NCSS comprend un certain nombre d’outils pour l’analyse multivariée, l’analyse des données avec plus d’une variable dépendante ou Y. L’analyse factorielle, l’analyse en composantes principales (ACP) et l’analyse multivariée de la variance (MANOVA) sont toutes des techniques d’analyse multivariée bien connues et toutes sont disponibles dans NCSS, ainsi que plusieurs autres procédures d’analyse multivariée comme indiqué ci-dessous.
Utilisez les liens ci-dessous pour passer au sujet d’analyse multivariée que vous souhaitez examiner. Pour voir comment ces outils peuvent vous être utiles, nous vous recommandons de télécharger et d’installer la version d’essai gratuite de NCSS.
Sauter à :
- Introduction
- Détails techniques
- Analyse factorielle
- Analyse en composantes principales (ACP)
- Corrélation canonique
- Egalité de covariance
- Analyse discriminante
- L’échantillon unique de Hotelling.T² d’échantillon de Hotelling
- Deux-Sample T²
- Analyse de variance à plusieurs variables (MANOVA)
- Analyse des correspondances
- Modèles log-linéaires
- Échelonnement multidimensionnel
Introduction
Bien que le terme d’analyse à plusieurs variables puisse être utilisé pour désigner toute analyse qui implique plus d’une variable (par ex.par exemple dans la régression multiple ou l’ANOVA GLM), le terme d’analyse multivariée est utilisé ici et dans le NCSS pour désigner les situations impliquant des données multidimensionnelles avec plus d’une variable dépendante, Y, ou de résultat. Les techniques d’analyse multivariée sont utilisées pour comprendre comment l’ensemble des variables de résultat, en tant qu’ensemble combiné, sont influencées par d’autres facteurs, comment les variables de résultat sont liées les unes aux autres, ou quels facteurs sous-jacents produisent les résultats observés dans les variables dépendantes.
Chaque procédure disponible dans la section Analyse multivariée du NCSS est décrite ci-dessous.
Détails techniques
Cette page est conçue pour donner un aperçu général des capacités du NCSS pour les techniques d’analyse multivariée. Si vous souhaitez examiner les formules et les détails techniques relatifs à une procédure NCSS spécifique, cliquez sur le lien » correspondant sous chaque rubrique pour charger la documentation complète de la procédure. Vous y trouverez des formules, des références, des discussions et des exemples ou tutoriels décrivant la procédure en détail.
Analyse factorielle
L’analyse factorielle (AF) est une technique exploratoire appliquée à un ensemble de variables de résultat qui cherche à trouver les facteurs sous-jacents (ou sous-ensembles de variables) à partir desquels les variables observées ont été générées. Par exemple, la réponse d’un individu aux questions d’un examen est influencée par des variables sous-jacentes telles que l’intelligence, le nombre d’années passées à l’école, l’âge, l’état émotionnel le jour de l’examen, la quantité de pratique des examens, etc. Les réponses aux questions sont les variables observées ou les variables de résultat. Les variables sous-jacentes, influentes, sont les facteurs.
L’analyse factorielle est effectuée sur la matrice de corrélation des variables observées. Un facteur est une moyenne pondérée des variables initiales. L’analyste factoriel espère trouver quelques facteurs à partir desquels la matrice de corrélation originale peut être générée.
En général, l’objectif de l’analyse factorielle est de faciliter l’interprétation des données. L’analyste factoriel espère identifier chaque facteur comme représentant un facteur théorique spécifique. Un autre objectif de l’analyse factorielle est de réduire le nombre de variables. L’analyste espère réduire l’interprétation d’un test de 200 questions à l’étude de 4 ou 5 facteurs.
La NCSS fournit la méthode d’analyse factorielle par axe principal. Les résultats peuvent être soumis à une rotation varimax ou quartimax et les scores des facteurs peuvent être stockés pour une analyse ultérieure. Un exemple de données, d’entrée de procédure et de sortie est présenté ci-dessous.
