Les variables catégorielles peuvent représenter le développement d’une maladie, une augmentation de la gravité de la maladie, la mortalité, ou toute autre variable composée de deux niveaux ou plus. Pour résumer l’association entre deux variables catégorielles avec les niveaux R et C, nous créons des tableaux croisés, ou tableaux RxC (« Row « x « Column » ou tableaux de contingence), qui résument les fréquences observées des résultats catégoriels parmi différents groupes de sujets. Nous nous concentrerons ici sur les tableaux 2 x 2.
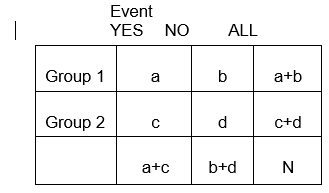
En général, les tableaux 2 x 2 résument la fréquence des événements liés à la santé (ou autres) parmi différents groupes, comme illustré ci-dessous dans lequel le groupe 1 peut représenter les patients qui ont reçu une thérapie standard, et le groupe 2 pourrait être les patients qui ont reçu une nouvelle thérapie expérimentale.
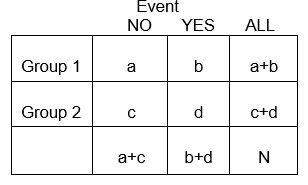
Exemple:
La variable de résultat primaire des essais Kawasaki était le développement d’anomalies des artères coronaires (AC), une variable dichotomique. L’un des objectifs de l’étude était de comparer les probabilités de développer des anomalies de l’AC sous traitement à l’aspirine (ASA) ou à la gammaglobuline (GG).

Nous pourrions être intéressés de savoir si la fréquence des anomalies des artères coronaires différait entre ces deux groupes, c’est-à-dire , l’un d’entre eux était-il associé à moins d’anomalies. La réponse à ce type de questions dépend de la comparaison des fréquences de ces événements de santé dans les deux groupes de traitement. Selon la conception de l’étude, on peut comparer soit la probabilité des événements, soit les chances qu’un événement se produise.
Probabilité et chances de développer un AC dans chacun des bras de traitement
La probabilité est calculée comme le nombre de valeurs « oui » dans chaque catégorie de traitement divisé par le nombre total dans la catégorie de traitement.
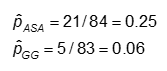
Les chances sont #oui / #non. Ici,
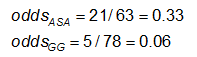
Toujours remarquer si le résultat est dans les lignes ou dans les colonnes ; il est très facile de les mélanger !
Lorsque nous avons examiné l’association entre une variable binaire et un résultat continu, nous avons résumé l’association en termes de différence de moyennes. Quelles statistiques sont appropriées pour représenter la différence entre deux groupes en ce qui concerne la probabilité d’un événement binaire ? Il existe au moins trois façons de résumer l’association :
Différence de risque RD = p1 – p2
Risque relatif (Risk Ratio) RR = p1 / p2
Odds Ratio OR = odds1/ odds2 = /
Le plan d’étude détermine laquelle de ces mesures d’effet est appropriée. Dans une étude cas/témoin, le risque relatif ne peut pas être évalué, et l’odds ratio (OR) est la mesure appropriée. Cependant, l’OR fournira une bonne estimation du risque relatif pour les événements rares (c’est-à-dire si p est petit, généralement 0,10 ou moins).
Les études transversales évaluent la prévalence des mesures de santé, donc l’odds ratio est approprie. Avec les études de cohorte prospectives, soit un ratio de taux, soit un ratio de risque est approprié, bien qu’un odds ratio puisse également être calculé,
Pour un examen plus détaillé des mesures d’effet, voir le module d’épidémiologie en ligne sur les « Mesures d’association. »
Exemple : En utilisant les données précédentes sur les anomalies de l’AC, les mesures d’effet pour ceux qui utilisent l’AAS (aspirine) par rapport aux gammaglobulines (GG) sont les suivantes :
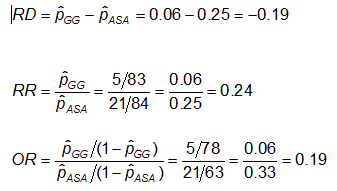

Exercice : Considérez les mesures de l’effet dans l’exemple précédent. Pourquoi le rapport de risque et l’odds ratio sont-ils si différents (le RR suggère que, par rapport au groupe traité uniquement par l’AAS, le risque d’anomalies coronaires est est 1/4 aussi élevé pour les personnes traitées par GG ; tandis que l’OR suggère que le risque est 1/5 aussi élevé) ?
Autres façons d’exprimer l’hypothèse nulle
Pour un tableau 2×2, l’hypothèse nulle peut équivalemment être écrite en termes de probabilités elles-mêmes, ou de différence de risque, de risque relatif, ou d’odds ratio. Dans chaque cas, l’hypothèse nulle affirme qu’il n’y a pas de différence entre les deux groupes.
H0 : p1 = p2
H1 : p1 ≠ p2
H0 : p1 – p2 = 0 (RD=0)
H1 : RD ≠ 0
H0 : p1/ p2 = 1 (RR=1)
H1 : RR ≠ 1
H0 : OR = 1
H1 : OR ≠ 1
Le test du chi-deux
La différence de fréquence du résultat entre les deux groupes peut être évaluée avec le test du chi-deux.
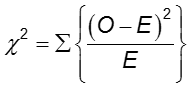
Dans chaque cellule du tableau 2×2, O est la fréquence observée des cellules et E est la fréquence attendue des cellules en supposant que l’hypothèse nulle est vraie. La somme est calculée sur les 2×2 = 4 cellules du tableau. Tant que la fréquence attendue dans chaque cellule est d’au moins cinq, la valeur de chi-deux calculée a une distribution χ2 avec 1 degré de liberté (df).
Rejeter l’hypothèse nulle si ![]() . Pour α = 0,05, la valeur critique est de 3,84.
. Pour α = 0,05, la valeur critique est de 3,84.
Exemple:
Fréquences observées

