NCSS bevat een aantal tools voor multivariate analyse, de analyse van gegevens met meer dan één afhankelijke of Y-variabele. Factoranalyse, Principal Components Analysis (PCA) en Multivariate Analysis of Variance (MANOVA) zijn bekende multivariate analysetechnieken en zijn allemaal beschikbaar in NCSS, samen met diverse andere multivariate analyseprocedures zoals hieronder beschreven.
Gebruik de links hieronder om naar het multivariate analyse-onderwerp te gaan dat u wilt onderzoeken. Om te zien hoe deze tools u van pas kunnen komen, raden wij u aan de gratis trial van NCSS te downloaden en te installeren.
Ga naar:
- Inleiding
- Technische details
- Factoranalyse
- Principal Components Analysis (PCA)
- Canonieke correlatie
- Equality of Covariance
- Discriminantanalyse
- Hotelling’s One-Sample T²
- Hotelling’s Two-Sample T²
- Multivariate Analysis of Variance (MANOVA)
- Correspondentie Analyse
- Loglineaire Modellen
- Multidimensionale Schaling
Inleiding
Hoewel de term Multivariate Analyse gebruikt kan worden om te verwijzen naar elke analyse die meer dan één variabele omvat (bv.b.v. meervoudige regressie of GLM ANOVA), wordt de term multivariate analyse hier en in NCSS gebruikt om te verwijzen naar situaties waarin sprake is van multidimensionale gegevens met meer dan één afhankelijke, Y-, of uitkomstvariabele. Multivariate analysetechnieken worden gebruikt om te begrijpen hoe de reeks uitkomstvariabelen als gecombineerd geheel wordt beïnvloed door andere factoren, hoe de uitkomstvariabelen zich tot elkaar verhouden, of welke onderliggende factoren de waargenomen resultaten in de afhankelijke variabelen produceren.
Elk van de procedures die beschikbaar zijn in de NCSS Multivariate Analysis-sectie wordt hieronder beschreven.
Technische Details
Deze pagina is bedoeld om een algemeen overzicht te geven van de mogelijkheden van NCSS voor multivariate analysetechnieken. Als u de formules en technische details van een specifieke NCSS-procedure wilt bekijken, klikt u op de betreffende ” link onder elke titel om de volledige proceduredocumentatie te laden. Daar vindt u formules, referenties, discussies en voorbeelden of tutorials die de procedure in detail beschrijven.
Factoranalyse
Factoranalyse (FA) is een verkennende techniek die wordt toegepast op een reeks uitkomstvariabelen, waarbij wordt gezocht naar de onderliggende factoren (of deelverzamelingen van variabelen) waaruit de waargenomen variabelen zijn voortgekomen. Bijvoorbeeld, het antwoord van een individu op de vragen van een examen wordt beïnvloed door onderliggende variabelen zoals intelligentie, jaren op school, leeftijd, emotionele toestand op de dag van het examen, hoeveelheid ervaring met het afleggen van examens, enzovoort. De antwoorden op de vragen zijn de geobserveerde of uitkomstvariabelen. De onderliggende, invloedrijke variabelen zijn de factoren.
Factoranalyse wordt uitgevoerd op de correlatiematrix van de waargenomen variabelen. Een factor is een gewogen gemiddelde van de oorspronkelijke variabelen. De factoranalist hoopt enkele factoren te vinden waaruit de oorspronkelijke correlatiematrix kan worden gegenereerd.
Het doel van factoranalyse is meestal de interpretatie van de gegevens te vergemakkelijken. De factoranalist hoopt van elke factor te kunnen vaststellen dat deze een specifieke theoretische factor vertegenwoordigt. Een ander doel van factoranalyse is het aantal variabelen te verminderen. De analist hoopt de interpretatie van een test van 200 vragen terug te brengen tot de bestudering van 4 of 5 factoren.
NCSS biedt de hoofdasmethode van factoranalyse. De resultaten kunnen worden geroteerd met behulp van varimax- of quartimax-rotatie en de factorscores kunnen worden opgeslagen voor verdere analyse. Hieronder ziet u een voorbeeld van de gegevens, de procedure-invoer en de uitvoer.
