SPSS Statistics
Interpretieren und Berichten der Ausgabe einer binomialen logistischen Regressionsanalyse
SPSS Statistics generiert bei der Durchführung einer binomialen logistischen Regression viele Ausgabetabellen. In diesem Abschnitt zeigen wir Ihnen nur die drei wichtigsten Tabellen, die zum Verständnis Ihrer Ergebnisse aus der binomialen logistischen Regression erforderlich sind, unter der Annahme, dass keine Annahmen verletzt worden sind. Eine vollständige Erklärung der Ausgabe, die Sie interpretieren müssen, wenn Sie Ihre Daten auf die für die Durchführung der binomialen logistischen Regression erforderlichen Annahmen überprüfen, finden Sie in unserem erweiterten Handbuch.
In dieser „Schnellstart“-Anleitung konzentrieren wir uns jedoch nur auf die drei Haupttabellen, die Sie benötigen, um Ihre Ergebnisse der binomialen logistischen Regression zu verstehen, wobei wir davon ausgehen, dass Ihre Daten bereits die Annahmen erfüllen, die für die binomiale logistische Regression erforderlich sind, um ein gültiges Ergebnis zu erhalten:
Erklärte Varianz
Um zu verstehen, wie viel Variation in der abhängigen Variable durch das Modell erklärt werden kann (das Äquivalent von R2 in der multiplen Regression), können Sie die folgende Tabelle „Modellzusammenfassung“ zu Rate ziehen:
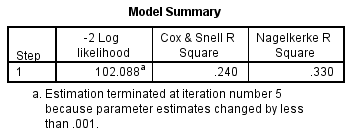
Diese Tabelle enthält die Cox & Snell R-Square und Nagelkerke R-Square Werte, die beide Methoden zur Berechnung der erklärten Variation sind. Diese Werte werden manchmal auch als Pseudo-R2-Werte bezeichnet (und werden niedrigere Werte als bei der multiplen Regression haben). Sie werden jedoch auf die gleiche Weise interpretiert, jedoch mit mehr Vorsicht. Daher liegt die erklärte Variation der abhängigen Variable auf der Basis unseres Modells zwischen 24,0 % und 33,0 %, je nachdem, ob Sie die Cox & Snell R2- oder die Nagelkerke R2-Methode verwenden. Nagelkerke R2 ist eine Modifikation von Cox & Snell R2, wobei letzteres keinen Wert von 1 erreichen kann. Aus diesem Grund ist es vorzuziehen, den Nagelkerke R2-Wert anzugeben.
Kategorievorhersage
Die binomiale logistische Regression schätzt die Wahrscheinlichkeit, dass ein Ereignis (in diesem Fall eine Herzerkrankung) eintritt. Wenn die geschätzte Wahrscheinlichkeit für das Auftreten des Ereignisses größer oder gleich 0,5 ist (besser als der Zufall), stuft SPSS Statistics das Ereignis als eingetreten ein (z. B. das Vorliegen einer Herzerkrankung). Wenn die Wahrscheinlichkeit kleiner als 0,5 ist, stuft SPSS Statistics das Ereignis als nicht eingetreten ein (z. B. keine Herzerkrankung). Es ist sehr üblich, die binomiale logistische Regression zu verwenden, um vorherzusagen, ob die Fälle aus den unabhängigen Variablen korrekt klassifiziert (d. h. vorhergesagt) werden können. Daher ist es notwendig, eine Methode zu haben, um die Effektivität der vorhergesagten Klassifikation gegenüber der tatsächlichen Klassifikation zu bewerten. Es gibt viele Methoden, um dies zu beurteilen, wobei ihre Nützlichkeit oft von der Art der durchgeführten Studie abhängt. Alle Methoden drehen sich jedoch um die beobachteten und vorhergesagten Klassifizierungen, die in der „Klassifizierungstabelle“ dargestellt werden, wie unten gezeigt:
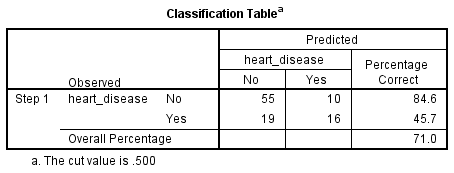
Zunächst fällt auf, dass die Tabelle einen tiefgestellten Index hat, der besagt: „Der Cut-Wert ist .500“. Das bedeutet, wenn die Wahrscheinlichkeit, dass ein Fall in die Kategorie „Ja“ eingeordnet wird, größer als .500 ist, dann wird dieser Fall in die Kategorie „Ja“ eingeordnet. Andernfalls wird der Fall in die Kategorie „Nein“ eingestuft (wie bereits erwähnt). Während die Klassifikationstabelle sehr einfach zu sein scheint, liefert sie tatsächlich viele wichtige Informationen über das Ergebnis der binomialen logistischen Regression, einschließlich:
- A. Die prozentuale Genauigkeit bei der Klassifikation (PAC), die den Prozentsatz der Fälle widerspiegelt, die korrekt als „keine“ Herzerkrankung klassifiziert werden können, wenn die unabhängigen Variablen hinzugefügt werden (nicht nur das Gesamtmodell).
- B. Die Sensitivität, die den Prozentsatz der Fälle darstellt, die das beobachtete Merkmal (z. B.,
- B. Sensitivität, d.h. der Prozentsatz der Fälle, die das beobachtete Merkmal aufweisen (z.B. „ja“ für Herzkrankheit) und vom Modell korrekt vorhergesagt wurden (d.h. „wahr positiv“).
