- 04/29/2020
- 14 minutes de lecture
-
-
 c
c -
 M
M -
 D
D - …D
-
 B
B -
 v
v -
+13
-
S’applique à : ![]() SQL Server (toutes les versions prises en charge)
SQL Server (toutes les versions prises en charge)
Cette rubrique présente les concepts des groupes de disponibilité Always On qui sont centraux pour configurer et gérer un ou plusieurs groupes de disponibilité dans SQL Server. Pour un résumé des avantages offerts par les groupes de disponibilité et un aperçu de la terminologie des groupes de disponibilité Always On, voir Groupes de disponibilité Always On (SQL Server).
Un groupe de disponibilité prend en charge un environnement répliqué pour un ensemble discret de bases de données utilisateur, appelées bases de données de disponibilité. Vous pouvez créer un groupe de disponibilité pour la haute disponibilité (HA) ou pour le read-scale. Un groupe de disponibilité HA est un groupe de bases de données qui basculent ensemble. Un groupe de disponibilité en lecture est un groupe de bases de données qui sont copiées sur d’autres instances de SQL Server pour une charge de travail en lecture seule. Un groupe de disponibilité prend en charge un ensemble de bases de données primaires et un à huit ensembles de bases de données secondaires correspondantes. Les bases de données secondaires ne sont pas des sauvegardes. Continuez à sauvegarder régulièrement vos bases de données et leurs journaux de transactions.
Conseil
Vous pouvez créer tout type de sauvegarde d’une base de données primaire. Sinon, vous pouvez créer des sauvegardes de journaux et des sauvegardes complètes en copie seulement de bases de données secondaires. Pour plus d’informations, consultez la section Secondaires actifs : Sauvegarde sur les répliques secondaires (groupes de disponibilité Always On).
Chaque ensemble de base de données de disponibilité est hébergé par une réplique de disponibilité. Deux types de répliques de disponibilité existent : une seule réplique primaire. qui héberge les bases de données primaires, et une à huit répliques secondaires, chacune hébergeant un ensemble de bases de données secondaires et servant de cibles de basculement potentielles pour le groupe de disponibilité. Un groupe de disponibilité effectue un basculement au niveau d’une réplique de disponibilité. Une réplique de disponibilité fournit une redondance uniquement au niveau de la base de données pour l’ensemble des bases de données d’un groupe de disponibilité. Les basculements ne sont pas causés par des problèmes de base de données tels qu’une base de données devenant suspecte en raison de la perte d’un fichier de données ou de la corruption d’un journal des transactions.
Le réplica primaire rend les bases de données primaires disponibles pour les connexions en lecture-écriture des clients. La réplique primaire envoie les enregistrements du journal des transactions de chaque base de données primaire à chaque base de données secondaire. Ce processus – connu sous le nom de synchronisation des données – se produit au niveau de la base de données. Chaque réplique secondaire met en cache les enregistrements du journal des transactions (durcit le journal) et les applique ensuite à sa base de données secondaire correspondante. La synchronisation des données se produit entre la base de données principale et chaque base de données secondaire connectée, indépendamment des autres bases de données. Par conséquent, une base de données secondaire peut être suspendue ou échouer sans affecter les autres bases de données secondaires, et une base de données primaire peut être suspendue ou échouer sans affecter les autres bases de données primaires.
Optionnellement, vous pouvez configurer une ou plusieurs répliques secondaires pour prendre en charge l’accès en lecture seule aux bases de données secondaires, et vous pouvez configurer n’importe quelle réplique secondaire pour autoriser les sauvegardes sur les bases de données secondaires.
