- 04/29/2020
- 14 minuti per leggere
-
-
 c
c -
 M
M -
 D
D -
 B
B -
 v
v -
+13
Si applica a: ![]() QL Server (tutte le versioni supportate)
QL Server (tutte le versioni supportate)
Questo argomento introduce i concetti di gruppi di disponibilità Always On che sono centrali per configurare e gestire uno o più gruppi di disponibilità in SQL Server. Per un riassunto dei benefici offerti dai gruppi di disponibilità e una panoramica della terminologia dei gruppi di disponibilità Always On, vedere Always On Availability Groups (SQL Server).
Un gruppo di disponibilità supporta un ambiente replicato per un insieme discreto di database utente, noto come database di disponibilità. È possibile creare un gruppo di disponibilità per l’alta disponibilità (HA) o per la scala di lettura. Un gruppo di disponibilità HA è un gruppo di database che falliscono insieme. Un gruppo di disponibilità in lettura è un gruppo di database che vengono copiati su altre istanze di SQL Server per il carico di lavoro in sola lettura. Un gruppo di disponibilità supporta un set di database primari e da uno a otto set di database secondari corrispondenti. I database secondari non sono backup. Continua a fare il backup dei tuoi database e dei loro log delle transazioni su base regolare.
Tip
Puoi creare qualsiasi tipo di backup di un database primario. In alternativa, puoi creare backup dei log e backup completi di sola copia dei database secondari. Per maggiori informazioni, vedere Secondarie attive: Backup su repliche secondarie (Always On Availability Groups).
Ogni set di database di disponibilità è ospitato da una replica di disponibilità. Esistono due tipi di repliche di disponibilità: una singola replica primaria, che ospita i database primari, e da una a otto repliche secondarie, ognuna delle quali ospita un set di database secondari e serve come potenziale obiettivo di failover per il gruppo di disponibilità. Un gruppo di disponibilità fallisce a livello di una replica di disponibilità. Una replica di disponibilità fornisce ridondanza solo a livello di database per l’insieme di database in un gruppo di disponibilità. I failover non sono causati da problemi di database come un database che diventa sospetto a causa della perdita di un file di dati o della corruzione di un log delle transazioni.
La replica primaria rende i database primari disponibili per le connessioni in lettura-scrittura dei clienti. La replica primaria invia i record del log delle transazioni di ogni database primario ad ogni database secondario. Questo processo, noto come sincronizzazione dei dati, avviene a livello di database. Ogni replica secondaria mette in cache i record del log delle transazioni (hardens the log) e poi li applica al suo corrispondente database secondario. La sincronizzazione dei dati avviene tra il database primario e ogni database secondario collegato, indipendentemente dagli altri database. Pertanto, un database secondario può essere sospeso o fallire senza influenzare altri database secondari, e un database primario può essere sospeso o fallire senza influenzare altri database primari.
Opzionalmente, è possibile configurare una o più repliche secondarie per supportare l’accesso in sola lettura ai database secondari, ed è possibile configurare qualsiasi replica secondaria per consentire i backup sui database secondari.
SQL Server 2017 introduce due diverse architetture per i gruppi di disponibilità. I gruppi di disponibilità Always On forniscono alta disponibilità, disaster recovery e bilanciamento della scala di lettura. Questi gruppi di disponibilità richiedono un cluster manager. In Windows, il failover clustering fornisce il cluster manager. In Linux, si può usare Pacemaker. L’altra architettura è un gruppo di disponibilità su scala di lettura. Un gruppo di disponibilità su scala di lettura fornisce repliche per carichi di lavoro di sola lettura, ma non alta disponibilità. In un gruppo di disponibilità su scala di lettura non c’è un cluster manager.
L’implementazione di gruppi di disponibilità Always On per HA su Windows richiede un Windows Server Failover Cluster(WSFC). Ogni replica di disponibilità di un dato gruppo di disponibilità deve risiedere su un nodo diverso dello stesso WSFC. L’unica eccezione è che durante la migrazione a un altro cluster WSFC, un gruppo di disponibilità può essere temporaneamente a cavallo di due cluster.
Nota
Per informazioni sui gruppi di disponibilità su Linux, vedi Gruppo di disponibilità Always On per SQL Server su Linux.
