Ultimo aggiornamento del 13 luglio 2020
La teoria dell’informazione è un sottocampo della matematica che si occupa della trasmissione dei dati attraverso un canale rumoroso.
Una pietra miliare della teoria dell’informazione è l’idea di quantificare quante informazioni ci sono in un messaggio. Più in generale, questo può essere usato per quantificare l’informazione in un evento e una variabile casuale, chiamata entropia, e viene calcolata usando la probabilità.
Calcolare l’informazione e l’entropia è uno strumento utile nell’apprendimento automatico e viene usato come base per tecniche come la selezione delle caratteristiche, la costruzione di alberi decisionali e, più in generale, l’adattamento di modelli di classificazione. Come tale, un professionista dell’apprendimento automatico richiede una forte comprensione e intuizione per l’informazione e l’entropia.
In questo post, scoprirete una leggera introduzione all’entropia dell’informazione.
Dopo aver letto questo post, saprete:
- La teoria dell’informazione riguarda la compressione e la trasmissione dei dati e si basa sulla probabilità e supporta l’apprendimento automatico.
- L’informazione fornisce un modo per quantificare la quantità di sorpresa per un evento misurata in bit.
- L’entropia fornisce una misura della quantità media di informazione necessaria per rappresentare un evento tratto da una distribuzione di probabilità per una variabile casuale.
Avvia il tuo progetto con il mio nuovo libro Probability for Machine Learning, che include tutorial passo dopo passo e i file del codice sorgente Python per tutti gli esempi.
Iniziamo.
- Aggiornamento Nov/2019: Aggiunto esempio di probabilità vs informazione e altro sull’intuizione dell’entropia.

A Gentle Introduction to Information Entropy
Foto di Cristiano Medeiros Dalbem, alcuni diritti riservati.
Panoramica
Questo tutorial è diviso in tre parti; esse sono:
- Che cos’è la teoria dell’informazione?
- Calcolare l’informazione per un evento
- Calcolare l’entropia per una variabile casuale
Cos’è la teoria dell’informazione?
La teoria dell’informazione è un campo di studio che si occupa di quantificare l’informazione per la comunicazione.
È un sottocampo della matematica e si occupa di argomenti come la compressione dei dati e i limiti dell’elaborazione dei segnali. Il campo fu proposto e sviluppato da Claude Shannon mentre lavorava alla compagnia telefonica statunitense Bell Labs.
La teoria dell’informazione si occupa di rappresentare i dati in modo compatto (un compito noto come compressione dei dati o codifica delle fonti), così come di trasmetterli e memorizzarli in modo che siano robusti agli errori (un compito noto come correzione degli errori o codifica dei canali).
– Pagina 56, Machine Learning: A Probabilistic Perspective, 2012.
Un concetto fondamentale dell’informazione è la quantificazione della quantità di informazione in cose come eventi, variabili casuali e distribuzioni.
Quantificare la quantità di informazione richiede l’uso di probabilità, da qui la relazione della teoria dell’informazione con la probabilità.
La misurazione dell’informazione è ampiamente utilizzata nell’intelligenza artificiale e nell’apprendimento automatico, ad esempio nella costruzione di alberi decisionali e nell’ottimizzazione di modelli classificatori.
Come tale, esiste un’importante relazione tra la teoria dell’informazione e l’apprendimento automatico e un professionista deve avere familiarità con alcuni dei concetti di base del campo.
Perché unificare la teoria dell’informazione e l’apprendimento automatico? Perché sono due facce della stessa medaglia. La teoria dell’informazione e l’apprendimento automatico appartengono ancora insieme. I cervelli sono i sistemi di compressione e comunicazione per eccellenza. E gli algoritmi allo stato dell’arte sia per la compressione dei dati che per i codici a correzione di errore usano gli stessi strumenti del machine learning.
– Page v, Information Theory, Inference, and Learning Algorithms, 2003.
Vuoi imparare la probabilità per l’apprendimento automatico
Prendi ora il mio corso crash gratuito di 7 giorni via email (con codice di esempio).
Clicca per iscriverti e ottieni anche una versione gratuita del corso in PDF Ebook.
Scarica il tuo mini-corso gratuito
Calcolare le informazioni per un evento
Quantificare le informazioni è il fondamento del campo della teoria dell’informazione.
