Nota di riflessione (5 marzo 2020)
Questo modello è stato concepito nel 2010, ormai più di 10 anni fa, e non molto tempo dopo la nascita di Git stesso. In questi 10 anni, git-flow (il modello di ramificazione esposto in questo articolo) è diventato enormemente popolare in molti team di software al punto che la gente ha iniziato a trattarlo come una specie di standard – ma sfortunatamente anche come un dogma o una panacea.
In questi 10 anni, Git stesso ha preso d’assalto il mondo, e il tipo più popolare di software che viene sviluppato con Git si sta spostando verso le applicazioni web – almeno nella mia bolla di filtraggio. Le applicazioni web sono tipicamente consegnate in modo continuo, non sono soggette a rollback, e non è necessario supportare versioni multiple del software in esecuzione in natura.
Questa non è la classe di software che avevo in mente quando ho scritto il blogpost 10 anni fa. Se il vostro team sta facendo una consegna continua di software, vi suggerirei di adottare un workflow molto più semplice (come GitHubflow) invece di cercare di inserire git-flow nel vostro team.
Se, tuttavia, state costruendo software che è esplicitamente in versione, o se avete bisogno di supportare più versioni del vostro software in natura, git-flow potrebbe essere ancora adatto al vostro team come lo è stato per le persone negli ultimi 10 anni. In questo caso, continuate a leggere.
Per concludere, ricordate sempre che le panacee non esistono. Considerate il vostro contesto. Non odiare. Decidete voi stessi.
In questo post presento il modello di sviluppo che ho introdotto per alcuni dei miei progetti (sia al lavoro che privati) circa un anno fa, e che si è rivelato di grande successo. È da un po’ che volevo scriverne, ma non ho mai trovato il tempo per farlo in modo approfondito, fino ad ora. Non parlerò dei dettagli del progetto, ma solo della strategia di branching e della gestione dei rilasci.

Perché git?
Per una discussione approfondita sui pro e i contro di Git rispetto ai sistemi centralizzati di controllo del codice sorgente, vedi il web. Ci sono un sacco di flamewars in corso lì. Come sviluppatore, preferisco Git a tutti gli altri strumenti in circolazione oggi. Dal classico mondo CVS/Subversion da cui provengo, il merging/branching è sempre stato considerato un po’ spaventoso (“attenzione ai conflitti di merge, ti mordono!”) e qualcosa che si fa solo ogni tanto.
Ma con Git, queste azioni sono estremamente economiche e semplici, e sono considerate una delle parti fondamentali del tuo flusso di lavoro quotidiano, davvero. Per esempio, nei libri su CVS/Subversion, il branching e il merging sono discussi per la prima volta nei capitoli successivi (per utenti avanzati), mentre in ogni libro su Git, sono già trattati nel capitolo 3 (basi).
Come conseguenza della sua semplicità e natura ripetitiva, il branching e il merging non sono più qualcosa di cui aver paura. Gli strumenti di controllo di versione dovrebbero assistere nel branching/merging più di ogni altra cosa.
Basta parlare degli strumenti, passiamo al modello di sviluppo. Il modello che presenterò qui non è essenzialmente altro che un insieme di procedure che ogni membro del team deve seguire per arrivare a un processo di sviluppo del software gestito.
Decentrato ma centralizzato
La configurazione del repository che usiamo e che funziona bene con questo modello di branching, è quella con un repo “verità” centrale. Si noti che questo repo è considerato solo quello centrale (poiché Git è un DVCS, non esiste una cosa come un repo centrale a livello tecnico). Ci riferiremo a questo repo come origin, dato che questo nome è familiare a tutti gli utenti di Git.
