SPSS Statistics
Interpretare e riportare l’output di un’analisi di regressione logistica binomiale
SPSS Statistics genera molte tabelle di output quando esegue una regressione logistica binomiale. In questa sezione, vi mostriamo solo le tre tabelle principali necessarie per comprendere i risultati della procedura di regressione logistica binomiale, supponendo che non siano state violate le ipotesi. Una spiegazione completa dell’output che dovete interpretare quando controllate i vostri dati per le ipotesi richieste per effettuare la regressione logistica binomiale è fornita nella nostra guida avanzata.
Tuttavia, in questa guida “quick start”, ci concentriamo solo sulle tre tabelle principali di cui avete bisogno per capire i risultati della regressione logistica binomiale, assumendo che i vostri dati abbiano già soddisfatto le ipotesi richieste dalla regressione logistica binomiale per darvi un risultato valido:
Varianza spiegata
Per capire quanta variazione della variabile dipendente può essere spiegata dal modello (l’equivalente di R2 nella regressione multipla), puoi consultare la tabella sottostante, “Model Summary”:
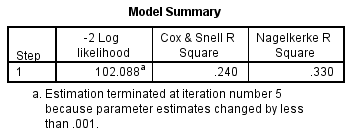
Questa tabella contiene i valori di Cox & Snell R Square e Nagelkerke R Square, che sono entrambi metodi di calcolo della variazione spiegata. Questi valori sono a volte indicati come pseudo valori R2 (e avranno valori più bassi che nella regressione multipla). Tuttavia, sono interpretati allo stesso modo, ma con più cautela. Pertanto, la variazione spiegata della variabile dipendente basata sul nostro modello varia dal 24,0% al 33,0%, a seconda che si faccia riferimento ai metodi Cox & Snell R2 o Nagelkerke R2, rispettivamente. Nagelkerke R2 è una modifica di Cox & Snell R2, quest’ultimo non può raggiungere un valore di 1. Per questo motivo, è preferibile riportare il valore di Nagelkerke R2.
Previsione della categoria
La regressione logistica binomiale stima la probabilità che si verifichi un evento (in questo caso, avere una malattia cardiaca). Se la probabilità stimata che l’evento si verifichi è maggiore o uguale a 0,5 (migliore del caso), SPSS Statistics classifica l’evento come avvenuto (ad esempio, la malattia cardiaca presente). Se la probabilità è inferiore a 0,5, SPSS Statistics classifica l’evento come non avvenuto (ad esempio, nessuna malattia cardiaca). È molto comune usare la regressione logistica binomiale per prevedere se i casi possono essere classificati correttamente (cioè, predetti) dalle variabili indipendenti. Pertanto, diventa necessario avere un metodo per valutare l’efficacia della classificazione prevista rispetto alla classificazione effettiva. Ci sono molti metodi per valutare questo e la loro utilità dipende spesso dalla natura dello studio condotto. Tuttavia, tutti i metodi ruotano intorno alle classificazioni osservate e previste, che sono presentate nella “Tabella di classificazione”, come mostrato di seguito:
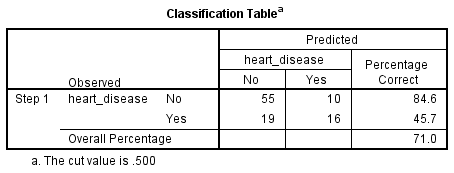
In primo luogo, si noti che la tabella ha un pedice che afferma: “Il valore di taglio è .500”. Questo significa che se la probabilità che un caso sia classificato nella categoria “sì” è maggiore di .500, allora quel particolare caso è classificato nella categoria “sì”. Altrimenti, il caso è classificato nella categoria “no” (come menzionato in precedenza). Mentre la tabella di classificazione sembra essere molto semplice, in realtà fornisce molte informazioni importanti sul risultato della regressione logistica binomiale, tra cui:
- A. La percentuale di precisione nella classificazione (PAC), che riflette la percentuale di casi che possono essere correttamente classificati come “no” malattia cardiaca con le variabili indipendenti aggiunte (non solo il modello complessivo).
- B. Sensibilità, che è la percentuale di casi che avevano la caratteristica osservata (ad es, “sì” per la malattia cardiaca) che sono stati correttamente predetti dal modello (cioè, veri positivi).