In una configurazione HA, viene creato un ruolo cluster per ogni gruppo di disponibilità che si crea. Il cluster WSFC controlla questo ruolo per valutare la salute della replica primaria. Il quorum per i gruppi di disponibilità Always On si basa su tutti i nodi del cluster WSFC, indipendentemente dal fatto che un dato nodo del cluster ospiti o meno delle repliche di disponibilità. In contrasto con il mirroring del database, non c’è un ruolo di testimone nei gruppi di disponibilità Always On.
Note
Per informazioni sulla relazione dei componenti Always On di SQL Server con il cluster WSFC, vedi Windows Server Failover Clustering (WSFC) con SQL Server.
La seguente illustrazione mostra un gruppo di disponibilità che contiene una replica primaria e quattro repliche secondarie. Sono supportate fino a otto repliche secondarie, inclusa una replica primaria e due repliche secondarie synchronous-commit.
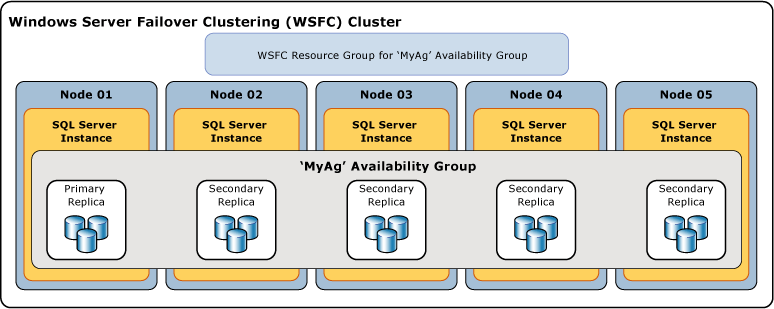
Database di disponibilità
Per aggiungere un database a un gruppo di disponibilità, il database deve essere un database online, in lettura e scrittura, esistente sull’istanza del server che ospita la replica primaria. Quando aggiungi un database, questo si unisce al gruppo di disponibilità come database primario, rimanendo disponibile per i client. Nessun database secondario corrispondente esiste fino a quando i backup del nuovo database primario sono ripristinati sull’istanza del server che ospita la replica secondaria (usando RESTORE WITH NORECOVERY). Il nuovo database secondario è nello stato RESTORING fino a quando non viene unito al gruppo di disponibilità. Per maggiori informazioni, vedi Avviare il movimento dei dati su un database secondario sempre attivo (SQL Server).
L’unione pone il database secondario nello stato ONLINE e avvia la sincronizzazione dei dati con il corrispondente database primario. La sincronizzazione dei dati è il processo con cui le modifiche a un database primario vengono riprodotte su un database secondario. La sincronizzazione dei dati comporta che il database primario invii i record del registro delle transazioni al database secondario.
Importante
Un database di disponibilità è talvolta chiamato una replica del database nei nomi Transact-SQL, PowerShell, e SQL Server Management Objects (SMO). Per esempio, il termine “replica di database” è usato nei nomi delle viste di gestione dinamica Always On che restituiscono informazioni sui database di disponibilità: sys.dm_hadr_database_replica_states e sys.dm_hadr_database_replica_cluster_states. Tuttavia, in SQL Server Books Online, il termine “replica” si riferisce tipicamente alle repliche di disponibilità. Per esempio, “replica primaria” e “replica secondaria” si riferiscono sempre alle repliche di disponibilità.
Repliche di disponibilità
Ogni gruppo di disponibilità definisce un insieme di due o più partner di failover conosciuti come repliche di disponibilità. Le repliche di disponibilità sono componenti del gruppo di disponibilità. Ogni replica di disponibilità ospita una copia dei database di disponibilità nel gruppo di disponibilità. Per un dato gruppo di disponibilità, le repliche di disponibilità devono essere ospitate da istanze separate di SQL Server che risiedono su diversi nodi di un cluster WSFC. Ognuna di queste istanze del server deve essere abilitata per Always On.
Una data istanza può ospitare solo una replica di disponibilità per gruppo di disponibilità. Tuttavia, ogni istanza può essere usata per molti gruppi di disponibilità. Una data istanza può essere un’istanza stand-alone o un’istanza di failover cluster di SQL Server (FCI). Se avete bisogno di ridondanza a livello di server, usate Failover Cluster Instances.