Staalgegevens
Procedure-invoer
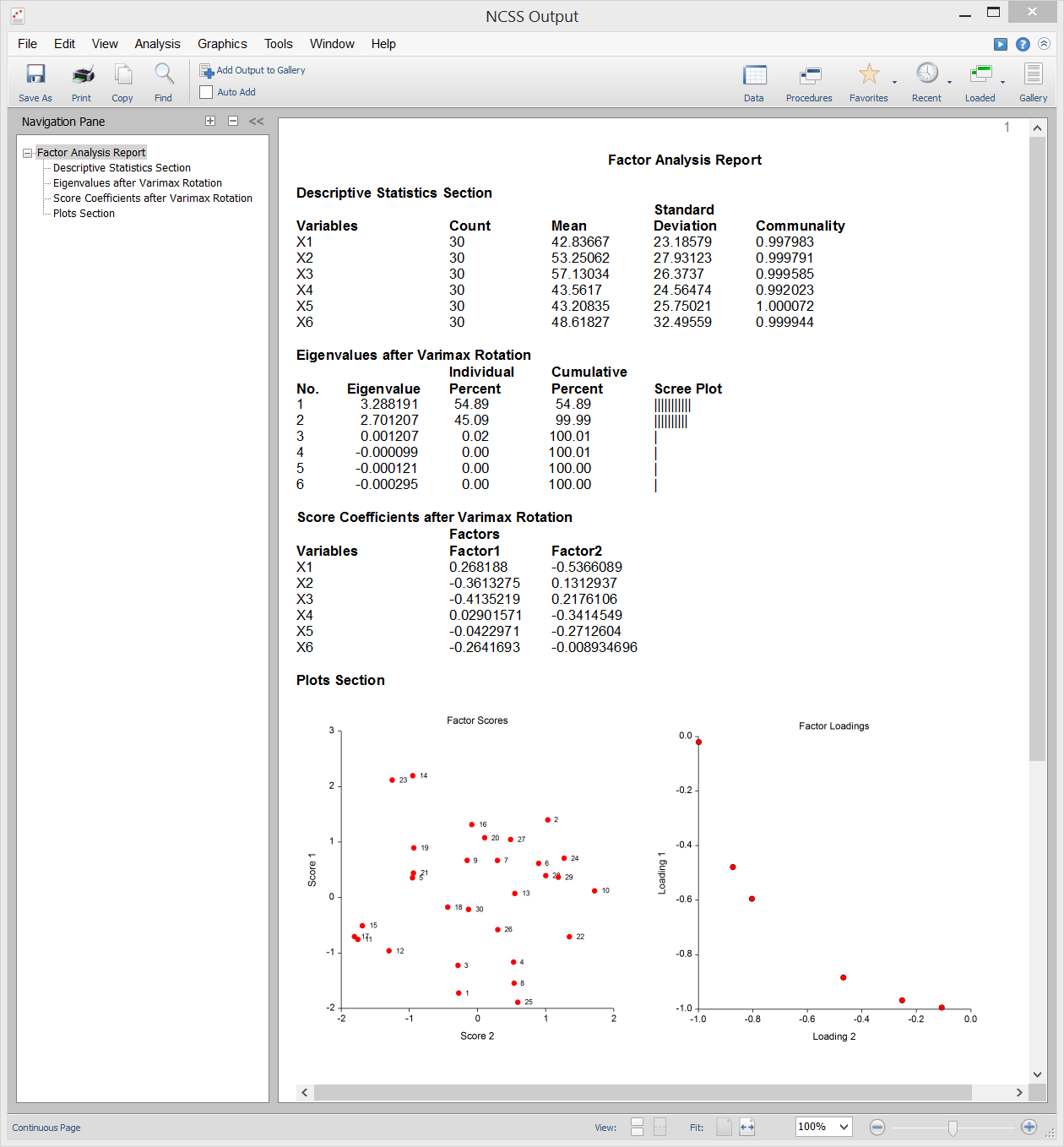
Staaluitvoer
Principal Components Analysis (PCA)
Principal Components Analysis (of PCA) is een gegevensanalyse-instrument dat vaak wordt gebruikt om de dimensionaliteit (of het aantal variabelen) van een groot aantal onderling gerelateerde variabelen te reduceren, met behoud van zoveel mogelijk informatie (bv.variatie) zoveel mogelijk te behouden. PCA berekent een ongecorreleerde reeks variabelen die factoren of hoofdcomponenten worden genoemd. Deze factoren worden zo gerangschikt dat de eerste paar de meeste variatie behouden die in alle oorspronkelijke variabelen aanwezig is. In tegenstelling tot zijn neefje Factoranalyse levert PCA altijd dezelfde oplossing op voor dezelfde gegevens.