L’intuizione dietro la quantificazione dell’informazione è l’idea di misurare quanta sorpresa c’è in un evento. Quegli eventi che sono rari (bassa probabilità) sono più sorprendenti e quindi hanno più informazione di quegli eventi che sono comuni (alta probabilità).
- Evento a bassa probabilità: Alta informazione (sorprendente).
- Evento ad alta probabilità: Bassa Informazione (non sorprendente).
L’intuizione di base della teoria dell’informazione è che imparare che un evento improbabile si è verificato è più informativo che imparare che un evento probabile si è verificato.
– Pagina 73, Deep Learning, 2016.
Gli eventi rari sono più incerti o più sorprendenti e richiedono più informazioni per rappresentarli rispetto agli eventi comuni.
Possiamo calcolare la quantità di informazioni di un evento usando la probabilità dell’evento. Questa è chiamata “informazione di Shannon”, “auto-informazione”, o semplicemente “informazione”, e può essere calcolata per un evento discreto x come segue:
- informazione(x) = -log( p(x) )
dove log() è il logaritmo in base-2 e p(x) è la probabilità dell’evento x.
La scelta del logaritmo in base-2 significa che l’unità di misura dell’informazione è in bit (cifre binarie). Questo può essere direttamente interpretato nel senso dell’elaborazione dell’informazione come il numero di bit richiesto per rappresentare l’evento.
Il calcolo dell’informazione è spesso scritto come h(); per esempio:
- h(x) = -log( p(x) )
Il segno negativo assicura che il risultato sia sempre positivo o zero.
L’informazione sarà zero quando la probabilità di un evento è 1,0 o una certezza, per esempio non c’è sorpresa.
Rendiamo tutto questo concreto con alcuni esempi.
Consideriamo il lancio di una singola moneta giusta. La probabilità di testa (e di croce) è 0,5. Possiamo calcolare l’informazione per il lancio di una testa in Python usando la funzione log2().
|
1
2
3
4
5
6
7
8
|
# calcolare le informazioni per un lancio di moneta
from math import log2
# probabilità dell’evento
p = 0.5
# calcolare l’informazione per l’evento
h = -log2(p)
# stampare il risultato
print(‘p(x)=%.3f, informazione: %.3f bit’ % (p, h))
|
L’esecuzione dell’esempio stampa la probabilità dell’evento come 50% e il contenuto informativo dell’evento come 1 bit.
|
1
|
p(x)=0.500, informazioni: 1.000 bit
|
Se la stessa moneta fosse lanciata n volte, allora l’informazione per questa sequenza di lanci sarebbe di n bit.
Se la moneta non fosse equa e la probabilità di una testa fosse invece del 10% (0,1), allora l’evento sarebbe più raro e richiederebbe più di 3 bit di informazione.
|
1
|
p(x)=0.100, informazioni: 3.322 bit
|
Possiamo anche esplorare l’informazione in un singolo lancio di un dado a sei facce, ad esempio l’informazione nel lancio di un 6.
Sappiamo che la probabilità di lanciare qualsiasi numero è 1/6, che è un numero minore di 1/2 per un lancio di moneta, quindi ci aspetteremmo più sorpresa o una maggiore quantità di informazioni.
|
1
2
3
4
5
6
7
8
|
# calcolare le informazioni per un lancio di dadi
from math import log2
# probabilità dell’evento
p = 1.0 / 6.0
# calcolare le informazioni per l’evento
h = -log2(p)
# stampare il risultato
print(‘p(x)=%.3f, informazioni: %.3f bit’ % (p, h))
|
Eseguendo l’esempio, possiamo vedere che la nostra intuizione è corretta e che in effetti, ci sono più di 2,5 bit di informazione in un singolo lancio di un dado giusto.
|
1
|
p(x)=0.167, informazione: 2.585 bit
|
Altri logaritmi possono essere usati al posto della base-2. Per esempio, è anche comune usare il logaritmo naturale che usa la base-e (il numero di Eulero) nel calcolo dell’informazione, nel qual caso le unità sono chiamate “nats.”
Possiamo sviluppare ulteriormente l’intuizione che gli eventi a bassa probabilità hanno più informazione.
Per rendere questo chiaro, possiamo calcolare l’informazione per probabilità tra 0 e 1 e tracciare l’informazione corrispondente per ciascuno. Possiamo quindi creare un grafico della probabilità rispetto all’informazione. Ci aspetteremmo che il grafico curvi verso il basso da basse probabilità con alte informazioni ad alte probabilità con basse informazioni.