Ad ogni replica di disponibilità viene assegnato un ruolo iniziale, il ruolo primario o il ruolo secondario, che viene ereditato dai database di disponibilità di quella replica. Il ruolo di una data replica determina se ospita database in lettura-scrittura o in sola lettura. A una replica, conosciuta come la replica primaria, è assegnato il ruolo primario e ospita i database in lettura-scrittura, che sono conosciuti come database primari. Ad almeno un’altra replica, conosciuta come replica secondaria, è assegnato il ruolo secondario. Una replica secondaria ospita database di sola lettura, conosciuti come database secondari.
Nota
Quando il ruolo di una replica di disponibilità è indeterminato, come durante un failover, i suoi database sono temporaneamente in uno stato NOT SYNCHRONIZING. Il loro ruolo è impostato su RESOLVING finché il ruolo della replica di disponibilità non si è risolto. Se una replica di disponibilità si risolve nel ruolo primario, i suoi database diventano i database primari. Se una replica di disponibilità si risolve al ruolo secondario, i suoi database diventano database secondari.
Modalità di disponibilità
La modalità di disponibilità è una proprietà di ogni replica di disponibilità. La modalità di disponibilità determina se la replica primaria attende di impegnare le transazioni su un database fino a quando una data replica secondaria non ha scritto i record del log delle transazioni su disco (hardened il log). I gruppi di disponibilità Always On supportano due modalità di disponibilità: la modalità di commit asincrono e la modalità di commit sincrono.
-
Modalità di commit asincrono
Una replica di disponibilità che usa questa modalità di disponibilità è conosciuta come una replica di commit asincrono. In modalità asincrona-commit, la replica primaria commette le transazioni senza aspettare la conferma che una replica secondaria asincrona-commit abbia temprato il log. La modalità asincrona-commit minimizza la latenza delle transazioni sui database secondari ma permette loro di rimanere indietro rispetto ai database primari, rendendo possibile una certa perdita di dati.
-
Modalità sincrona-commit
Una replica di disponibilità che usa questa modalità di disponibilità è conosciuta come una replica sincrona-commit. In modalità synchronous-commit, prima di commettere le transazioni, una replica primaria synchronous-commit aspetta che una replica secondaria synchronous-commit riconosca di aver finito l’hardening del log. La modalità synchronous-commit assicura che una volta che un dato database secondario è sincronizzato con il database primario, le transazioni commesse sono completamente protette. Questa protezione avviene al costo di una maggiore latenza delle transazioni.
Per maggiori informazioni, vedere Modalità di disponibilità (Gruppi di disponibilità sempre attivi).
Tipi di failover
Nel contesto di una sessione tra la replica primaria e una replica secondaria, i ruoli primario e secondario sono potenzialmente intercambiabili in un processo noto come failover. Durante un failover la replica secondaria di destinazione passa al ruolo primario, diventando la nuova replica primaria. La nuova replica primaria porta i suoi database online come i database primari, e le applicazioni client possono connettersi ad essi. Quando la precedente replica primaria è disponibile, passa al ruolo secondario, diventando una replica secondaria. I precedenti database primari diventano database secondari e la sincronizzazione dei dati riprende.
Esistono tre forme di failover: automatico, manuale e forzato (con possibile perdita di dati). La forma o le forme di failover supportate da una data replica secondaria dipende dalla sua modalità di disponibilità e, per la modalità synchronous-commit, dalla modalità di failover sulla replica primaria e sulla replica secondaria di destinazione, come segue.
-
La modalità synchronous-commit supporta due forme di failover: failover manuale pianificato e failover automatico, se la replica secondaria di destinazione è attualmente sincronizzata con quella primaria. Il supporto per queste forme di failover dipende dall’impostazione della proprietà failover mode sui partner di failover. Se la modalità di failover è impostata su “manuale” sulla replica primaria o secondaria, solo il failover manuale è supportato per quella replica secondaria. Se la modalità di failover è impostata su “automatico” sia sulla replica primaria che su quella secondaria, sia il failover automatico che quello manuale sono supportati su quella replica secondaria.
-
Failover manuale pianificato (senza perdita di dati)
Un failover manuale si verifica dopo che un amministratore di database emette un comando di failover e fa sì che una replica secondaria sincronizzata passi al ruolo primario (con protezione dei dati garantita) e la replica primaria passi al ruolo secondario. Un failover manuale richiede che sia la replica primaria che la replica secondaria di destinazione siano in esecuzione in modalità synchronous-commit, e la replica secondaria deve essere già sincronizzata.
