SPSS Statistics
Interpretacja i raportowanie danych wyjściowych analizy dwumianowej regresji logistycznej
SPSS Statistics generuje wiele tabel danych wyjściowych podczas przeprowadzania dwumianowej regresji logistycznej. W tej sekcji pokażemy tylko trzy główne tabele wymagane do zrozumienia wyników procedury dwumianowej regresji logistycznej, zakładając, że żadne założenia nie zostały naruszone. Pełne wyjaśnienie danych wyjściowych, które należy zinterpretować podczas sprawdzania danych pod kątem założeń wymaganych do przeprowadzenia dwumianowej regresji logistycznej, znajduje się w naszym rozszerzonym przewodniku.
Jednakże w tym poradniku „szybki start” skupimy się tylko na trzech głównych tabelach, które są potrzebne do zrozumienia wyników dwumianowej regresji logistycznej, zakładając, że dane spełniają założenia wymagane do uzyskania poprawnych wyników:
Wariancja wyjaśniona
Aby zrozumieć, jak wiele wariancji zmiennej zależnej może być wyjaśnione przez model (odpowiednik R2 w regresji wielorakiej), możesz skonsultować poniższą tabelę „Podsumowanie modelu”:
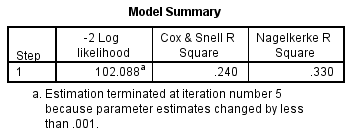
Ta tabela zawiera wartości Coxa & Snell R Square i Nagelkerke R Square, które są obiema metodami obliczania zmienności wyjaśnionej. Wartości te są czasami określane jako wartości pseudo R2 (i będą miały niższe wartości niż w regresji wielokrotnej). Są one jednak interpretowane w ten sam sposób, ale z większą ostrożnością. Zatem zmienność wyjaśniona zmiennej zależnej na podstawie naszego modelu waha się od 24,0% do 33,0%, w zależności od tego, czy odwołujemy się odpowiednio do metody Coxa & Snell R2 czy Nagelkerke R2. Nagelkerke R2 jest modyfikacją Coxa & Snell R2, przy czym ta ostatnia nie może osiągnąć wartości 1. Z tego powodu preferowane jest podawanie wartości Nagelkerke R2.
Przewidywanie kategorii
Binomialna regresja logistyczna szacuje prawdopodobieństwo wystąpienia zdarzenia (w tym przypadku wystąpienia choroby serca). Jeśli oszacowane prawdopodobieństwo wystąpienia zdarzenia jest większe lub równe 0,5 (lepsze niż prawdopodobieństwo równe), SPSS Statistics klasyfikuje zdarzenie jako występujące (np. obecność choroby serca). Jeśli prawdopodobieństwo jest mniejsze niż 0,5, SPSS Statistics klasyfikuje zdarzenie jako niewystępujące (np. brak choroby serca). Bardzo często stosuje się dwumianową regresję logistyczną, aby przewidzieć, czy przypadki można prawidłowo sklasyfikować (tj. przewidzieć) na podstawie zmiennych niezależnych. Dlatego konieczne staje się posiadanie metody oceny skuteczności przewidywanej klasyfikacji w stosunku do klasyfikacji rzeczywistej. Istnieje wiele metod oceny, których przydatność często zależy od charakteru prowadzonego badania. Jednak wszystkie metody obracają się wokół obserwowanych i przewidywanych klasyfikacji, które są przedstawione w „Tabeli klasyfikacji”, jak pokazano poniżej:
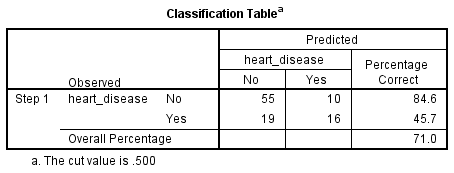
Po pierwsze, zauważ, że tabela ma indeks dolny, który stwierdza, „The cut value is .500”. Oznacza to, że jeśli prawdopodobieństwo zaklasyfikowania przypadku do kategorii „tak” jest większe niż .500, wówczas ten konkretny przypadek jest zaklasyfikowany do kategorii „tak”. W przeciwnym razie, sprawa jest klasyfikowana jako w kategorii „nie” (jak wspomniano wcześniej). Chociaż tabela klasyfikacji wydaje się bardzo prosta, w rzeczywistości dostarcza wielu ważnych informacji na temat wyniku dwumianowej regresji logistycznej, w tym:
- A. Procentowa dokładność w klasyfikacji (PAC), która odzwierciedla odsetek przypadków, które można poprawnie sklasyfikować jako „nie” choroby serca z dodanymi zmiennymi niezależnymi (nie tylko ogólny model).
