SPSS Statistics
Interpréter et rapporter les résultats d’une analyse de régression logistique binomiale
SPSS Statistics génère de nombreux tableaux de sortie lors de l’exécution d’une régression logistique binomiale. Dans cette section, nous vous montrons uniquement les trois principaux tableaux nécessaires à la compréhension de vos résultats issus de la procédure de régression logistique binomiale, en supposant qu’aucune hypothèse n’a été violée. Une explication complète de la sortie que vous devez interpréter lorsque vous vérifiez vos données pour les hypothèses requises pour effectuer une régression logistique binomiale est fournie dans notre guide amélioré.
Toutefois, dans ce guide de » démarrage rapide « , nous nous concentrons uniquement sur les trois tableaux principaux dont vous avez besoin pour comprendre vos résultats de régression logistique binomiale, en supposant que vos données ont déjà satisfait aux hypothèses requises pour que la régression logistique binomiale vous donne un résultat valide :
Variance expliquée
Afin de comprendre quelle part de la variation de la variable dépendante peut être expliquée par le modèle (l’équivalent du R2 en régression multiple), vous pouvez consulter le tableau ci-dessous, » Résumé du modèle » :
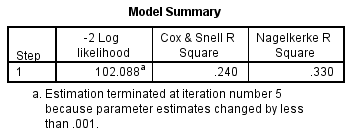
Ce tableau contient les valeurs Cox & Snell R Square et Nagelkerke R Square, qui sont toutes deux des méthodes de calcul de la variation expliquée. Ces valeurs sont parfois appelées valeurs de pseudo R2 (et auront des valeurs plus faibles que dans la régression multiple). Cependant, elles sont interprétées de la même manière, mais avec plus de prudence. Par conséquent, la variation expliquée de la variable dépendante sur la base de notre modèle varie de 24,0 % à 33,0 %, selon que l’on se réfère respectivement aux méthodes Cox & Snell R2 ou Nagelkerke R2. Le Nagelkerke R2 est une modification du Cox & Snell R2, ce dernier ne pouvant atteindre une valeur de 1. Pour cette raison, il est préférable de rapporter la valeur du Nagelkerke R2.
Prédiction de la catégorie
La régression logistique binomiale estime la probabilité de survenue d’un événement (dans ce cas, avoir une maladie cardiaque). Si la probabilité estimée de la survenue de l’événement est supérieure ou égale à 0,5 (meilleure que le hasard pair), SPSS Statistics classe l’événement comme survenant (par exemple, présence d’une maladie cardiaque). Si la probabilité est inférieure à 0,5, SPSS Statistics considère que l’événement ne s’est pas produit (par exemple, pas de maladie cardiaque). Il est très courant d’utiliser la régression logistique binomiale pour prédire si les cas peuvent être correctement classés (c’est-à-dire prédits) à partir des variables indépendantes. Par conséquent, il devient nécessaire de disposer d’une méthode permettant d’évaluer l’efficacité de la classification prédite par rapport à la classification réelle. Il existe de nombreuses méthodes pour évaluer cela, leur utilité dépendant souvent de la nature de l’étude menée. Cependant, toutes les méthodes tournent autour des classifications observées et prédites, qui sont présentées dans le « Tableau de classification », comme indiqué ci-dessous:
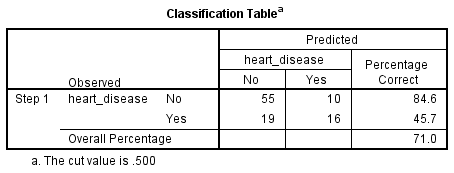
Tout d’abord, remarquez que le tableau a un indice qui indique : « La valeur de coupure est de 0,500 ». Cela signifie que si la probabilité qu’un cas soit classé dans la catégorie « oui » est supérieure à 0,500, alors ce cas particulier est classé dans la catégorie « oui ». Sinon, le cas est classé dans la catégorie « non » (comme mentionné précédemment). Alors que le tableau de classification semble être très simple, il fournit en fait beaucoup d’informations importantes sur votre résultat de régression logistique binomiale, notamment :
- A. Le pourcentage d’exactitude de la classification (PAC), qui reflète le pourcentage de cas qui peuvent être correctement classés comme » non » maladie cardiaque avec les variables indépendantes ajoutées (pas seulement le modèle global).
- B. La sensibilité, qui est le pourcentage de cas qui avaient la caractéristique observée (par ex, « oui » pour les maladies cardiaques) qui ont été correctement prédits par le modèle (c’est-à-dire les vrais positifs).
