Kategoriale Variablen können die Entwicklung einer Krankheit, eine Zunahme des Krankheitsschweregrades, die Sterblichkeit oder jede andere Variable darstellen, die aus zwei oder mehr Stufen besteht. Um die Assoziation zwischen zwei kategorialen Variablen mit R- und C-Niveaus zusammenzufassen, erstellen wir Kreuztabellen oder RxC-Tabellen („Row „x „Column“ oder Kontingenztabellen), die die beobachteten Häufigkeiten der kategorialen Ergebnisse in verschiedenen Gruppen von Probanden zusammenfassen. Hier werden wir uns auf 2 x 2 Tabellen konzentrieren.
Im Allgemeinen fassen 2 x 2-Tabellen die Häufigkeit von gesundheitsbezogenen (oder anderen) Ereignissen unter verschiedenen Gruppen zusammen, wie unten dargestellt, wobei Gruppe 1 Patienten repräsentieren könnte, die eine Standardtherapie erhalten haben, und Gruppe 2 könnten Patienten sein, die eine neue experimentelle Therapie erhalten haben.
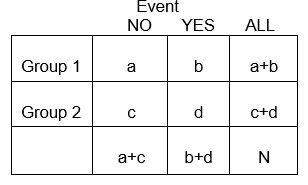
Beispiel:
Die primäre Ergebnisvariable in den Kawasaki-Studien war die Entwicklung von Anomalien der Koronararterien (CA), eine dichotome Variable. Ein Ziel der Studie war es, die Wahrscheinlichkeiten für die Entwicklung von CA-Anomalien bei Behandlung mit Aspirin (ASS) oder Gamma-Globulin (GG) zu vergleichen.

Wir könnten daran interessiert sein zu wissen, ob sich die Häufigkeit von Koronararterien-Anomalien zwischen diesen beiden Gruppen unterscheidet, d.h., ob eine der beiden Gruppen mit weniger Anomalien assoziiert war. Die Antwort auf solche Fragen hängt von einem Vergleich der Häufigkeiten dieser Gesundheitsereignisse in den beiden Behandlungsgruppen ab. Je nach Studiendesign kann man entweder die Wahrscheinlichkeit von Ereignissen oder die Odds für das Auftreten eines Ereignisses vergleichen.
Wahrscheinlichkeit und Wahrscheinlichkeit der Entwicklung von CA in jedem der Behandlungsarme
Die Wahrscheinlichkeit wird berechnet als die Anzahl der „Ja“-Werte in jeder Behandlungskategorie geteilt durch die Gesamtzahl in der Behandlungskategorie.
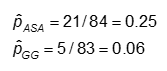
Die Wahrscheinlichkeit ist #Ja / #Nein. Hier,
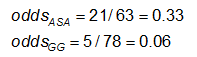
Achten Sie immer darauf, ob das Ergebnis in den Zeilen oder in den Spalten steht; Es ist sehr leicht, diese zu verwechseln!
Wenn wir die Assoziation zwischen einer binären Variable und einem kontinuierlichen Ergebnis betrachtet haben, haben wir die Assoziation in Form der Differenz der Mittelwerte zusammengefasst. Welche Statistiken sind geeignet, um den Unterschied zwischen zwei Gruppen in Bezug auf die Wahrscheinlichkeit eines binären Ereignisses darzustellen? Es gibt mindestens drei Möglichkeiten, die Assoziation zusammenzufassen:
Risikodifferenz RD = p1 – p2
Relatives Risiko (Risk Ratio) RR = p1 / p2
Odds Ratio OR = odds1/ odds2 = /
Das Studiendesign bestimmt, welches dieser Effektmaße angemessen ist. In einer Fall-Kontroll-Studie kann das relative Risiko nicht bewertet werden, und das Odds Ratio (OR) ist das geeignete Maß. Das OR liefert jedoch eine gute Schätzung des relativen Risikos für seltene Ereignisse (d.h. wenn p klein ist, typischerweise 0,10 oder kleiner).
Querschnittsstudien bewerten die Prävalenz von Gesundheitsmaßnahmen, daher ist das Odds Ratio geeignet. Bei prospektiven Kohortenstudien ist entweder ein Ratenverhältnis oder ein Risikoverhältnis angemessen, obwohl auch ein Odds Ratio berechnet werden kann.
