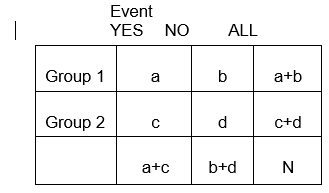
Le variabili categoriche possono rappresentare lo sviluppo di una malattia, un aumento della gravità della malattia, la mortalità, o qualsiasi altra variabile che consiste di due o più livelli. Per riassumere l’associazione tra due variabili categoriche con livelli R e C, creiamo tabulazioni incrociate, o tabelle RxC (“Fila “x “Colonna” o tabelle di contingenza), che riassumono le frequenze osservate di esiti categorici tra diversi gruppi di soggetti. Qui ci concentreremo sulle tabelle 2 x 2.
In generale, le tabelle 2 x 2 riassumono la frequenza di eventi relativi alla salute (o altro) tra diversi gruppi, come illustrato di seguito in cui il Gruppo 1 potrebbe rappresentare i pazienti che hanno ricevuto una terapia standard, e il Gruppo 2 potrebbe essere i pazienti che hanno ricevuto una nuova terapia sperimentale.
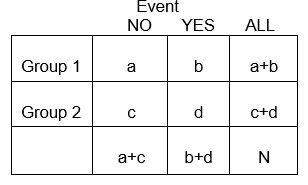
Esempio:
La variabile primaria di risultato negli studi Kawasaki era lo sviluppo di anomalie dell’arteria coronaria (CA), una variabile dicotomica. Uno degli obiettivi dello studio era quello di confrontare le probabilità di sviluppare anomalie CA dato il trattamento con Aspirina (ASA) o Gamma globulina (GG).

Potremmo essere interessati a sapere se la frequenza di anomalie dell’arteria coronarica differiva tra questi due gruppi, cioè, uno di questi era associato a un minor numero di anomalie. La risposta a domande come questa dipende dal confronto delle frequenze di questi eventi sanitari nei due gruppi di trattamento. A seconda del disegno dello studio, si può confrontare la probabilità degli eventi o le probabilità che un evento si verifichi.
Probabilità e probabilità di sviluppare la CA in ciascuno dei bracci di trattamento
La probabilità è calcolata come il numero di valori “sì” in ogni categoria di trattamento diviso per il numero totale nella categoria di trattamento.
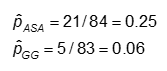
Le probabilità sono #Sì / #No. Qui,
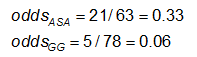
Si noti sempre se il risultato è nelle righe o nelle colonne; è molto facile confonderle!
Quando abbiamo esaminato l’associazione tra una variabile binaria e un risultato continuo, abbiamo riassunto l’associazione in termini di differenza di media. Quale statistica è appropriata per rappresentare la differenza tra due gruppi rispetto alla probabilità di un evento binario? Ci sono almeno tre modi di riassumere l’associazione:
Differenza di rischio RD = p1 – p2
Rischio relativo (Risk Ratio) RR = p1 / p2
Odds Ratio OR = odds1/ odds2 = /
Il disegno dello studio determina quale di queste misure di effetto è appropriata. In uno studio caso/controllo, il rischio relativo non può essere valutato, e l’odds ratio (OR) è la misura appropriata. Tuttavia, l’OR fornirà una buona stima del rischio relativo per eventi rari (cioè, se p è piccolo, tipicamente 0,10 o più piccolo).
Gli studi trasversali valutano la prevalenza delle misure di salute, quindi l’odds ratio è appropriato. Con gli studi di coorte prospettici è appropriato sia un rate ratio che un risk ratio, anche se può essere calcolato anche un odds ratio.,
Per una revisione più dettagliata delle misure di effetto, vedere il modulo di epidemiologia online su “Misure di associazione”.
Esempio: Utilizzando i dati precedenti sulle anomalie CA, le misure di effetto per coloro che utilizzano ASA (aspirina) rispetto alla gamma globulina (GG) sono le seguenti:
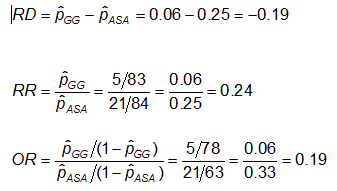

Esercitazione: Considerate le misure di effetto nell’esempio precedente. Perché il rapporto di rischio e l’odds ratio sono così diversi (il RR suggerisce che, rispetto al gruppo trattato solo con ASA, il rischio di anomalie coronariche è 1/4 più alto per quelli trattati con GG; mentre l’OR suggerisce che il rischio è 1/5 più alto)?
Modi alternativi per esprimere l’ipotesi nulla
Per una tabella 2×2, l’ipotesi nulla può equivalentemente essere scritta in termini di probabilità stesse, o la differenza di rischio, il rischio relativo o l’odds ratio. In ogni caso, l’ipotesi nulla afferma che non c’è differenza tra i due gruppi.
H0: p1 = p2
H1: p1 ≠ p2
H0: p1 – p2 = 0 (RD=0)
H1: RD ≠ 0
H0: p1/ p2 = 1 (RR=1)
H1: RR ≠ 1
H0: OR = 1
H1: OR ≠ 1
Il test del chi-quadrato
La differenza di frequenza del risultato tra i due gruppi può essere valutata con il test del chi-quadrato.
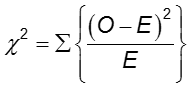
In ogni cella della tabella 2×2, O è la frequenza delle celle osservate ed E è la frequenza delle celle attesa sotto l’ipotesi che l’ipotesi nulla sia vera. La somma è calcolata sulle 2×2 = 4 celle della tabella. Finché la frequenza attesa in ogni cella è almeno cinque, il valore chi-quadro calcolato ha una distribuzione χ2 con 1 grado di libertà (df).
Rifiuta l’ipotesi nulla se ![]() . Per α = 0,05, il valore critico è 3,84.
. Per α = 0,05, il valore critico è 3,84.
Esempio:
Frequenze osservate