- C. Spezifität, d.h. der Prozentsatz der Fälle, die das beobachtete Merkmal nicht aufweisen (z.B. „nein“ für Herzkrankheit) und ebenfalls korrekt als nicht vorhanden vorhergesagt wurden (d.h.,
- D. Der positive prädiktive Wert, d.h. der Prozentsatz der korrekt vorhergesagten Fälle „mit“ dem beobachteten Merkmal im Vergleich zur Gesamtzahl der als mit dem Merkmal vorhergesagten Fälle.
- E. Der negative prädiktive Wert, d.h. der Prozentsatz der korrekt vorhergesagten Fälle „ohne“ das beobachtete Merkmal im Vergleich zur Gesamtzahl der als nicht mit dem Merkmal vorhergesagten Fälle.
Wenn Sie sich nicht sicher sind, wie Sie den PAC, die Sensitivität, die Spezifität, den positiven prädiktiven Wert und den negativen prädiktiven Wert aus der „Klassifikationstabelle“ interpretieren sollen, erklären wir Ihnen das in unserer erweiterten Anleitung zur binomialen logistischen Regression.
Variablen in der Gleichung
Die Tabelle „Variablen in der Gleichung“ zeigt den Beitrag jeder unabhängigen Variable zum Modell und ihre statistische Signifikanz. Diese Tabelle ist unten dargestellt:
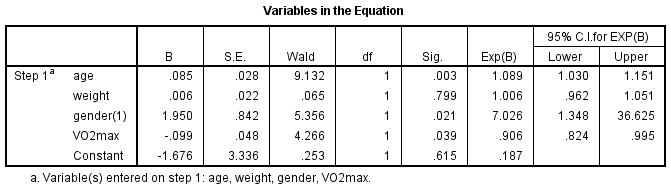
Der Wald-Test (Spalte „Wald“) wird verwendet, um die statistische Signifikanz für jede der unabhängigen Variablen zu bestimmen. Die statistische Signifikanz des Tests ist in der Spalte „Sig.“ zu finden. Aus diesen Ergebnissen können Sie sehen, dass Alter (p = .003), Geschlecht (p = .021) und VO2max (p = .039) signifikant zum Modell/zur Vorhersage beitragen, aber das Gewicht (p = .799) nicht signifikant zum Modell beiträgt. Sie können die Informationen in der Tabelle „Variablen in der Gleichung“ verwenden, um die Wahrscheinlichkeit des Auftretens eines Ereignisses basierend auf einer Änderung einer unabhängigen Variablen um eine Einheit vorherzusagen, wenn alle anderen unabhängigen Variablen konstant gehalten werden. Die Tabelle zeigt beispielsweise, dass die Wahrscheinlichkeit, eine Herzerkrankung zu haben (Kategorie „ja“), für Männer 7,026-mal größer ist als für Frauen. Wenn Sie sich nicht sicher sind, wie Sie Odds Ratios verwenden können, um Vorhersagen zu treffen, informieren Sie sich über unsere erweiterten Anleitungen auf unserer Features: Übersichtsseite.
Alles zusammenfassen
Basierend auf den obigen Ergebnissen könnten wir die Ergebnisse der Studie wie folgt darstellen (Achtung, dies beinhaltet nicht die Ergebnisse der Annahmen-Tests):
- Allgemeines
Eine logistische Regression wurde durchgeführt, um die Auswirkungen von Alter, Gewicht, Geschlecht und VO2max auf die Wahrscheinlichkeit, dass die Teilnehmer eine Herzerkrankung haben, zu ermitteln. Das logistische Regressionsmodell war statistisch signifikant, χ2(4) = 27,402, p < .0005. Das Modell erklärte 33,0 % (Nagelkerke R2) der Varianz bei Herzerkrankungen und klassifizierte 71,0 % der Fälle korrekt. Bei Männern war die Wahrscheinlichkeit einer Herzerkrankung 7,02-mal höher als bei Frauen. Steigendes Alter war mit einer erhöhten Wahrscheinlichkeit für eine Herzerkrankung assoziiert, aber steigende VO2max war mit einer Verringerung der Wahrscheinlichkeit für eine Herzerkrankung assoziiert.
Zusätzlich zu der obigen Aufstellung sollten Sie auch einschließen: (a) die Ergebnisse aus den von Ihnen durchgeführten Annahmen-Tests; (b) die Ergebnisse aus der „Klassifikationstabelle“, einschließlich Sensitivität, Spezifität, positivem prädiktivem Wert und negativem prädiktivem Wert; und (c) die Ergebnisse aus der Tabelle „Variablen in der Gleichung“, einschließlich der Angabe, welche der Prädiktorvariablen statistisch signifikant waren und welche Vorhersagen aufgrund der Verwendung von Odds Ratios gemacht werden können. Wenn Sie sich nicht sicher sind, wie Sie dies tun können, zeigen wir Ihnen dies in unserer erweiterten Anleitung zur binomialen logistischen Regression. Wir zeigen Ihnen auch, wie Sie die Ergebnisse Ihrer Annahmetests und die Ergebnisse der binomialen logistischen Regression aufschreiben, wenn Sie diese in einer Dissertation, einer Hausarbeit oder einem Forschungsbericht wiedergeben müssen. Wir tun dies unter Verwendung des Harvard- und APA-Stils. Sie können mehr über unsere erweiterten Inhalte auf unserer Features: Übersichtsseite.