NCSS gebruikt een dubbelprecieze versie van het moderne QL-algoritme zoals beschreven door Press (1986) om het eigenwaarde-eigenvectorprobleem op te lossen dat bij de berekeningen van PCA een rol speelt. NCSS voert PCA uit op een correlatie- of een covariantiematrix. De analyse kan worden uitgevoerd met behulp van robuuste schattingstechnieken.
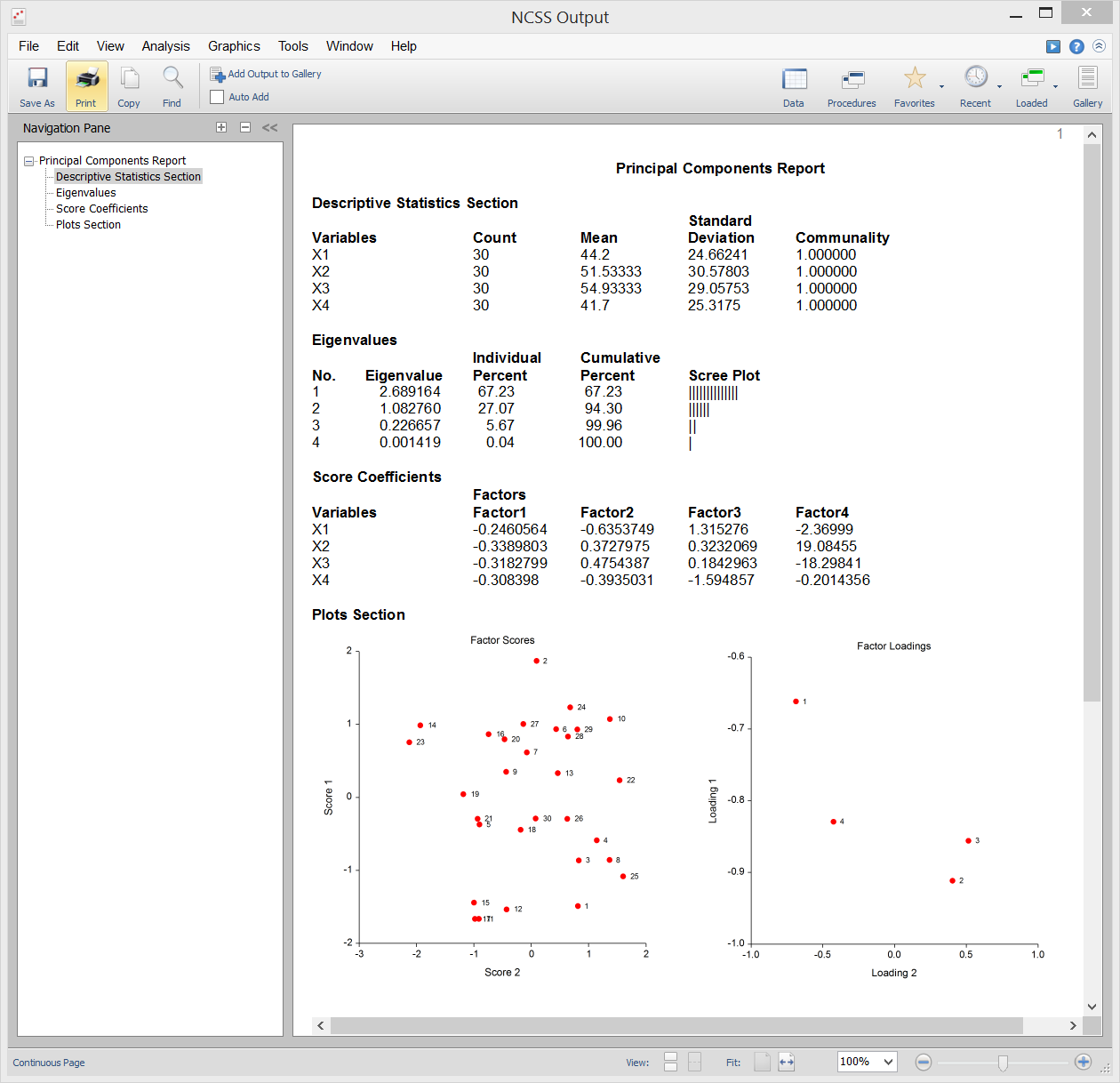
Sample Output
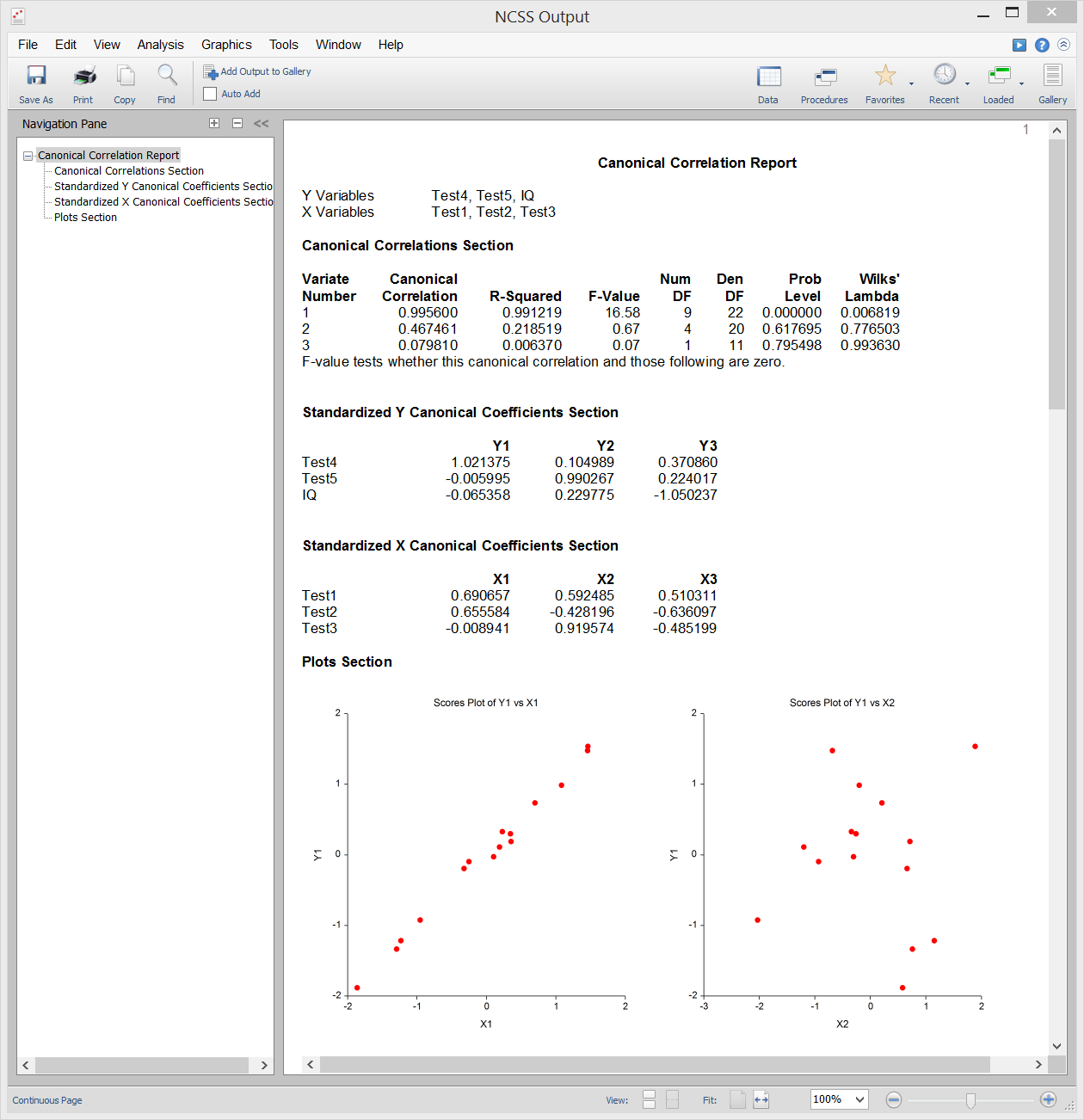
Canonical Correlation
Canonical correlation analysis is de studie van het lineaire verband tussen twee verzamelingen variabelen. Het is de multivariate uitbreiding van correlatieanalyse. Ter illustratie, stel dat een groep studenten elk twee toetsen van elk tien vragen krijgt en dat u de algemene correlatie tussen deze twee toetsen wilt bepalen. Canonieke correlatie vindt een gewogen gemiddelde van de vragen uit de eerste test en correleert dit met een gewogen gemiddelde van de vragen uit de tweede test. De gewichten worden zo geconstrueerd dat de correlatie tussen deze twee gemiddelden zo groot mogelijk is. Deze correlatie wordt de eerste canonieke correlatiecoëfficiënt genoemd. U kunt dan een andere reeks gewogen gemiddelden maken die geen verband houden met de eerste en hun correlatie berekenen. Deze correlatie is de tweede canonieke correlatiecoëfficiënt. Dit proces gaat door totdat het aantal canonieke correlaties gelijk is aan het aantal variabelen in de kleinste groep.
