Last Updated on July 13, 2020
Die Informationstheorie ist ein Teilgebiet der Mathematik, das sich mit der Übertragung von Daten über einen verrauschten Kanal beschäftigt.
Ein Eckpfeiler der Informationstheorie ist die Idee, zu quantifizieren, wie viel Information in einer Nachricht steckt. Allgemeiner ausgedrückt, kann damit die Information in einem Ereignis und einer Zufallsvariablen quantifiziert werden, die Entropie genannt wird und mit Hilfe der Wahrscheinlichkeitsrechnung berechnet wird.
Die Berechnung von Information und Entropie ist ein nützliches Werkzeug beim maschinellen Lernen und wird als Grundlage für Techniken wie die Auswahl von Merkmalen, die Erstellung von Entscheidungsbäumen und, allgemeiner, die Anpassung von Klassifikationsmodellen verwendet. Als solcher benötigt ein Praktiker des maschinellen Lernens ein starkes Verständnis und Gespür für Information und Entropie.
In diesem Beitrag finden Sie eine sanfte Einführung in die Informationsentropie.
Nach der Lektüre dieses Beitrags wissen Sie:
- Die Informationstheorie beschäftigt sich mit der Datenkompression und -übertragung und baut auf der Wahrscheinlichkeit auf und unterstützt das maschinelle Lernen.
- Information bietet eine Möglichkeit, die Menge an Überraschung für ein Ereignis, gemessen in Bits, zu quantifizieren.
- Entropie bietet ein Maß für die durchschnittliche Menge an Information, die benötigt wird, um ein Ereignis aus einer Wahrscheinlichkeitsverteilung für eine Zufallsvariable darzustellen.
Starten Sie Ihr Projekt mit meinem neuen Buch Probability for Machine Learning, inklusive Schritt-für-Schritt-Tutorials und den Python-Quellcode-Dateien für alle Beispiele.
Lassen Sie uns loslegen.
- Update Nov/2019: Beispiel für Wahrscheinlichkeit vs. Information und mehr zur Intuition für Entropie hinzugefügt.

Eine sanfte Einführung in die Informationsentropie
Photo by Cristiano Medeiros Dalbem, some rights reserved.
Übersicht
Dieses Tutorial ist in drei Teile gegliedert; sie sind:
- Was ist Informationstheorie?
- Berechnen Sie die Information für ein Ereignis
- Berechnen Sie die Entropie für eine Zufallsvariable
Was ist Informationstheorie?
Die Informationstheorie ist ein Fachgebiet, das sich mit der Quantifizierung von Informationen für die Kommunikation beschäftigt.
Sie ist ein Teilgebiet der Mathematik und beschäftigt sich mit Themen wie Datenkompression und den Grenzen der Signalverarbeitung. Das Gebiet wurde von Claude Shannon während seiner Arbeit bei der US-Telefongesellschaft Bell Labs vorgeschlagen und entwickelt.
Die Informationstheorie befasst sich mit der kompakten Darstellung von Daten (eine Aufgabe, die als Datenkompression oder Quellencodierung bekannt ist) sowie mit der fehlerrobusten Übertragung und Speicherung dieser Daten (eine Aufgabe, die als Fehlerkorrektur oder Kanalcodierung bekannt ist).
– Seite 56, Machine Learning: A Probabilistic Perspective, 2012.
Ein grundlegendes Konzept aus der Informationstheorie ist die Quantifizierung der Informationsmenge in Dingen wie Ereignissen, Zufallsvariablen und Verteilungen.
Die Quantifizierung der Informationsmenge erfordert die Verwendung von Wahrscheinlichkeiten, daher die Beziehung der Informationstheorie zur Wahrscheinlichkeit.
Messungen der Information werden häufig in der künstlichen Intelligenz und dem maschinellen Lernen verwendet, wie z.B. bei der Konstruktion von Entscheidungsbäumen und der Optimierung von Klassifizierungsmodellen.