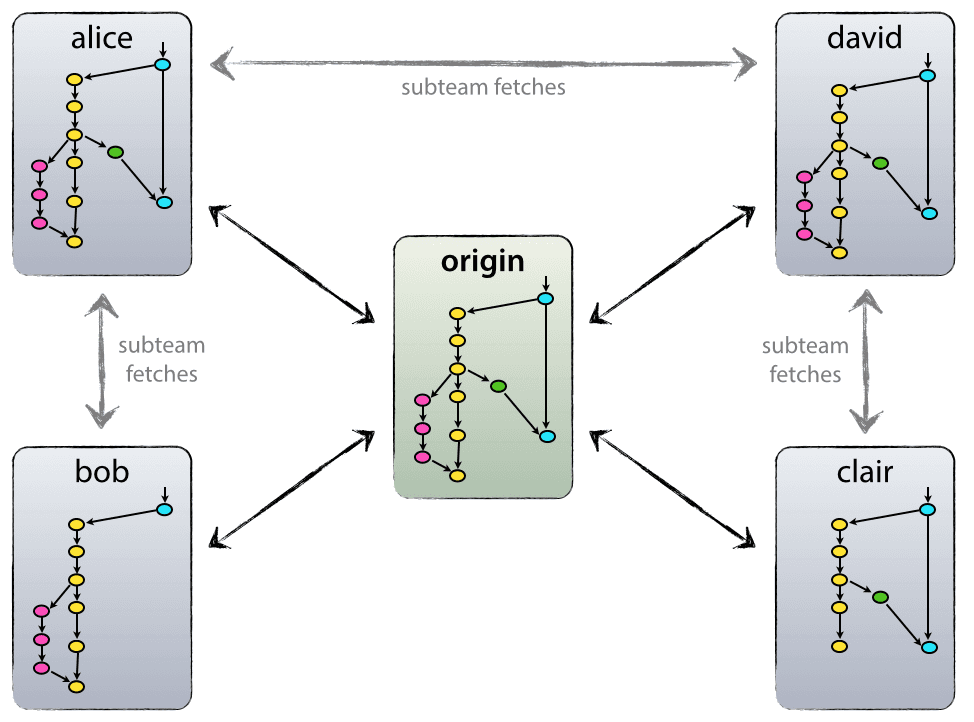
Ogni sviluppatore tira e spinge su origin. Ma oltre alle relazioni centralizzate di push-pull, ogni sviluppatore può anche tirare i cambiamenti da altri peers per formare dei sub team. Per esempio, questo potrebbe essere utile per lavorare insieme a due o più sviluppatori su una nuova grande caratteristica, prima di spingere il lavoro in corso aorigin prematuramente. Nella figura sopra, ci sono sotto-squadre di Alice e Bob, Alice e David, e Clair e David.
Tecnicamente, questo non significa altro che Alice ha definito un Git remoto, chiamato bob, che punta al repository di Bob, e viceversa.
I rami principali ¶
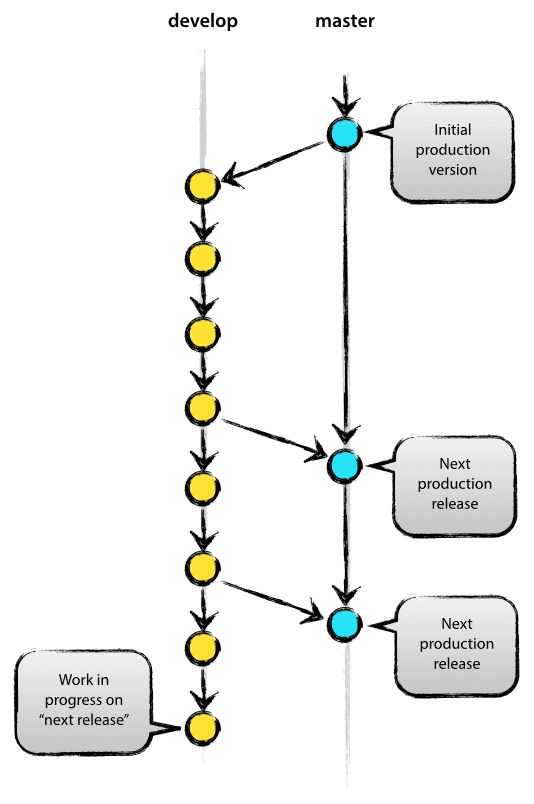
Al centro, il modello di sviluppo è molto ispirato ai modelli esistenti là fuori. Il repo centrale contiene due rami principali con una durata infinita:
masterdevelop
Il ramo master a origin dovrebbe essere familiare a ogni utente Git. Parallelamente al ramo master, esiste un altro ramo chiamato develop.
Consideriamo origin/master come il ramo principale dove il codice sorgente diHEAD riflette sempre uno stato pronto per la produzione.
Consideriamo origin/develop come il ramo principale in cui il codice sorgente diHEAD riflette sempre uno stato con le ultime modifiche di sviluppo consegnate per il prossimo rilascio. Alcuni lo chiamerebbero il “ramo di integrazione”. Quando il codice sorgente nel ramo develop raggiunge un punto stabile ed è pronto per essere rilasciato, tutti i cambiamenti dovrebbero essere fusi nuovamente in masterin qualche modo e poi etichettati con un numero di rilascio. Come questo viene fatto in dettaglio sarà discusso più avanti.