Données échantillons
Entrée de procédure
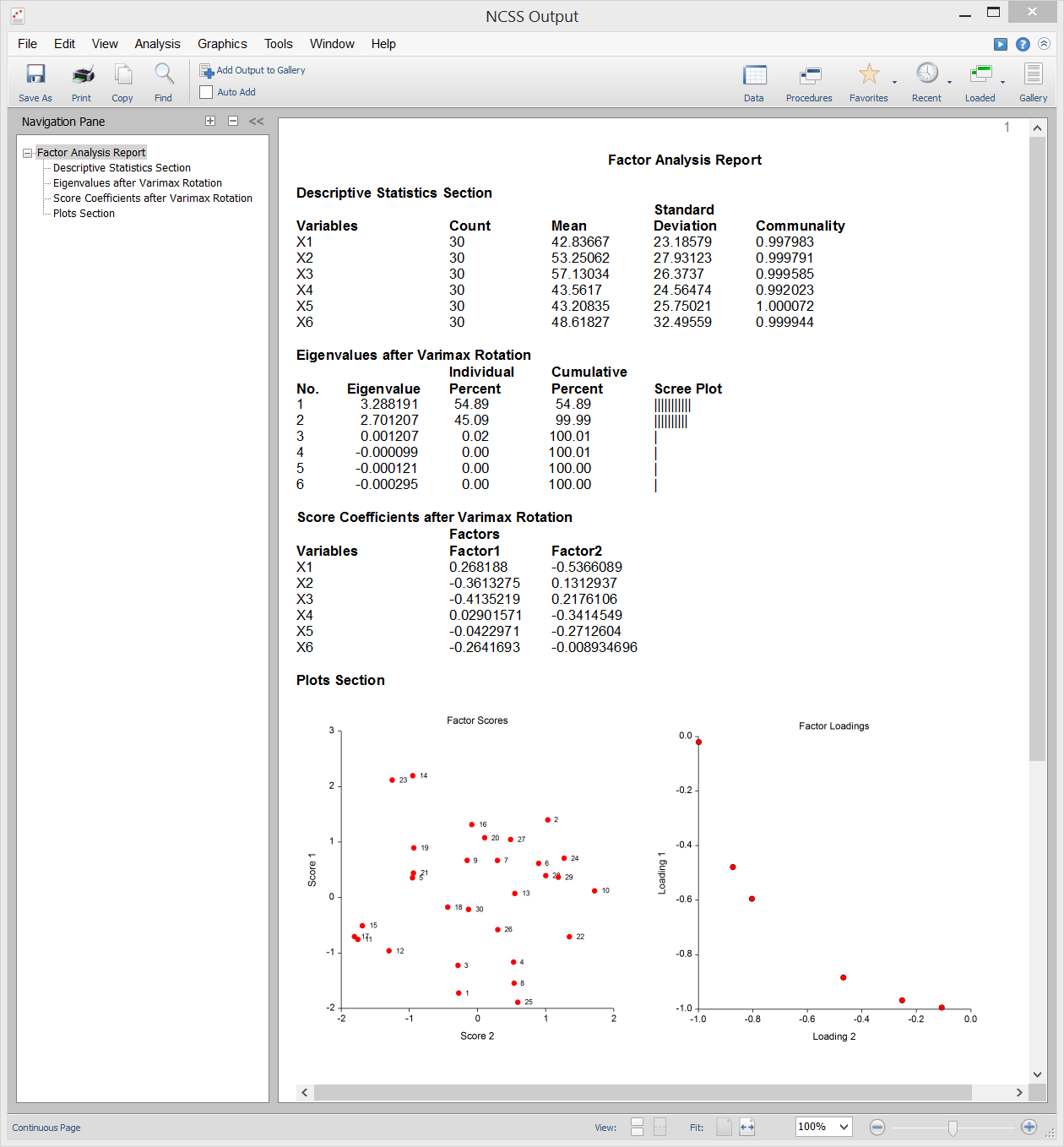
Sortie de l’échantillon
Analyse en composantes principales (ACP)
L’analyse en composantes principales (ou ACP) est un outil d’analyse de données souvent utilisé pour réduire la dimensionnalité (ou le nombre de variables) d’un grand nombre de variables interdépendantes, interreliées, tout en conservant autant d’informations (ex.par exemple, la variation) que possible. L’ACP calcule un ensemble de variables non corrélées, appelées facteurs ou composantes principales. Ces facteurs sont ordonnés de manière à ce que les premiers retiennent la plupart de la variation présente dans toutes les variables d’origine. Contrairement à sa cousine l’analyse factorielle, l’ACP donne toujours la même solution à partir des mêmes données.
