Dernière mise à jour le 13 juillet 2020
La théorie de l’information est un sous-domaine des mathématiques qui s’intéresse à la transmission de données sur un canal bruyant.
L’une des pierres angulaires de la théorie de l’information est l’idée de quantifier la quantité d’information contenue dans un message. Plus généralement, cela peut être utilisé pour quantifier l’information dans un événement et une variable aléatoire, appelée entropie, et est calculé à l’aide de la probabilité.
Le calcul de l’information et de l’entropie est un outil utile dans l’apprentissage automatique et est utilisé comme base pour des techniques telles que la sélection des caractéristiques, la construction d’arbres de décision et, plus généralement, l’ajustement des modèles de classification. En tant que tel, un praticien de l’apprentissage automatique a besoin d’une solide compréhension et d’une intuition pour l’information et l’entropie.
Dans ce post, vous découvrirez une introduction douce à l’entropie de l’information.
Après avoir lu ce post, vous saurez :
- La théorie de l’information concerne la compression et la transmission des données et s’appuie sur la probabilité et soutient l’apprentissage automatique.
- L’information fournit un moyen de quantifier la quantité de surprise pour un événement mesuré en bits.
- L’entropie fournit une mesure de la quantité moyenne d’information nécessaire pour représenter un événement tiré d’une distribution de probabilité pour une variable aléatoire.
Démarrez votre projet avec mon nouveau livre Probability for Machine Learning, comprenant des tutoriels étape par étape et les fichiers de code source Python pour tous les exemples.
Démarrons.
- Mise à jour nov/2019 : ajout d’un exemple de probabilité par rapport à l’information et plus sur l’intuition de l’entropie.

Une douce introduction à l’entropie de l’information
Photo de Cristiano Medeiros Dalbem, certains droits réservés.
Aperçu
Ce tutoriel est divisé en trois parties ; ce sont :
- Qu’est-ce que la théorie de l’information ?
- Calculer l’information pour un événement
- Calculer l’entropie pour une variable aléatoire
Qu’est-ce que la théorie de l’information ?
La théorie de l’information est un domaine d’étude qui s’intéresse à la quantification de l’information pour la communication.
C’est un sous-domaine des mathématiques et il s’intéresse à des sujets comme la compression des données et les limites du traitement du signal. Le domaine a été proposé et développé par Claude Shannon alors qu’il travaillait à la compagnie de téléphone américaine Bell Labs.
La théorie de l’information s’intéresse à la représentation des données de manière compacte (une tâche connue sous le nom de compression des données ou codage de la source), ainsi qu’à leur transmission et leur stockage d’une manière robuste aux erreurs (une tâche connue sous le nom de correction des erreurs ou codage du canal).
– Page 56, Machine Learning : A Probabilistic Perspective, 2012.
Un concept fondateur de l’information est la quantification de la quantité d’information dans des choses comme les événements, les variables aléatoires et les distributions.
La quantification de la quantité d’information nécessite l’utilisation de probabilités, d’où la relation entre la théorie de l’information et les probabilités.
Les mesures de l’information sont largement utilisées en intelligence artificielle et en apprentissage automatique, par exemple dans la construction d’arbres de décision et l’optimisation de modèles de classificateurs.
En tant que tel, il existe une relation importante entre la théorie de l’information et l’apprentissage automatique et un praticien doit être familier avec certains des concepts de base du domaine.
Pourquoi unifier la théorie de l’information et l’apprentissage automatique ? Parce qu’elles sont les deux faces d’une même pièce. La théorie de l’information et l’apprentissage automatique ont toujours leur place ensemble. Les cerveaux sont les systèmes de compression et de communication par excellence. Et les algorithmes de pointe tant pour la compression des données que pour les codes correcteurs d’erreurs utilisent les mêmes outils que l’apprentissage automatique.
– Page v, Théorie de l’information, inférence et algorithmes d’apprentissage, 2003.
Vous voulez apprendre les probabilités pour l’apprentissage automatique
Suivez dès maintenant mon cours intensif gratuit de 7 jours par courriel (avec un exemple de code).
Cliquez pour vous inscrire et obtenir également une version PDF Ebook gratuite du cours.
Téléchargez votre mini-cours gratuit
Calculez l’information d’un événement
La quantification de l’information est le fondement du domaine de la théorie de l’information.
