NCSS include un certo numero di strumenti per l’analisi multivariata, l’analisi dei dati con più di una variabile dipendente o Y. L’analisi dei fattori, l’analisi delle componenti principali (PCA) e l’analisi multivariata della varianza (MANOVA) sono tutte tecniche di analisi multivariata ben conosciute e sono tutte disponibili in NCSS, insieme a diverse altre procedure di analisi multivariata come indicato di seguito.
Usa i link qui sotto per saltare all’argomento di analisi multivariata che vuoi esaminare. Per vedere come questi strumenti possono esserti utili, ti consigliamo di scaricare e installare la prova gratuita di NCSS.
Salta a:
- Introduzione
- Dettagli tecnici
- Analisi dei fattori
- Analisi delle componenti principali (PCA)
- Correlazione canonica
- Equalità della covarianza
- Analisi discriminante
- T² a campione unico di Hotelling
- T².campione T²
- Campione T² di Hotelling
- Campione T² a dueSample T²
- Analisi multivariata della varianza (MANOVA)
- Analisi delle corrispondenze
- Modelli logaritmici
- Scala multidimensionale
Introduzione
Anche se il termine Analisi multivariata può essere usato per riferirsi a qualsiasi analisi che coinvolge più di una variabile (es.Ad esempio nella Regressione Multipla o GLM ANOVA), il termine analisi multivariata è usato qui e in NCSS per riferirsi a situazioni che coinvolgono dati multidimensionali con più di una variabile dipendente, Y, o risultato. Le tecniche di analisi multivariata sono usate per capire come l’insieme delle variabili di risultato come un insieme combinato sia influenzato da altri fattori, come le variabili di risultato si relazionino tra loro, o quali fattori sottostanti producano i risultati osservati nelle variabili dipendenti.
Ognuna delle procedure disponibili nella sezione Analisi Multivariata di NCSS è descritta di seguito.
Dettagli tecnici
Questa pagina ha lo scopo di fornire una panoramica generale delle capacità di NCSS per le tecniche di analisi multivariata. Se vuoi esaminare le formule e i dettagli tecnici relativi a una specifica procedura NCSS, clicca sul corrispondente link ” sotto ogni titolo per caricare la documentazione completa della procedura. Lì troverai formule, riferimenti, discussioni ed esempi o tutorial che descrivono la procedura in dettaglio.
Analisi Fattoriale
L’Analisi Fattoriale (FA) è una tecnica esplorativa applicata a un insieme di variabili di risultato che cerca di trovare i fattori sottostanti (o sottoinsiemi di variabili) da cui sono state generate le variabili osservate. Per esempio, la risposta di un individuo alle domande di un esame è influenzata da variabili sottostanti come l’intelligenza, gli anni di scuola, l’età, lo stato emotivo nel giorno del test, la quantità di pratica nel fare i test, e così via. Le risposte alle domande sono le variabili osservate o di risultato. Le variabili sottostanti e influenti sono i fattori.
L’analisi dei fattori viene effettuata sulla matrice di correlazione delle variabili osservate. Un fattore è una media ponderata delle variabili originali. L’analista dei fattori spera di trovare alcuni fattori da cui la matrice di correlazione originale può essere generata.
Di solito l’obiettivo dell’analisi dei fattori è di aiutare l’interpretazione dei dati. L’analista dei fattori spera di identificare ogni fattore come rappresentante un fattore teorico specifico. Un altro obiettivo dell’analisi dei fattori è quello di ridurre il numero di variabili. L’analista spera di ridurre l’interpretazione di un test di 200 domande allo studio di 4 o 5 fattori.
NCSS fornisce il metodo dell’asse principale dell’analisi dei fattori. I risultati possono essere ruotati usando la rotazione varimax o quartimax e i punteggi dei fattori possono essere memorizzati per ulteriori analisi. I dati di esempio, l’input della procedura e l’output sono mostrati qui sotto.
