Przez Marka Sheada
Wprowadzenie do pojęć informatyki
Komputerologia umożliwia nam programowanie, ale możliwe jest wykonywanie wielu czynności programistycznych bez zrozumienia podstawowych pojęć informatyki.
Nie zawsze jest to złe. Kiedy programujemy, pracujemy na dużo wyższym poziomie abstrakcji.
Kiedy prowadzimy samochód, zajmujemy się tylko dwoma lub trzema pedałami, dźwignią zmiany biegów i kierownicą. Możesz bezpiecznie prowadzić samochód, nie mając pojęcia, jak on działa.
Jednakże, jeśli chcesz prowadzić samochód na granicy jego możliwości, musisz wiedzieć o nim znacznie więcej niż tylko trzy pedały, skrzynia biegów i kierownica.
Tak samo jest z programowaniem. Wiele codziennych zadań można wykonać z niewielkim lub żadnym zrozumieniem informatyki. Nie musisz rozumieć teorii obliczeń, aby zbudować formularz „Skontaktuj się z nami” w PHP.
Jednakże, jeśli planujesz pisać kod, który wymaga poważnych obliczeń, będziesz musiał zrozumieć nieco więcej na temat tego, jak obliczenia działają pod maską.
Celem tego artykułu jest zapewnienie fundamentalnego tła dla obliczeń. Jeśli będzie zainteresowanie, być może zajmę się bardziej zaawansowanymi tematami, ale teraz chcę przyjrzeć się logice stojącej za jednym z najprostszych abstrakcyjnych urządzeń obliczeniowych – maszyną stanów skończonych.
Maszyny stanów skończonych
Maszyna stanów skończonych jest matematyczną abstrakcją używaną do projektowania algorytmów.
W uproszczeniu, maszyna stanów będzie czytać serię wejść. Kiedy odczyta dane wejściowe, przełączy się do innego stanu. Każdy stan określa, na jaki stan należy przejść dla danego wejścia. Brzmi to skomplikowanie, ale tak naprawdę jest to całkiem proste.
Wyobraź sobie urządzenie, które czyta długą kartkę papieru. Na każdym calu papieru jest wydrukowana jedna litera – albo litera „a”, albo litera „b”.

Jak maszyna stanów czyta każdą literę, zmienia stan. Oto bardzo prosta maszyna stanów:
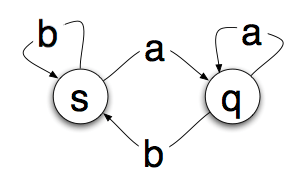
Kółka to „stany”, w których może znajdować się maszyna. Strzałki to przejścia. Tak więc, jeśli jesteś w stanie s i przeczytasz literę 'a', przejdziesz do stanu q. Jeśli przeczytasz literę 'b', pozostaniesz w stanie s.
Jeśli zaczniemy od s i będziemy czytać taśmę papierową powyżej od lewej do prawej, przeczytamy 'a' i przejdziemy do stanu q.
Potem przeczytamy 'b' i wrócimy do stanu s.
Kolejne 'b' zatrzyma nas na s, a następnie 'a' – co przeniesie nas z powrotem do stanu q. To dość proste, ale o co chodzi?
Okazuje się, że można przepuścić taśmę przez maszynę stanów i powiedzieć coś o kolejności liter, badając stan, w którym kończymy.
W naszej prostej maszynie stanów powyżej, jeśli kończymy w stanie s, taśma musi kończyć się literą 'b'. Jeśli kończymy w stanie q, taśma kończy się literą 'a'.
Może to brzmieć bez sensu, ale istnieje bardzo wiele problemów, które można rozwiązać za pomocą tego typu podejścia. Bardzo prostym przykładem może być określenie, czy strona HTML zawiera te znaczniki w tej kolejności:
<html> <head> </head> <body> </body> </html>Maszyna stanowa może przejść do stanu, który pokazuje, że przeczytała znacznik html, pętla, aż dotrze do znacznika head, pętla, aż dotrze do znacznika zamknięcia head i tak dalej.