Als solches gibt es eine wichtige Beziehung zwischen der Informationstheorie und dem maschinellen Lernen, und ein Praktiker muss mit einigen der grundlegenden Konzepte aus dem Bereich vertraut sein.
Warum die Informationstheorie und das maschinelle Lernen vereinen? Weil sie zwei Seiten der gleichen Medaille sind. Informationstheorie und maschinelles Lernen gehören doch zusammen. Gehirne sind die ultimativen Kompressions- und Kommunikationssysteme. Und die modernsten Algorithmen für Datenkompression und fehlerkorrigierende Codes verwenden die gleichen Werkzeuge wie das maschinelle Lernen.
– Page v, Information Theory, Inference, and Learning Algorithms, 2003.
Willst du Wahrscheinlichkeitsrechnung für maschinelles Lernen lernen
Nimm jetzt meinen kostenlosen 7-Tage-E-Mail-Crashkurs (mit Beispielcode).
Klicken Sie hier, um sich anzumelden und eine kostenlose PDF-Ebook-Version des Kurses zu erhalten.
Laden Sie sich Ihren KOSTENLOSEN Mini-Kurs herunter
Berechnen Sie die Information für ein Ereignis
Die Quantifizierung von Informationen ist die Grundlage des Fachgebiets der Informationstheorie.
Die Intuition hinter der Quantifizierung von Information ist die Idee, zu messen, wie viel Überraschung in einem Ereignis steckt. Diejenigen Ereignisse, die selten sind (niedrige Wahrscheinlichkeit), sind überraschender und haben daher mehr Information als die Ereignisse, die häufig sind (hohe Wahrscheinlichkeit).
- Ereignis mit niedriger Wahrscheinlichkeit: Hohe Information (überraschend).
- Ereignis mit hoher Wahrscheinlichkeit: Niedrige Information (nicht überraschend).
Die grundlegende Intuition hinter der Informationstheorie ist, dass die Erkenntnis, dass ein unwahrscheinliches Ereignis eingetreten ist, informativer ist als die Erkenntnis, dass ein wahrscheinliches Ereignis eingetreten ist.
– Seite 73, Deep Learning, 2016.
Seltene Ereignisse sind unsicherer oder überraschender und erfordern mehr Informationen, um sie zu repräsentieren, als gewöhnliche Ereignisse.
Wir können die Menge an Informationen, die in einem Ereignis steckt, anhand der Wahrscheinlichkeit des Ereignisses berechnen. Dies wird als „Shannon-Information“, „Selbstinformation“ oder einfach als „Information“ bezeichnet und kann für ein diskretes Ereignis x wie folgt berechnet werden:
- Information(x) = -log( p(x) )
Wobei log() der Logarithmus zur Basis 2 ist und p(x) die Wahrscheinlichkeit des Ereignisses x ist.
Die Wahl des Basis-2-Logarithmus bedeutet, dass die Einheiten des Informationsmaßes in Bits (Binärziffern) angegeben werden. Dies kann im Sinne der Informationsverarbeitung direkt als die Anzahl der Bits interpretiert werden, die benötigt werden, um das Ereignis darzustellen.
Die Berechnung der Information wird oft als h() geschrieben; zum Beispiel:
- h(x) = -log( p(x) )
Das negative Vorzeichen stellt sicher, dass das Ergebnis immer positiv oder Null ist.
Die Information wird Null, wenn die Wahrscheinlichkeit eines Ereignisses 1,0 oder eine Gewissheit ist, d.h. es gibt keine Überraschung.
Lassen Sie uns dies anhand einiger Beispiele konkretisieren.