Dati campione
Input della procedura
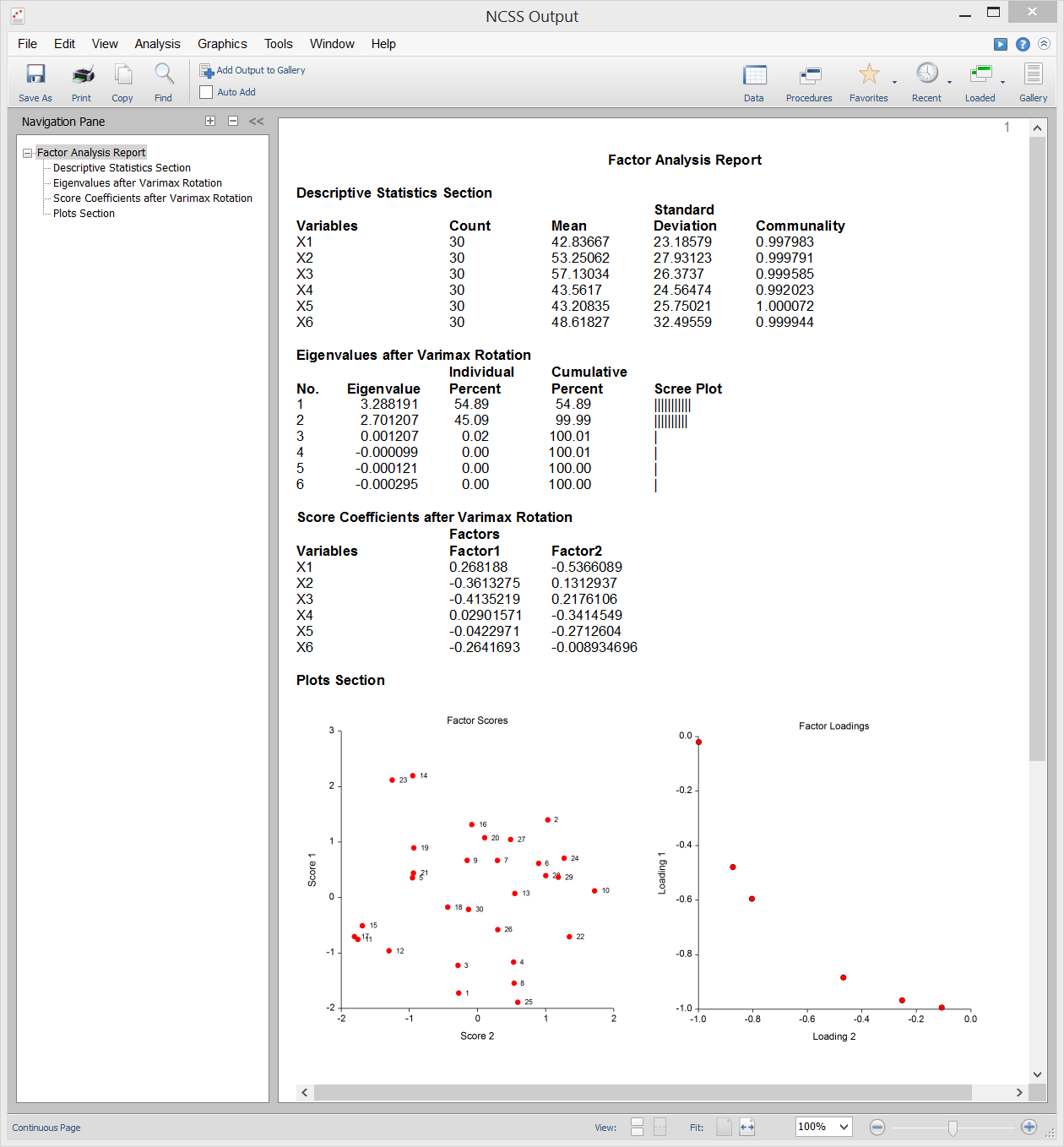
Uscita campione
Principal Components Analysis (PCA)
Principal Components Analysis (o PCA) è uno strumento di analisi dei dati che viene spesso utilizzato per ridurre la dimensionalità (o numero di variabili) da un gran numero di variabili correlate, mantenendo la maggior parte delle informazioni (ad es.variazione) il più possibile. La PCA calcola un insieme non correlato di variabili note come fattori o componenti principali. Questi fattori sono ordinati in modo che i primi conservino la maggior parte della variazione presente in tutte le variabili originali. A differenza della sua cugina Factor Analysis, la PCA produce sempre la stessa soluzione dagli stessi dati.
NCSS usa una versione a doppia precisione del moderno algoritmo QL descritto da Press (1986) per risolvere il problema autovalore-eigenvettore coinvolto nei calcoli della PCA. NCSS esegue la PCA su una matrice di correlazione o di covarianza. L’analisi può essere effettuata usando tecniche di stima robuste.