Jeśli pomyślnie dotrze do stanu końcowego, wtedy masz te konkretne znaczniki w prawidłowej kolejności.
Skończone maszyny stanów mogą być również używane do reprezentowania wielu innych systemów – takich jak mechanika parkometru, automatu do sprzedaży napojów, automatycznej pompy benzynowej i wielu innych rzeczy.
Deterministyczne skończone maszyny stanów
Maszyny stanów, którym przyglądaliśmy się do tej pory, są deterministycznymi maszynami stanów. Z dowolnego stanu, istnieje tylko jedno przejście dla dowolnego dozwolonego wejścia. Innymi słowy, nie mogą istnieć dwie ścieżki prowadzące ze stanu, w którym czytamy literę 'a'. Na początku brzmi to głupio, że w ogóle dokonujemy takiego rozróżnienia.
Co dobrego jest w zestawie decyzji, jeśli to samo wejście może spowodować przejście do więcej niż jednego stanu? Nie możesz powiedzieć komputerowi, if x == true następnie wykonaj doSomethingBig lub wykonaj doSomethingSmall, możesz?
Cóż, możesz tak jakby z maszyną stanów.
Wyjściem maszyny stanów jest jej stan końcowy. Przechodzi przez wszystkie swoje przetwarzanie, a następnie stan końcowy jest odczytywany, a następnie podejmowane jest działanie. Maszyna stanowa nie robi nic, gdy przechodzi ze stanu do stanu.
Przetwarza, a gdy dochodzi do końca, stan jest odczytywany i coś zewnętrznego wyzwala pożądaną akcję (na przykład wydanie puszki z napojem). Jest to ważna koncepcja, jeśli chodzi o niedeterministyczne maszyny stanów skończonych.
Niedeterministyczne maszyny stanów skończonych
Niedeterministyczne maszyny stanów skończonych to maszyny stanów skończonych, w których dane wejściowe z danego stanu mogą prowadzić do więcej niż jednego innego stanu.
Na przykład, powiedzmy, że chcemy zbudować maszynę stanów skończonych, która potrafi rozpoznawać ciągi liter, które:
- Zaczynają się literą 'a'
- i następuje po nich zero lub więcej wystąpień litery 'b'
- lub, zero lub więcej wystąpień litery 'c'
- kończą się następną literą alfabetu.
Prawidłowe ciągi byłyby:
- abbbbbbbc
- abbbc
- acccd
- acccd
- ac (zero wystąpień b)
- ad (zero wystąpień c)
Więc rozpozna literę 'a', po której następuje zero lub więcej takich samych liter 'b' lub 'c', a następnie następną literę alfabetu.
Bardzo prostym sposobem na przedstawienie tego jest maszyna stanów, która wygląda jak ta poniżej, gdzie końcowy stan t oznacza, że łańcuch został zaakceptowany i pasuje do wzorca.
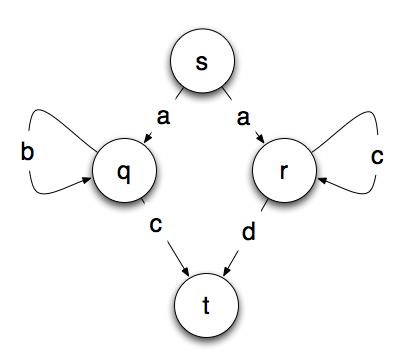
Widzisz problem? Od punktu startowego s nie wiemy, jaką ścieżkę wybrać. Jeśli czytamy literę 'a', to nie wiemy czy przejść do stanu q czy r.
Jest kilka sposobów na rozwiązanie tego problemu. Jednym z nich jest backtracking. Po prostu bierzesz wszystkie możliwe ścieżki i ignorujesz lub wycofujesz się z tych, w których utknąłeś.
To jest w zasadzie sposób, w jaki działa większość komputerów grających w szachy. Patrzą na wszystkie możliwości – i wszystkie możliwości tych możliwości – i wybierają ścieżkę, która daje im największą liczbę przewag nad przeciwnikiem.
Drugą opcją jest przekształcenie niedeterministycznej maszyny w maszynę deterministyczną.