-
Failover automatico (senza perdita di dati)
Un failover automatico si verifica in risposta a un errore che causa la transizione di una replica secondaria sincronizzata al ruolo primario (con protezione dei dati garantita). Quando la precedente replica primaria diventa disponibile, passa al ruolo secondario. Il failover automatico richiede che sia la replica primaria che la replica secondaria di destinazione siano in esecuzione in modalità synchronous-commit con la modalità di failover impostata su “Automatic”. Inoltre, la replica secondaria deve essere già sincronizzata, avere il quorum WSFC e soddisfare le condizioni specificate dalla politica di failover flessibile del gruppo di disponibilità.
Importante
SQL Server Failover Cluster Instances (FCI) non supportano il failover automatico dai gruppi di disponibilità, quindi qualsiasi replica di disponibilità che è ospitata da un FCI può essere configurata solo per il failover manuale.
Nota
Nota che se emetti un comando di failover forzato su una replica secondaria sincronizzata, la replica secondaria si comporta come per un failover manuale pianificato.
-
-
In modalità asincrona-commit, l’unica forma di failover è il failover manuale forzato (con possibile perdita di dati), tipicamente chiamato forced failover. Il failover forzato è considerato una forma di failover manuale perché può essere avviato solo manualmente. Il failover forzato è un’opzione di disaster recovery. E’ l’unica forma di failover possibile quando la replica secondaria di destinazione non è sincronizzata con la replica primaria.
Per maggiori informazioni, vedere Failover e modalità di failover (Always On Availability Groups).
Connessioni client
E’ possibile fornire connettività client alla replica primaria di un dato gruppo di disponibilità creando un listener del gruppo di disponibilità. Un listener di un gruppo di disponibilità fornisce un insieme di risorse collegate a un dato gruppo di disponibilità per dirigere le connessioni dei client alla replica di disponibilità appropriata.
Un listener di un gruppo di disponibilità è associato a un nome DNS unico che serve come nome di rete virtuale (VNN), uno o più indirizzi IP virtuali (VIP) e un numero di porta TCP. Per maggiori informazioni, vedi Ascoltatori dei gruppi di disponibilità, connettività client e failover delle applicazioni (SQL Server).
Tip
Se un gruppo di disponibilità possiede solo due repliche di disponibilità e non è configurato per permettere l’accesso in lettura alla replica secondaria, i client possono connettersi alla replica primaria usando una stringa di connessione al database mirroring. Questo approccio può essere utile temporaneamente dopo aver migrato un database dal mirroring del database ai gruppi di disponibilità Always On. Prima di aggiungere ulteriori repliche secondarie, sarà necessario creare un listener del gruppo di disponibilità e aggiornare le applicazioni per utilizzare il nome di rete del listener.
Repliche secondarie attive
I gruppi di disponibilità Always On supportano le repliche secondarie attive. Le capacità secondarie attive includono il supporto per:
-
Eseguire operazioni di backup sulle repliche secondarie
Le repliche secondarie supportano l’esecuzione di backup di log e di backup di sola copia di un intero database, file o gruppo di file. Puoi configurare il gruppo di disponibilità per specificare una preferenza su dove i backup dovrebbero essere eseguiti. È importante capire che la preferenza non è applicata da SQL Server, quindi non ha alcun impatto sui backup ad-hoc. L’interpretazione di questa preferenza dipende dalla logica, se ce n’è una, che si scrive nei processi di backup per ciascuno dei database in un dato gruppo di disponibilità. Per una singola replica di disponibilità, puoi specificare la tua priorità per eseguire i backup su questa replica rispetto alle altre repliche nello stesso gruppo di disponibilità. Per maggiori informazioni, vedere Secondarie attive: Backup su repliche secondarie (gruppi di disponibilità sempre attivi).
-
Accesso in sola lettura a una o più repliche secondarie (repliche secondarie leggibili)
Ogni replica secondaria di disponibilità può essere configurata per consentire solo l’accesso in sola lettura ai suoi database locali, sebbene alcune operazioni non siano pienamente supportate. Questo impedirà i tentativi di connessione in lettura-scrittura alla replica secondaria. È anche possibile prevenire i carichi di lavoro in sola lettura sulla replica primaria consentendo solo l’accesso in lettura-scrittura. Questo impedirà che vengano effettuate connessioni in sola lettura alla replica primaria. Per maggiori informazioni, vedere Secondarie attive: Readable Secondary Replicas (Always On Availability Groups).