Se non c’è associazione tra trattamento e malattia, la percentuale di casi tra quelli trattati e non trattati sarebbe la stessa e sarebbe uguale alla percentuale di casi nell’intera popolazione dello studio.
Frequenze attese:
In totale, tra i 167 bambini, ci sono 26 con anomalie CA e 141 senza anomalie CA. La proporzione con anomalie CA è 26/167, ovvero il 16%. Se l’ipotesi nulla è vera, e i due gruppi di trattamento hanno la stessa probabilità di anomalie CA, allora ci aspettiamo che circa il 16% in ogni gruppo abbia anomalie CA.
Quindi, nel gruppo GG di n=83, ci aspettiamo che il 16% di 83 abbia anomalie CA. Questo è calcolato come 0,16 x 83 = 13, ed è chiamato la frequenza attesa in quella cella.
Possiamo scriverlo come
E11 = frequenza attesa nella riga 1, colonna 1
= numero atteso nel gruppo 1 che ha l’evento (riga 1, colonna 1)
E lo calcoliamo come
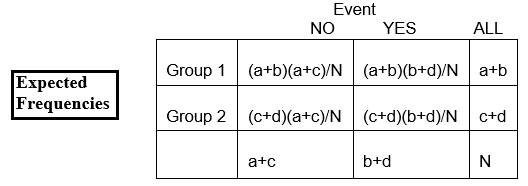
E11 = (proporzione che ci aspettiamo abbia l’evento) x numero totale in (gruppo) riga 1
= x numero in (gruppo) riga 1
Usando la notazione nella tabella,
E11 = x (a+b)
E spesso lo riscriviamo semplicemente come
E11 = (a+b)(a+c)/N
Nel nostro esempio, calcoliamo la frequenza attesa nella prima cella (E11):
E11 = (83)(26)/167 = 12.92
Possiamo calcolare le frequenze attese nelle altre celle nello stesso modo
La proporzione complessiva senza anomalie CA è 141/167, o 84%. Ci aspettiamo che circa l’84% di quelli nel gruppo ASA non abbia anomalie CA, quindi la frequenza attesa nella riga 2, colonna 2, è E22 = 84% di 84, o 0,84 x 84, o circa 71.
Utilizzando la tabella sopra, potremmo semplicemente calcolarla come
E22 = (c+d)(b+d)/N = (84)(141)/167 = 70.92
Esercizio: Quanti dei bambini del gruppo ASA vi aspettereste di avere anomalie CA se l’ipotesi nulla fosse vera? Provate a risolverlo prima di guardare la risposta qui sotto.
Nota che le frequenze osservate assumono valori interi, mentre le frequenze attese possono assumere valori decimali.
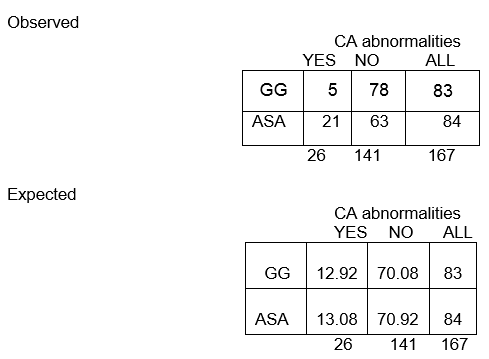
Ci aspettiamo che quasi 13 bambini del gruppo GG abbiano anomalie CA, ma solo 5 lo hanno effettivamente fatto! Il numero di gradi di libertà è uguale al numero di celle la cui frequenza attesa deve essere calcolata; in una tabella 2 x 2, questo è 1.
Statistica del test Chi-quadrato
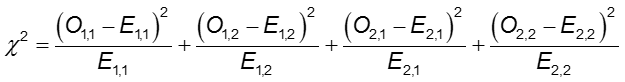
dove O1,1 e E1,1 sono i conteggi osservati e previsti nella cella della prima riga e della prima colonna. Per esempio, O1,1 = a e E1,1 =(a+b)(a+c)/N. Se i conteggi delle celle osservate sono abbastanza diversi da quelli attesi, allora non possiamo concludere che le due probabilità sono uguali.
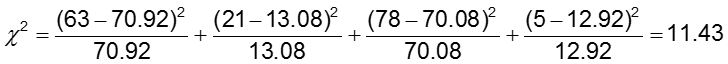
H0: Le probabilità di anomalie CA sono le stesse tra i gruppi di trattamento (OR=1)
H1: Le probabilità di anomalie CA non sono le stesse tra i gruppi di trattamento (OR≠1)
Il livello di significatività è 0.05.
La statistica del test è calcolata come 11,43. Poiché la nostra statistica del test è maggiore di 3,84 (il valore critico del chi-quadro per 1 grado di libertà), rifiutiamo l’ipotesi nulla e concludiamo che le probabilità di anomalie CA non sono le stesse nei due gruppi di trattamento.
tornare all’inizio | pagina precedente | pagina successiva