Betrachten Sie den Wurf einer einzelnen fairen Münze. Die Wahrscheinlichkeit für Kopf (und Zahl) ist 0,5. Wir können die Information für das Werfen von Kopf in Python mit der Funktion log2() berechnen.
|
1
2
3
4
5
6
7
8
|
# Berechnung der Information für einen Münzwurf
from math import log2
# Wahrscheinlichkeit des Ereignisses
p = 0.5
# Information für Ereignis berechnen
h = -log2(p)
# Ergebnis ausgeben
print(‚p(x)=%.3f, Information: %.3f bits‘ % (p, h))
|
Das Ausführen des Beispiels gibt die Wahrscheinlichkeit des Ereignisses als 50% und den Informationsgehalt für das Ereignis als 1 Bit aus.
|
1
|
p(x)=0.500, Informationen: 1.000 Bits
|
Wenn die gleiche Münze n-mal geworfen würde, dann wäre die Information für diese Folge von Würfen n Bits.
Wenn die Münze nicht fair wäre und die Wahrscheinlichkeit eines Kopfes stattdessen 10 % (0,1) betragen würde, dann wäre das Ereignis seltener und würde mehr als 3 Bits an Information erfordern.
|
1
|
p(x)=0.100, Informationen: 3,322 Bits
|
Wir können auch die Information in einem einzelnen Wurf eines fairen sechsseitigen Würfels untersuchen, z. B. die Information im Wurf einer 6.
Wir wissen, dass die Wahrscheinlichkeit, eine beliebige Zahl zu würfeln, 1/6 ist, was eine kleinere Zahl als 1/2 für einen Münzwurf ist, daher würden wir mehr Überraschung oder eine größere Menge an Information erwarten.
|
1
2
3
4
5
6
7
8
|
# Berechnung der Information für einen Würfelwurf
from math import log2
# Wahrscheinlichkeit des Ereignisses
p = 1.0 / 6.0
# Information für Ereignis berechnen
h = -log2(p)
# Ergebnis ausdrucken
print(‚p(x)=%.3f, Information: %.3f bits‘ % (p, h))
|
Wenn wir das Beispiel ausführen, können wir sehen, dass unsere Intuition richtig ist und dass tatsächlich mehr als 2,5 Bits an Informationen in einem einzigen Wurf eines fairen Würfels stecken.
|
1
|
p(x)=0.167, Information: 2,585 Bit
|
Anstelle der Basis-2 können auch andere Logarithmen verwendet werden. Zum Beispiel ist es auch üblich, den natürlichen Logarithmus zu verwenden, der die Basis-e (Eulersche Zahl) bei der Berechnung der Information verwendet; in diesem Fall werden die Einheiten als „nats“ bezeichnet.
Wir können die Intuition weiterentwickeln, dass Ereignisse mit geringer Wahrscheinlichkeit mehr Information haben.
Um dies zu verdeutlichen, können wir die Information für Wahrscheinlichkeiten zwischen 0 und 1 berechnen und die entsprechende Information für jede darstellen. Wir können dann ein Diagramm von Wahrscheinlichkeit gegen Information erstellen. Wir würden erwarten, dass die Kurve von niedrigen Wahrscheinlichkeiten mit hoher Information zu hohen Wahrscheinlichkeiten mit niedriger Information abwärts verläuft.
Das vollständige Beispiel ist unten aufgeführt.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# Vergleich Wahrscheinlichkeit vs. Informationsentropie
from math import log2
from matplotlib import pyplot
# Liste der Wahrscheinlichkeiten
probs =
# Information berechnen
info =
# Wahrscheinlichkeit vs. Information darstellen
pyplot.plot(probs, info, marker=‘.‘)
pyplot.title(‚Probability vs Information‘)
pyplot.xlabel(‚Probability‘)
pyplot.ylabel(‚Information‘)
pyplot.show()
|
Das Ausführen des Beispiels erzeugt die Darstellung der Wahrscheinlichkeit gegenüber der Information in Bits.
Wir sehen die erwartete Beziehung, bei der Ereignisse mit geringer Wahrscheinlichkeit überraschender sind und mehr Informationen enthalten, während das Komplement von Ereignissen mit hoher Wahrscheinlichkeit weniger Informationen enthält.