SQL Server 2017 introduit deux architectures différentes pour les groupes de disponibilité. Les groupes de disponibilité Always On assurent la haute disponibilité, la reprise après sinistre et l’équilibrage en lecture. Ces groupes de disponibilité nécessitent un gestionnaire de cluster. Sous Windows, le clustering de basculement fournit le gestionnaire de cluster. Sous Linux, vous pouvez utiliser Pacemaker. L’autre architecture est un groupe de disponibilité à échelle de lecture. Un groupe de disponibilité à l’échelle de la lecture fournit des répliques pour les charges de travail en lecture seule, mais pas de haute disponibilité. Dans un groupe de disponibilité à l’échelle de la lecture, il n’y a pas de gestionnaire de cluster.
Déployer des groupes de disponibilité Always On pour HA sur Windows nécessite un Windows Server Failover Cluster(WSFC). Chaque réplique de disponibilité d’un groupe de disponibilité donné doit résider sur un nœud différent du même WSFC. La seule exception est que lors de la migration vers un autre cluster WSFC, un groupe de disponibilité peut temporairement chevaucher deux clusters.
Note
Pour plus d’informations sur les groupes de disponibilité sur Linux, consultez la section Groupe de disponibilité Always On pour SQL Server sur Linux.
Dans une configuration HA, un rôle de cluster est créé pour chaque groupe de disponibilité que vous créez. Le cluster WSFC surveille ce rôle pour évaluer la santé de la réplique primaire. Le quorum des groupes de disponibilité Always On est basé sur tous les nœuds du cluster WSFC, qu’un nœud de cluster donné héberge ou non des répliques de disponibilité. Contrairement à la mise en miroir de bases de données, il n’y a pas de rôle de témoin dans les groupes de disponibilité Always On.
Note
Pour plus d’informations sur la relation entre les composants SQL Server Always On et le cluster WSFC, voir Windows Server Failover Clustering (WSFC) avec SQL Server.
L’illustration suivante montre un groupe de disponibilité qui contient une réplique primaire et quatre répliques secondaires. Jusqu’à huit répliques secondaires sont prises en charge, dont une réplique primaire et deux répliques secondaires à commande synchrone.
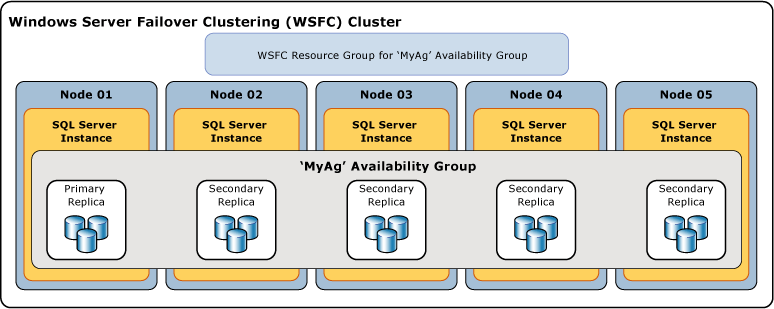
Bases de données de disponibilité
Pour ajouter une base de données à un groupe de disponibilité, la base de données doit être une base de données en ligne, en lecture-écriture, qui existe sur l’instance de serveur qui héberge la réplique primaire. Lorsque vous ajoutez une base de données, elle rejoint le groupe de disponibilité en tant que base de données primaire, tout en restant disponible pour les clients. Aucune base de données secondaire correspondante n’existe jusqu’à ce que les sauvegardes de la nouvelle base de données primaire soient restaurées sur l’instance de serveur qui héberge la réplique secondaire (à l’aide de RESTORE WITH NORECOVERY). La nouvelle base de données secondaire est dans l’état RESTORING jusqu’à ce qu’elle soit jointe au groupe de disponibilité. Pour plus d’informations, voir Démarrer le mouvement des données sur une base de données secondaire Always On (SQL Server).
La jonction place la base de données secondaire dans l’état ONLINE et lance la synchronisation des données avec la base de données primaire correspondante. La synchronisation des données est le processus par lequel les modifications apportées à une base de données primaire sont reproduites sur une base de données secondaire. La synchronisation des données implique que la base de données primaire envoie des enregistrements du journal des transactions à la base de données secondaire.