- B. Czułość, która jest odsetkiem przypadków, które miały obserwowaną cechę (np, „tak” dla choroby serca), które zostały prawidłowo przewidziane przez model (tj. prawdziwe wyniki pozytywne).
- C. Swoistość, która jest odsetkiem przypadków, które nie miały obserwowanej cechy (np. „nie” dla choroby serca) i również zostały prawidłowo przewidziane jako nie mające obserwowanej cechy (tj, prawdziwe negatywy).
- D. Pozytywna wartość predykcyjna, która jest procentem poprawnie przewidywanych przypadków „z” obserwowaną cechą w porównaniu do całkowitej liczby przypadków przewidywanych jako mające cechę.
- E. Negatywna wartość predykcyjna, która jest procentem poprawnie przewidywanych przypadków „bez” obserwowanej cechy w porównaniu do całkowitej liczby przypadków przewidywanych jako nie mające cechy.
Jeśli nie jesteś pewien jak interpretować PAC, czułość, specyficzność, pozytywną wartość predykcyjną i negatywną wartość predykcyjną z „Tabeli klasyfikacji”, wyjaśniamy jak w naszym rozszerzonym przewodniku po dwumianowej regresji logistycznej.
Zmienne w równaniu
Tabela „Zmienne w równaniu” pokazuje wkład każdej niezależnej zmiennej do modelu i jej istotność statystyczną. Tabela ta jest przedstawiona poniżej:
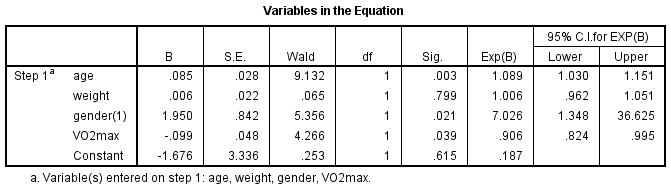
Test Walda (kolumna „Wald”) służy do określenia istotności statystycznej dla każdej ze zmiennych niezależnych. Istotność statystyczna testu znajduje się w kolumnie „Sig.”. Z tych wyników widać, że wiek (p = .003), płeć (p = .021) i VO2max (p = .039) dodały istotnie do modelu/przewidywania, ale waga (p = .799) nie dodała istotnie do modelu. Możesz użyć informacji z tabeli „Zmienne w równaniu”, aby przewidzieć prawdopodobieństwo wystąpienia zdarzenia na podstawie zmiany o jedną jednostkę w zmiennej niezależnej, gdy wszystkie inne zmienne niezależne są utrzymywane na stałym poziomie. Na przykład, tabela pokazuje, że prawdopodobieństwo wystąpienia choroby serca (kategoria „tak”) jest 7,026 razy większe dla mężczyzn niż dla kobiet. Jeśli nie jesteś pewien, jak używać ilorazów szans do tworzenia prognoz, zapoznaj się z naszymi rozszerzonymi przewodnikami na naszej stronie Funkcje: Overview page.
Putting it all together
Based on the results above, we could report the results of the study as follows (N.B., this does not include the results from your assumptions tests):
- General
A logistic regression was performed to ascertain the effects of age, weight, gender and VO2max on the likelihood that participants have heart disease. Model regresji logistycznej był istotny statystycznie, χ2(4) = 27,402, p < .0005. Model ten wyjaśniał 33,0% (Nagelkerke R2) wariancji chorób serca i poprawnie klasyfikował 71,0% przypadków. Mężczyźni byli 7,02 razy bardziej narażeni na wystąpienie choroby serca niż kobiety. Wzrost wieku wiązał się ze zwiększonym prawdopodobieństwem wystąpienia choroby serca, ale wzrost VO2max wiązał się ze zmniejszeniem prawdopodobieństwa wystąpienia choroby serca.
W uzupełnieniu powyższego zapisu należy zamieścić: (a) wyniki z testów założeń, które przeprowadziłeś; (b) wyniki z „Tabeli klasyfikacji”, w tym czułość, swoistość, dodatnią wartość predykcyjną i ujemną wartość predykcyjną; oraz (c) wyniki z tabeli „Zmienne w równaniu”, w tym, które ze zmiennych predykcyjnych były statystycznie istotne i jakie przewidywania można poczynić w oparciu o wykorzystanie ilorazów szans. Jeśli nie jesteś pewien, jak to zrobić, pokażemy Ci to w naszym rozszerzonym przewodniku po dwumianowej regresji logistycznej. Pokazujemy również, jak zapisywać wyniki testów założeń i wyniki dwumianowej regresji logistycznej, jeśli trzeba to zgłosić w pracy dyplomowej/tezie, zadaniu lub raporcie z badań. Robimy to przy użyciu stylów Harvard i APA. Możesz dowiedzieć się więcej o naszych rozszerzonych treściach na naszej stronie Funkcje: Overview page.