Le NCSS utilise une version en double précision de l’algorithme moderne QL tel que décrit par Press (1986) pour résoudre le problème des valeurs propres et des vecteurs propres impliqué dans les calculs de l’ACP. NCSS effectue l’ACP sur une matrice de corrélation ou de covariance. L’analyse peut être effectuée en utilisant des techniques d’estimation robuste.
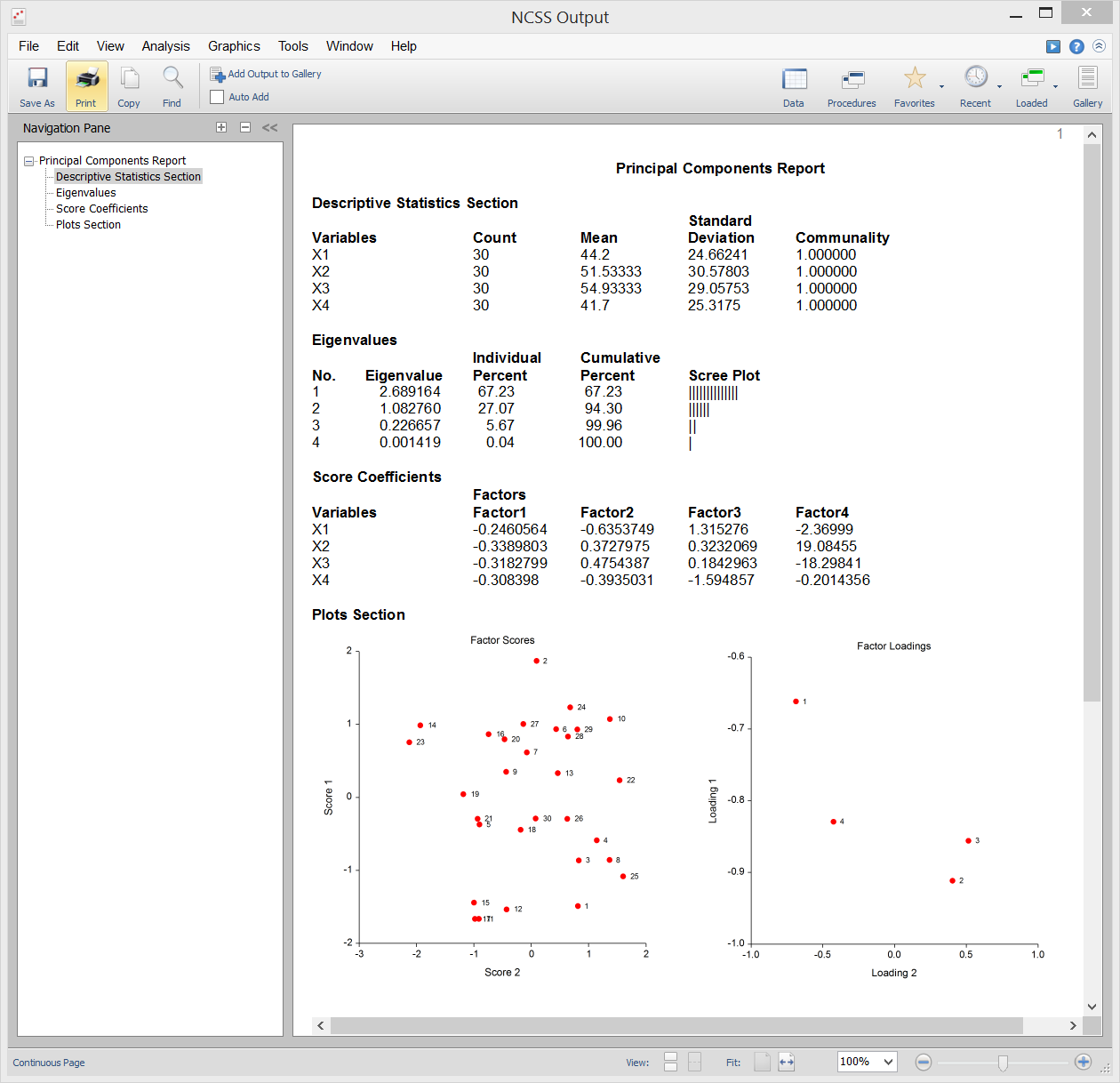
Sample Output
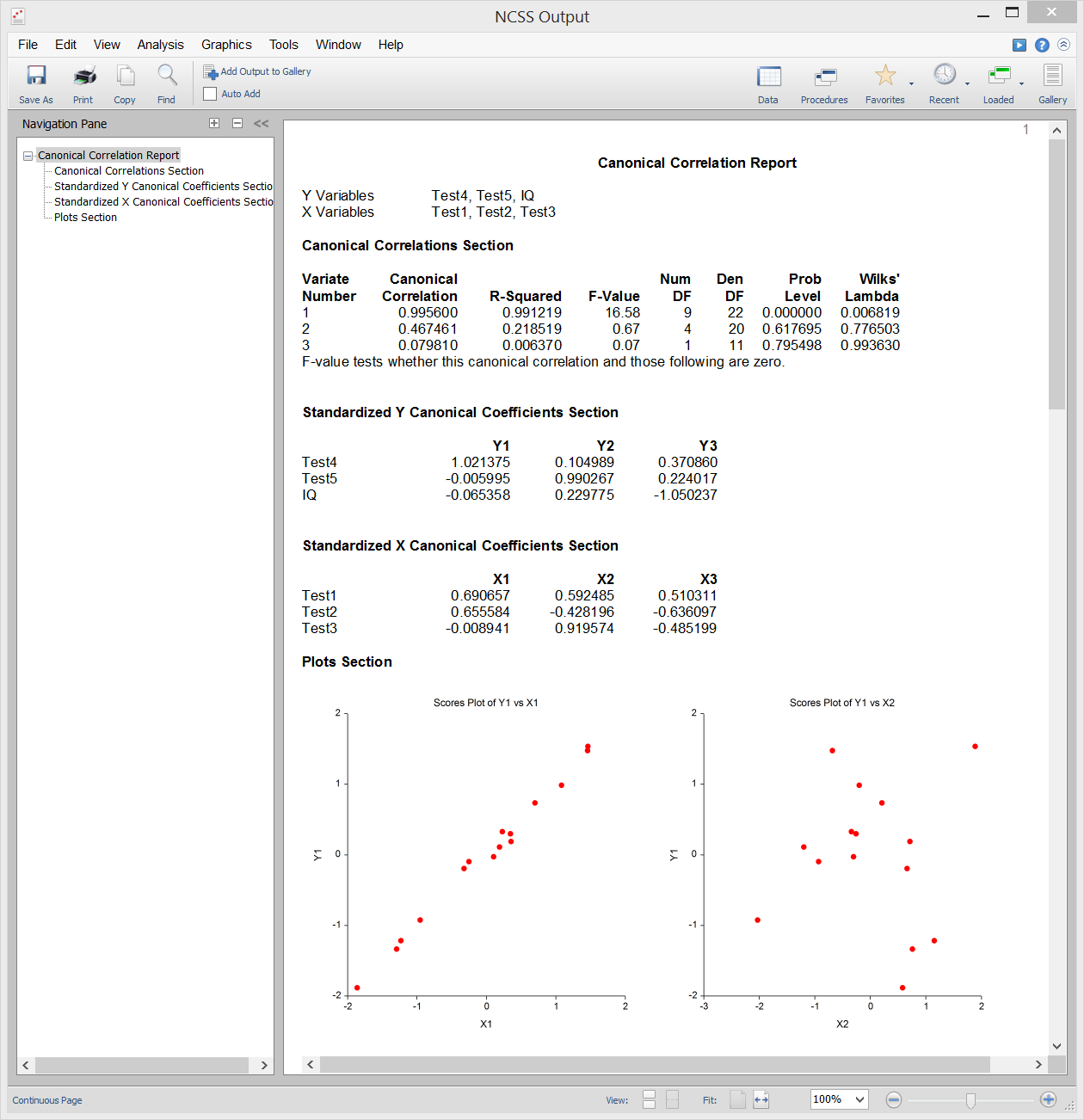
Corrélation canonique
L’analyse de corrélation canonique est l’étude de la relation linéaire entre deux ensembles de variables. C’est l’extension multivariée de l’analyse de corrélation. À titre d’illustration, supposons qu’un groupe d’étudiants subisse chacun deux tests de dix questions et que vous souhaitiez déterminer la corrélation globale entre ces deux tests. La corrélation canonique trouve une moyenne pondérée des questions du premier test et la met en corrélation avec une moyenne pondérée des questions du second test. Les pondérations sont construites de manière à maximiser la corrélation entre ces deux moyennes. Cette corrélation est appelée le premier coefficient de corrélation canonique. Vous pouvez ensuite créer un autre ensemble de moyennes pondérées sans rapport avec le premier et calculer leur corrélation. Cette corrélation est le deuxième coefficient de corrélation canonique. Le processus se poursuit jusqu’à ce que le nombre de corrélations canoniques soit égal au nombre de variables dans le plus petit groupe.
