カテゴリー変数は、疾患の発症、疾患の重症度の増加、死亡率、または2つ以上のレベルからなるその他の変数を表します。 2つのカテゴリー変数とRおよびCレベルとの関連性を要約するために、クロス集計、またはRxC表(「行」×「列」または分割表)を作成し、被験者の異なるグループ間のカテゴリー結果の観察された頻度を要約します。 ここでは、2×2表に焦点を当てます。
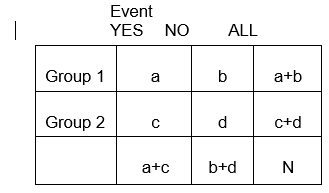
一般的に、2×2表は異なるグループ間の健康関連(またはその他)のイベントの頻度をまとめたもので、以下の図のように、グループ1は標準的な治療を受けた患者、グループ2は新しい実験的な治療を受けた患者を表しています。
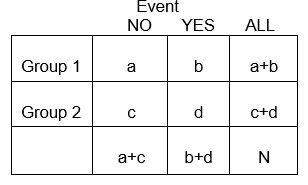
例:
川崎試験の主要なアウトカム変数は冠動脈(CA)異常の発生であり、二分法の変数でした。

これらの2つのグループ間で冠動脈異常の頻度が異なるかどうか、つまり、どちらのグループが異常が少ないかどうかに興味があるかもしれません。 冠動脈の異常の頻度が異なるかどうか、つまり、どちらかのグループの方が異常が少ないかどうかを知りたいと思います。 このような疑問に対する答えは、2つの治療群におけるこれらの健康イベントの頻度を比較することにかかっています。 研究デザインに応じて、イベントの発生確率またはイベント発生のオッズを比較することができます。
各治療群におけるCA発症の確率とオッズ
確率は、各治療カテゴリーにおける「はい」の数を治療カテゴリーの総数で割ったものとして計算されます。
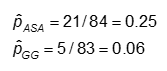
オッズは#Yes / #Noです。 ここでは
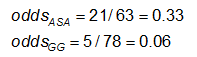
結果が行にあるのか、列にあるのかを常に意識してください。 これらを混ぜるのはとても簡単です。
1つのバイナリ変数と連続的なアウトカムの間の関連性を見たとき、私たちはその関連性を平均値の差で要約しました。 二値事象の確率に関する2群間の差を表すには、どのような統計が適切でしょうか。 関連性を要約する方法は少なくとも3つあります。
リスクの差 RD = p1 – p2
Relative Risk (Risk Ratio) RR = p1 / p2
Odds Ratio OR = odds1/ odds2 = /
研究デザインにより、これらの効果測定のどれが適切かが決まります。 症例/対照研究では、相対リスクを評価することができないため、オッズ比(OR)が適切な指標となります。
クロスセクション研究では、健康指標の有病率を評価するので、オッズ比が適切である。
クロスセクション研究では、健康指標の有病率を評価するので、オッズ比が適しています。
プロスペクティブコホート研究では、オッズ比も計算できますが、レート比またはリスク比のどちらかが適しています。
効果測定のより詳細なレビューについては、オンライン疫学モジュールの “Measure of Association “を参照してください。
例を挙げます。 先ほどのCA異常のデータを用いて、ASA(アスピリン)を使用している人とガンマグロブリン(GG)を使用している人の効果測定値は以下のようになります:
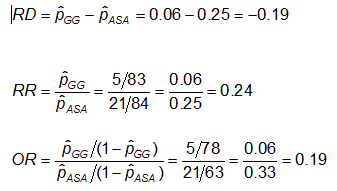

Exercise: 先ほどの例の効果の尺度を考えてみましょう。 リスク比とオッズ比が大きく異なるのはなぜでしょうか(RRはASAのみで治療した群と比較して、GGで治療した群では冠動脈異常のリスクが1/4になることを示唆しており、ORはリスクが1/5になることを示唆しています)。
帰無仮説を表現する別の方法
2×2表の場合、帰無仮説は同等に、確率そのもの、またはリスク差、相対リスク、オッズ比のいずれかで書くことができます。 いずれの場合も、帰無仮説は2つのグループの間に差がないことを示します。
H0: p1 = p2
H1: p1 ≠ p2
H0: p1 – p2 = 0 (RD=0)
H1: RD≠0
H0: p1/ p2 = 1 (RR=1)
H1: RR≠1
H0:OR=1
H1: OR≠1
カイ二乗検定
2群間のアウトカムの頻度の差は、カイ二乗検定で評価できます。
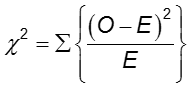
2×2表の各セルにおいて、Oは観察されたセルの頻度、Eは帰無仮説が真であるという仮定の下での期待されるセルの頻度です。 合計は、表の2×2 = 4個のセルに対して計算されます。
![]() の場合は帰無仮説を棄却します。 α=0.05の場合、臨界値は3.84.
の場合は帰無仮説を棄却します。 α=0.05の場合、臨界値は3.84.
例:
観察された度数