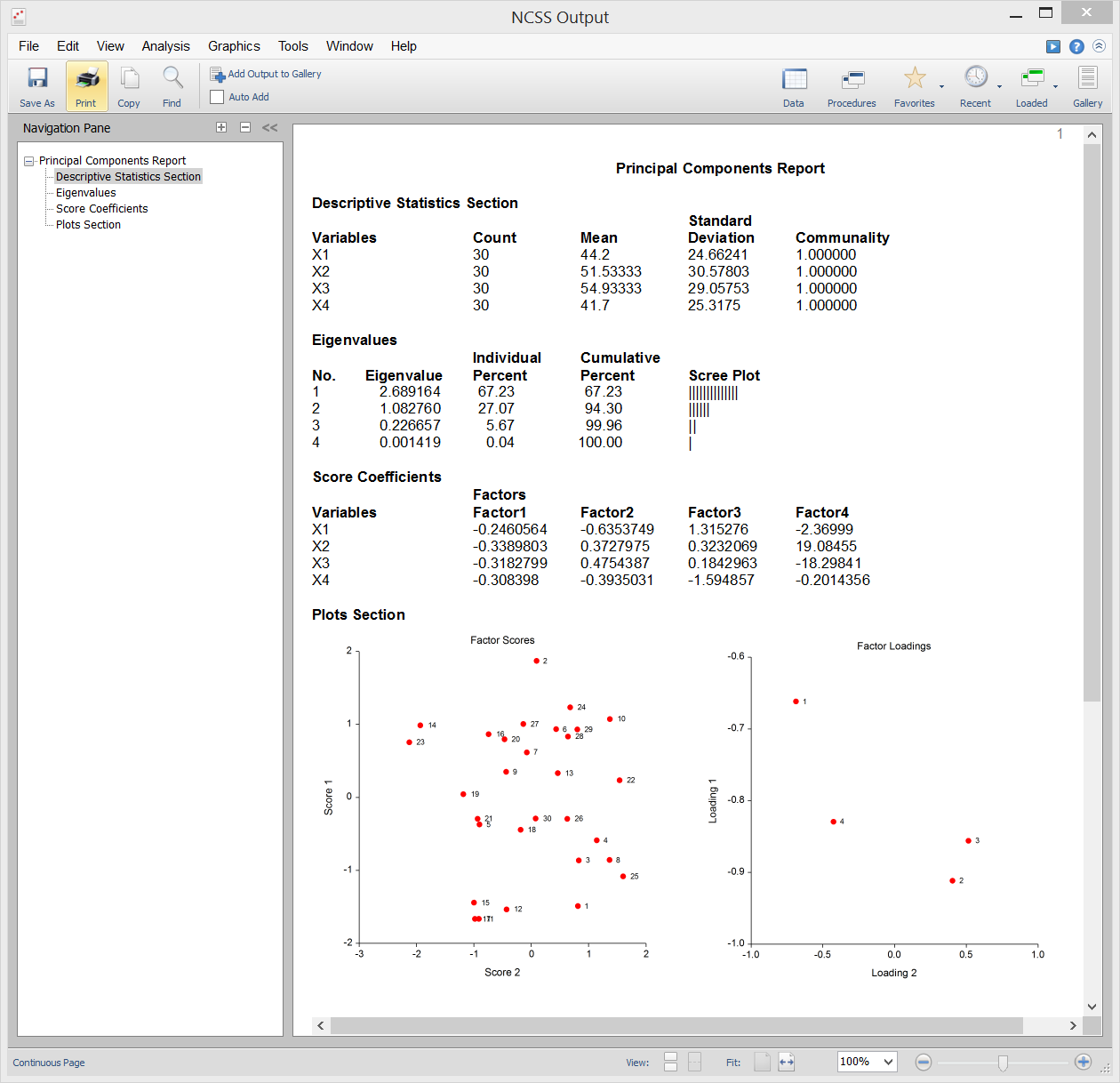
Sample Output
Correlazione canonica
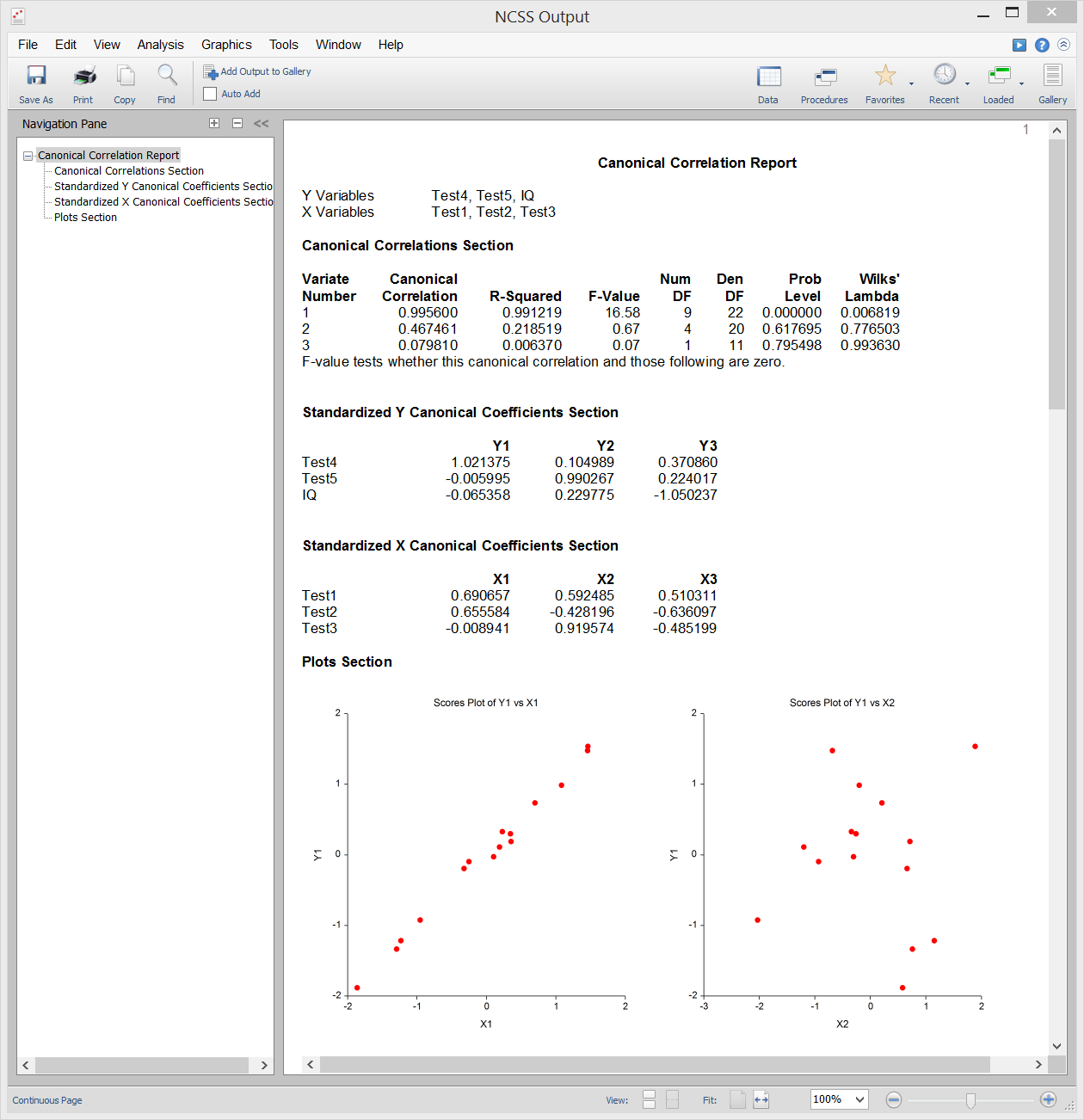
L’analisi di correlazione canonica è lo studio della relazione lineare tra due insiemi di variabili. È l’estensione multivariata dell’analisi di correlazione. A titolo illustrativo, supponiamo che un gruppo di studenti riceva due test di dieci domande ciascuno e che si voglia determinare la correlazione complessiva tra questi due test. La correlazione canonica trova una media ponderata delle domande del primo test e la correla con una media ponderata delle domande del secondo test. I pesi sono costruiti per massimizzare la correlazione tra queste due medie. Questa correlazione è chiamata il primo coefficiente di correlazione canonica. Si può poi creare un’altra serie di medie ponderate non correlate alla prima e calcolare la loro correlazione. Questa correlazione è il secondo coefficiente di correlazione canonica. Il processo continua fino a quando il numero di correlazioni canoniche è uguale al numero di variabili nel gruppo più piccolo.