- C. Specificità, che è la percentuale di casi che non avevano la caratteristica osservata (ad esempio, “no” per la malattia cardiaca) e sono stati anche correttamente predetti come non aventi la caratteristica osservata (cioè, veri negativi).
- D. Il valore predittivo positivo, che è la percentuale di casi correttamente predetti “con” la caratteristica osservata rispetto al numero totale di casi predetti come aventi la caratteristica.
- E. Il valore predittivo negativo, che è la percentuale di casi correttamente predetti “senza” la caratteristica osservata rispetto al numero totale di casi predetti come non aventi la caratteristica.
Se non sei sicuro di come interpretare il PAC, la sensibilità, la specificità, il valore predittivo positivo e il valore predittivo negativo dalla “Tabella di classificazione”, ti spieghiamo come nella nostra guida avanzata alla regressione logistica binomiale.
Variabili nell’equazione
La tabella “Variabili nell’equazione” mostra il contributo di ogni variabile indipendente al modello e la sua significatività statistica. Questa tabella è mostrata qui sotto:
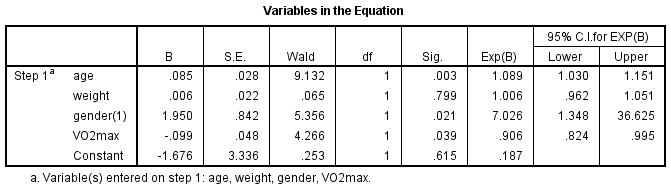
Il test di Wald (colonna “Wald”) è usato per determinare la significatività statistica per ciascuna delle variabili indipendenti. La significatività statistica del test si trova nella colonna “Sig. Da questi risultati si può vedere che l’età (p = .003), il sesso (p = .021) e il VO2max (p = .039) hanno aggiunto significativamente al modello/predizione, ma il peso (p = .799) non ha aggiunto significativamente al modello. È possibile utilizzare le informazioni nella tabella “Variabili nell’equazione” per prevedere la probabilità che un evento si verifichi sulla base di un cambiamento di una unità in una variabile indipendente quando tutte le altre variabili indipendenti sono mantenute costanti. Per esempio, la tabella mostra che la probabilità di avere una malattia cardiaca (categoria “sì”) è 7,026 volte maggiore per i maschi rispetto alle femmine. Se non sei sicuro di come usare gli odds ratio per fare previsioni, scopri le nostre guide avanzate nella nostra pagina delle Caratteristiche:
Mettere tutto insieme
In base ai risultati di cui sopra, potremmo riportare i risultati dello studio come segue (N.B., questo non include i risultati dei vostri test di ipotesi):
- Generale
È stata eseguita una regressione logistica per accertare gli effetti di età, peso, sesso e VO2max sulla probabilità che i partecipanti abbiano malattie cardiache. Il modello di regressione logistica era statisticamente significativo, χ2(4) = 27,402, p < .0005. Il modello ha spiegato il 33,0% (Nagelkerke R2) della varianza delle malattie cardiache e ha classificato correttamente il 71,0% dei casi. I maschi avevano una probabilità 7,02 volte maggiore di presentare una malattia cardiaca rispetto alle femmine. L’aumento dell’età è stato associato a un aumento della probabilità di presentare una malattia cardiaca, ma l’aumento del VO2max è stato associato a una riduzione della probabilità di presentare una malattia cardiaca.
In aggiunta alla scrittura di cui sopra, si dovrebbe anche includere: (a) i risultati dei test di ipotesi che avete effettuato; (b) i risultati della “Tabella di classificazione”, compresi sensibilità, specificità, valore predittivo positivo e valore predittivo negativo; e (c) i risultati della tabella “Variabili nell’equazione”, comprese quali delle variabili predittive erano statisticamente significative e quali previsioni possono essere fatte in base all’uso degli odds ratio. Se non siete sicuri di come farlo, ve lo mostriamo nella nostra guida avanzata alla regressione logistica binomiale. Ti mostriamo anche come scrivere i risultati dei tuoi test di ipotesi e l’output della regressione logistica binomiale se hai bisogno di riportarli in una tesi, un compito o un rapporto di ricerca. Lo facciamo usando gli stili Harvard e APA. Puoi saperne di più sui nostri contenuti migliorati sulla nostra pagina delle Caratteristiche: Pagina panoramica.