Quindi, ogni volta che i cambiamenti sono fusi in master, questo è un nuovo rilascio di produzione per definizione. Tendiamo ad essere molto rigorosi in questo, in modo che, teoricamente, potremmo usare uno script Git hook per costruire automaticamente e lanciare il nostro software sui nostri server di produzione ogni volta che c’è un commit sumaster.
Rami di supporto ¶
Oltre ai rami principali master e develop, il nostro modello di sviluppo usa una varietà di rami di supporto per aiutare lo sviluppo parallelo tra i membri del team, facilitare il tracciamento delle caratteristiche, preparare i rilasci in produzione e aiutare a risolvere rapidamente i problemi in produzione. A differenza dei rami principali, questi rami hanno sempre un tempo di vita limitato, poiché saranno rimossi alla fine.
I diversi tipi di rami che possiamo usare sono:
- Rami di funzionalità
- Rami di rilascio
- Rami di correzione
Ognuno di questi rami ha uno scopo specifico e sono legati a regole severe su quali rami possono essere il loro ramo di origine e quali rami devono essere i loro obiettivi di fusione. Li esamineremo tra un minuto.
In nessun modo questi rami sono “speciali” da un punto di vista tecnico. I tipi di rami sono categorizzati da come li usiamo. Sono ovviamente dei semplici vecchi rami di Git.
Rami caratteristici ¶
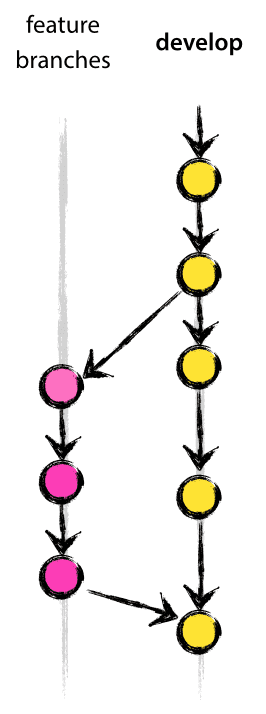
Può diramarsi da:developDeve fondersi nuovamente in:developConvenzione di denominazione dei rami: qualsiasi cosa trannemasterdeveloprelease-*, ohotfix-*
I rami delle caratteristiche (o talvolta chiamati rami degli argomenti) sono usati per sviluppare nuove caratteristiche per il prossimo o lontano rilascio futuro. Quando si inizia lo sviluppo di una caratteristica, la release di destinazione in cui questa caratteristica sarà incorporata potrebbe essere sconosciuta a quel punto. L’essenza di un ramo di caratteristica è che esiste finché la caratteristica è in sviluppo, ma alla fine sarà fusa di nuovo in develop (per aggiungere definitivamente la nuova caratteristica al prossimo rilascio) o scartata (in caso di un esperimento deludente).
I rami di funzionalità tipicamente esistono solo nei repo degli sviluppatori, non nel origin.
Creare un ramo di funzionalità¶
Quando si inizia a lavorare su una nuova funzionalità, si dirama dal ramo develop.