Jedną z interesujących cech maszyny niedeterministycznej jest to, że istnieje algorytm pozwalający przekształcić dowolną maszynę niedeterministyczną w deterministyczną. Jednak często jest to o wiele bardziej skomplikowane.
Na szczęście dla nas, powyższy przykład jest tylko trochę bardziej skomplikowany. W rzeczywistości jest on na tyle prosty, że możemy go przekształcić w maszynę deterministyczną w naszej głowie, bez pomocy formalnego algorytmu.
Poniższa maszyna jest deterministyczną wersją powyższej maszyny niedeterministycznej. W poniższej maszynie stan końcowy t lub v jest osiągany przez dowolny łańcuch, który jest akceptowany przez maszynę.
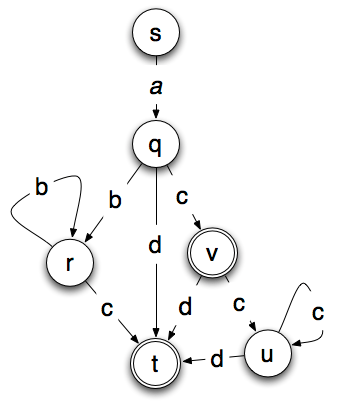
Model niedeterministyczny ma cztery stany i sześć przejść. Model deterministyczny ma sześć stanów, dziesięć przejść i dwa możliwe stany końcowe.
To nie jest dużo więcej, ale złożoność zwykle rośnie wykładniczo. Umiarkowanie duża maszyna niedeterministyczna może stworzyć absolutnie ogromną maszynę deterministyczną.
Wyrażenia regularne
Jeśli zajmowałeś się programowaniem, prawdopodobnie spotkałeś się z wyrażeniami regularnymi. Wyrażenia regularne i maszyny stanów skończonych są funkcjonalnie równoważne. Wszystko, co można zaakceptować lub dopasować za pomocą wyrażenia regularnego, może zostać zaakceptowane lub dopasowane za pomocą maszyny stanów.
Na przykład, wzór opisany powyżej może zostać dopasowany za pomocą wyrażenia regularnego: a(b*c|c*d)
Wyrażenia regularne i skończone maszyny stanów mają również te same ograniczenia. W szczególności, oba mogą tylko dopasować lub zaakceptować wzorce, które mogą być obsługiwane z skończoną pamięcią.
Jakiego więc typu wzorców nie mogą dopasować? Powiedzmy, że chcesz dopasować tylko ciągi 'a' i 'b', gdzie jest pewna liczba 'a', po których następuje równa liczba 'b'. Lub n 'a’s, po których następuje n 'b’s, gdzie n jest jakąś liczbą.
Przykładami mogą być:
- ab
- aabb
- aaaaaabbbbbb
- aaaaaaaaaaaaaaaabbbbbbbbbbbbbb
Na początku wygląda to na łatwe zadanie dla maszyny stanów skończonych. Problem w tym, że szybko skończą się stany, albo będziesz musiał założyć nieskończoną liczbę stanów – w tym momencie nie będzie to już skończona maszyna stanowa.
Powiedzmy, że stworzyłeś skończoną maszynę stanów, która może przyjąć do 20 'a', po których następuje 20 'b'. To działa dobrze, dopóki nie otrzymasz ciągu 21 'a', po którym następuje 21 'b' – w tym momencie będziesz musiał przepisać maszynę, aby obsłużyć dłuższy ciąg.
Dla każdego ciągu, który możesz rozpoznać, istnieje jeden tylko trochę dłuższy, którego twoja maszyna nie może rozpoznać, ponieważ zabraknie jej pamięci.
Jest to znane jako Lemmat Pompowania, który w zasadzie mówi: „jeśli twój wzorzec ma sekcję, która może być powtórzona (jak ta) powyżej, to wzorzec nie jest regularny”.
Innymi słowy, ani wyrażenie regularne, ani maszyna stanów skończonych nie mogą być skonstruowane tak, aby rozpoznać wszystkie ciągi, które pasują do wzorca.
