio OR = odds1/ odds2 = /
De studieopzet bepaalt welke van deze effectmaten geschikt is. In een case/control-studie kan het relatieve risico niet worden beoordeeld en is de odds ratio (OR) de geschikte maat. De OR geeft echter een goede schatting van het relatieve risico voor zeldzame voorvallen (d.w.z. als p klein is, meestal 0,10 of kleiner).
Cross-sectionele studies beoordelen de prevalentie van gezondheidsmaatregelen, zodat de odds ratio geschikt is. Bij prospectieve cohortstudies is ofwel een rate ratio ofwel een risk ratio geschikt, hoewel ook een odds ratio kan worden berekend.
Voor een meer gedetailleerd overzicht van effectmaten, zie de online epidemiologiemodule over “Associatiematen”.
Voorbeeld: Gebruikmakend van de eerdere gegevens over CA-afwijkingen, zijn de effectmaten voor degenen die ASA (aspirine) gebruiken versus gammaglobuline (GG) als volgt:
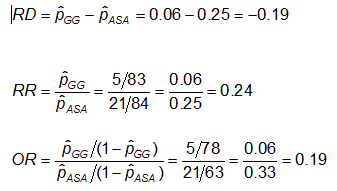

Uitleg: Beschouw de maatstaven voor het effect in het vorige voorbeeld. Waarom zijn de risico-ratio en de odds ratio zo verschillend (de RR suggereert dat, in vergelijking met de groep die alleen met ASA werd behandeld, het risico op coronaire afwijkingen 1/4 zo hoog is voor degenen die met GG werden behandeld; terwijl de OR suggereert dat het risico 1/5 zo hoog is)?
Alternatieve manieren om de nulhypothese uit te drukken
Voor een 2×2-tabel kan de nulhypothese ook worden geschreven in termen van de waarschijnlijkheden zelf, of het risicoverschil, het relatieve risico, of de odds ratio. In elk geval stelt de nulhypothese dat er geen verschil is tussen de twee groepen.
H0: p1 = p2
H1: p1 ≠ p2
H0: p1 – p2 = 0 (RD=0)
H1: RD ≠ 0
H0: p1/ p2 = 1 (RR=1)
H1: RR ≠ 1
H0: OR = 1
H1: OR ≠ 1
De Chi-kwadraattoets
Het verschil in frequentie van de uitkomst tussen de twee groepen kan worden beoordeeld met de chi-kwadraattoets.
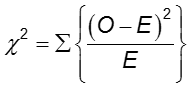
In elke cel van de 2×2-tabel is O de waargenomen celfrequentie en E de verwachte celfrequentie onder de aanname dat de nulhypothese waar is. De som wordt berekend over de 2×2 = 4 cellen in de tabel. Zolang de verwachte frequentie in elke cel ten minste vijf is, heeft de berekende chi-kwadraatwaarde een χ2-verdeling met 1 vrijheidsgraad (df).
Verwerp de nulhypothese als ![]() . Voor α = 0,05 is de kritieke waarde 3,84.
. Voor α = 0,05 is de kritieke waarde 3,84.
Voorbeeld:
Geconstateerde frequenties

Als er geen verband is tussen behandeling en ziekte, zou de proportie gevallen onder degenen die wel en degenen die niet zijn behandeld, gelijk zijn en gelijk aan de proportie gevallen in de gehele onderzoekspopulatie.
Verwachte frequenties:
Over het geheel genomen zijn er onder de 167 kinderen 26 met CA-afwijkingen en 141 zonder CA-afwijkingen. Het aandeel met CA-afwijkingen is 26/167, ofwel 16%. Als de nulhypothese waar is, en de twee behandelingsgroepen hebben dezelfde kans op CA-afwijkingen, dan zouden we verwachten dat ongeveer 16% in elke groep CA-afwijkingen heeft.
Dus, in de GG groep van n=83, zouden we verwachten dat 16% van 83 CA-afwijkingen heeft. Dit wordt berekend als 0,16 x 83 = 13, en wordt de verwachte frequentie in die cel genoemd.
