Zmienne kategoryczne mogą reprezentować rozwój choroby, wzrost ciężkości choroby, śmiertelność lub jakąkolwiek inną zmienną, która składa się z dwóch lub więcej poziomów. Aby podsumować związek między dwiema zmiennymi kategorycznymi z poziomami R i C, tworzymy tabele krzyżowe lub tabele RxC („Wiersz „x „Kolumna” lub tabele kontyngencji), które podsumowują obserwowane częstości wyników kategorycznych wśród różnych grup badanych. Tutaj skoncentrujemy się na tabelach 2 x 2.
Ogólnie, tabele 2 x 2 podsumowują częstość występowania zdarzeń związanych ze zdrowiem (lub innych) w różnych grupach, jak pokazano poniżej, gdzie Grupa 1 może reprezentować pacjentów, którzy otrzymali standardową terapię, a Grupa 2 może być pacjentami, którzy otrzymali nową terapię eksperymentalną.
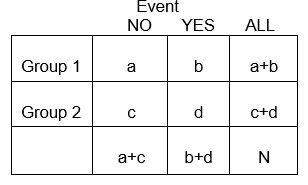
Przykład:
Pierwszorzędową zmienną wynikową w badaniach Kawasaki był rozwój nieprawidłowości w tętnicach wieńcowych (CA), zmienna dychotomiczna. Jednym z celów badania było porównanie prawdopodobieństwa rozwoju nieprawidłowości w tętnicach wieńcowych w przypadku leczenia aspiryną (ASA) lub gamma globuliną (GG).

Chcielibyśmy wiedzieć, czy częstość występowania nieprawidłowości w tętnicach wieńcowych różniła się w tych dwóch grupach, tzn, czy jedna z nich była związana z mniejszą liczbą nieprawidłowości. Odpowiedź na pytania takie jak to zależy od porównania częstości tych zdarzeń zdrowotnych w dwóch grupach leczenia. W zależności od projektu badania, można porównać prawdopodobieństwo wystąpienia zdarzeń lub szanse wystąpienia zdarzenia.
Prawdopodobieństwo i szanse wystąpienia CA w każdej z grup badanych
Prawdopodobieństwo jest obliczane jako liczba wartości „tak” w każdej kategorii leczenia podzielona przez całkowitą liczbę w kategorii leczenia.
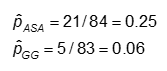
Szanse to #tak / #nie. Tutaj,
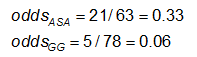
Zawsze zwracaj uwagę, czy wynik jest w wierszach, czy w kolumnach; bardzo łatwo jest je pomieszać!
Gdy patrzyliśmy na związek między jedną zmienną binarną a wynikiem ciągłym, podsumowaliśmy związek w kategoriach różnicy średnich. Jakie statystyki są odpowiednie do przedstawienia różnicy między dwiema grupami w odniesieniu do prawdopodobieństwa zdarzenia binarnego? Istnieją co najmniej trzy sposoby podsumowania asocjacji:
Różnica ryzyka RD = p1 – p2
p2
Relative Risk (Risk Ratio) RR = p1 / p2
Odds Ratio OR = odds1/ odds2 = /
Projekt badania określa, która z tych miar efektu jest odpowiednia. W badaniu typu przypadek/kontrola nie można ocenić ryzyka względnego, a odpowiednią miarą jest iloraz szans (OR). Jednak OR zapewni dobre oszacowanie ryzyka względnego dla rzadkich zdarzeń (tzn. jeśli p jest małe, zwykle 0,10 lub mniejsze).
Badania przekrojowe oceniają częstość występowania działań zdrowotnych, dlatego odpowiedni jest iloraz szans. W przypadku prospektywnych badań kohortowych odpowiedni jest współczynnik częstości lub współczynnik ryzyka, chociaż można również obliczyć iloraz szans.,
Aby zapoznać się z bardziej szczegółowym przeglądem miar efektu, zobacz moduł epidemiologii online na temat „Miary asocjacji”.