$ git checkout -b myfeature developSwitched to a new branch "myfeature"
Integrare una caratteristica finita su develop ¶
Le caratteristiche finite possono essere unite nel ramo develop per aggiungerle definitivamente al prossimo rilascio:
$ git checkout developSwitched to branch 'develop'$ git merge --no-ff myfeatureUpdating ea1b82a..05e9557(Summary of changes)$ git branch -d myfeatureDeleted branch myfeature (was 05e9557).$ git push origin develop
Il flag --no-ff fa sì che il merge crei sempre un nuovo oggetto commit, anche se il merge potrebbe essere eseguito con un fast-forward. Questo evita di perdere informazioni sull’esistenza storica di un ramo di una caratteristica e raggruppa tutti i commit che insieme hanno aggiunto la caratteristica. Confronta:
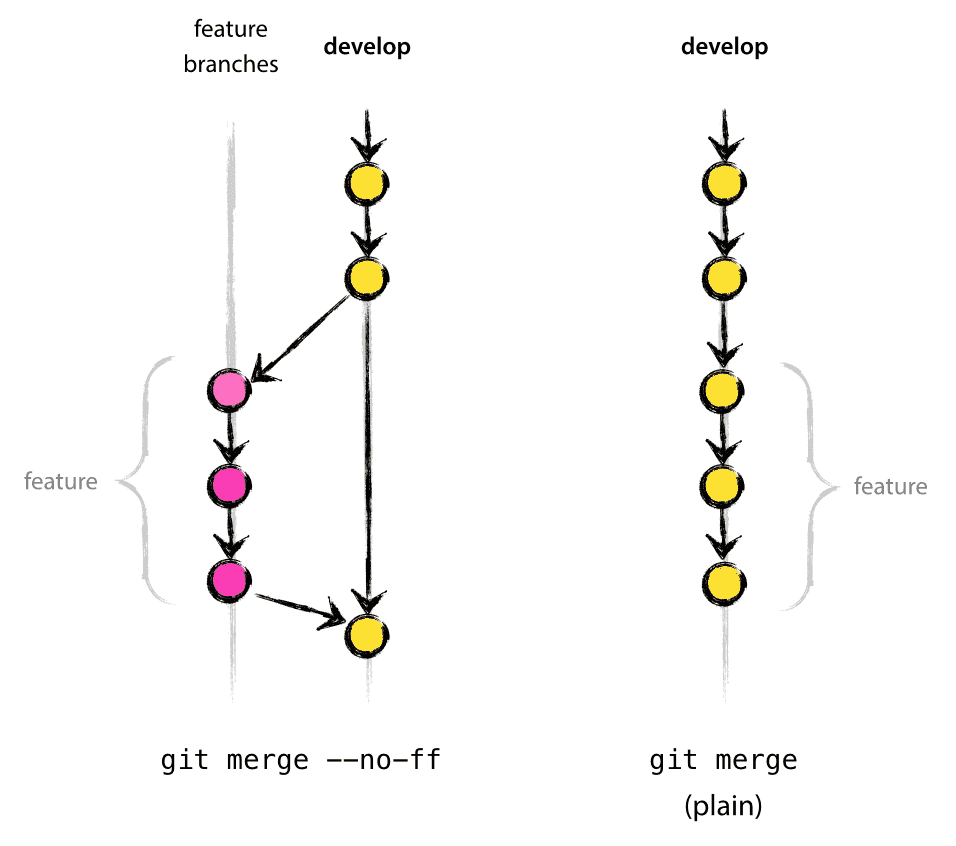
Nel secondo caso, è impossibile vedere dalla storia di Git quali oggetticommit insieme hanno implementato una caratteristica – dovresti leggere manualmente tutti i messaggi di log. Ripristinare un’intera caratteristica (cioè un gruppo di commit), è un vero mal di testa in quest’ultima situazione, mentre è facilmente realizzabile se fosse usato il flag--no-ff.
Sì, creerà qualche oggetto commit (vuoto) in più, ma il guadagno è molto più grande del costo.
Rami di rilascio ¶
Può diramarsi da:developDeve fondersi nuovamente in:developemasterConvenzione di denominazione dei rami:release-*
I rami di rilascio supportano la preparazione di un nuovo rilascio di produzione. Permettono di mettere i puntini sulle i e le crocette all’ultimo minuto. Inoltre, permettono la correzione di bug minori e la preparazione di meta-dati per un rilascio (numero di versione, builddates, ecc.). Facendo tutto questo lavoro su un ramo di rilascio, il developramo è autorizzato a ricevere le caratteristiche per la prossima grande release.
Il momento chiave per diramare un nuovo ramo di rilascio da develop è quandoendevelop (quasi) riflette lo stato desiderato della nuova release. Almeno tutte le caratteristiche che sono mirate al rilascio da costruire devono essere unite adevelop in questo momento. Tutte le caratteristiche mirate ai rilasci futuri non possono – devono aspettare fino a quando il ramo di rilascio è ramificato.
È esattamente all’inizio di un ramo di rilascio che al prossimo rilascio viene assegnato un numero di versione – non prima. Fino a quel momento, il developramo riflette i cambiamenti per la “prossima release”, ma non è chiaro se questa “prossima release” diventerà alla fine 0.3 o 1.0, fino a quando il ramo di rilascio non viene avviato. Questa decisione viene presa all’inizio del ramo di rilascio e viene eseguita dalle regole del progetto sul bumping del numero di versione.