Important
Une base de données de disponibilité est parfois appelée réplique de base de données dans les noms Transact-SQL, PowerShell et SQL Server Management Objects (SMO). Par exemple, le terme » réplique de base de données » est utilisé dans les noms des vues de gestion dynamique Always On qui renvoient des informations sur les bases de données de disponibilité : sys.dm_hadr_database_replica_states et sys.dm_hadr_database_replica_cluster_states. Toutefois, dans SQL Server Books Online, le terme « replica » fait généralement référence aux répliques de disponibilité. Par exemple, « réplique primaire » et « réplique secondaire » font toujours référence aux répliques de disponibilité.
Répliques de disponibilité
Chaque groupe de disponibilité définit un ensemble de deux ou plusieurs partenaires de basculement appelés répliques de disponibilité. Les répliques de disponibilité sont des composants du groupe de disponibilité. Chaque réplique de disponibilité héberge une copie des bases de données de disponibilité du groupe de disponibilité. Pour un groupe de disponibilité donné, les répliques de disponibilité doivent être hébergées par des instances distinctes de SQL Server résidant sur différents nœuds d’un cluster WSFC. Chacune de ces instances de serveur doit être activée pour Always On.
Une instance donnée ne peut héberger qu’une seule réplique de disponibilité par groupe de disponibilité. Cependant, chaque instance peut être utilisée pour de nombreux groupes de disponibilité. Une instance donnée peut être soit une instance autonome, soit une instance de cluster de basculement SQL Server (FCI). Si vous avez besoin d’une redondance au niveau du serveur, utilisez des instances de cluster de basculement.
Chaque réplique de disponibilité se voit attribuer un rôle initial – soit le rôle principal, soit le rôle secondaire, qui est hérité par les bases de données de disponibilité de cette réplique. Le rôle d’une réplique donnée détermine si elle héberge des bases de données en lecture-écriture ou des bases de données en lecture seule. Une réplique, appelée réplique primaire, se voit attribuer le rôle primaire et héberge des bases de données en lecture-écriture, appelées bases de données primaires. Au moins une autre réplique, appelée réplique secondaire, se voit attribuer le rôle secondaire. Une réplique secondaire héberge des bases de données en lecture seule, appelées bases de données secondaires.
Note
Lorsque le rôle d’une réplique de disponibilité est indéterminé, par exemple lors d’un basculement, ses bases de données sont temporairement dans un état NOT SYNCHRONIZING. Leur rôle est défini sur RESOLVING jusqu’à ce que le rôle de la réplique de disponibilité soit résolu. Si une réplique de disponibilité se résout au rôle primaire, ses bases de données deviennent les bases de données primaires. Si une réplique de disponibilité se résout au rôle secondaire, ses bases de données deviennent des bases de données secondaires.
Modes de disponibilité
Le mode de disponibilité est une propriété de chaque réplique de disponibilité. Le mode de disponibilité détermine si la réplique primaire attend pour valider les transactions sur une base de données qu’une réplique secondaire donnée ait écrit les enregistrements du journal des transactions sur le disque (durcissement du journal). Les groupes de disponibilité Always On prennent en charge deux modes de disponibilité : le mode commit asynchrone et le mode commit synchrone.
-
Mode commit asynchrone
Une réplique de disponibilité qui utilise ce mode de disponibilité est appelée réplique commit asynchrone. En mode asynchrone-commit, la réplique primaire commet les transactions sans attendre la confirmation qu’une réplique secondaire asynchrone-commit a durci le journal. Le mode de validation asynchrone minimise la latence des transactions sur les bases de données secondaires mais leur permet d’être en retard par rapport aux bases de données primaires, ce qui rend possible une certaine perte de données.
-
Mode de validation synchrone
Une réplique de disponibilité qui utilise ce mode de disponibilité est appelée réplique de validation synchrone. En mode synchrone-commit, avant de commettre des transactions, une réplique primaire synchrone-commit attend qu’une réplique secondaire synchrone-commit reconnaisse qu’elle a terminé le durcissement du journal. Le mode de validation synchrone garantit qu’une fois qu’une base de données secondaire donnée est synchronisée avec la base de données primaire, les transactions validées sont entièrement protégées. Cette protection se fait au prix d’une latence accrue des transactions.