Przykład: Korzystając z poprzednich danych dotyczących nieprawidłowości CA, miary efektu dla osób stosujących ASA (aspiryna) w porównaniu z gamma globuliną (GG) są następujące:
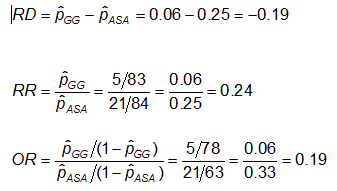

Ćwiczenie: Rozważ miary efektu w poprzednim przykładzie. Dlaczego współczynnik ryzyka i iloraz szans są tak różne (RR sugeruje, że w porównaniu z grupą leczoną tylko ASA, ryzyko wystąpienia nieprawidłowości wieńcowych jest o 1/4 większe u osób leczonych GG; natomiast OR sugeruje, że ryzyko jest o 1/5 większe)?
Alternatywne sposoby wyrażenia hipotezy zerowej
W przypadku tabeli 2×2 hipoteza zerowa może być zapisana w kategoriach samych prawdopodobieństw, różnicy ryzyka, ryzyka względnego lub ilorazu szans. W każdym z tych przypadków hipoteza zerowa stwierdza, że nie ma różnicy między dwiema grupami.
H0: p1 = p2
H1: p1 ≠ p2
H0: p1 – p2 = 0 (RD=0)
H1: RD ≠ 0
H0: p1/ p2 = 1 (RR=1)
H1: RR ≠ 1
H0: OR = 1
H1: OR ≠ 1
Test Chi-kwadrat
Różnicę w częstości występowania wyniku między dwiema grupami można ocenić za pomocą testu chi kwadrat.
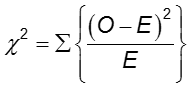
W każdej komórce tabeli 2×2, O jest obserwowaną częstością komórek, a E jest oczekiwaną częstością komórek przy założeniu, że hipoteza zerowa jest prawdziwa. Suma jest obliczana na 2×2 = 4 komórki w tabeli. Tak długo, jak oczekiwana częstotliwość w każdej komórce wynosi co najmniej pięć, obliczona wartość chi kwadrat ma rozkład χ2 z 1 stopniem swobody (df).
Odrzuć hipotezę zerową, jeśli ![]() . Dla α = 0,05, wartość krytyczna wynosi 3,84.
. Dla α = 0,05, wartość krytyczna wynosi 3,84.
Przykład:
Częstości obserwowane

Jeśli nie ma związku między leczeniem a chorobą, proporcja przypadków wśród leczonych i nieleczonych byłaby taka sama i równa proporcji przypadków w całej badanej populacji.
Przewidywane częstości:
Ogółem, wśród 167 dzieci, jest 26 z nieprawidłowościami CA i 141 bez nieprawidłowości CA. Odsetek dzieci z nieprawidłowościami CA wynosi 26/167, czyli 16%. Jeśli hipoteza zerowa jest prawdziwa, a obie grupy mają takie samo prawdopodobieństwo wystąpienia nieprawidłowości CA, to spodziewamy się, że około 16% w każdej grupie będzie miało nieprawidłowości CA.
Więc w grupie GG n=83, spodziewamy się, że 16% z 83 będzie miało nieprawidłowości CA. Obliczamy to jako 0,16 x 83 = 13 i nazywamy to oczekiwaną częstością w tej komórce.