L’esempio completo è elencato qui sotto.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# confrontare la probabilità con l’entropia dell’informazione
from math import log2
from matplotlib import pyplot
# lista di probabilità
probs =
# calcolare l’informazione
info =
# tracciare probabilità vs informazione
pyplot.plot(probs, info, marker=’.’)
pyplot.title(‘Probabilità vs Informazioni’)
pyplot.xlabel(‘Probabilità’)
pyplot.ylabel(‘Informazioni’)
pyplot.show()
|
L’esecuzione dell’esempio crea il grafico della probabilità rispetto all’informazione in bit.
Possiamo vedere la relazione attesa in cui gli eventi a bassa probabilità sono più sorprendenti e portano più informazioni, e il complemento di eventi ad alta probabilità porta meno informazioni.
Possiamo anche vedere che questa relazione non è lineare, è infatti leggermente sub-lineare. Questo ha senso dato l’uso della funzione log.
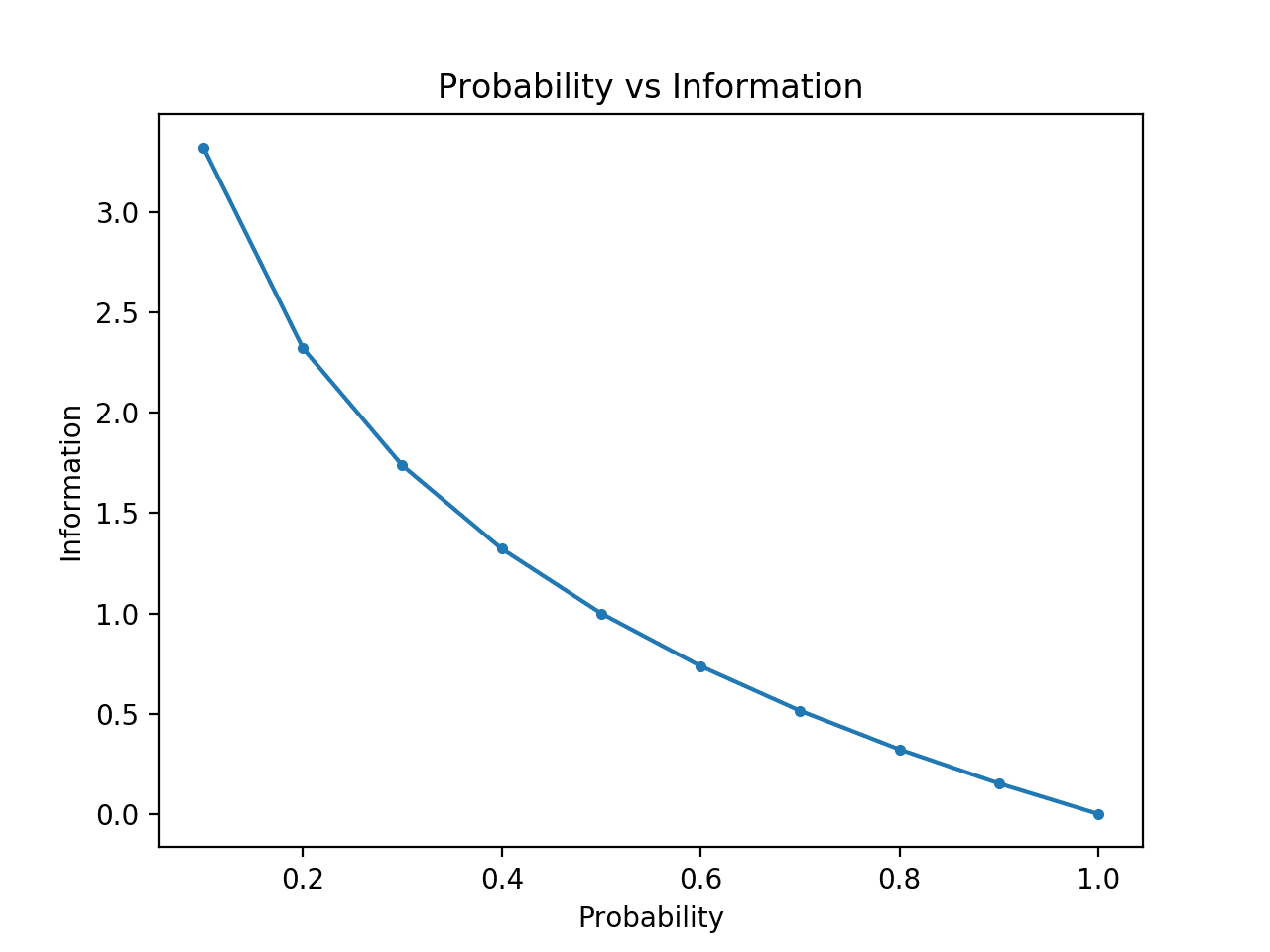
Plot di probabilità vs informazione
Calcolare l’Entropia per una variabile casuale
Possiamo anche quantificare quanta informazione c’è in una variabile casuale.