S’il n’y a pas d’association entre le traitement et la maladie, la proportion de cas parmi les personnes traitées et non traitées serait la même et serait égale à la proportion de cas dans l’ensemble de la population étudiée.
Fréquences attendues :
En tout, parmi les 167 enfants, il y a 26 avec des anomalies de l’AC et 141 sans anomalies de l’AC. La proportion avec des anomalies de l’AC est de 26/167, soit 16 %. Si l’hypothèse nulle est vraie, et que les deux groupes de traitement ont la même probabilité d’anomalies de l’AC, alors nous nous attendons à ce qu’environ 16% dans chaque groupe aient des anomalies de l’AC.
Donc, dans le groupe GG de n=83, nous nous attendons à ce que 16% des 83 aient des anomalies de l’AC. Cela se calcule comme suit : 0,16 x 83 = 13, et on appelle cela la fréquence attendue dans cette cellule.
Nous pouvons l’écrire comme suit
E11 = fréquence attendue dans la ligne 1, colonne 1
= nombre attendu dans le groupe 1 qui présente l’événement (ligne 1, colonne 1)
Et nous le calculons comme suit
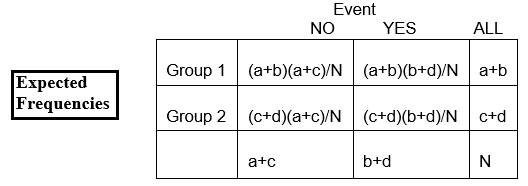
E11 = (proportion dont on s’attend à ce qu’elle présente l’événement) x nombre total dans le (groupe) ligne 1
= x nombre dans (groupe) ligne 1
En utilisant la notation du tableau,
E11 = x (a+b)
Et nous réécrivons souvent ceci simplement comme
E11 = (a+b)(a+c)/N
Dans notre exemple, calculons la fréquence attendue dans la première cellule ( E11) :
E11 = (83)(26)/167 = 12.92
Nous pouvons calculer les fréquences attendues dans les autres cellules de la même manière
La proportion globale sans anomalies de l’AC est de 141/167, soit 84%. Nous nous attendons à ce qu’environ 84 % des personnes du groupe ASA ne présentent pas d’anomalies de l’AC, de sorte que la fréquence attendue à la ligne 2, colonne 2, est E22 = 84 % de 84, soit 0,84 x 84, ou environ 71.
En utilisant le tableau ci-dessus, nous pourrions simplement la calculer comme suit
E22 = (c+d)(b+d)/N = (84)(141)/167 = 70.92
Exercice : combien d’enfants du groupe ASA devraient présenter des anomalies de l’AC si l’hypothèse nulle est vraie ? Essayez de le calculer avant de regarder la réponse ci-dessous.
Notez que les fréquences observées prennent des valeurs entières, tandis que les fréquences attendues peuvent prendre des valeurs décimales.
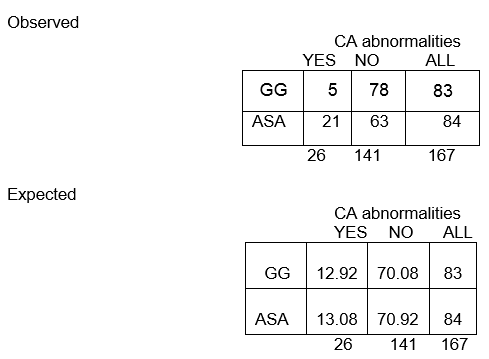
Nous nous attendons à ce que près de 13 enfants du groupe GG présentent des anomalies de l’AC, mais seuls 5 l’ont réellement fait !
Notez qu’une fois que nous avons calculé une fréquence attendue, les autres peuvent être obtenues facilement par soustraction ! Le nombre de degrés de liberté est égal au nombre de cellules dont la fréquence attendue doit être calculée ; dans un tableau 2 x 2, ce nombre est de 1.
Statistique du test du chi-carré
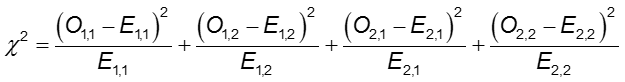
où O1,1 et E1,1 sont les effectifs observés et attendus dans la cellule de la première ligne et de la première colonne. Par exemple, O1,1 = a et E1,1 =(a+b)(a+c)/N. Si les effectifs observés des cellules sont suffisamment différents des effectifs attendus, alors nous ne pouvons pas conclure que les deux probabilités sont égales.
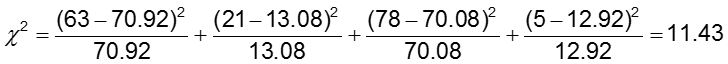
H0 : Les probabilités d’anomalies du CA sont les mêmes dans tous les groupes de traitement (OR=1)
H1 : Les probabilités d’anomalies de l’AC ne sont pas les mêmes dans tous les groupes de traitement (OR≠1)
Le niveau de signification est de 0.05.
La statistique de test est calculée pour être de 11,43. Comme notre statistique de test est supérieure à 3,84 (la valeur critique du chi-deux pour 1 degré de liberté), nous rejetons l’hypothèse nulle et concluons que les probabilités d’anomalies de l’AC ne sont pas les mêmes dans les deux groupes de traitement.
retour en haut | page précédente | page suivante