- C. Spécificité, qui est le pourcentage de cas qui ne présentaient pas la caractéristique observée (par exemple, « non » pour les maladies cardiaques) et qui ont également été correctement prédits comme ne présentant pas la caractéristique observée (c’est-à-dire, vrais négatifs).
- D. La valeur prédictive positive, qui est le pourcentage de cas correctement prédits « avec » la caractéristique observée par rapport au nombre total de cas prédits comme ayant la caractéristique.
- E. La valeur prédictive négative, qui est le pourcentage de cas correctement prédits « sans » la caractéristique observée par rapport au nombre total de cas prédits comme n’ayant pas la caractéristique.
Si vous n’êtes pas sûr de savoir comment interpréter la PAC, la sensibilité, la spécificité, la valeur prédictive positive et la valeur prédictive négative du » Tableau de classification « , nous vous expliquons comment procéder dans notre guide de la régression logistique binomiale améliorée.
Variables de l’équation
Le tableau » Variables de l’équation » indique la contribution de chaque variable indépendante au modèle et sa signification statistique. Ce tableau est présenté ci-dessous :
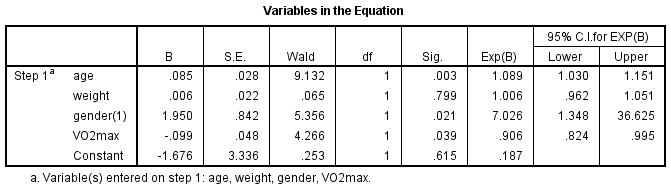
Le test de Wald (colonne « Wald ») est utilisé pour déterminer la signification statistique de chacune des variables indépendantes. La signification statistique du test se trouve dans la colonne » Sig. « . Ces résultats montrent que l’âge (p = 0,003), le sexe (p = 0,021) et la VO2max (p = 0,039) ont contribué de manière significative au modèle/à la prédiction, mais que le poids (p = 0,799) n’a pas contribué de manière significative au modèle. Vous pouvez utiliser les informations du tableau » Variables de l’équation » pour prédire la probabilité qu’un événement se produise en fonction d’une variation d’une unité d’une variable indépendante lorsque toutes les autres variables indépendantes sont maintenues constantes. Par exemple, le tableau montre que la probabilité d’avoir une maladie cardiaque (catégorie « oui ») est 7,026 fois plus élevée pour les hommes que pour les femmes. Si vous ne savez pas comment utiliser les rapports de cotes pour faire des prédictions, découvrez nos guides améliorés sur notre page Caractéristiques : Aperçu.
Mise en commun
Sur la base des résultats ci-dessus, nous pourrions présenter les résultats de l’étude comme suit (N.B., cela n’inclut pas les résultats de vos tests d’hypothèses) :
- Général
Une régression logistique a été effectuée pour vérifier les effets de l’âge, du poids, du sexe et de la VO2max sur la probabilité que les participants aient une maladie cardiaque. Le modèle de régression logistique était statistiquement significatif, χ2(4) = 27,402, p < ,0005. Le modèle expliquait 33,0 % (Nagelkerke R2) de la variance des maladies cardiaques et classait correctement 71,0 % des cas. Les hommes étaient 7,02 fois plus susceptibles de présenter une maladie cardiaque que les femmes. L’augmentation de l’âge était associée à une probabilité accrue de présenter une maladie cardiaque, mais l’augmentation de la VO2max était associée à une réduction de la probabilité de présenter une maladie cardiaque.
En plus de la rédaction ci-dessus, vous devez également inclure : (a) les résultats des tests d’hypothèses que vous avez effectués ; (b) les résultats du » Tableau de classification « , notamment la sensibilité, la spécificité, la valeur prédictive positive et la valeur prédictive négative ; et (c) les résultats du tableau » Variables de l’équation « , notamment les variables prédictives qui étaient statistiquement significatives et les prédictions qui peuvent être faites sur la base de l’utilisation des rapports de cotes. Si vous ne savez pas comment procéder, nous vous montrons dans notre guide de la régression logistique binomiale améliorée. Nous vous montrons également comment rédiger les résultats de vos tests d’hypothèses et de la régression logistique binomiale si vous devez les présenter dans une dissertation/thèse, un travail ou un rapport de recherche. Nous utilisons pour cela les styles Harvard et APA. Vous pouvez en savoir plus sur notre contenu amélioré sur notre page Caractéristiques : Aperçu.