L’intuition derrière la quantification de l’information est l’idée de mesurer le degré de surprise d’un événement. Les événements qui sont rares (faible probabilité) sont plus surprenants et ont donc plus d’information que les événements qui sont communs (forte probabilité).
- Événement à faible probabilité : Information élevée (surprenant).
- Événement à forte probabilité : Faible information (peu surprenant).
L’intuition de base de la théorie de l’information est qu’apprendre qu’un événement peu probable s’est produit est plus informatif qu’apprendre qu’un événement probable s’est produit.
– Page 73, Deep Learning, 2016.
Les événements rares sont plus incertains ou plus surprenants et nécessitent plus d’informations pour les représenter que les événements courants.
Nous pouvons calculer la quantité d’informations qu’il y a dans un événement en utilisant la probabilité de l’événement. C’est ce qu’on appelle » l’information de Shannon « , » l’auto-information » ou simplement » l’information « , et on peut la calculer pour un événement discret x comme suit :
- information(x) = -log( p(x) )
Où log() est le logarithme de base 2 et p(x) la probabilité de l’événement x.
Le choix du logarithme en base-2 signifie que les unités de la mesure de l’information sont en bits (chiffres binaires). Cela peut être directement interprété dans le sens du traitement de l’information comme le nombre de bits nécessaires pour représenter l’événement.
Le calcul de l’information est souvent écrit sous la forme h() ; par exemple :
- h(x) = -log( p(x) )
Le signe négatif garantit que le résultat est toujours positif ou nul.
L’information sera nulle lorsque la probabilité d’un événement est de 1,0 ou une certitude, par exemple, il n’y a pas de surprise.
Donnons des exemples concrets.
Envisageons le lancer d’une seule pièce de monnaie équitable. La probabilité de pile (et de face) est de 0,5. Nous pouvons calculer l’information pour un pile ou face en Python en utilisant la fonction log2().
..
|
1
2
3
4
5
. 6
7
8
|
# calculer l’information pour un tirage à pile ou face
from math import log2
# probabilité de l’événement
p = 0.5
# calculer l’information pour l’événement
h = -log2(p)
# imprimer le résultat
print(‘p(x)=%.3f, information : %.3f bits’ % (p, h)).
|
L’exécution de l’exemple imprime la probabilité de l’événement comme étant de 50% et le contenu en information pour l’événement comme étant de 1 bit.
|
1
|
p(x)=0.500, information : 1.000 bits
|
Si la même pièce de monnaie était tirée à pile ou face n fois, alors l’information pour cette séquence de tirages serait de n bits.
Si la pièce n’était pas juste et que la probabilité d’une tête était plutôt de 10% (0,1), alors l’événement serait plus rare et nécessiterait plus de 3 bits d’information.
|
1
|
p(x)=0.100, information : 3,322 bits
|
Nous pouvons également explorer l’information contenue dans un seul lancer d’un dé équitable à six faces, par exemple l’information contenue dans un 6.
Nous savons que la probabilité de lancer un nombre quelconque est de 1/6, ce qui est un nombre plus petit que 1/2 pour un tirage à pile ou face, nous nous attendrions donc à plus de surprise ou à une plus grande quantité d’information.
|
1
2
3
4
5
6
7
8
. |
# calculer l’information pour un lancer de dé
from math import log2
# probabilité de l’événement
p = 1.0 / 6,0
# calculer l’information pour l’événement
h = -log2(p)
# imprimer le résultat
print(‘p(x)=%.3f, information : %.3f bits’ % (p, h)).
|
En exécutant l’exemple, nous pouvons voir que notre intuition est correcte et qu’effectivement, il y a plus de 2,5 bits d’information dans un seul lancer de dé juste.
|
1
|
p(x)=0.167, information : 2,585 bits
|
D’autres logarithmes peuvent être utilisés à la place de la base 2. Par exemple, il est également courant d’utiliser le logarithme naturel qui utilise la base-e (nombre d’Euler) pour calculer l’information, auquel cas les unités sont appelées » nats « .
Nous pouvons développer davantage l’intuition selon laquelle les événements à faible probabilité ont plus d’information.
Pour rendre cela clair, nous pouvons calculer l’information pour des probabilités comprises entre 0 et 1 et tracer l’information correspondante pour chacune. Nous pouvons ensuite créer un graphique de la probabilité par rapport à l’information. Nous nous attendrions à ce que le tracé se courbe vers le bas, des probabilités faibles avec une information élevée aux probabilités élevées avec une information faible.