Creazione di un ramo di rilascio ¶
I rami di rilascio sono creati dal ramo develop. Per esempio, diciamo che la versione 1.1.5 è l’attuale versione di produzione e abbiamo una grande release in arrivo. Lo stato di develop è pronto per la “prossima release” e abbiamo deciso che questa diventerà la versione 1.2 (piuttosto che 1.1.6 o 2.0). Perciò, si fa un webranch off e si dà al ramo di rilascio un nome che rifletta il nuovo numero di versione:
$ git checkout -b release-1.2 developSwitched to a new branch "release-1.2"$ ./bump-version.sh 1.2Files modified successfully, version bumped to 1.2.$ git commit -a -m "Bumped version number to 1.2" Bumped version number to 1.21 files changed, 1 insertions(+), 1 deletions(-)
Dopo aver creato un nuovo ramo e avervi fatto il passaggio, si fa un bump del numero di versione.Qui, bump-version.sh è uno script di shell fittizio che cambia alcuni file nella copia di lavoro per riflettere la nuova versione. (Questo può ovviamente essere un cambiamento manuale – il punto è che alcuni file cambiano). Poi, il numero della versione modificata viene commesso.
Questo nuovo ramo può esistere per un po’ di tempo, fino a quando il rilascio può essere distribuito definitivamente. Durante questo periodo, le correzioni dei bug possono essere applicate in questo ramo (piuttosto che sul ramo develop). L’aggiunta di nuove funzionalità di grandi dimensioni qui è rigorosamente proibita. Devono essere fuse in develop, e quindi, aspettare la prossima grande release.
Finire un ramo di rilascio ¶
Quando lo stato del ramo di rilascio è pronto per diventare una vera release, alcune azioni devono essere eseguite. Per prima cosa, il ramo di rilascio viene fuso inmaster (poiché ogni commit su master è un nuovo rilascio per definizione, ricordate). Poi, quel commit su master deve essere etichettato per un facile riferimento futuro a questa versione storica. Infine, le modifiche fatte sul ramo di rilascio devono essere fuse di nuovo in develop, in modo che i futuri rilasci contengano anche queste correzioni di bug.
I primi due passi in Git:
$ git checkout masterSwitched to branch 'master'$ git merge --no-ff release-1.2Merge made by recursive.(Summary of changes)$ git tag -a 1.2
Il rilascio è ora fatto, e taggato per riferimento futuro.
Modifica: Potresti anche voler usare i flag
-so-u <key>per firmare crittograficamente il tuo tag.
Per mantenere le modifiche apportate nel ramo di rilascio, abbiamo bisogno di unire quelle nel develop, però. In Git:
$ git checkout developSwitched to branch 'develop'$ git merge --no-ff release-1.2Merge made by recursive.(Summary of changes)
Questo passo potrebbe portare ad un conflitto di fusione (probabilmente anche, visto che abbiamo cambiato il numero di versione). Se è così, correggilo e fai il commit.
Ora abbiamo davvero finito e il ramo di rilascio può essere rimosso, dato che non ne abbiamo più bisogno:
$ git branch -d release-1.2Deleted branch release-1.2 (was ff452fe).
Rami hotfix ¶
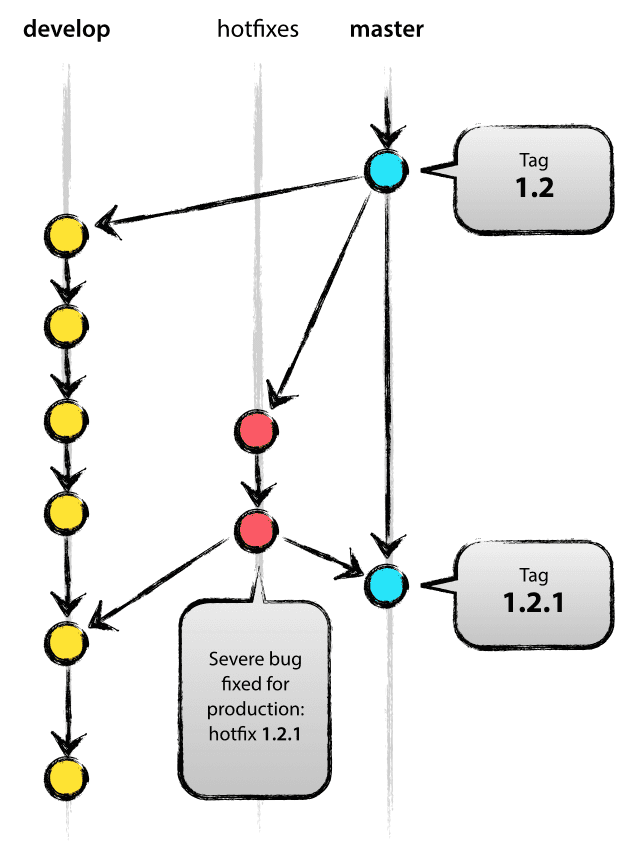
Può ramificare da:masterDeve fondersi nuovamente in:developemasterConvenzione di denominazione dei rami:hotfix-*
I rami hotfix sono molto simili ai rami di rilascio in quanto sono anche destinati a preparare un nuovo rilascio di produzione, anche se non pianificato. Nascono dalla necessità di agire immediatamente su uno stato indesiderato di una versione in produzione. Quando un bug critico in una versione di produzione deve essere risolto immediatamente, un ramo hotfix può essere diramato dal tag corrispondente sul ramo master che segna la versione di produzione.