La correlazione canonica fornisce il quadro multivariato più generale (l’analisi discriminante, MANOVA e la regressione multipla sono tutti casi speciali della correlazione canonica). A causa di questa generalità, la correlazione canonica è probabilmente la meno usata delle procedure multivariate.
Output campione
Uguaglianza della covarianza
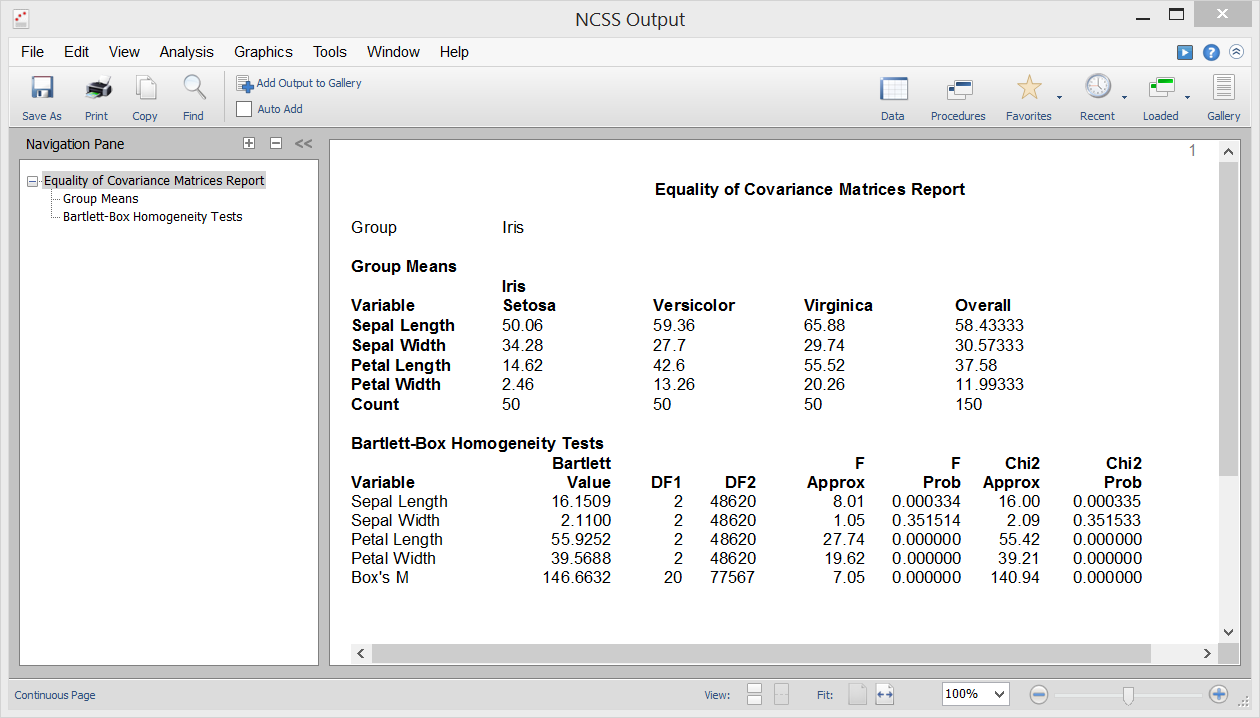
Una delle assunzioni dell’analisi discriminante, MANOVA, e varie altre procedure multivariate è che le matrici di covarianza dei singoli gruppi siano uguali (cioè omogenee tra i gruppi). La procedura Equality of Covariance in NCSS permette di testare questa ipotesi usando il test M di Box, presentato per la prima volta da Box (1949). Questa procedura produce anche il test di omogeneità univariata della varianza di Bartlett per testare l’uguaglianza della varianza tra le singole variabili.