L’exemple complet est repris ci-dessous.
|
1
2
3
4
5
6
7
8
9
10
11
.. 12
13
|
# comparer la probabilité à l’entropie d’information
from math import log2
from matplotlib import pyplot
# liste de probabilités
probs =
# calculer l’information
info =
# tracer la probabilité par rapport à l’information
pyplot.plot(probs, info, marker=’.’)
pyplot.title(‘Probabilité vs Information’)
pyplot.xlabel(‘Probabilité’)
pyplot.ylabel(‘Information’)
pyplot.show()
|
L’exécution de l’exemple crée le graphique de la probabilité par rapport à l’information en bits.
Nous pouvons voir la relation attendue où les événements à faible probabilité sont plus surprenants et portent plus d’informations, et le complément d’événements à forte probabilité porte moins d’informations.
Nous pouvons également voir que cette relation n’est pas linéaire, elle est en fait légèrement sous-linéaire. Cela est logique étant donné l’utilisation de la fonction logarithmique.
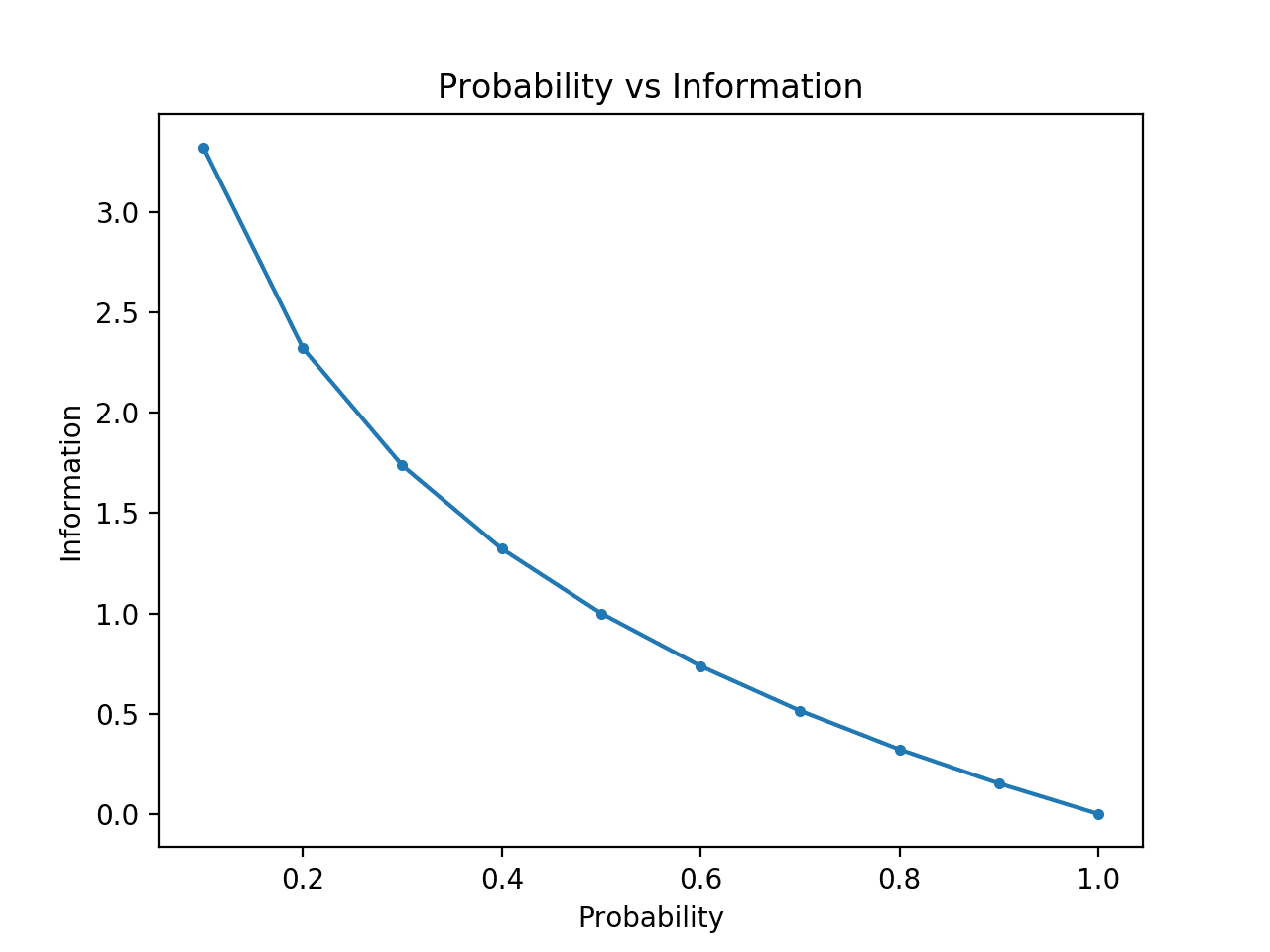
Plot de la probabilité par rapport à l’information
Calculer l’entropie pour une variable aléatoire
Nous pouvons également quantifier la quantité d’information contenue dans une variable aléatoire.