Für eine detailliertere Übersicht über Effektmaße siehe das Online-Epidemiologie-Modul „Assoziationsmaße“.
Beispiel: Unter Verwendung der vorherigen Daten zu den CA-Anomalien lauten die Effektmaße für diejenigen, die ASS (Aspirin) gegenüber Gammaglobulin (GG) verwenden, wie folgt:
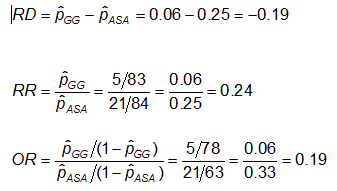

Beispiel: Betrachten Sie die Effektmaße aus dem vorherigen Beispiel. Warum sind das Risikoverhältnis und die Odds Ratio so unterschiedlich (das RR legt nahe, dass im Vergleich zu der nur mit ASS behandelten Gruppe das Risiko für Koronaranomalien bei den mit GG Behandelten 1/4 so hoch ist; während das OR nahelegt, dass das Risiko 1/5 so hoch ist)?
Alternative Wege, die Nullhypothese auszudrücken
Für eine 2×2-Tabelle kann die Nullhypothese äquivalent in Form der Wahrscheinlichkeiten selbst, oder der Risikodifferenz, des relativen Risikos oder des Odds Ratio geschrieben werden. In jedem Fall besagt die Nullhypothese, dass es keinen Unterschied zwischen den beiden Gruppen gibt.
H0: p1 = p2
H1: p1 ≠ p2
H0: p1 – p2 = 0 (RD=0)
H1: RD ≠ 0
H0: p1/ p2 = 1 (RR=1)
H1: RR ≠ 1
H0: OR = 1
H1: OR ≠ 1
Der Chi-Quadrat-Test
Der Unterschied in der Häufigkeit des Ergebnisses zwischen den beiden Gruppen kann mit dem Chi-Quadrat-Test ermittelt werden.
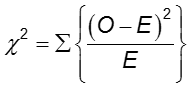
In jeder Zelle der 2×2-Tabelle ist O die beobachtete Zellhäufigkeit und E die erwartete Zellhäufigkeit unter der Annahme, dass die Nullhypothese wahr ist. Die Summe wird über die 2×2 = 4 Zellen in der Tabelle berechnet. Solange die erwartete Häufigkeit in jeder Zelle mindestens fünf ist, hat der berechnete Chi-Quadrat-Wert eine χ2-Verteilung mit 1 Freiheitsgrad (df).
Werfen Sie die Nullhypothese, wenn ![]() . Für α = 0,05 ist der kritische Wert 3,84.
. Für α = 0,05 ist der kritische Wert 3,84.
Beispiel:
Beobachtete Häufigkeiten

Wenn es keine Assoziation zwischen Behandlung und Krankheit gibt, wäre der Anteil der Fälle unter den Behandelten und Unbehandelten gleich und würde dem Anteil der Fälle in der gesamten Studienpopulation entsprechen.
Erwartete Häufigkeiten:
Insgesamt gibt es unter den 167 Kindern 26 mit CA-Anomalien und 141 ohne CA-Anomalien. Der Anteil mit CA-Anomalien beträgt 26/167, also 16 %. Wenn die Nullhypothese wahr ist und die beiden Behandlungsgruppen die gleiche Wahrscheinlichkeit für CA-Anomalien haben, dann würden wir erwarten, dass etwa 16% in jeder Gruppe CA-Anomalien haben.
So würden wir in der GG-Gruppe von n=83 erwarten, dass 16% von 83 CA-Anomalien haben. Dies wird als 0,16 x 83 = 13 berechnet und wird als erwartete Häufigkeit in dieser Zelle bezeichnet.