Wir sehen auch, dass diese Beziehung nicht linear ist, sondern sogar leicht sublinear ist. Das macht Sinn, wenn man die Logarithmusfunktion verwendet.
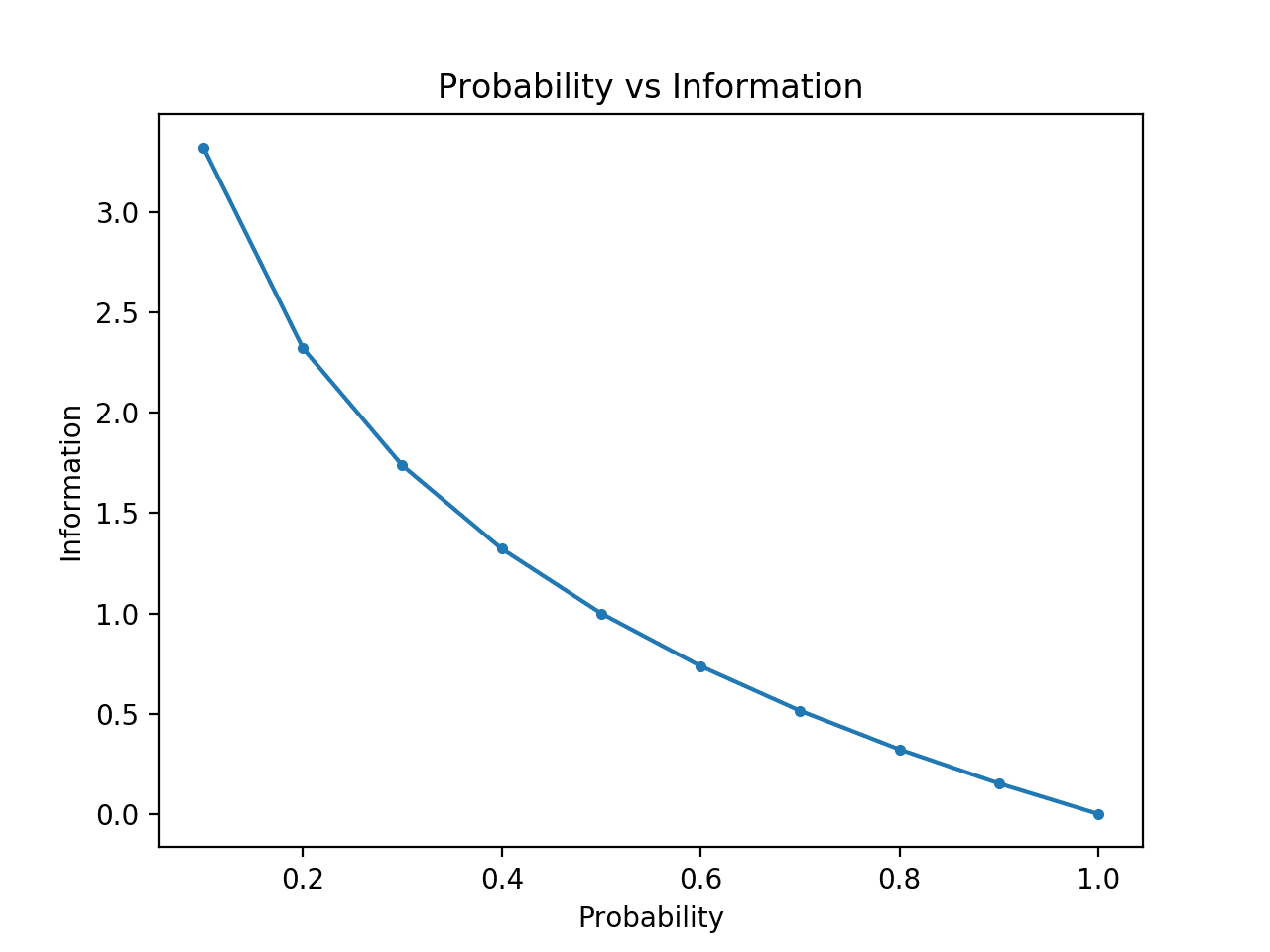
Darstellung der Wahrscheinlichkeit im Vergleich zur Information
Berechnen Sie die Entropie für eine Zufallsvariable
Wir können auch quantifizieren, wie viel Information in einer Zufallsvariablen steckt.
