この検定はいつ使用する必要があるでしょうか? (続き…)
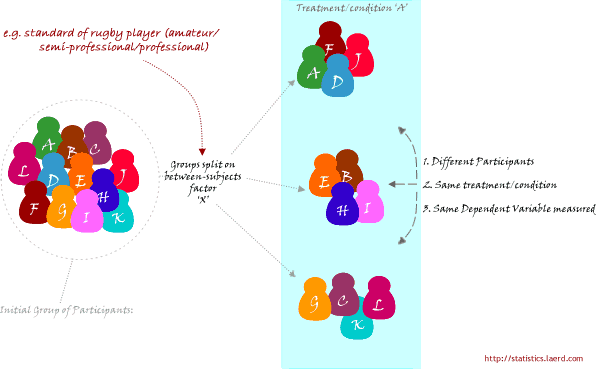
2つ目の研究デザインは、個人のグループをリクルートし、その後、いくつかの独立変数に基づいてグループに分けることです。 この場合も、各個人は1つのグループにのみ割り当てられます。 この独立変数は、属性独立変数と呼ばれることもあります。これは、個人が持つ何らかの属性に基づいてグループを分割しているからです(例えば、教育レベルなどです。 そして、各グループは、同じ課題や条件を受けた(あるいは全く受けていない)同じ従属変数について測定されます。 例えば、ある研究者が、アマチュア、セミプロ、プロのラグビー選手の間で脚力に違いがあるかどうかを調べたいとします。 アイソキネティック・マシンで測定された力/強度が従属変数です。
Why not compare groups with multiple t-test?
t-testを行うたびに、Type Iエラーを起こす可能性があります。 この誤差は通常5%です。 同じデータに対して2つのt-testを実行することで、「間違いを犯す」確率が10%に増えます。 複数のt-testを行った場合の新たな誤り率を決定する公式は、5%にtestの数を乗じればよいという単純なものではありません。 しかし、数回の多重比較しかしないのであれば、そうしても結果はよく似たものになります。 そのため、3回のt検定では15%(実際には14.3%)などとなってしまいます。 これらは許容できない誤差です。 ANOVAは、これらの誤差をコントロールするので、第一種の誤差は5%のままで、統計的に有意な結果を見つけても、たくさんのテストを実行しただけではないことを確信できます。 I型誤差の詳細については、仮説検定のガイドを参照してください。