Per esempio, se volessimo calcolare l’informazione per una variabile casuale X con distribuzione di probabilità p, questo potrebbe essere scritto come una funzione H(); per esempio:
- H(X)
In effetti, calcolare l’informazione per una variabile casuale è lo stesso che calcolare l’informazione per la distribuzione di probabilità degli eventi per la variabile casuale.
Calcolare l’informazione per una variabile casuale è chiamato “entropia dell’informazione”, “entropia di Shannon” o semplicemente “entropia”. È collegata all’idea di entropia della fisica per analogia, in quanto entrambe riguardano l’incertezza.
L’intuizione per l’entropia è che è il numero medio di bit richiesti per rappresentare o trasmettere un evento tratto dalla distribuzione di probabilità della variabile casuale.
… l’entropia di Shannon di una distribuzione è la quantità attesa di informazione in un evento tratto da quella distribuzione. Dà un limite inferiore al numero di bit necessari in media per codificare simboli tratti da una distribuzione P.
– Pagina 74, Deep Learning, 2016.
L’entropia può essere calcolata per una variabile casuale X con k in K stati discreti come segue:
- H(X) = -somma(ogni k in K p(k) * log(p(k)))
Che è il negativo della somma delle probabilità di ogni evento moltiplicato per il log della probabilità di ogni evento.
Come l’informazione, la funzione log() usa la base-2 e le unità sono i bit. Un logaritmo naturale può essere usato invece e le unità saranno i nats.
L’entropia più bassa è calcolata per una variabile casuale che ha un singolo evento con una probabilità di 1.0, una certezza. L’entropia più grande per una variabile casuale sarà se tutti gli eventi sono ugualmente probabili.
Possiamo considerare un lancio di un dado equo e calcolare l’entropia per la variabile. Ogni risultato ha la stessa probabilità di 1/6, quindi è una distribuzione di probabilità uniforme. Ci aspetteremmo quindi che l’informazione media sia la stessa informazione per un singolo evento calcolato nella sezione precedente.
|
1
2
3
4
5
6
7
8
9
10
|
# calcola l’entropia per un lancio di dadi lancio
from math import log2
# il numero di eventi
n = 6
# probabilità di un evento
p = 1.0 /n
# calcola l’entropia
entropia = -sum()
# stampa il risultato
print(‘entropia: %.3f bits’ % entropia)
|
L’esecuzione dell’esempio calcola l’entropia come più di 2,5 bit, che è la stessa dell’informazione per un singolo risultato. Questo ha senso, poiché l’informazione media è uguale al limite inferiore dell’informazione, dato che tutti i risultati sono ugualmente probabili.
|
1
|
entropia: 2.585 bit
|
Se conosciamo la probabilità per ogni evento, possiamo usare la funzione entropia() SciPy per calcolare direttamente l’entropia.
Per esempio:
|
1
2
3
4
5
6
7
8
|
# calcolare l’entropia per un lancio di dadi
from scipy.stats import entropy
# probabilità discrete
p =
# calcolare l’entropia
e = entropia(p, base=2)
# stampare il risultato
print(‘entropia: %.3f bits’ % e)
|
L’esecuzione dell’esempio riporta lo stesso risultato che abbiamo calcolato manualmente.
|
1
|
entropia: 2.585 bit
|
Possiamo sviluppare ulteriormente l’intuizione per l’entropia delle distribuzioni di probabilità.
Ricordiamo che l’entropia è il numero di bit richiesti per rappresentare un pari estratto a caso dalla distribuzione, ad esempio un evento medio. Possiamo esplorare questo per una semplice distribuzione con due eventi, come il lancio di una moneta, ma esplorare diverse probabilità per questi due eventi e calcolare l’entropia per ciascuno.