Par exemple, si nous voulions calculer l’information pour une variable aléatoire X avec une distribution de probabilité p, cela pourrait s’écrire sous la forme d’une fonction H() ; par exemple :
- H(X)
En effet, calculer l’information pour une variable aléatoire revient à calculer l’information pour la distribution de probabilité des événements pour la variable aléatoire.
Le calcul de l’information pour une variable aléatoire est appelé « entropie d’information », « entropie de Shannon », ou simplement « entropie ». Elle est liée à l’idée d’entropie de la physique par analogie, dans la mesure où toutes deux concernent l’incertitude.
L’intuition de l’entropie est qu’il s’agit du nombre moyen de bits nécessaires pour représenter ou transmettre un événement tiré de la distribution de probabilité pour la variable aléatoire.
… l’entropie de Shannon d’une distribution est la quantité d’information attendue dans un événement tiré de cette distribution. Elle donne une limite inférieure au nombre de bits nécessaires en moyenne pour coder des symboles tirés d’une distribution P.
– Page 74, Deep Learning, 2016.
L’entropie peut être calculée pour une variable aléatoire X avec k dans K états discrets comme suit :
- H(X) = -somme(chaque k dans K p(k) * log(p(k)))
C’est-à-dire le négatif de la somme de la probabilité de chaque événement multiplié par le log de la probabilité de chaque événement.
Comme l’information, la fonction log() utilise la base 2 et les unités sont les bits. Un logarithme naturel peut être utilisé à la place et les unités seront des nats.
La plus faible entropie est calculée pour une variable aléatoire qui a un seul événement avec une probabilité de 1,0, une certitude. La plus grande entropie pour une variable aléatoire sera si tous les événements ont la même probabilité.
Nous pouvons considérer un lancer de dé équitable et calculer l’entropie de la variable. Chaque résultat a la même probabilité de 1/6, il s’agit donc d’une distribution de probabilité uniforme. Nous nous attendrions donc à ce que l’information moyenne soit la même information pour un seul événement calculé dans la section précédente.
|
1
2
3
4
5
6
7
8
9
10
|
# calculer l’entropie pour un jet de dé. roll
from math import log2
# le nombre d’événements
n = 6
# la probabilité d’un événement
p = 1.0 /n
# calculer l’entropie
entropie = -sum()
# imprimer le résultat
print(‘entropie : %.3f bits’ % entropie)
|
L’exécution de l’exemple calcule l’entropie comme étant supérieure à 2,5 bits, ce qui correspond à l’information d’une seule issue. Cela est logique, car l’information moyenne est la même que la borne inférieure de l’information puisque toutes les issues ont la même probabilité.
|
1
|
entropie : 2.585 bits
|
Si nous connaissons la probabilité de chaque événement, nous pouvons utiliser la fonction SciPy entropy() pour calculer directement l’entropie.
Par exemple :
|
1
2
3
4
5
6
7
8
|
# calculer l’entropie pour un lancer de dé
from scipy.stats import entropy
# probabilités discrètes
p =
# calculer l’entropie
e = entropy(p, base=2)
# imprimer le résultat
print(‘entropy : %.3f bits’ % e)
|
L’exécution de l’exemple rapporte le même résultat que celui que nous avons calculé manuellement.
|
1
|
entropie : 2.585 bits
|
Nous pouvons développer davantage l’intuition de l’entropie des distributions de probabilité.
Rappelons que l’entropie est le nombre de bits nécessaires pour représenter un pair tiré au hasard de la distribution, par exemple un événement moyen. Nous pouvons explorer cela pour une distribution simple avec deux événements, comme un pile ou face, mais explorer différentes probabilités pour ces deux événements et calculer l’entropie pour chacun.