Canonieke correlatie biedt het meest algemene multivariate raamwerk (Discriminantanalyse, MANOVA, en meervoudige regressie zijn allemaal speciale gevallen van canonieke correlatie). Vanwege deze algemeenheid is canonieke correlatie waarschijnlijk de minst gebruikte van de multivariate procedures.
Bemonsteringsuitvoer
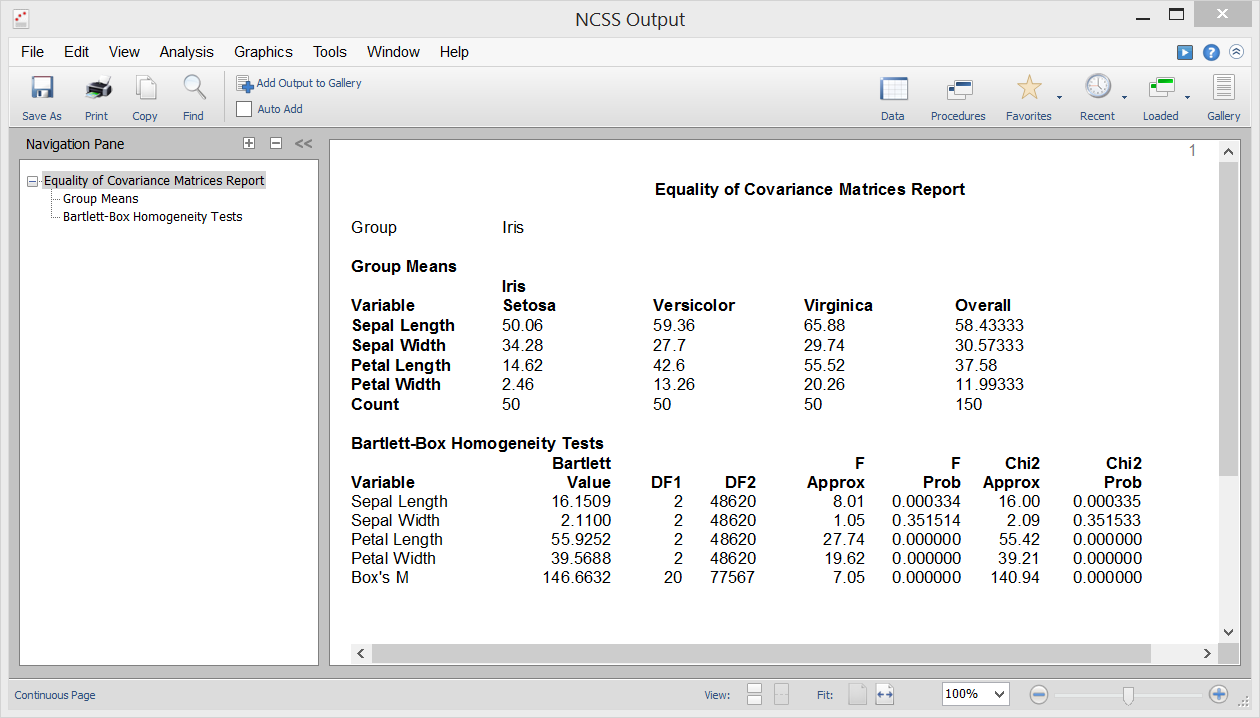
Gelijkheid van covariantie
Eén van de veronderstellingen in Discriminantanalyse, MANOVA en diverse andere multivariate procedures is dat de covariantiematrices van de afzonderlijke groepen gelijk zijn (d.w.z. homogeen over de groepen). Met de gelijkheid van covariantie-procedure in NCSS kunt u deze hypothese testen met de M-toets van Box, die voor het eerst voorgesteld werd door Box (1949). Deze procedure voert ook de univariate homogeniteitstest van Bartlett uit om de gelijkheid van variantie tussen afzonderlijke variabelen te testen.
