SPSS Statistics
Interpreting and Reporting the Output of a Binomial Logistic Regression Analysis
SPSS Statisticsは、二項ロジスティック回帰を実施する際に多くの出力表を生成します。 このセクションでは、仮定に違反していないと仮定して、二項ロジスティック回帰の手順からの結果を理解するのに必要な3つの主要な表だけを示します。 二項ロジスティック回帰を実行するために必要な仮定についてデータをチェックする際に解釈しなければならない出力の完全な説明は、拡張ガイドに記載されています。
しかし、この「クイック スタート」ガイドでは、二項ロジスティック回帰の結果を理解するために必要な 3 つの主な表にのみ焦点を当てます。
説明された変動
従属変数のどのくらいの変動がモデルによって説明されるか(重回帰におけるR2に相当)を理解するために、以下の表「モデルの概要」を参照することができます:
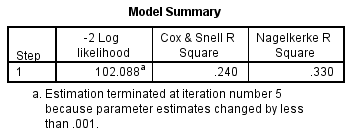
このテーブルには、説明された変動を計算する両方の方法であるCox & Snell R SquareとNagelkerke R Squareの値が含まれています。 これらの値は、疑似R2値と呼ばれることもあります(重回帰の場合よりも低い値になります)。 しかし、これらは同じように解釈されますが、より注意が必要です。 したがって、我々のモデルに基づく従属変数の説明された変動は、Cox & Snell R2法とNagelkerke R2法のどちらを参照するかによって、それぞれ24.0%から33.0%の範囲となります。 Nagelkerke R2は、Cox & Snell R2を改良したもので、後者は1の値を達成することができません。
カテゴリー予測
二項ロジスティック回帰では、ある事象(ここでは心臓病であること)の発生確率を推定します。 イベントが発生する推定確率が0.5以上(偶然よりも良い)の場合、SPSS Statisticsはイベントが発生したと分類します(例:心臓病が存在する)。 確率が0.5より小さい場合は、SPSS統計では事象が発生していない(例:心臓病がない)と分類します。 二項ロジスティック回帰を用いて、独立変数から症例が正しく分類できるか(予測できるか)を予測することは非常に一般的です。 そのため、実際の分類に対して予測した分類の有効性を評価する方法が必要になります。 これを評価する方法は数多くあり、その有用性は実施する研究の性質によって異なることが多い。
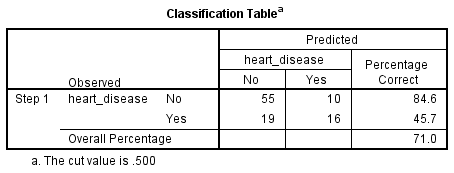
まず、この表には「The cut value is .500」と書かれた添え字があることに注目してください。 これは、あるケースが「はい」カテゴリーに分類される確率が0.500より大きい場合、その特定のケースは「はい」カテゴリーに分類されることを意味します。 それ以外の場合は、(前述のように)「いいえ」のカテゴリーに分類されます。 分類表は非常にシンプルに見えますが、実際には二項ロジスティック回帰の結果について、以下のような多くの重要な情報を提供しています:
- A. 分類精度のパーセンテージ (PAC)。 “
- C. 特異性: 観察された特性 (例えば、心臓病の「はい」) を持っておらず、観察された特性を持っていないと正しく予測された (すなわち、真の陰性) 症例の割合です。
- D. 正の予測値:観察された特性を「持つ」と正しく予測されたケースの割合を、特性を持つと予測されたケースの総数と比較したものです。
- E. 負の予測値:観察された特性を「持たない」と正しく予測されたケースの割合を、特性を持たないと予測されたケースの総数と比較したものです。
「分類表」からのPAC、感度、特異度、正の予測値、負の予測値の解釈の仕方がわからない場合は、強化された二項ロジスティック回帰のガイドで説明しています。 この表を以下に示します:
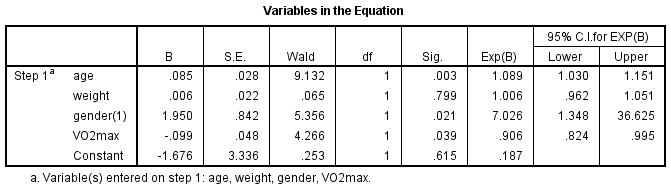
Wald検定(「Wald」列)は、独立変数のそれぞれについて統計的有意性を判定するために使用されます。 検定の統計的有意性は、「Sig.」列に記載されています。 この結果から、年齢(p = 0.003)、性別(p = 0.021)、VO2max(p = 0.039)はモデル/予測に有意に追加されましたが、体重(p = 0.799)はモデルに有意に追加されなかったことがわかります。 式中の変数」の表の情報を使用して、他のすべての独立変数が一定である場合に、独立変数の1単位の変化に基づいてイベントが発生する確率を予測することができます。 例えば、この表では、心臓病にかかる確率(「はい」のカテゴリー)は、男性の方が女性よりも7.026倍大きいことを示しています。 オッズ比を使った予測の仕方がわからない場合は、「機能」のページで充実したガイドをご紹介しています。
Putting it all together
上記の結果に基づいて、研究の結果を次のように報告することができます (注意: これには仮定のテストの結果は含まれません):
- 全般
年齢、体重、性別、および VO2max が参加者が心臓病である可能性に与える影響を確認するために、ロジスティック回帰を行いました。 ロジスティック回帰モデルは統計的に有意で、χ2(4)=27.402、p < 0.0005となりました。 このモデルは、心臓病の分散の33.0%(Nagelkerke R2)を説明し、71.0%の症例を正しく分類した。 男性は女性の7.02倍の確率で心臓病を発症していた。
上記の記述に加えて、以下の内容も含める必要があります。 (a)実施した仮定テストの結果、(b)感度、特異度、陽性予測値、陰性予測値などの「分類表」の結果、(c)どの予測変数が統計的に有意であったか、オッズ比の使用に基づいてどのような予測ができるかなどの「式中の変数」の表の結果。 この方法がわからない場合は、強化された二項ロジスティック回帰ガイドで紹介しています。 また、論文/卒論、課題、研究レポートで報告する必要がある場合、仮定のテストと二項ロジスティック回帰の出力から得られた結果をどのように記述するかを示します。 これには、ハーバード・スタイルとAPAスタイルを使用しています。 充実したコンテンツの詳細については、「機能」のページをご覧ください。
概要ページをご覧ください。