Sample Output
Analisi discriminante
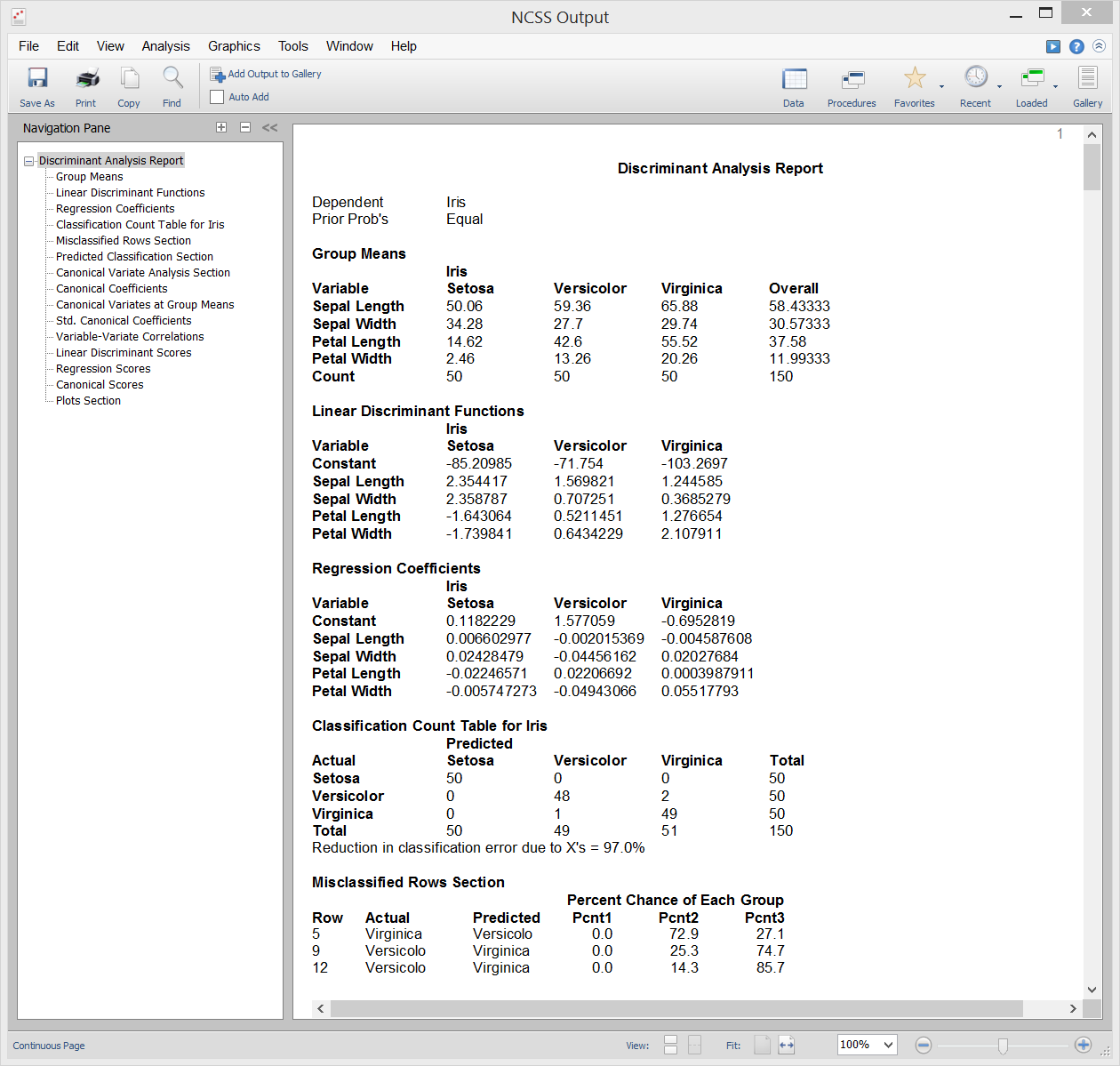
L’analisi discriminante è una tecnica usata per trovare un insieme di equazioni di predizione basate su una o più variabili indipendenti. Queste equazioni di predizione sono poi usate per classificare gli individui in gruppi. Ci sono due obiettivi comuni nell’analisi discriminante: 1. trovare un’equazione predittiva per classificare nuovi individui, e 2. interpretare l’equazione predittiva per capire meglio le relazioni tra le variabili.
In molti modi, l’analisi discriminante è molto simile all’analisi di regressione logistica. La metodologia usata per completare un’analisi discriminante è simile all’analisi di regressione logistica. Spesso si traccia ogni variabile indipendente contro la variabile di gruppo, si passa attraverso una fase di selezione delle variabili per determinare quali variabili indipendenti sono utili, e si conduce un’analisi dei residui per determinare l’accuratezza delle equazioni discriminanti.
I calcoli dell’analisi discriminante sono molto vicini alla MANOVA a una via. Infatti, i ruoli delle variabili sono semplicemente invertiti. La variabile di classificazione (fattore) nella MANOVA diventa la variabile dipendente nell’analisi discriminante. Le variabili dipendenti nella MANOVA a senso unico diventano le variabili indipendenti nell’analisi discriminante.