Dans le cas où un événement domine, comme une distribution de probabilité asymétrique, alors il y a moins de surprise et la distribution aura une entropie plus faible. Dans le cas où aucun événement ne domine un autre, comme une distribution de probabilité égale ou approximativement égale, alors nous nous attendons à une entropie plus grande ou maximale.
- Distribution de probabilité asymétrique (sans surprise) : Faible entropie.
- Distribution de probabilité équilibrée (surprenante) : entropie élevée.
Si nous passons d’une probabilité asymétrique à une probabilité égale des événements dans la distribution, nous nous attendrions à ce que l’entropie commence à un niveau bas et augmente, plus précisément à partir de l’entropie la plus faible de 0.0 pour les événements avec impossibilité/certitude (probabilité de 0 et 1 respectivement) à la plus grande entropie de 1,0 pour les événements à probabilité égale.
L’exemple ci-dessous met cela en œuvre, en créant chaque distribution de probabilité dans cette transition, en calculant l’entropie pour chacune et en traçant le résultat.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# comparer les distributions de probabilité par rapport à l’entropie
from math import log2
from matplotlib import pyplot
# calculer l’entropie
def entropy(events, ets=1e-15) :
return -sum()
# définir les probabilités
probs =
# créer une distribution de probabilités
dists = for p in probs]
# calculer l’entropie pour chaque distribution
ents =
# tracer la distribution de probabilité en fonction de l’entropie
pyplot.plot(probs, ents, marker=’.’)
pyplot.title(‘Probability Distribution vs Entropy’)
pyplot.xticks(probs, )
pyplot.xlabel(‘Distribution de probabilités’)
pyplot.ylabel(‘Entropie (bits)’)
pyplot.show()
|
L’exécution de l’exemple crée les 6 distributions de probabilités avec la probabilité jusqu’aux probabilités.
Comme prévu, nous pouvons voir que lorsque la distribution des événements passe de biaisée à équilibrée, l’entropie augmente des valeurs minimales aux valeurs maximales.
C’est-à-dire que si l’événement moyen tiré d’une distribution de probabilité n’est pas surprenant, nous obtenons une entropie plus faible, alors que s’il est surprenant, nous obtenons une entropie plus grande.
Nous pouvons voir que la transition n’est pas linéaire, qu’elle est super linéaire. Nous pouvons également voir que cette courbe est symétrique si nous avons continué la transition vers et vers pour les deux événements, formant une forme de parabole inversée.