Sample Output
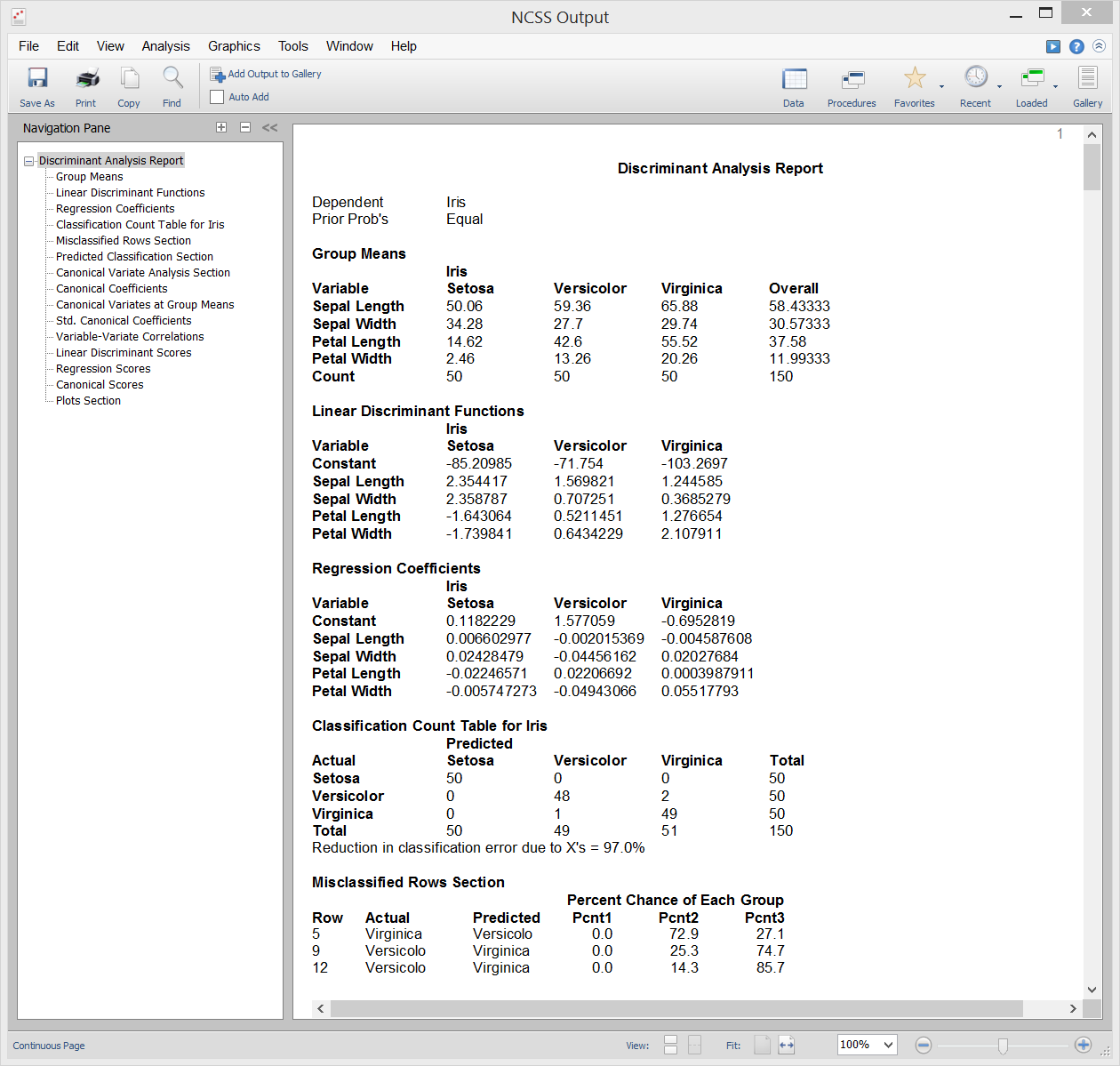
Discriminantanalyse
Discriminantanalyse is een techniek die wordt gebruikt om een reeks voorspellingsvergelijkingen te vinden op basis van een of meer onafhankelijke variabelen. Deze voorspellingsvergelijkingen worden vervolgens gebruikt om individuen in groepen in te delen. Er zijn twee gemeenschappelijke doelstellingen bij discriminantanalyse: 1. het vinden van een voorspellende vergelijking voor het classificeren van nieuwe individuen, en 2. het interpreteren van de voorspellende vergelijking om de relaties tussen de variabelen beter te begrijpen.
In veel opzichten lijkt discriminantanalyse veel op logistische regressieanalyse. De methodologie die wordt gebruikt om een discriminantanalyse uit te voeren, is vergelijkbaar met logistische regressieanalyse. Vaak plot je elke onafhankelijke variabele versus de groepsvariabele, doorloop je een variabelenselectiefase om te bepalen welke onafhankelijke variabelen gunstig zijn, en voer je een residu-analyse uit om de nauwkeurigheid van de discriminantvergelijkingen te bepalen.