Wir können dies schreiben als
E11 = erwartete Häufigkeit in Zeile 1, Spalte 1
= erwartete Anzahl in Gruppe 1, die das Ereignis haben (Zeile 1, Spalte 1)
Und wir berechnen es als
E11 = (Anteil, den wir erwarten, das Ereignis zu haben) x Gesamtzahl in (Gruppe) Zeile 1
= x Anzahl in (Gruppe) Zeile 1
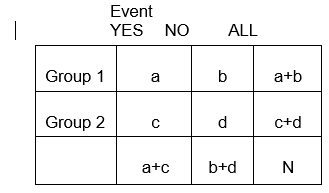
Wir verwenden die Notation der Tabelle,
E11 = x (a+b)
Und das schreiben wir oft einfach um als
E11 = (a+b)(a+c)/N
In unserem Beispiel, lassen Sie uns die erwartete Häufigkeit in der ersten Zelle ( E11) berechnen:
E11 = (83)(26)/167 = 12.92
Wir können die erwarteten Häufigkeiten in den anderen Zellen auf die gleiche Weise berechnen
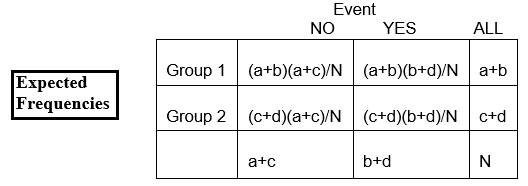
Der Gesamtanteil ohne CA-Anomalien ist 141/167, oder 84%. Wir erwarten, dass etwa 84% der Personen in der ASA-Gruppe keine CA-Anomalien haben, also ist die erwartete Häufigkeit in Zeile 2, Spalte 2, E22 = 84% von 84, oder 0,84 x 84, oder ungefähr 71.
Unter Verwendung der obigen Tabelle können wir sie einfach berechnen als
E22 = (c+d)(b+d)/N = (84)(141)/167 = 70.92
Übung: Wie viele der Kinder in der ASA-Gruppe würden Sie erwarten, dass sie CA-Anomalien haben, wenn die Nullhypothese wahr ist? Versuchen Sie, dies zu berechnen, bevor Sie sich die Antwort unten ansehen.
Beachten Sie, dass die beobachteten Häufigkeiten ganzzahlige Werte annehmen, während die erwarteten Häufigkeiten dezimale Werte annehmen können.
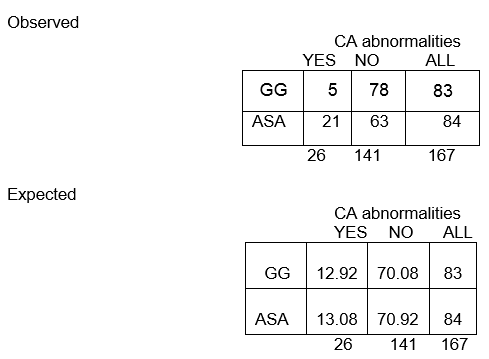
Wir erwarten, dass fast 13 Kinder in der GG-Gruppe CA-Anomalien haben, aber nur 5 haben sie tatsächlich!
Beachten Sie, dass, sobald wir eine erwartete Häufigkeit berechnet haben, die anderen einfach durch Subtraktion erhalten werden können! Die Anzahl der Freiheitsgrade entspricht der Anzahl der Zellen, deren erwartete Häufigkeit berechnet werden muss; in einer 2 x 2 Tabelle ist dies 1.
Chi-Square-Teststatistik
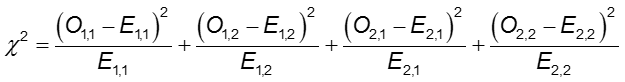
wobei O1,1 und E1,1 die beobachteten und erwarteten Werte in der Zelle in der ersten Zeile und der ersten Spalte sind. Zum Beispiel: O1,1 = a und E1,1 =(a+b)(a+c)/N. Wenn die beobachteten Zellzahlen sich stark genug von den erwarteten unterscheiden, dann können wir nicht schließen, dass die beiden Wahrscheinlichkeiten gleich sind.
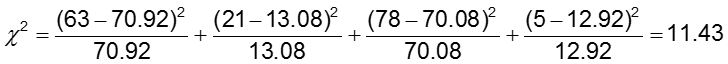
H0: Die Wahrscheinlichkeit von CA-Anomalien ist in allen Behandlungsgruppen gleich (OR=1)
H1: Die Wahrscheinlichkeit von CA-Anomalien ist in den Behandlungsgruppen nicht gleich (OR≠1)
Das Signifikanzniveau ist 0.05.
Die Teststatistik wird zu 11,43 berechnet. Da unsere Teststatistik größer als 3,84 ist (der kritische Chi-Quadrat-Wert für 1 Freiheitsgrad), lehnen wir die Nullhypothese ab und schließen, dass die Wahrscheinlichkeit von CA-Anomalien in den beiden Behandlungsgruppen nicht gleich ist.
Zurück zum Anfang | vorherige Seite | nächste Seite