Nel caso in cui un evento domina, come una distribuzione di probabilità obliqua, allora c’è meno sorpresa e la distribuzione avrà un’entropia inferiore. Nel caso in cui nessun evento domini un altro, come una distribuzione di probabilità uguale o approssimativamente uguale, allora ci aspetteremmo un’entropia maggiore o massima.
- Distribuzione di probabilità obliqua (non sorprendente): Bassa entropia.
- Distribuzione di probabilità bilanciata (sorprendente): Alta entropia.
Se passiamo da una distribuzione di probabilità asimmetrica ad una uguale degli eventi nella distribuzione ci aspetteremmo che l’entropia iniziasse bassa e aumentasse, in particolare dall’entropia più bassa di 0.0 per gli eventi con impossibilità/certezza (probabilità di 0 e 1 rispettivamente) alla più grande entropia di 1.0 per gli eventi con uguale probabilità.
L’esempio qui sotto implementa questo, creando ogni distribuzione di probabilità in questa transizione, calcolando l’entropia per ciascuna e tracciando il risultato.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# confrontare le distribuzioni di probabilità con l’entropia
from math import log2
from matplotlib import pyplot
# calcolare l’entropia
def entropy(events, ets=1e-15):
return -sum()
# definire le probabilità
probs =
# creare una distribuzione di probabilità
dists = for p in probs]
# calcolare l’entropia per ogni distribuzione
ents =
# tracciare la distribuzione di probabilità contro l’entropia
pyplot.plot(probs, ents, marker=’.’)
pyplot.title(‘Probability Distribution vs Entropy’)
pyplot.xticks(probs, )
pyplot.xlabel(‘Distribuzione di probabilità’)
pyplot.ylabel(‘Entropia (bit)’)
pyplot.show()
|
L’esecuzione dell’esempio crea le 6 distribuzioni di probabilità con probabilità fino a probabilità.
Come previsto, possiamo vedere che quando la distribuzione degli eventi passa da skewed a balanced, l’entropia aumenta da valori minimi a valori massimi.
Ovvero, se l’evento medio estratto da una distribuzione di probabilità non è sorprendente otteniamo un’entropia inferiore, mentre se è sorprendente, otteniamo un’entropia maggiore.
Possiamo vedere che la transizione non è lineare, che è super lineare. Possiamo anche vedere che questa curva è simmetrica se continuiamo la transizione a e verso i due eventi, formando una parabola rovesciata.