Se un gruppo di disponibilità possiede attualmente un ascoltatore del gruppo di disponibilità e una o più repliche secondarie leggibili, SQL Server può instradare le richieste di connessione in sola lettura a una di esse (read-only routing). Per maggiori informazioni, vedi Ascoltatori del gruppo di disponibilità, connettività client e failover delle applicazioni (SQL Server).
Periodo di timeout della sessione
Il periodo di timeout della sessione è una proprietà della replica di disponibilità che determina per quanto tempo la connessione con un’altra replica di disponibilità può rimanere inattiva prima che la connessione venga chiusa. Le repliche primarie e secondarie si pingano a vicenda per segnalare che sono ancora attive. Ricevere un ping dall’altra replica durante il periodo di timeout indica che la connessione è ancora aperta e che le istanze del server stanno comunicando. Alla ricezione di un ping, una replica di disponibilità azzera il suo contatore di session-timeout su quella connessione.
Il periodo di session-timeout evita che una delle due repliche aspetti indefinitamente di ricevere un ping dall’altra replica. Se nessun ping viene ricevuto dall’altra replica entro il periodo di session-timeout, la replica va in time out. La sua connessione viene chiusa, e la replica in time-out entra nello stato DISCONNECTED. Anche se una replica scollegata è configurata per la modalità synchronous-commit, le transazioni non aspetteranno che la replica si ricolleghi e si risincronizzi.
Il periodo predefinito di session-timeout per ogni replica di disponibilità è di 10 secondi. Questo valore è configurabile dall’utente, con un minimo di 5 secondi. In generale, si consiglia di mantenere il periodo di timeout a 10 secondi o più. Impostando il valore a meno di 10 secondi si crea la possibilità che un sistema molto carico dichiari un falso fallimento.
Nota
Nel ruolo di risoluzione, il periodo di session-timeout non si applica perché il ping non avviene.
Riparazione automatica delle pagine
Ogni replica di disponibilità cerca di recuperare automaticamente le pagine corrotte su un database locale risolvendo alcuni tipi di errori che impediscono la lettura di una pagina dati. Se una replica secondaria non può leggere una pagina, la replica richiede una copia fresca della pagina dalla replica primaria. Se la replica primaria non può leggere una pagina, la replica trasmette una richiesta per una copia fresca a tutte le repliche secondarie e ottiene la pagina dalla prima che risponde. Se questa richiesta ha successo, la pagina illeggibile viene sostituita dalla copia, che di solito risolve l’errore.
Per maggiori informazioni, vedi Riparazione automatica delle pagine (Gruppi di disponibilità: Mirroring del database).
Compiti correlati
- Inizio con i gruppi di disponibilità Always On (SQL Server)
Contenuti correlati
-
Blogs:
Always On – HADRON Learning Series: Utilizzo del pool di lavoro per i database abilitati HADRON
SQL Server Always On Team Blogs: L’ufficiale SQL Server Always On Team Blog
CSS SQL Server Engineers Blogs
-
Video:
Microsoft SQL Server Code-Named “Denali” Always On Series, Part 1: Introduzione alla soluzione di alta disponibilità di prossima generazione
Microsoft SQL Server Code-Named “Denali” Always On Series, Parte 2: Costruire una soluzione di alta disponibilità mission-critical utilizzando Always On
-
Whitepapers:
Microsoft SQL Server Always On Solutions Guide for High Availability and Disaster Recovery
Microsoft White Papers for SQL Server 2012
SQL Server Customer Advisory Team Whitepapers
Vedi anche
Modalità di disponibilità (Always On Availability Groups)
Failover e modalità di Failover (Always On Availability Groups)
Panoramica dei Transact-SQL Statements for Always On Availability Groups (SQL Server)
Overview of PowerShell Cmdlets for Always On Availability Groups (SQL Server)
High Availability Support for In-Memory OLTP databases
Prequisiti, Restrizioni e raccomandazioni per i gruppi di disponibilità sempre attivi (SQL Server)
Creazione e configurazione dei gruppi di disponibilità (SQL Server)
Secondari attivi: Repliche secondarie leggibili (Always On Availability Groups)
Secondarie attive: Backup su repliche secondarie (Always On Availability Groups)
Availability Group Listeners, Client Connectivity, and Application Failover (SQL Server)