Sample Output
Hotelling’s One-Sample T²
Il test Hotelling’s One-Sample T² è l’estensione multivariata del comune test T di Student a un campione o a coppie. Questo test è usato quando il numero di variabili di risposta è due o più, anche se può essere usato quando c’è solo una variabile di risposta. Il test richiede l’assunzione che i dati siano approssimativamente normali multivariati, tuttavia sono forniti test di randomizzazione che non si basano su questa assunzione.
Sample Output

T² a due campioni di Hotelling
Il test T² a due campioni di Hotelling è l’estensione multivariata del comune test T a due campioni di Student per la differenza di medie. Questo test è usato quando il numero di variabili di risposta è due o più, anche se può essere usato quando c’è solo una variabile di risposta. Il test richiede le ipotesi di varianze uguali e residui normalmente distribuiti, tuttavia sono forniti test di randomizzazione che non si basano su queste ipotesi.
Sample Output

Analisi multivariata della varianza (MANOVA)
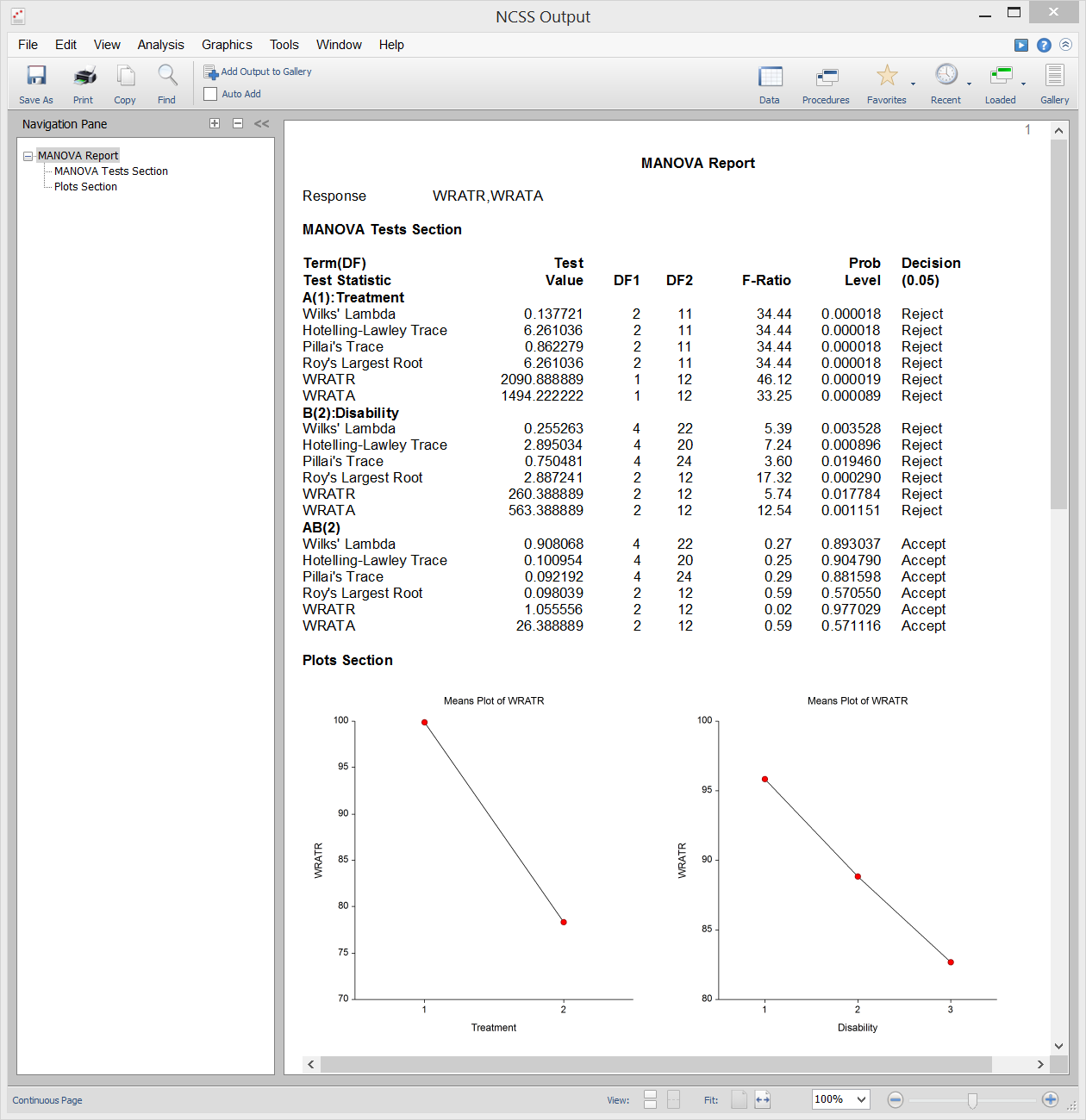
L’Analisi multivariata della varianza (o MANOVA) è un’estensione dell’ANOVA al caso in cui ci siano due o più variabili di risposta. La MANOVA è progettata per il caso in cui si hanno uno o più fattori indipendenti (ciascuno con due o più livelli) e due o più variabili dipendenti. I test di ipotesi coinvolgono il confronto di vettori di medie di gruppo.