Nota che abbiamo dovuto aggiungere un piccolo valore alla probabilità quando abbiamo calcolato l’entropia per evitare di calcolare il log di un valore zero, che risulterebbe in un infinito su non un numero.
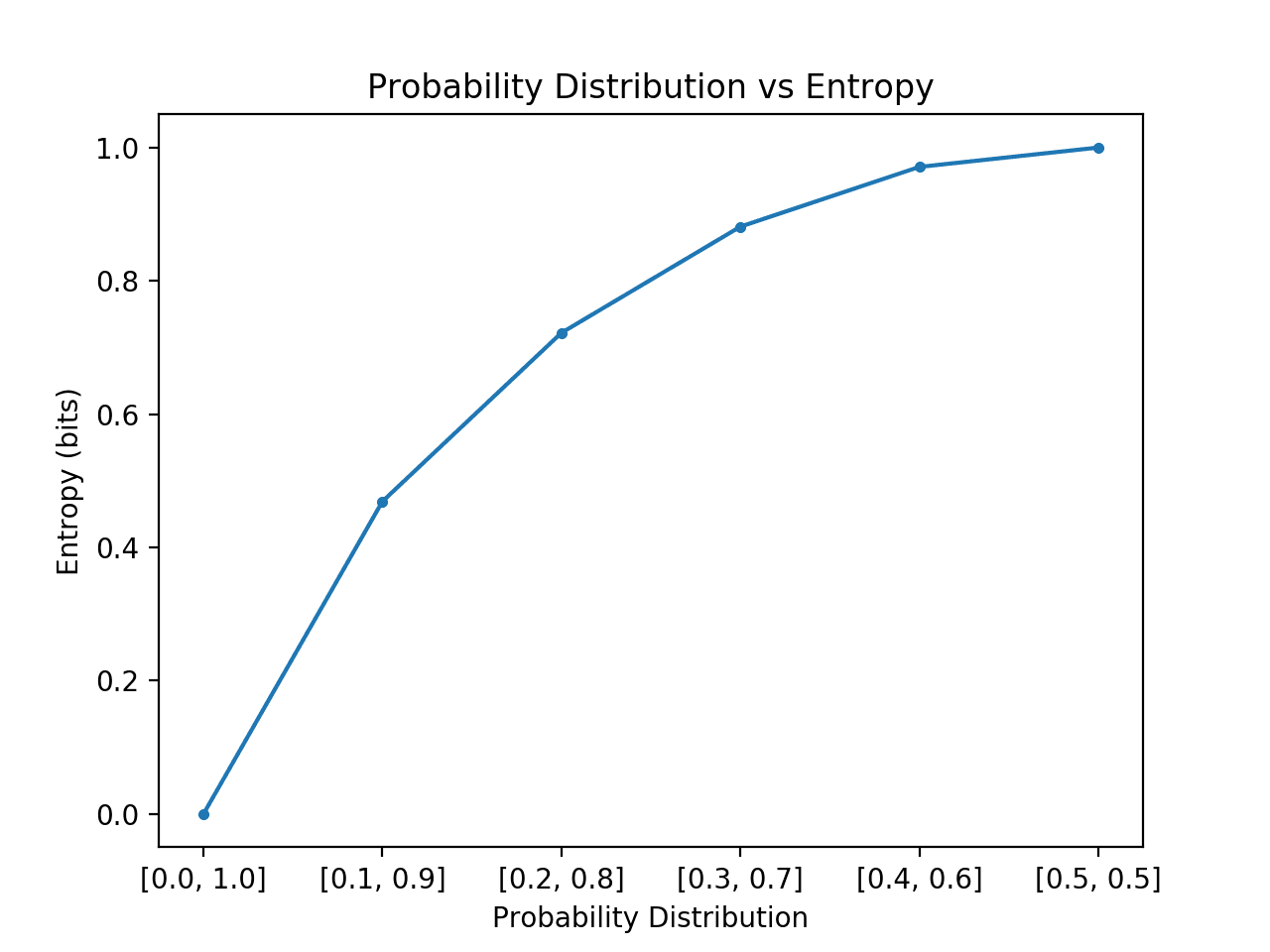
Plot of Probability Distribution vs Entropy
Calcolare l’entropia per una variabile casuale fornisce la base per altre misure come la mutua informazione (information gain).
L’entropia fornisce anche la base per calcolare la differenza tra due distribuzioni di probabilità con l’entropia incrociata e la divergenza KL.
Altre letture
Questa sezione fornisce altre risorse sull’argomento se vuoi approfondire.
Libri
- Information Theory, Inference, and Learning Algorithms, 2003.
Capitoli
- Sezione 2.8: Information theory, Machine Learning: A Probabilistic Perspective, 2012.
- Sezione 1.6: Information Theory, Pattern Recognition and Machine Learning, 2006.
- Sezione 3.13 Information Theory, Deep Learning, 2016.
API
- scipy.stats.entropy API
Articoli
- Entropia (teoria dell’informazione), Wikipedia.
- Guadagno di informazione negli alberi decisionali, Wikipedia.
- Rapporto guadagno di informazione, Wikipedia.
Sommario
In questo post, hai scoperto una leggera introduzione all’entropia dell’informazione.
Specificamente, hai imparato:
- La teoria dell’informazione riguarda la compressione e la trasmissione dei dati e si basa sulla probabilità e supporta l’apprendimento automatico.
- L’informazione fornisce un modo per quantificare la quantità di sorpresa di un evento misurata in bit.
- L’entropia fornisce una misura della quantità media di informazioni necessarie per rappresentare un evento tratto da una distribuzione di probabilità per una variabile casuale.
Hai qualche domanda?
Fai le tue domande nei commenti qui sotto e farò del mio meglio per rispondere.
Prendi confidenza con la probabilità per l’apprendimento automatico!

Sviluppa la tua comprensione della probabilità
…con poche righe di codice python
Scopri come nel mio nuovo Ebook:
Probability for Machine Learning
Fornisce tutorial di autoapprendimento e progetti end-to-end su:
Teorema di Bayes, Ottimizzazione Bayesiana, Distribuzioni, Massima Probabilità, Cross-Entropia, Calibrazione dei Modelli
e molto altro…
Finalmente sfrutta l’incertezza nei tuoi progetti
Fai a meno degli accademici. Solo risultati. Guarda cosa c’è dentro