We kunnen dit schrijven als
E11 = verwachte frequentie in rij 1, kolom 1
= verwacht aantal in groep 1 dat de afwijking heeft (rij 1, kolom 1)
En we berekenen het als
E11 = (proportie waarvan we verwachten dat ze de gebeurtenis hebben) x totaal aantal in (groep) rij 1
= x aantal in (groep) rij 1
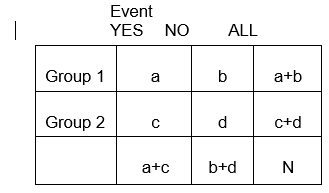
Met behulp van de notatie in de tabel,
E11 = x (a+b)
En we herschrijven dit vaak eenvoudig als
E11 = (a+b)(a+c)/N
In ons voorbeeld, berekenen we de verwachte frequentie in de eerste cel ( E11) :
E11 = (83)(26)/167 = 12.92
We kunnen de verwachte frequenties in de andere cellen op dezelfde manier berekenen
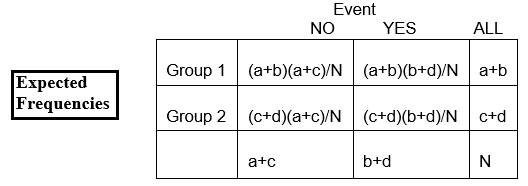
Het totale aandeel zonder CA-afwijkingen is 141/167, of 84%. We verwachten dat ongeveer 84% van degenen in de ASA-groep geen CA-afwijkingen heeft, dus de verwachte frequentie in rij 2, kolom 2, is E22 = 84% van 84, of 0,84 x 84, of ongeveer 71.
Gebruik makend van bovenstaande tabel, kunnen we het eenvoudig berekenen als
E22 = (c+d)(b+d)/N = (84)(141)/167 = 70.92
Oefening: Hoeveel van de kinderen in de ASA-groep zou je verwachten dat ze CA-afwijkingen hebben als de nulhypothese waar is? Probeer dit uit te rekenen voordat je naar het antwoord hieronder kijkt.
Merk op dat de waargenomen frequenties gehele waarden aannemen, terwijl de verwachte frequenties decimale waarden kunnen aannemen.
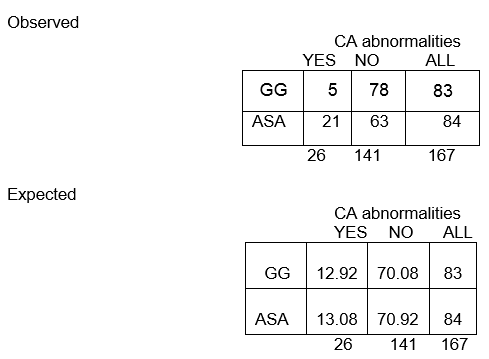
We verwachten dat bijna 13 kinderen in de GG-groep CA-afwijkingen hebben, maar slechts 5 hebben dat ook daadwerkelijk!
Merk op dat wanneer we eenmaal één verwachte frequentie hebben berekend, de andere gemakkelijk door aftrekking kunnen worden verkregen! Het aantal vrijheidsgraden is gelijk aan het aantal cellen waarvan de verwachte frequentie moet worden berekend; in een 2 x 2 tabel is dit 1.
Chi-Square teststatistiek
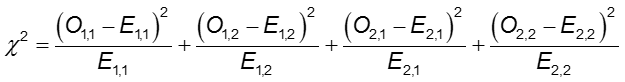
waarbij O1,1 en E1,1 de waargenomen en verwachte tellingen zijn in de cel in de eerste rij en eerste kolom. Bijvoorbeeld, O1,1 = a en E1,1 =(a+b)(a+c)/N. Als de waargenomen celtellingen voldoende verschillen van de verwachte, dan kunnen we niet concluderen dat de twee waarschijnlijkheden gelijk zijn.
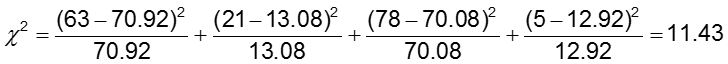
H0: De kans op CA-afwijkingen is gelijk voor alle behandelgroepen (OR=1)
H1: De kans op CA-afwijkingen is niet gelijk over de behandelgroepen (OR≠1)
Het significantieniveau is 0.05.
De teststatistiek is berekend op 11,43. Omdat onze test statistiek groter is dan 3.84 (de chi-kwadraat kritische waarde voor 1 graad van vrijheid), verwerpen we de nulhypothese en concluderen we dat de kans op CA-afwijkingen niet gelijk is in de twee behandelingsgroepen.
terug naar boven | vorige pagina | volgende pagina