Pour plus d’informations, voir Modes de disponibilité (groupes de disponibilité Always On).
Types de basculement
Dans le contexte d’une session entre la réplique primaire et une réplique secondaire, les rôles primaire et secondaire sont potentiellement interchangeables dans un processus appelé basculement. Pendant un basculement, la réplique secondaire cible passe au rôle primaire, devenant ainsi la nouvelle réplique primaire. La nouvelle réplique primaire met ses bases de données en ligne en tant que bases de données primaires, et les applications clientes peuvent s’y connecter. Lorsque l’ancienne réplique primaire est disponible, elle passe au rôle secondaire et devient une réplique secondaire. Les anciennes bases de données primaires deviennent des bases de données secondaires et la synchronisation des données reprend.
Trois formes de basculement existent : automatique, manuel et forcé (avec perte possible de données). La ou les formes de basculement prises en charge par une réplique secondaire donnée dépendent de son mode de disponibilité et, pour le mode synchronous-commit, du mode de basculement sur la réplique primaire et la réplique secondaire cible, comme suit.
-
Le mode synchronous-commit prend en charge deux formes de basculement – basculement manuel planifié et basculement automatique, si la réplique secondaire cible est actuellement synchronisée avec la réplique primaire. La prise en charge de ces formes de basculement dépend du paramétrage de la propriété failover mode sur les partenaires de basculement. Si le mode de basculement est défini sur « manuel » sur la réplique primaire ou secondaire, seul le basculement manuel est pris en charge pour cette réplique secondaire. Si le mode de basculement est défini sur « automatique » sur les répliques primaire et secondaire, le basculement automatique et manuel est pris en charge sur cette réplique secondaire.
-
Basculement manuel planifié (sans perte de données)
Un basculement manuel se produit après qu’un administrateur de base de données a émis une commande de basculement et fait en sorte qu’une réplique secondaire synchronisée passe au rôle primaire (avec une protection des données garantie) et que la réplique primaire passe au rôle secondaire. Un basculement manuel nécessite que la réplique primaire et la réplique secondaire cible s’exécutent toutes deux en mode de validation synchrone, et que la réplique secondaire soit déjà synchronisée.
-
Un basculement automatique (sans perte de données)
Un basculement automatique se produit en réponse à une panne qui entraîne la transition d’une réplique secondaire synchronisée vers le rôle primaire (avec une protection des données garantie). Lorsque l’ancienne réplique primaire devient disponible, elle effectue la transition vers le rôle secondaire. Le basculement automatique exige que la réplique primaire et la réplique secondaire cible soient toutes deux exécutées en mode « synchronous-commit » avec le mode de basculement réglé sur « Automatic ». En outre, la réplique secondaire doit déjà être synchronisée, avoir le quorum WSFC et remplir les conditions spécifiées par la politique de basculement flexibledu groupe de disponibilité.
Important
Les instances Failover Cluster (FCI) de SQL Server ne prennent pas en charge le basculement automatique par les groupes de disponibilité, donc toute réplique de disponibilité hébergée par un FCI ne peut être configurée que pour un basculement manuel.
Note
Notez que si vous émettez une commande de basculement forcé sur une réplique secondaire synchronisée, la réplique secondaire se comporte de la même manière que pour un basculement manuel planifié.
-
-
En mode commit asynchrone, la seule forme de basculement est le basculement manuel forcé (avec perte possible de données), généralement appelé basculement forcé. Le basculement forcé est considéré comme une forme de basculement manuel car il ne peut être initié que manuellement. Le basculement forcé est une option de reprise après sinistre. C’est la seule forme de basculement possible lorsque la réplique secondaire cible n’est pas synchronisée avec la réplique primaire.