Notez que nous avons dû ajouter une valeur minuscule à la probabilité lors du calcul de l’entropie pour éviter de calculer le logarithme d’une valeur nulle, ce qui donnerait une infinité sur pas un nombre.
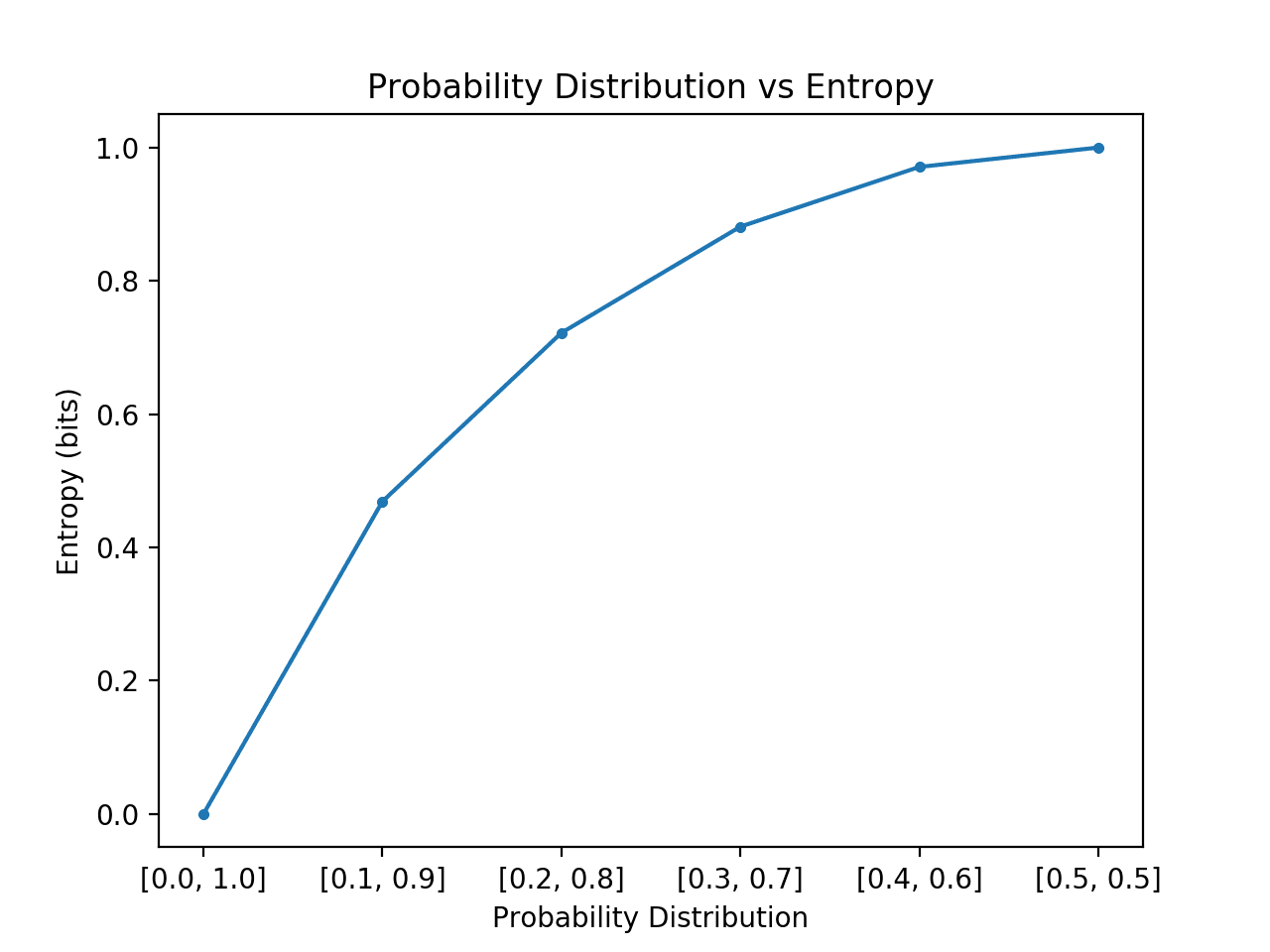
Plot de la distribution des probabilités par rapport à l’entropie
Le calcul de l’entropie d’une variable aléatoire fournit la base d’autres mesures telles que l’information mutuelle (gain d’information).
L’entropie fournit également la base pour calculer la différence entre deux distributions de probabilité avec l’entropie croisée et la divergence KL.
Lectures complémentaires
Cette section fournit plus de ressources sur le sujet si vous cherchez à approfondir.
Livres
- Théorie de l’information, Inférence et algorithmes d’apprentissage, 2003.
Chapitres
- Section 2.8 : Théorie de l’information, Apprentissage automatique : A Probabilistic Perspective, 2012.
- Section 1.6 : Théorie de l’information, Reconnaissance des formes et apprentissage automatique, 2006.
- Section 3.13 Théorie de l’information, Apprentissage profond, 2016.
API
- scipy.stats.entropy API
Articles
- Entropie (théorie de l’information), Wikipédia.
- Gain d’information dans les arbres de décision, Wikipédia.
- Ratio de gain d’information, Wikipédia.
Résumé
Dans ce billet, vous avez découvert une introduction douce à l’entropie de l’information.
Spécifiquement, vous avez appris :
- La théorie de l’information s’intéresse à la compression et à la transmission des données et s’appuie sur les probabilités et soutient l’apprentissage automatique.
- L’entropie fournit un moyen de quantifier la quantité de surprise pour un événement mesuré en bits.
- L’entropie fournit une mesure de la quantité moyenne d’information nécessaire pour représenter un événement tiré d’une distribution de probabilité pour une variable aléatoire.
Avez-vous des questions ?
Posez vos questions dans les commentaires ci-dessous et je ferai de mon mieux pour y répondre.
Maîtrisez les probabilités pour l’apprentissage automatique !

Développez votre compréhension de la probabilité
….avec seulement quelques lignes de code python
Découvrez comment dans mon nouvel Ebook :
Probabilité pour l’apprentissage automatique
Il fournit des tutoriels d’auto-apprentissage et des projets de bout en bout sur :
le théorème de Bayes, l’optimisation bayésienne, les distributions, la vraisemblance maximale, l’entropie croisée, le calibrage des modèles
et bien plus encore.
Enfin, maîtrisez l’incertitude dans vos projets
Skip the Academics. Voyez ce qu’il y a dedans