治療と病気の間に関連性がない場合、治療を受けた人と受けていない人の症例の割合は同じで、調査対象者全体の症例の割合と同じになります。
予想される頻度:
全体では、167人の子供のうち、CA異常があるのは26人で、CA異常がないのは141人です。 CA異常のある割合は26/167、つまり16%です。 帰無仮説が成立し、2つの治療群が同じ確率でCA異常を持つとすると、それぞれの群で約16%がCA異常を持つと予想されます。
つまり、GG群n=83では、83人中16%がCA異常を持つと予想されます。 これは、0.16×83=13と計算され、そのセルにおける期待頻度と呼ばれます。
次のように書くことができます
E11 = 1行1列の期待頻度
= 1群の中でイベントを持っている人の期待数(1行, 列1)
そして、次のように計算します。 (グループ)の1行目
= × (グループ)の1行目の数
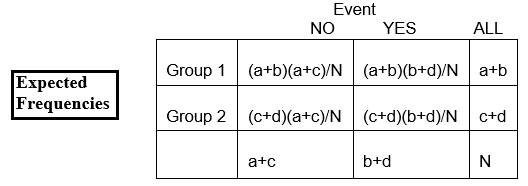
表の表記を使います。
E11 = x (a+b)
そして、これを単純に
E11 = (a+b)(a+c)/N
今回の例では。 この例では、最初のセル(E11)における期待度を計算してみましょう。
E11 = (83)(26)/167 = 12.92
同じ方法で他のセルでの期待度を計算することができます
CAの異常がない全体の割合は141/167、つまり84%です。 ASA群でCA異常がない人は約84%と予想されるので、2行目2列目の予想頻度は、E22=84の84%、つまり0.84×84、約71となります。
上の表を使って、単純に計算すると
E22=(c+d)(b+d)/N=(84)(141)/167=70.92
練習問題:帰無仮説が真であれば、ASAグループの子どものうち何人にCA異常があると予想しますか?
観察された頻度は整数値であるのに対し、期待される頻度は10進数であることに注意してください。
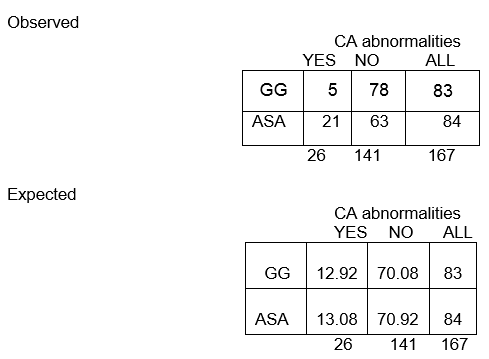
GGグループの13人近くの子供がCA異常を持つと予想されますが、実際には5人しかいませんでした!
予想頻度を1つ計算すると、他の頻度は引き算で簡単に得られることに注意してください。
カイ二乗検定統計量
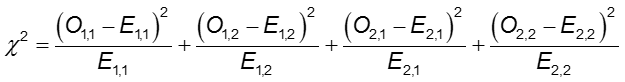
ここで、O1,1とE1,1は、1行目と1列目のセルにおける観察された数と期待された数です。 例えば、O1,1 = a、E1,1 =(a+b)(a+c)/Nとします。 観察されたセルの数が期待値と十分に異なる場合、2つの確率が等しいと結論づけることはできません。
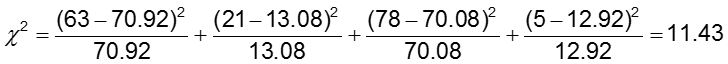
H0: CA異常のオッズは治療群間で同じ(OR=1)
H1: CA異常のオッズは治療群間で同じ(OR=1)
H1: CA異常のオッズは治療グループ間で同じではない(OR≠1)
有意水準は0.05です。05です。
検定統計量は11.43と計算されます。 検定統計量は3.84(自由度1のカイ二乗臨界値)より大きいので、帰無仮説を棄却し、CA異常のオッズは2つの治療群で同じではないと結論づけました。
トップへ戻る|前のページ|次のページ