Wenn wir z. B. die Information für eine Zufallsvariable X mit der Wahrscheinlichkeitsverteilung p berechnen wollen, könnte dies als Funktion H() geschrieben werden; z. B.:
- H(X)
In der Tat ist die Berechnung der Information für eine Zufallsvariable dasselbe wie die Berechnung der Information für die Wahrscheinlichkeitsverteilung der Ereignisse für die Zufallsvariable.
Die Berechnung der Information für eine Zufallsvariable wird „Informationsentropie“, „Shannon-Entropie“ oder einfach „Entropie“ genannt. Sie ist mit der Idee der Entropie aus der Physik analog verwandt, da sich beide mit Unsicherheit beschäftigen.
Die Intuition für die Entropie ist, dass sie die durchschnittliche Anzahl von Bits ist, die benötigt wird, um ein Ereignis aus der Wahrscheinlichkeitsverteilung für die Zufallsvariable darzustellen oder zu übertragen.
… die Shannon-Entropie einer Verteilung ist die erwartete Menge an Informationen in einem Ereignis, das aus dieser Verteilung gezogen wird. Sie gibt eine untere Schranke für die Anzahl der Bits an, die im Durchschnitt benötigt werden, um Symbole aus einer Verteilung P zu kodieren.
– Seite 74, Deep Learning, 2016.
Die Entropie kann für eine Zufallsvariable X mit k in K diskreten Zuständen wie folgt berechnet werden:
- H(X) = -sum(jedes k in K p(k) * log(p(k)))
Das ist das Negativ der Summe der Wahrscheinlichkeit jedes Ereignisses multipliziert mit dem Log der Wahrscheinlichkeit jedes Ereignisses.
Wie bei der Information verwendet die Funktion log() die Basis-2 und die Einheiten sind Bits. Stattdessen kann ein natürlicher Logarithmus verwendet werden und die Einheiten sind nats.
Die niedrigste Entropie wird für eine Zufallsvariable berechnet, die ein einzelnes Ereignis mit einer Wahrscheinlichkeit von 1,0, also einer Gewissheit, hat. Die größte Entropie für eine Zufallsvariable ist, wenn alle Ereignisse gleich wahrscheinlich sind.
Wir können einen Wurf eines fairen Würfels betrachten und die Entropie für die Variable berechnen. Jedes Ergebnis hat die gleiche Wahrscheinlichkeit von 1/6, es handelt sich also um eine gleichmäßige Wahrscheinlichkeitsverteilung. Wir würden daher erwarten, dass die durchschnittliche Information dieselbe Information für ein einzelnes Ereignis ist, die im vorherigen Abschnitt berechnet wurde.
|
1
2
3
4
5
6
7
8
9
10
|
# Berechnung der Entropie für einen Würfel Wurf
from math import log2
# die Anzahl der Ereignisse
n = 6
# die Wahrscheinlichkeit eines Ereignisses
p = 1.0 /n
# Entropie berechnen
Entropie = -sum()
# Ergebnis drucken
print(‚Entropie: %.3f bits‘ % entropy)
|
Bei der Ausführung des Beispiels wird die Entropie mit mehr als 2,5 Bits berechnet, was der Information für einen einzelnen Ausgang entspricht. Das macht Sinn, da die durchschnittliche Information gleich der unteren Grenze der Information ist, da alle Ergebnisse gleich wahrscheinlich sind.
|
1
|
Entropie: 2.585 Bits
|
Wenn wir die Wahrscheinlichkeit für jedes Ereignis kennen, können wir die SciPy-Funktion entropy() verwenden, um die Entropie direkt zu berechnen.