Jeśli przyjrzysz się uważnie, zauważysz, że ten typ wzorca, gdzie każde 'a' ma pasujące 'b', wygląda bardzo podobnie do HTML. W obrębie każdej pary znaczników, możesz mieć dowolną liczbę innych pasujących par znaczników.
Więc, podczas gdy możesz być w stanie użyć wyrażenia regularnego lub maszyny stanów skończonych, aby rozpoznać, czy strona HTML ma <html>, <head>; i <body> elementy w odpowiedniej kolejności, nie można użyć wyrażenia regularnego, aby stwierdzić, czy cała strona HTML jest poprawna, czy nie – ponieważ HTML nie jest wzorcem regularnym.
Maszyny Turinga
Jak więc rozpoznać nieregularne wzorce?
Istnieje teoretyczne urządzenie, które jest podobne do maszyny stanów, zwane maszyną Turinga. Jest ona podobna do maszyny stanów w tym sensie, że posiada pasek papieru, który czyta. Ale maszyna Turinga może wymazywać i pisać na papierowej taśmie.
Wyjaśnienie maszyny Turinga zajmie więcej miejsca niż mamy tutaj, ale jest kilka ważnych punktów istotnych dla naszej dyskusji o maszynach stanów skończonych i wyrażeniach regularnych.
Maszyny Turinga są obliczeniowo kompletne – co oznacza, że wszystko, co może być obliczone, może być obliczone na maszynie Turinga.
Ponieważ maszyna Turinga może zarówno pisać, jak i czytać z taśmy papierowej, nie jest ona ograniczona do skończonej liczby stanów. Można założyć, że taśma papierowa ma nieskończoną długość. Oczywiście, rzeczywiste komputery nie mają nieskończonej ilości pamięci. Ale zazwyczaj zawierają wystarczającą ilość pamięci, aby nie przekroczyć limitu dla problemów, które przetwarzają.
Maszyny Turinga dają nam wyobrażenie mechanicznego urządzenia, które pozwala nam zwizualizować i zrozumieć, jak działa proces obliczeniowy. Jest to szczególnie przydatne w zrozumieniu granic obliczeń. Jeśli będzie zainteresowanie, zrobię kolejny artykuł o maszynach Turinga w przyszłości.
Dlaczego to ma znaczenie?
Więc, o co chodzi? Jak to pomoże Ci stworzyć następny formularz w PHP?
Niezależnie od swoich ograniczeń, maszyny stanów są bardzo centralnym pojęciem w informatyce. W szczególności, istotne jest to, że dla każdej niedeterministycznej maszyny stanów, którą możesz zaprojektować, istnieje deterministyczna maszyna stanów, która robi to samo.
Jest to kluczowy punkt, ponieważ oznacza to, że możesz zaprojektować swój algorytm w dowolny sposób, który jest najłatwiejszy do przemyślenia. Kiedy masz już działający algorytm, możesz przekształcić go w dowolną formę, która jest najbardziej wydajna.
Zrozumienie, że maszyny stanów skończonych i wyrażenia regularne są funkcjonalnie równoważne, otwiera kilka niezwykle interesujących zastosowań dla silników wyrażeń regularnych – szczególnie jeśli chodzi o tworzenie reguł biznesowych, które można zmieniać bez rekompilacji systemu.
Podstawa w informatyce pozwala ci na rozwiązanie problemu, którego nie znasz i stwierdzenie: „Nie wiem, jak rozwiązać X, ale wiem, jak rozwiązać Y. I wiem, jak przekształcić rozwiązanie Y w rozwiązanie X. Dlatego teraz wiem, jak rozwiązać X.”
Jeśli spodobał ci się ten artykuł, możesz polubić mój kanał na YouTube, gdzie tworzę okazjonalne filmy lub kreskówki na temat jakiegoś aspektu tworzenia oprogramowania. Mam również listę mailingową dla ludzi, którzy chcieliby okazjonalnego e-maila, gdy produkuję coś nowego.
Oryginalnie opublikowane na blog.markshead.com w dniu 11 lutego 2018 r.
.