De berekeningen in discriminantanalyse zijn zeer nauw verwant aan eenrichtings-MANOVA. In feite zijn de rollen van de variabelen gewoon omgedraaid. De classificatie (factor) variabele in de MANOVA wordt de afhankelijke variabele in de discriminantanalyse. De afhankelijke variabelen in de eenrichtings-MANOVA worden de onafhankelijke variabelen in de discriminantanalyse.
Sample Output
Hotelling’s One-Sample T²
De Hotelling’s One-Sample T²-test is de multivariate uitbreiding van de gebruikelijke one-sample of gepaarde Student’s T-test. Deze test wordt gebruikt als het aantal responsvariabelen twee of meer is, hoewel hij ook kan worden gebruikt als er slechts één responsvariabele is. De toets vereist de aanname dat de gegevens bij benadering multivariaat normaal zijn, maar er zijn randomisatietoetsen beschikbaar die niet op deze aanname berusten.
Bemonsteringsuitvoer

Hotelling’s twee-steekproef T²
De Hotelling’s twee-steekproef T²-test is de multivariate uitbreiding van de gebruikelijke twee-steekproef Student’s T-test voor verschil in gemiddelden. Deze test wordt gebruikt als het aantal responsvariabelen twee of meer is, hoewel hij ook kan worden gebruikt als er slechts één responsvariabele is. De toets vereist de aanname van gelijke varianties en normaal verdeelde residuen, maar er zijn randomisatietoetsen beschikbaar die niet op deze aannames berusten.
Bemonsteringsuitvoer

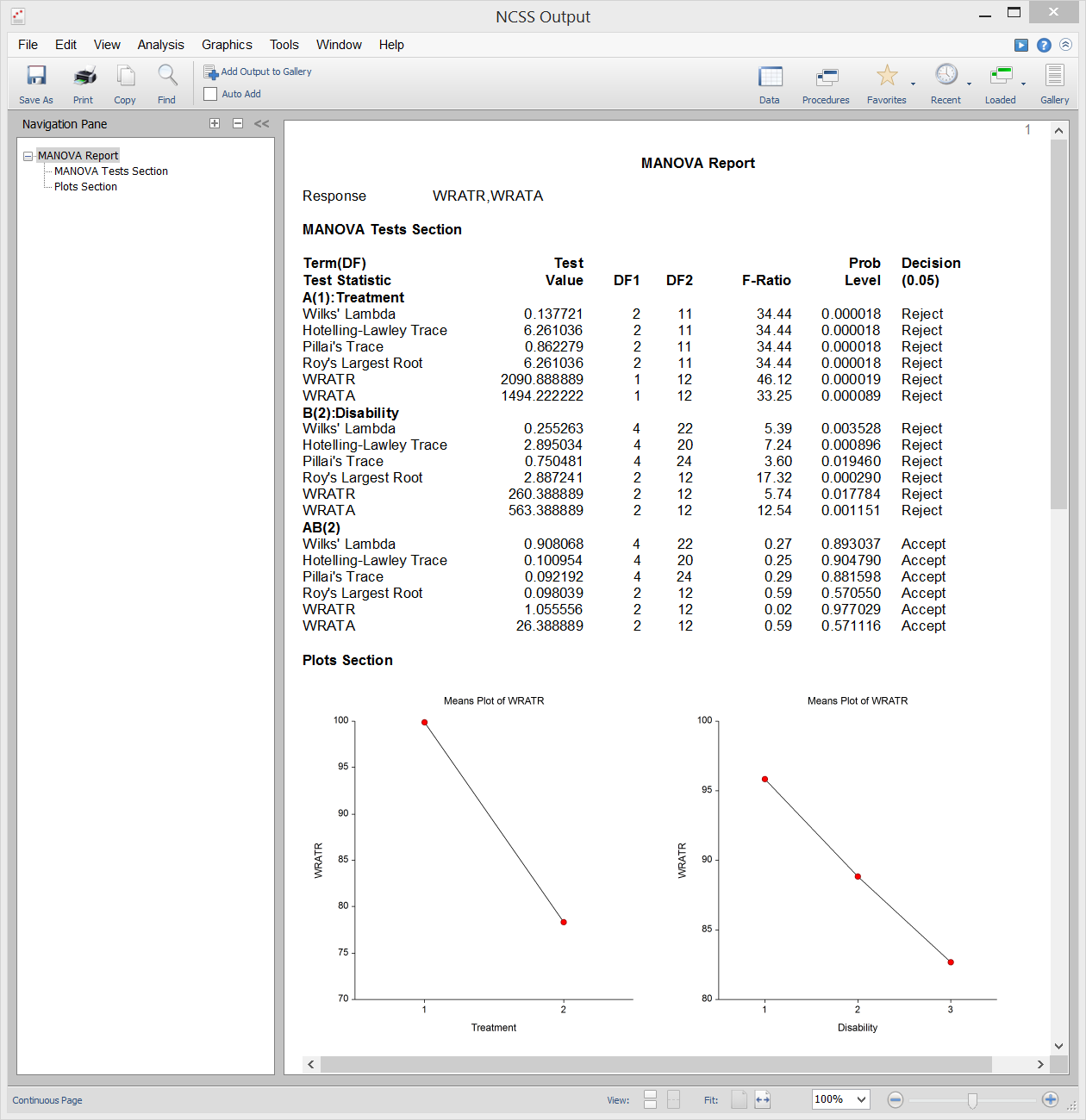
Multivariate Analysis of Variance (MANOVA)
Multivariate Analysis of Variance (of MANOVA) is een uitbreiding van ANOVA tot het geval waarin er twee of meer responsvariabelen zijn. MANOVA is ontworpen voor het geval waarin je een of meer onafhankelijke factoren hebt (elk met twee of meer niveaus) en twee of meer afhankelijke variabelen. De hypothesetests betreffen de vergelijking van vectoren van groepsgemiddelden.