Beispielsweise:
|
1
2
3
4
5
6
7
8
|
# Berechne die Entropie für einen Würfelwurf
from scipy.stats import entropy
# diskrete Wahrscheinlichkeiten
p =
# Entropie berechnen
e = entropy(p, base=2)
# das Ergebnis drucken
print(‚entropy: %.3f bits‘ % e)
|
Das Ausführen des Beispiels liefert das gleiche Ergebnis, das wir manuell berechnet haben.
|
1
|
Entropie: 2.585 Bits
|
Wir können die Intuition für die Entropie von Wahrscheinlichkeitsverteilungen weiterentwickeln.
Erinnern Sie sich daran, dass die Entropie die Anzahl der Bits ist, die benötigt wird, um ein zufällig gezogenes gleichmäßiges Ereignis aus der Verteilung darzustellen, z. B. ein durchschnittliches Ereignis. Wir können dies für eine einfache Verteilung mit zwei Ereignissen, wie z. B. einem Münzwurf, untersuchen, aber unterschiedliche Wahrscheinlichkeiten für diese beiden Ereignisse untersuchen und die Entropie für jedes berechnen.
In dem Fall, in dem ein Ereignis dominiert, wie z. B. bei einer schiefen Wahrscheinlichkeitsverteilung, dann gibt es weniger Überraschung und die Verteilung wird eine niedrigere Entropie haben. In dem Fall, in dem kein Ereignis ein anderes dominiert, wie z. B. bei einer gleichen oder annähernd gleichen Wahrscheinlichkeitsverteilung, dann würden wir eine größere oder maximale Entropie erwarten.
- Schiefe Wahrscheinlichkeitsverteilung (nicht überraschend): Niedrige Entropie.
- Ausgeglichene Wahrscheinlichkeitsverteilung (überraschend): Hohe Entropie.
Wenn wir von einer schiefen zu einer gleichen Wahrscheinlichkeit der Ereignisse in der Verteilung übergehen, würden wir erwarten, dass die Entropie niedrig beginnt und ansteigt, und zwar von der niedrigsten Entropie von 0.0 für Ereignisse mit Unmöglichkeit/Gewissheit (Wahrscheinlichkeit von 0 bzw. 1) bis zur größten Entropie von 1,0 für Ereignisse mit gleicher Wahrscheinlichkeit.
Das folgende Beispiel implementiert dies, indem es jede Wahrscheinlichkeitsverteilung in diesem Übergang erstellt, die Entropie für jede berechnet und das Ergebnis aufzeichnet.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# Wahrscheinlichkeitsverteilungen vs. Entropie vergleichen
from math import log2
from matplotlib import pyplot
# Entropie berechnen
def entropy(events, ets=1e-15):
return -sum()
# Wahrscheinlichkeiten definieren
probs =
# Wahrscheinlichkeitsverteilung erstellen
dists = for p in probs]
# Entropie für jede Verteilung berechnen
ents =
# Wahrscheinlichkeitsverteilung gegen Entropie darstellen
pyplot.plot(probs, ents, marker=‘.‘)
pyplot.title(‚Wahrscheinlichkeitsverteilung vs. Entropie‘)
pyplot.xticks(probs, )
pyplot.xlabel(‚Wahrscheinlichkeitsverteilung‘)
pyplot.ylabel(‚Entropie (Bits)‘)
pyplot.show()
|
Das Ausführen des Beispiels erzeugt die 6 Wahrscheinlichkeitsverteilungen mit Wahrscheinlichkeiten bis hin zu Wahrscheinlichkeiten.