L’estensione multivariata del test F da ANOVA non è completamente diretta. Invece, diverse altre statistiche di test sono disponibili in MANOVA: Lambda di Wilks, Hotelling-Lawley Trace, Pillai’s Trace, e Roy’s Largest Root. Le distribuzioni effettive di queste statistiche di test sono difficili da calcolare, quindi ci affidiamo ad approssimazioni basate sulla distribuzione F per calcolare i p-valori.
Sample Output
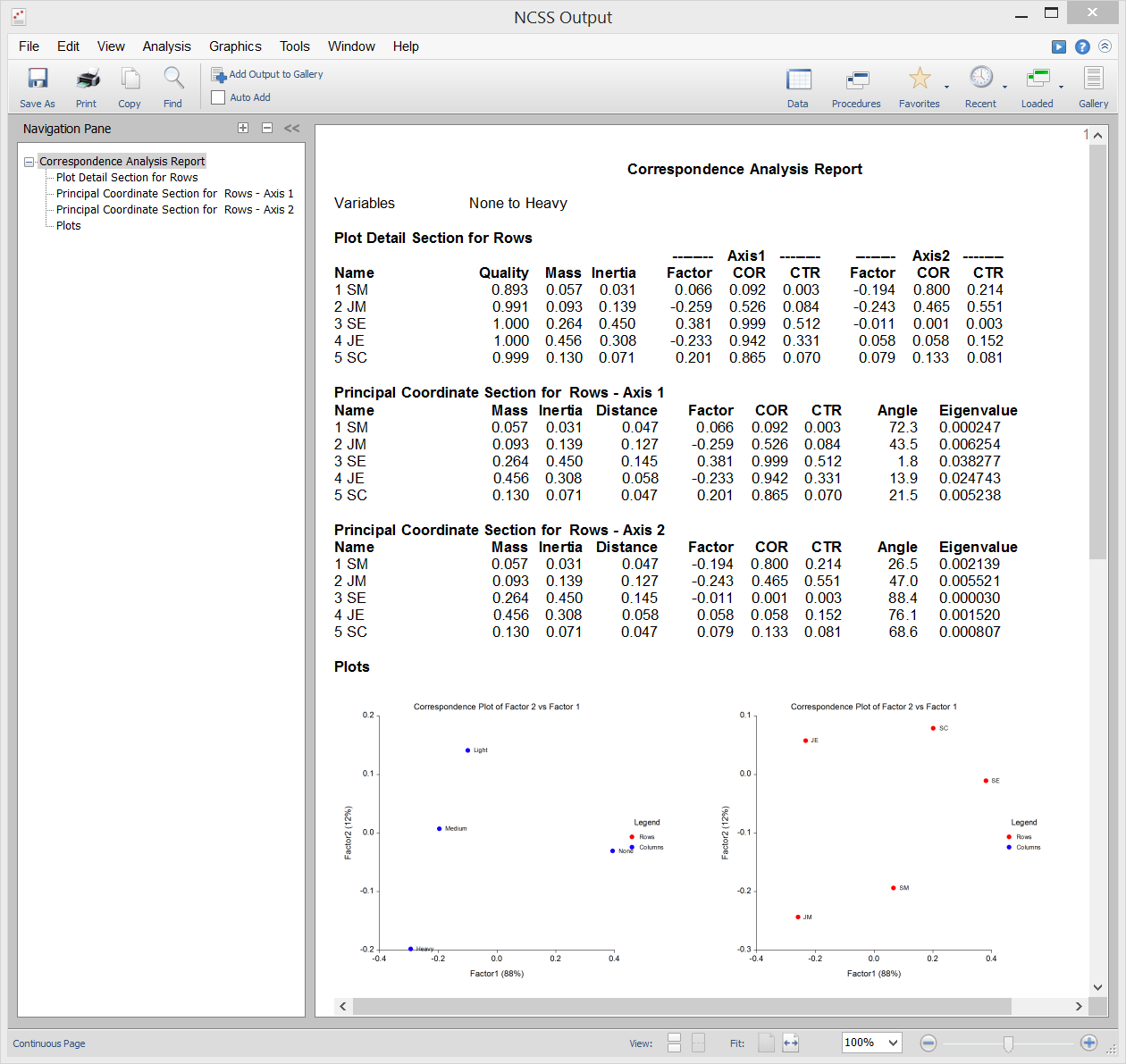
Analisi delle Corrispondenze
L’Analisi delle Corrispondenze (o CA) è una tecnica per visualizzare graficamente una tabella a due vie di dati categorici usando coordinate calcolate che rappresentano le righe e le colonne della tabella. Queste coordinate sono analoghe ai fattori in un’analisi delle componenti principali (usata per i dati continui) eccetto che dividono il valore del Chi-quadrato usato per testare l’indipendenza invece della varianza totale.