Pour plus d’informations, consultez la section Basculement et modes de basculement (groupes de disponibilité Always On).
Connexions client
Vous pouvez fournir une connectivité client à la réplique primaire d’un groupe de disponibilité donné en créant un auditeur de groupe de disponibilité. Un auditeur de groupe de disponibilité fournit un ensemble de ressources qui est attaché à un groupe de disponibilité donné pour diriger les connexions client vers la réplique de disponibilité appropriée.
Un auditeur de groupe de disponibilité est associé à un nom DNS unique qui sert de nom de réseau virtuel (VNN), une ou plusieurs adresses IP virtuelles (VIP) et un numéro de port TCP. Pour plus d’informations, voir Écouteurs de groupe de disponibilité, connectivité client et basculement d’application (SQL Server).
Conseil
Si un groupe de disponibilité ne possède que deux répliques de disponibilité et n’est pas configuré pour autoriser l’accès en lecture à la réplique secondaire, les clients peuvent se connecter à la réplique primaire en utilisant une chaîne de connexion de mise en miroir de la base de données. Cette approche peut être utile temporairement après avoir migré une base de données de la mise en miroir de la base de données vers les groupes de disponibilité Always On. Avant d’ajouter des répliques secondaires supplémentaires, vous devrez créer un auditeur de groupe de disponibilité le groupe de disponibilité et mettre à jour vos applications pour utiliser le nom de réseau de l’auditeur.
Répliques secondaires actives
Les groupes de disponibilité Always On prennent en charge les répliques secondaires actives. Les capacités secondaires actives incluent la prise en charge de :
-
L’exécution d’opérations de sauvegarde sur les répliques secondaires
Les répliques secondaires prennent en charge l’exécution de sauvegardes de journaux et de sauvegardes en copie seule d’une base de données complète, d’un fichier ou d’un groupe de fichiers. Vous pouvez configurer le groupe de disponibilité pour spécifier une préférence pour l’endroit où les sauvegardes doivent être effectuées. Il est important de comprendre que la préférence n’est pas appliquée par SQL Server, elle n’a donc aucun impact sur les sauvegardes ad hoc. L’interprétation de cette préférence dépend de la logique, le cas échéant, que vous intégrez dans vos tâches de sauvegarde pour chacune des bases de données d’un groupe de disponibilité donné. Pour une réplique de disponibilité individuelle, vous pouvez spécifier votre priorité pour l’exécution des sauvegardes sur cette réplique par rapport aux autres répliques du même groupe de disponibilité. Pour plus d’informations, voir Secondaires actifs : Sauvegarde sur les répliques secondaires (groupes de disponibilité Always On).
-
Accès en lecture seule à une ou plusieurs répliques secondaires (répliques secondaires lisibles)
Toute réplique de disponibilité secondaire peut être configurée pour autoriser uniquement l’accès en lecture seule à ses bases de données locales, bien que certaines opérations ne soient pas entièrement prises en charge. Cela empêchera les tentatives de connexion en lecture-écriture à la réplique secondaire. Il est également possible d’empêcher les charges de travail en lecture seule sur la réplique primaire en autorisant uniquement l’accès en lecture-écriture. Cela empêchera les connexions en lecture seule sur la réplique primaire. Pour plus d’informations, consultez la rubrique Secondaires actifs : Répliques secondaires lisibles (groupes de disponibilité Always On).
Si un groupe de disponibilité possède actuellement un auditeur de groupe de disponibilité et une ou plusieurs répliques secondaires lisibles, SQL Server peut acheminer les demandes de connexion en lecture vers l’une d’entre elles (routage en lecture seule). Pour plus d’informations, voir Écouteurs de groupe de disponibilité, connectivité client et basculement d’application (SQL Server).