Wie erwartet, können wir sehen, dass die Entropie von minimalen zu maximalen Werten ansteigt, wenn die Verteilung der Ereignisse von schief zu ausgeglichen wechselt.
Das heißt, wenn das durchschnittliche Ereignis, das aus einer Wahrscheinlichkeitsverteilung gezogen wird, nicht überraschend ist, erhalten wir eine niedrigere Entropie, während wir, wenn es überraschend ist, eine größere Entropie erhalten.
Wir können sehen, dass der Übergang nicht linear ist, sondern superlinear. Wir können auch sehen, dass diese Kurve symmetrisch ist, wenn wir den Übergang nach und nach für die beiden Ereignisse fortsetzen, so dass eine umgekehrte Parabelform entsteht.
Beachten Sie, dass wir bei der Berechnung der Entropie einen winzigen Wert zur Wahrscheinlichkeit hinzufügen mussten, um zu vermeiden, dass der Logarithmus eines Nullwerts berechnet wird, was zu einer Unendlichkeit auf nicht einer Zahl führen würde.
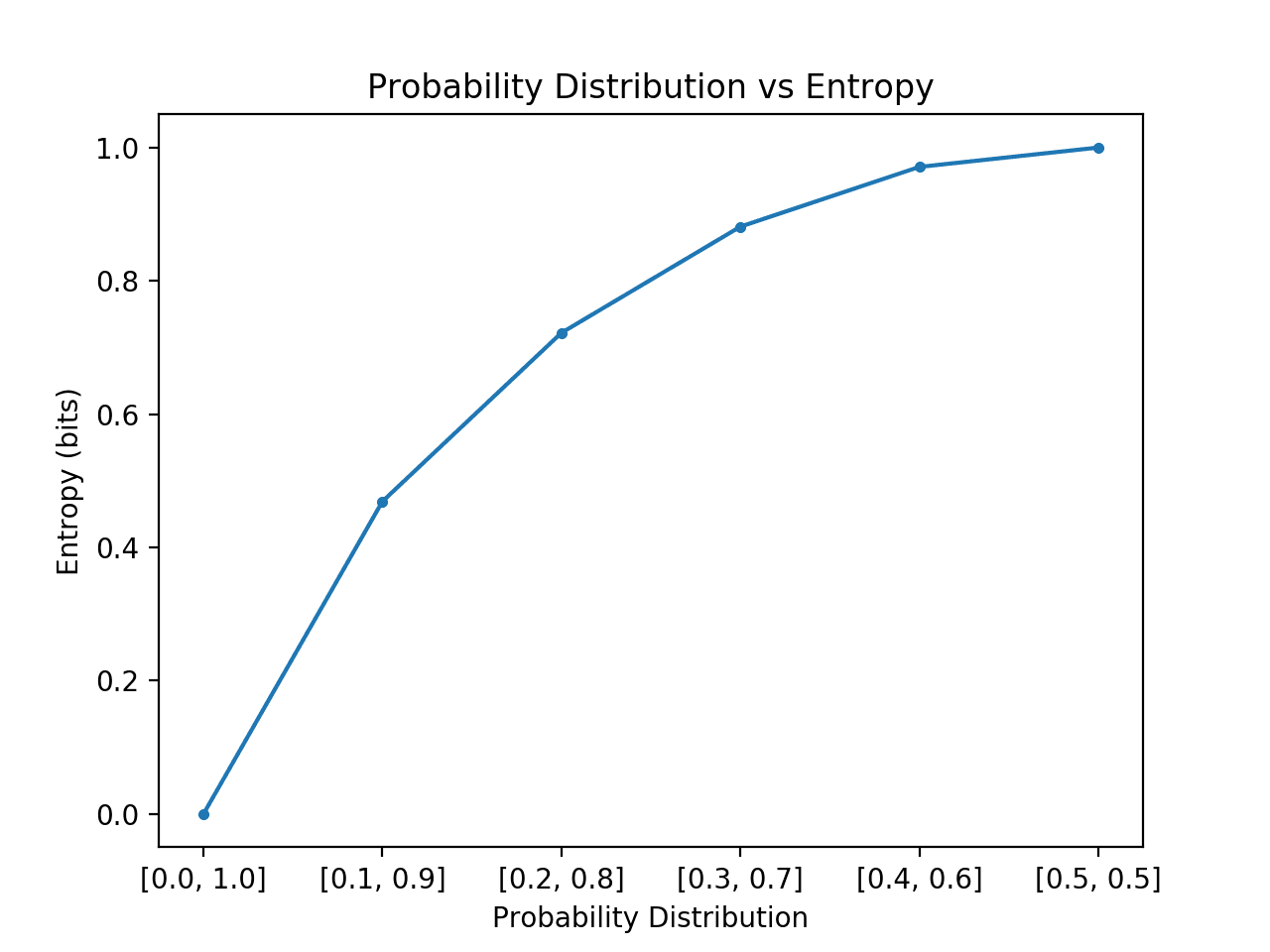
Diagramm der Wahrscheinlichkeitsverteilung im Vergleich zur Entropie
Die Berechnung der Entropie für eine Zufallsvariable liefert die Grundlage für andere Maße wie die gegenseitige Information (Informationsgewinn).
Die Entropie liefert auch die Grundlage für die Berechnung der Differenz zwischen zwei Wahrscheinlichkeitsverteilungen mit der Kreuzentropie und der KL-Divergenz.
Weitere Lektüre
In diesem Abschnitt finden Sie weitere Ressourcen zum Thema, wenn Sie tiefer einsteigen möchten.
Bücher
- Information Theory, Inference, and Learning Algorithms, 2003.
Kapitel
- Abschnitt 2.8: Informationstheorie, Maschinelles Lernen: A Probabilistic Perspective, 2012.