Możemy to zapisać jako
E11 = oczekiwana częstość w wierszu 1, kolumnie 1
= oczekiwana liczba w grupie 1, która ma zdarzenie (wiersz 1, kolumna 1)
I obliczamy to jako
E11 = (odsetek, dla którego spodziewamy się wystąpienia zdarzenia) x całkowita liczba w (grupie) wiersz 1
= x liczba w (grupie) wiersz 1
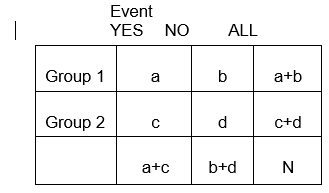
Używając zapisu w tabeli,
E11 = x (a+b)
I często zapisujemy to po prostu jako
E11 = (a+b)(a+c)/N
W naszym przykładzie, obliczmy oczekiwaną częstotliwość w pierwszej komórce ( E11) :
E11 = (83)(26)/167 = 12.92
W ten sam sposób możemy obliczyć oczekiwane częstości w pozostałych komórkach
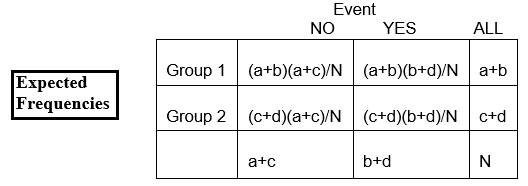
Ogólna proporcja bez nieprawidłowości CA wynosi 141/167, czyli 84%. Spodziewamy się, że około 84% osób z grupy ASA nie będzie miało nieprawidłowości CA, więc oczekiwana częstość w wierszu 2, kolumnie 2 wynosi E22 = 84% z 84, lub 0,84 x 84, czyli około 71.
Przy użyciu powyższej tabeli moglibyśmy po prostu obliczyć ją jako
E22 = (c+d)(b+d)/N = (84)(141)/167 = 70.92
Ćwiczenie: Jak wielu dzieci z grupy ASA spodziewałbyś się mieć nieprawidłowości CA, jeśli hipoteza zerowa jest prawdziwa? Spróbuj to obliczyć, zanim spojrzysz na odpowiedź poniżej.
Zauważ, że obserwowane częstości przyjmują wartości całkowite, podczas gdy oczekiwane częstości mogą przyjmować wartości dziesiętne.
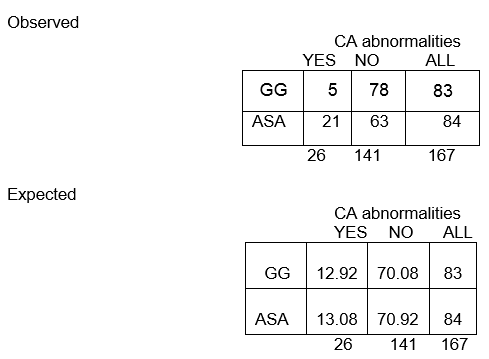
Spodziewamy się, że prawie 13 dzieci w grupie GG będzie miało nieprawidłowości CA, ale tylko 5 rzeczywiście je ma!
Zauważ, że po obliczeniu jednej oczekiwanej częstości, pozostałe można łatwo uzyskać przez odejmowanie! Liczba stopni swobody równa się liczbie komórek, których oczekiwana częstość musi być obliczona; w tabeli 2 x 2 jest to 1.
Statystyka testu Chi-Square
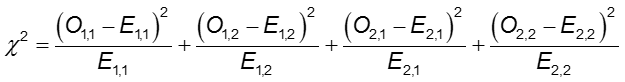
gdzie O1,1 i E1,1 są obserwowaną i oczekiwaną liczbą w komórce w pierwszym wierszu i pierwszej kolumnie. Na przykład O1,1 = a, a E1,1 =(a+b)(a+c)/N. Jeśli zaobserwowane liczby komórek różnią się wystarczająco od oczekiwanych, nie możemy stwierdzić, że oba prawdopodobieństwa są równe.
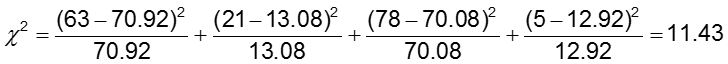
H0: Szanse wystąpienia nieprawidłowości CA są takie same we wszystkich grupach leczenia (OR=1)
H1: The odds of CA abnormalities are not the same across treatment groups (OR≠1)
Poziom istotności wynosi 0.05.
Statystyka testowa jest obliczana jako 11,43. Ponieważ nasza statystyka testowa jest większa niż 3,84 (wartość krytyczna chi kwadrat dla 1 stopnia swobody), odrzucamy hipotezę zerową i stwierdzamy, że prawdopodobieństwo wystąpienia nieprawidłowości CA nie jest takie samo w dwóch grupach leczonych.
powrót do góry | poprzednia strona | następna strona