De multivariate uitbreiding van de F-test uit ANOVA is niet helemaal direct. In plaats daarvan zijn er verschillende andere teststatistieken beschikbaar in MANOVA: Wilks’ Lambda, Hotelling-Lawley Trace, Pillai’s Trace, en Roy’s Largest Root. De werkelijke verdelingen van deze teststatistieken zijn moeilijk te berekenen, dus vertrouwen we op benaderingen op basis van de F-verdeling om p-waarden te berekenen.
Bemonsteringsuitvoer
Correspondentieanalyse
Correspondentieanalyse (of CA) is een techniek om een tabel met categorische gegevens in twee richtingen grafisch weer te geven met behulp van berekende coördinaten die de rijen en kolommen van de tabel weergeven. Deze coördinaten zijn analoog aan factoren in een principale componentenanalyse (gebruikt voor continue gegevens), behalve dat ze de Chi-kwadraatwaarde verdelen die wordt gebruikt bij het testen van de onafhankelijkheid in plaats van de totale variantie.
Bemonsteringsuitvoer
Loglineaire modellen
Loglineaire modellen (LLM) worden gebruikt om de relaties tussen twee of meer discrete variabelen te bestuderen. LLM wordt ook wel multiway frequency analysis genoemd en is een uitbreiding van de bekende chi-kwadraattoets voor onafhankelijkheid in two-way contingency tables.
LLM kan worden gebruikt voor de analyse van enquêtes en vragenlijsten met complexe onderlinge relaties tussen de vragen. Hoewel vragenlijsten vaak worden geanalyseerd door slechts twee vragen tegelijk te beschouwen, gaat dit voorbij aan belangrijke drie- (en meerweg) relaties tussen de vragen. Het gebruik van LLM op dit soort gegevens is analoog aan het gebruik van meervoudige regressie in plaats van eenvoudige correlaties op continue gegevens.
De rapporten in deze procedure omvatten rapporten over meerdere perioden, rapporten over één perioden, chi-kwadraatrapporten, modelrapporten, rapporten over parameterschattingen, en tabelrapporten.
Voorbeelduitvoer
Multidimensionale schaling
Multidimensionale schaling (MDS) is een techniek waarmee een kaart wordt gemaakt die de relatieve posities van een aantal objecten weergeeft, gegeven alleen een tabel met de afstanden tussen die objecten. De kaart kan uit één, twee, drie of meer dimensies bestaan. De procedure berekent ofwel de metrische ofwel de niet-metrische oplossing. De tabel van afstanden staat bekend als de nabijheidsmatrix. Deze ontstaat hetzij direct uit experimenten, hetzij indirect als een correlatiematrix.
Het programma biedt twee algemene methoden om het MDS-probleem op te lossen. De eerste heet Metric, of Classical, Multidimensional Scaling (CMDS) omdat wordt getracht de oorspronkelijke metriek of afstanden te reproduceren. De tweede methode, Non-Metric Multidimensional Scaling (NMMDS) genoemd, gaat ervan uit dat alleen de rangorde van de afstanden bekend is. Deze methode produceert dus een kaart die de rangen tracht te reproduceren. De afstanden zelf worden niet gereproduceerd.