- Abschnitt 1.6: Informationstheorie, Pattern Recognition and Machine Learning, 2006.
- Abschnitt 3.13: Informationstheorie, Deep Learning, 2016.
API
- scipy.stats.entropy API
Artikel
- Entropie (Informationstheorie), Wikipedia.
- Informationsgewinn in Entscheidungsbäumen, Wikipedia.
- Informationsgewinnverhältnis, Wikipedia.
Zusammenfassung
In diesem Beitrag haben Sie eine sanfte Einführung in die Informationsentropie kennengelernt.
Speziell haben Sie gelernt:
- Die Informationstheorie befasst sich mit der Komprimierung und Übertragung von Daten und baut auf der Wahrscheinlichkeit auf und unterstützt das maschinelle Lernen.
- Die Informationstheorie bietet eine Möglichkeit, die Menge der Überraschung für ein Ereignis, gemessen in Bits, zu quantifizieren.
- Entropie liefert ein Maß für die durchschnittliche Informationsmenge, die benötigt wird, um ein Ereignis aus einer Wahrscheinlichkeitsverteilung für eine Zufallsvariable darzustellen.
Haben Sie noch Fragen?
Stellen Sie Ihre Fragen in den Kommentaren unten und ich werde mein Bestes tun, um sie zu beantworten.
Get a Handle on Probability for Machine Learning!

Entwickeln Sie Ihr Verständnis für Wahrscheinlichkeit
…mit nur ein paar Zeilen Python-Code
Entdecken Sie in meinem neuen Ebook:
Probability for Machine Learning
Es bietet Selbstlern-Tutorials und durchgängige Projekte zu:
Bayes-Theorem, Bayes’sche Optimierung, Verteilungen, Maximum Likelihood, Cross-Entropie, Kalibrierung von Modellen
und vielem mehr….
Nutzen Sie endlich die Unsicherheit in Ihren Projekten
Überspringen Sie die akademische Seite. Just Results.See What’s Inside