La corrélation canonique fournit le cadre multivarié le plus général (l’analyse discriminante, la MANOVA et la régression multiple sont toutes des cas particuliers de la corrélation canonique). En raison de cette généralité, la corrélation canonique est probablement la moins utilisée des procédures multivariées.
Sample Output
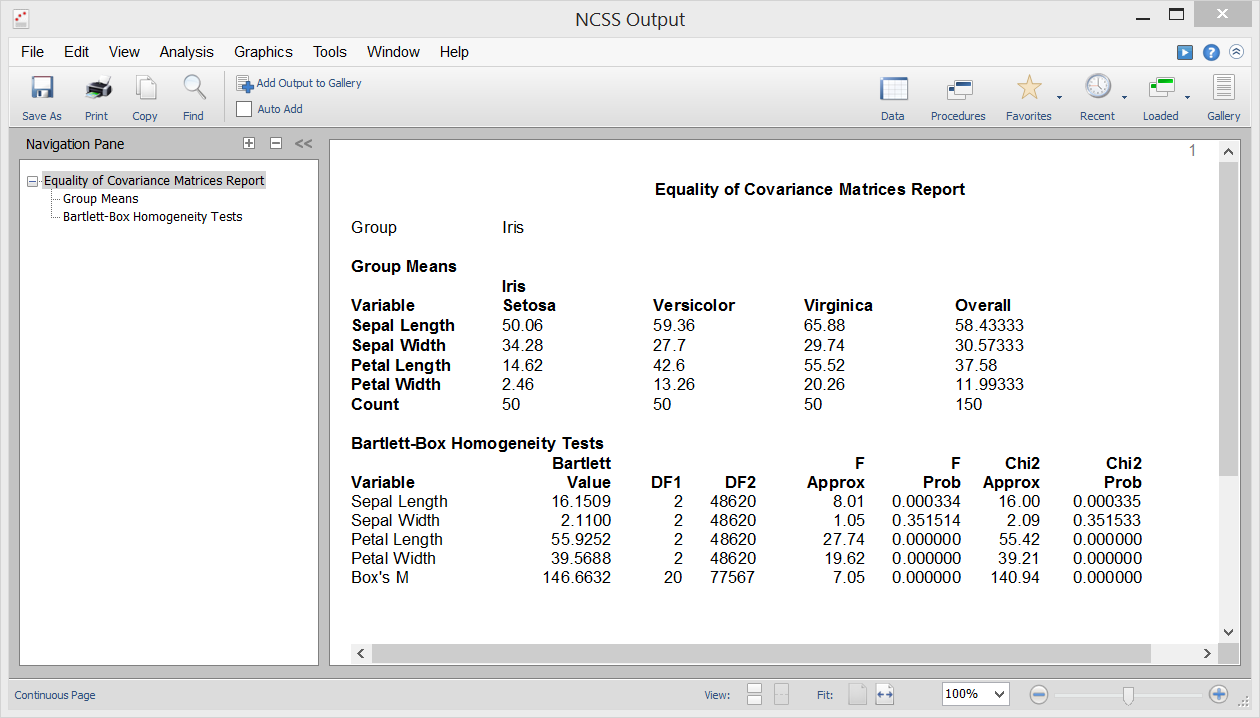
Egalité de covariance
L’une des hypothèses de l’analyse discriminante, de la MANOVA et de diverses autres procédures multivariées est que les matrices de covariance des groupes individuels sont égales (c’est-à-dire homogènes entre les groupes). La procédure d’égalité de covariance du NCSS vous permet de tester cette hypothèse à l’aide du test M de Box, qui a été présenté pour la première fois par Box (1949). Cette procédure sort également le test d’homogénéité de variance univariée de Bartlett pour tester l’égalité de variance entre les variables individuelles.