Sample Output
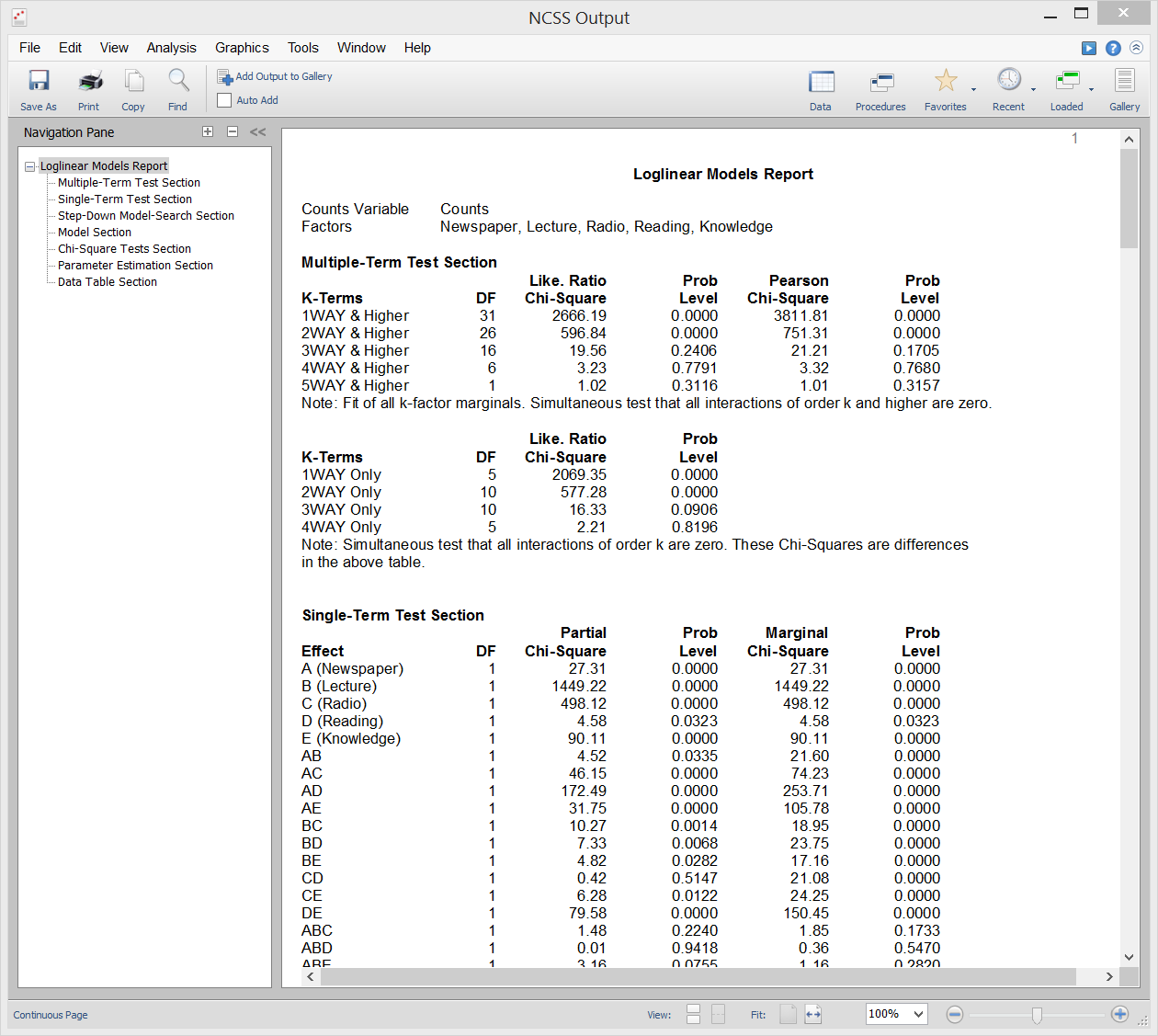
Modelli loglineari
I modelli loglineari (LLM) sono usati per studiare le relazioni tra due o più variabili discrete. Spesso chiamato analisi di frequenza a più vie, è un’estensione del familiare test chi-quadro per l’indipendenza nelle tabelle di contingenza a due vie.
LLM può essere usato per analizzare indagini e questionari che hanno interrelazioni complesse tra le domande. Anche se i questionari sono spesso analizzati considerando solo due domande alla volta, questo ignora importanti relazioni a tre (e più) vie tra le domande. L’uso di LLM su questo tipo di dati è analogo all’uso della regressione multipla piuttosto che delle semplici correlazioni su dati continui.
I rapporti di questa procedura includono rapporti a più termini, rapporti a termine singolo, rapporti chi-quadro, rapporti sui modelli, rapporti sulla stima dei parametri e rapporti sulle tabelle.
Sample Output
Multidimensional Scaling
Multidimensional Scaling (MDS) è una tecnica che crea una mappa che visualizza le posizioni relative di un certo numero di oggetti, data solo una tabella delle distanze tra loro. La mappa può consistere di una, due, tre o più dimensioni. La procedura calcola la soluzione metrica o non metrica. La tabella delle distanze è nota come matrice di prossimità. Nasce direttamente dagli esperimenti o indirettamente come matrice di correlazione.
Il programma offre due metodi generali per risolvere il problema MDS. Il primo è chiamato Metric, o Classical, Multidimensional Scaling (CMDS) perché cerca di riprodurre la metrica o le distanze originali. Il secondo metodo, chiamato Non-Metric Multidimensional Scaling (NMMDS), assume che solo i gradi delle distanze siano noti. Quindi, questo metodo produce una mappa che cerca di riprodurre i ranghi. Le distanze stesse non vengono riprodotte.