Durée du délai d’attente de session
La durée du délai d’attente de session est une propriété de réplique de disponibilité qui détermine combien de temps la connexion avec une autre réplique de disponibilité peut rester inactive avant que la connexion ne soit fermée. Les répliques primaire et secondaire se lancent des ping pour signaler qu’elles sont toujours actives. La réception d’un ping de l’autre réplique pendant le délai d’attente indique que la connexion est toujours ouverte et que les instances de serveur communiquent. À la réception d’un ping, une réplique de disponibilité réinitialise son compteur de délai d’attente de session sur cette connexion.
Le délai d’attente de session empêche l’une ou l’autre réplique d’attendre indéfiniment de recevoir un ping de l’autre réplique. Si aucun ping n’est reçu de l’autre réplique dans le délai de dépassement de session, la réplique passe en temps mort. Sa connexion est fermée et la réplique dont le délai d’attente est dépassé passe à l’état DISCONNECTED. Même si une réplique déconnectée est configurée pour le mode synchronous-commit, les transactions n’attendront pas que cette réplique se reconnecte et se resynchronise.
Le délai d’expiration de session par défaut pour chaque réplique de disponibilité est de 10 secondes. Cette valeur est configurable par l’utilisateur, avec un minimum de 5 secondes. En général, nous vous recommandons de maintenir le délai d’attente à 10 secondes ou plus. La définition de la valeur à moins de 10 secondes crée la possibilité qu’un système fortement chargé déclare un faux échec.
Note
Dans le rôle de résolution, la période de délai d’attente de session ne s’applique pas car le ping ne se produit pas.
Réparation automatique des pages
Chaque réplique de disponibilité tente de récupérer automatiquement les pages corrompues sur une base de données locale en résolvant certains types d’erreurs qui empêchent la lecture d’une page de données. Si une réplique secondaire ne peut pas lire une page, elle demande une copie fraîche de la page à la réplique primaire. Si le réplica primaire ne peut pas lire une page, il diffuse une demande de copie fraîche à tous les réplicas secondaires et obtient la page du premier à répondre. Si cette demande aboutit, la page illisible est remplacée par la copie, ce qui résout généralement l’erreur.
Pour plus d’informations, voir Réparation automatique des pages (Groupes de disponibilité : mise en miroir de bases de données).
Tâches associées
- Démarrer avec les groupes de disponibilité Always On (SQL Server)
Contenu associé
-
Blogs:
Always On – Série d’apprentissage HADRON : Utilisation du pool de travailleurs pour les bases de données activées par HADRON
Blogs de l’équipe Always On de SQL Server : Le blog officiel de l’équipe Always On de SQL Server
Blogs des ingénieurs SQL Server de la CSS
-
Vidéos:
Série Always On du nom de code » Denali » de Microsoft SQL Server,1ère partie : Présentation de la solution de haute disponibilité de nouvelle génération
Série Microsoft SQL Server nom de code « Denali » Always On, partie 2 : Construction d’une solution de haute disponibilité critique à l’aide de Always On
-
Les livres blancs :
Guide des solutions Always On de Microsoft SQL Server pour la haute disponibilité et la reprise après sinistre
Les livres blancs de Microsoft pour SQL Server 2012
L’équipe consultative des clients de SQL Server. Whitepapers
Voir aussi
Modes de disponibilité (groupes de disponibilité Always On)
Failover et modes de basculement (groupes de disponibilité Always On)
Vue d’ensemble des instructions Transact-.SQL pour les groupes de disponibilité Always On (SQL Server)
Présentation des Cmdlets PowerShell pour les groupes de disponibilité Always On (SQL Server)
Prise en charge de la haute disponibilité pour les bases de données OLTP en mémoire
Prérequis, Restrictions et recommandations pour les groupes de disponibilité Always On (SQL Server)
Création et configuration des groupes de disponibilité (SQL Server)
Secondaires actifs : Répliques secondaires lisibles (groupes de disponibilité Always On)
Secondaires actifs : Sauvegarde sur les répliques secondaires (groupes de disponibilité Always On)
Les récepteurs de groupes de disponibilité, la connectivité client et le basculement des applications (SQL Server)
.