Sample Output
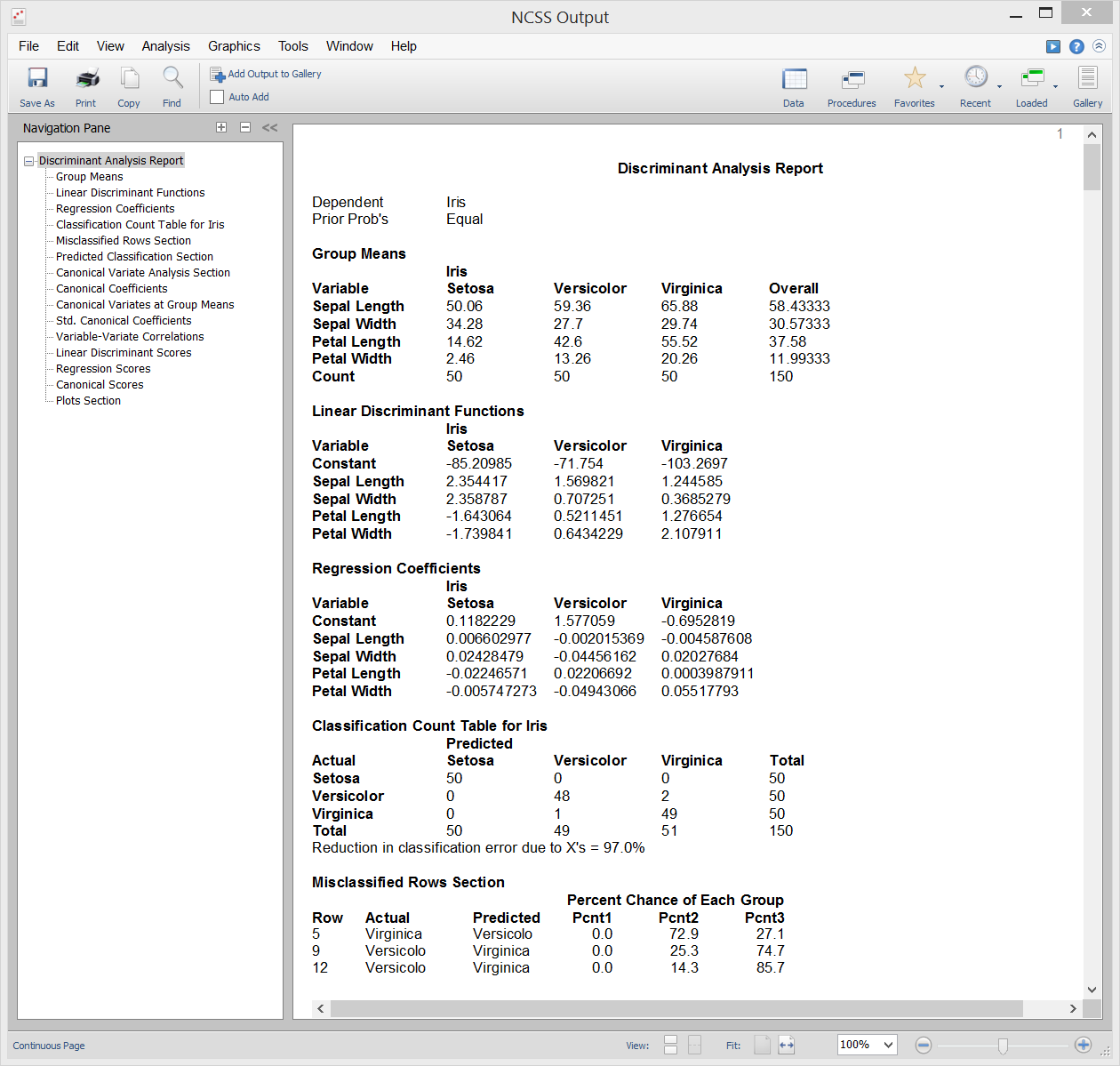
Analyse discriminante
L’analyse discriminante est une technique utilisée pour trouver un ensemble d’équations de prédiction basées sur une ou plusieurs variables indépendantes. Ces équations de prédiction sont ensuite utilisées pour classer les individus en groupes. L’analyse discriminante a deux objectifs communs : 1. trouver une équation prédictive pour classer de nouveaux individus, et 2. interpréter l’équation prédictive pour mieux comprendre les relations entre les variables.
À bien des égards, l’analyse discriminante ressemble beaucoup à l’analyse de régression logistique. La méthodologie utilisée pour réaliser une analyse discriminante est similaire à l’analyse de régression logistique. Vous tracez souvent chaque variable indépendante par rapport à la variable de groupe, vous passez par une phase de sélection des variables pour déterminer quelles variables indépendantes sont bénéfiques, et vous effectuez une analyse résiduelle pour déterminer la précision des équations discriminantes.