L’essenza è che il lavoro dei membri del team (sul ramo develop) può continuare, mentre un’altra persona sta preparando una rapida correzione di produzione.
Creazione del ramo hotfix ¶
I rami hotfix sono creati dal ramo master. Per esempio, diciamo che la versione 1.2 è l’attuale versione di produzione che funziona dal vivo e che causa problemi a causa di un grave bug. Ma i cambiamenti su develop sono ancora instabili. Possiamo quindi diramare da un ramo hotfix e iniziare a risolvere il problema:
$ git checkout -b hotfix-1.2.1 masterSwitched to a new branch "hotfix-1.2.1"$ ./bump-version.sh 1.2.1Files modified successfully, version bumped to 1.2.1.$ git commit -a -m "Bumped version number to 1.2.1" Bumped version number to 1.2.11 files changed, 1 insertions(+), 1 deletions(-)
Non dimenticate di modificare il numero di versione dopo aver diramato!
Poi, correggete il bug e inviate la correzione in uno o più commit separati.
$ git commit -m "Fixed severe production problem" Fixed severe production problem5 files changed, 32 insertions(+), 17 deletions(-)
Finire un ramo hotfix ¶
Una volta finito, il bugfix ha bisogno di essere unito nuovamente in master, ma ha anche bisogno di essere fuso nuovamente in develop, al fine di salvaguardare che il bugfix sia incluso anche nel prossimo rilascio. Questo è del tutto simile a come vengono finite le releasebranches.
Prima di tutto, aggiornate master e date un tag alla release.
$ git checkout masterSwitched to branch 'master'$ git merge --no-ff hotfix-1.2.1Merge made by recursive.(Summary of changes)$ git tag -a 1.2.1
Modifica: potresti anche voler usare i flag
-so-u <key>per firmare il tuo tag in modo crittografico.
Prossimo, includere il bugfix in develop, anche:
$ git checkout developSwitched to branch 'develop'$ git merge --no-ff hotfix-1.2.1Merge made by recursive.(Summary of changes)
L’unica eccezione alla regola qui è che, quando un ramo di rilascio esiste già, le modifiche all’hotfix devono essere fuse in quel ramo di rilascio, invece di develop. Il back-merging del bugfix nel ramo di rilascio finirà per far sì che il bugfix venga fuso anche in develop, quando il ramo di rilascio sarà finito. (Se il lavoro in develop richiede immediatamente questo bugfix e non si può aspettare che il ramo di rilascio sia finito, si può tranquillamente unire il bugfix in develop già ora.)
Infine, rimuovete il ramo temporaneo:
$ git branch -d hotfix-1.2.1Deleted branch hotfix-1.2.1 (was abbe5d6).
Sommario ¶
Anche se non c’è niente di veramente sconvolgente in questo modello di ramificazione, la figura “bigpicture” con cui questo post è iniziato si è rivelata tremendamente utile nei nostri progetti. Forma un elegante modello mentale che è facile da comprendere e permette ai membri del team di sviluppare una comprensione condivisa dei processi di ramificazione e rilascio. Andate avanti e appendetela al muro per una rapida consultazione in qualsiasi momento.
Aggiornamento: E per chiunque l’abbia richiesto: ecco il thegitflow-model.src.key dell’immagine del diagramma principale (Apple Keynote).

Git-branching-model.pdf
Altri post su questo blog
- Git power tools per l’uso quotidiano
- Un’introduzione ai decoder
- Il debito tecnico è un debito reale
- Bello codice
- Bella mappa