Les calculs de l’analyse discriminante sont très proches de la MANOVA à sens unique. En fait, les rôles des variables sont simplement inversés. La variable de classification (facteur) dans le MANOVA devient la variable dépendante dans l’analyse discriminante. Les variables dépendantes dans la MANOVA à sens unique deviennent les variables indépendantes dans l’analyse discriminante.
Sample Output
T² à un échantillon de Hotelling
Le test T² à un échantillon de Hotelling est l’extension multivariée du test T de Student commun à un échantillon ou apparié. Ce test est utilisé lorsque le nombre de variables de réponse est de deux ou plus, bien qu’il puisse être utilisé lorsqu’il n’y a qu’une seule variable de réponse. Le test nécessite l’hypothèse que les données sont approximativement normales multivariées, cependant des tests de randomisation sont fournis qui ne reposent pas sur cette hypothèse.
Sample Output

T² à deux échantillons de Hotelling
Le test T² à deux échantillons de Hotelling est l’extension multivariée du test T de Student à deux échantillons courant pour la différence de moyennes. Ce test est utilisé lorsque le nombre de variables de réponse est de deux ou plus, bien qu’il puisse être utilisé lorsqu’il n’y a qu’une seule variable de réponse. Le test nécessite les hypothèses de variances égales et de résidus normalement distribués, cependant des tests de randomisation sont fournis qui ne reposent pas sur ces hypothèses.
Sample Output

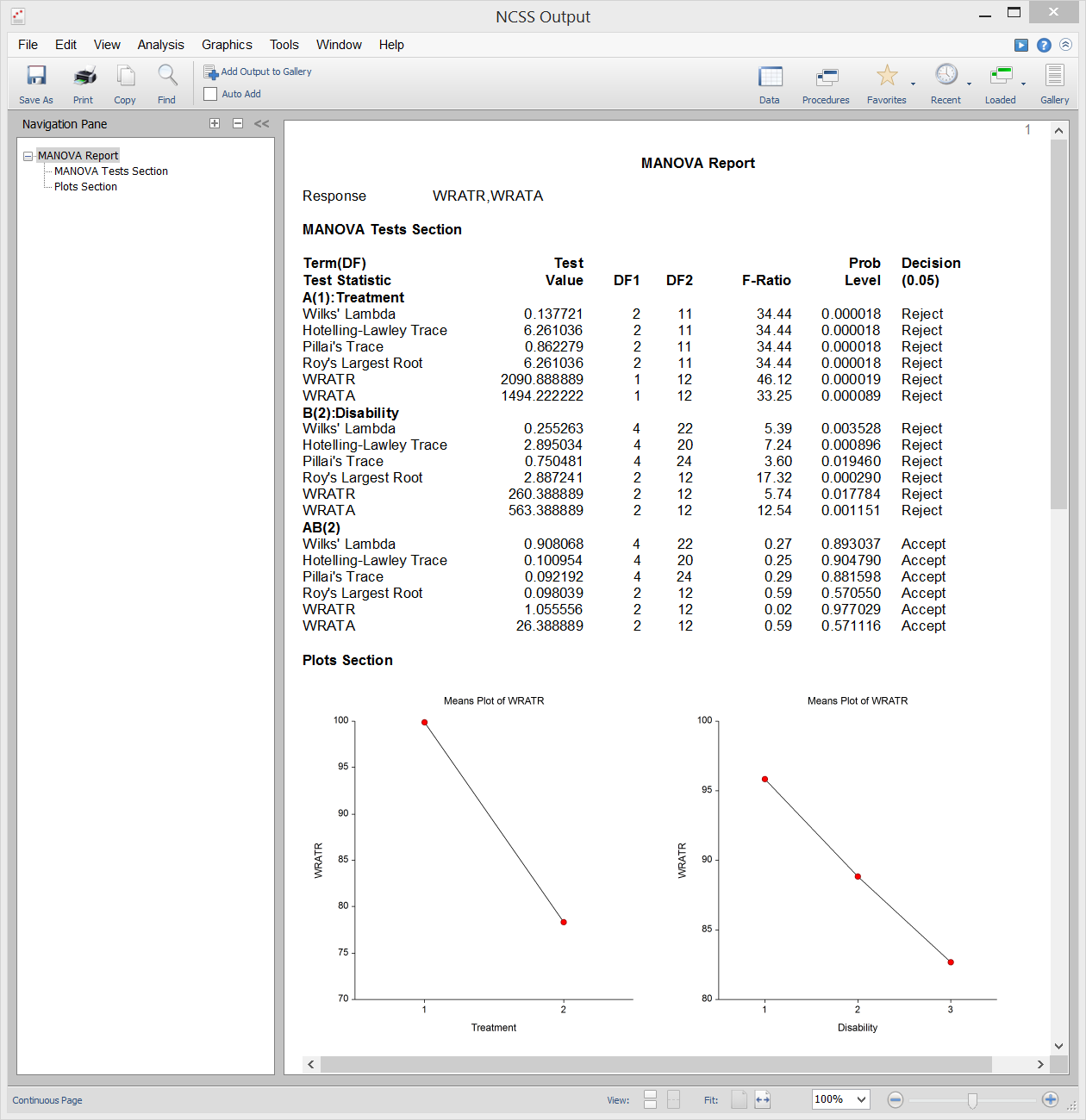
Analyse de variance multivariée (MANOVA)
L’analyse de variance multivariée (ou MANOVA) est une extension de l’ANOVA au cas où il y a deux variables de réponse ou plus. La MANOVA est conçue pour le cas où vous avez un ou plusieurs facteurs indépendants (chacun avec deux ou plusieurs niveaux) et deux ou plusieurs variables dépendantes. Les tests d’hypothèse impliquent la comparaison de vecteurs de moyennes de groupes.
L’extension multivariée du test F de l’ANOVA n’est pas complètement directe. Au lieu de cela, plusieurs autres statistiques de test sont disponibles dans MANOVA : Lambda de Wilks, trace de Hotelling-Lawley, trace de Pillai et racine la plus grande de Roy. Les distributions réelles de ces statistiques de test sont difficiles à calculer, nous nous appuyons donc sur des approximations basées sur la distribution F pour calculer les valeurs p.
Sortie d’échantillon
Analyse des correspondances
L’analyse des correspondances (ou AC) est une technique de représentation graphique d’un tableau à deux voies de données catégorielles à l’aide de coordonnées calculées représentant les lignes et les colonnes du tableau. Ces coordonnées sont analogues aux facteurs d’une analyse en composantes principales (utilisée pour les données continues), sauf qu’elles partitionnent la valeur du Khi-deux utilisée pour tester l’indépendance au lieu de la variance totale.
Sample Output
Modèles log-linéaires
Les modèles log-linéaires (LLM) sont utilisés pour étudier les relations entre deux ou plusieurs variables discrètes. Souvent appelé analyse de fréquence multivoie, il s’agit d’une extension du test familier du chi-deux pour l’indépendance dans les tableaux de contingence à deux voies.
Le LLM peut être utilisé pour analyser des enquêtes et des questionnaires qui présentent des interrelations complexes entre les questions. Bien que les questionnaires soient souvent analysés en ne considérant que deux questions à la fois, cela ignore les relations importantes à trois voies (et à voies multiples) entre les questions. L’utilisation de LLM sur ce type de données est analogue à l’utilisation de la régression multiple plutôt que de simples corrélations sur des données continues.
Les rapports de cette procédure comprennent des rapports à termes multiples, des rapports à terme unique, des rapports de chi-deux, des rapports de modèles, des rapports d’estimation de paramètres et des rapports de tableaux.
Sample Output
Multidimensional Scaling
Multidimensional Scaling (MDS) est une technique qui crée une carte affichant les positions relatives d’un certain nombre d’objets, étant donné seulement un tableau des distances entre eux. La carte peut comporter une, deux, trois ou plusieurs dimensions. La procédure calcule soit la solution métrique, soit la solution non métrique. Le tableau des distances est connu sous le nom de matrice de proximité. Elle découle soit directement des expériences, soit indirectement d’une matrice de corrélation.
Le programme propose deux méthodes générales pour résoudre le problème MDS. La première est appelée Metric, ou Classical, Multidimensional Scaling (CMDS) car elle tente de reproduire la métrique ou les distances d’origine. La seconde méthode, appelée Non-Metric Multidimensional Scaling (NMMDS), suppose que seuls les rangs des distances sont connus. Cette méthode produit donc une carte qui tente de reproduire les rangs. Les distances elles-mêmes ne sont pas reproduites.