NCSS enthält eine Reihe von Werkzeugen für die multivariate Analyse, die Analyse von Daten mit mehr als einer abhängigen oder Y-Variablen. Die Faktorenanalyse, die Hauptkomponentenanalyse (PCA) und die multivariate Varianzanalyse (MANOVA) sind bekannte multivariate Analyseverfahren, die alle in NCSS zur Verfügung stehen, zusammen mit einigen anderen multivariaten Analyseverfahren, wie unten beschrieben.
Benutzen Sie die Links unten, um zu dem Thema der multivariaten Analyse zu springen, das Sie untersuchen möchten. Um zu sehen, wie Sie von diesen Tools profitieren können, empfehlen wir Ihnen, die kostenlose Testversion von NCSS herunterzuladen und zu installieren.
Springen Sie zu:
- Einführung
- Technische Details
- Faktorenanalyse
- Principal Components Analysis (PCA)
- Kanonische Korrelation
- Kovarianzgleichheit
- Diskriminanzanalyse
- Hotelling’s One-Stichprobe T²
- Hotelling’s Zwei-Stichprobe T²
- Multivariate Varianzanalyse (MANOVA)
- Korrespondenzanalyse
- Loglineare Modelle
- Multidimensionale Skalierung
Einführung
Obwohl der Begriff Multivariate Analyse für jede Analyse verwendet werden kann, die mehr als eine Variable umfasst (z.z. B. in der multiplen Regression oder GLM ANOVA), wird der Begriff multivariate Analyse hier und in NCSS verwendet, um sich auf Situationen zu beziehen, die mehrdimensionale Daten mit mehr als einer abhängigen, Y- oder Ergebnisvariablen beinhalten. Multivariate Analysetechniken werden verwendet, um zu verstehen, wie der Satz von Ergebnisvariablen als kombiniertes Ganzes von anderen Faktoren beeinflusst wird, wie sich die Ergebnisvariablen zueinander verhalten oder welche zugrundeliegenden Faktoren die in den abhängigen Variablen beobachteten Ergebnisse hervorrufen.
Jede der im NCSS-Bereich Multivariate Analyse verfügbaren Prozeduren wird im Folgenden beschrieben.
Technische Details
Diese Seite soll einen allgemeinen Überblick über die Möglichkeiten von NCSS für multivariate Analysetechniken geben. Wenn Sie die Formeln und technischen Details zu einer bestimmten NCSS-Prozedur untersuchen möchten, klicken Sie auf den entsprechenden “ Link unter jeder Überschrift, um die vollständige Dokumentation der Prozedur zu laden. Dort finden Sie Formeln, Referenzen, Diskussionen und Beispiele oder Tutorials, die die Prozedur im Detail beschreiben.
Faktoranalyse
Die Faktoranalyse (FA) ist eine explorative Technik, die auf einen Satz von Ergebnisvariablen angewandt wird und versucht, die zugrunde liegenden Faktoren (oder Teilmengen von Variablen) zu finden, aus denen die beobachteten Variablen generiert wurden. Zum Beispiel wird die Antwort eines Individuums auf die Fragen in einer Prüfung von zugrundeliegenden Variablen wie Intelligenz, Schuljahren, Alter, emotionalem Zustand am Tag des Tests, Menge an Übung im Umgang mit Tests und so weiter beeinflusst. Die Antworten auf die Fragen sind die beobachteten oder Ergebnisvariablen. Die zugrundeliegenden, einflussnehmenden Variablen sind die Faktoren.
Die Faktorenanalyse wird auf der Korrelationsmatrix der beobachteten Variablen durchgeführt. Ein Faktor ist ein gewichteter Durchschnitt der ursprünglichen Variablen. Der Faktorenanalytiker hofft, einige wenige Faktoren zu finden, aus denen die ursprüngliche Korrelationsmatrix generiert werden kann.
Ziel der Faktorenanalyse ist es in der Regel, die Interpretation der Daten zu erleichtern. Der Faktorenanalytiker hofft, jeden Faktor als einen spezifischen theoretischen Faktor zu identifizieren. Ein weiteres Ziel der Faktorenanalyse ist es, die Anzahl der Variablen zu reduzieren. Der Analytiker hofft, die Interpretation eines 200-Fragen-Tests auf die Untersuchung von 4 oder 5 Faktoren zu reduzieren.
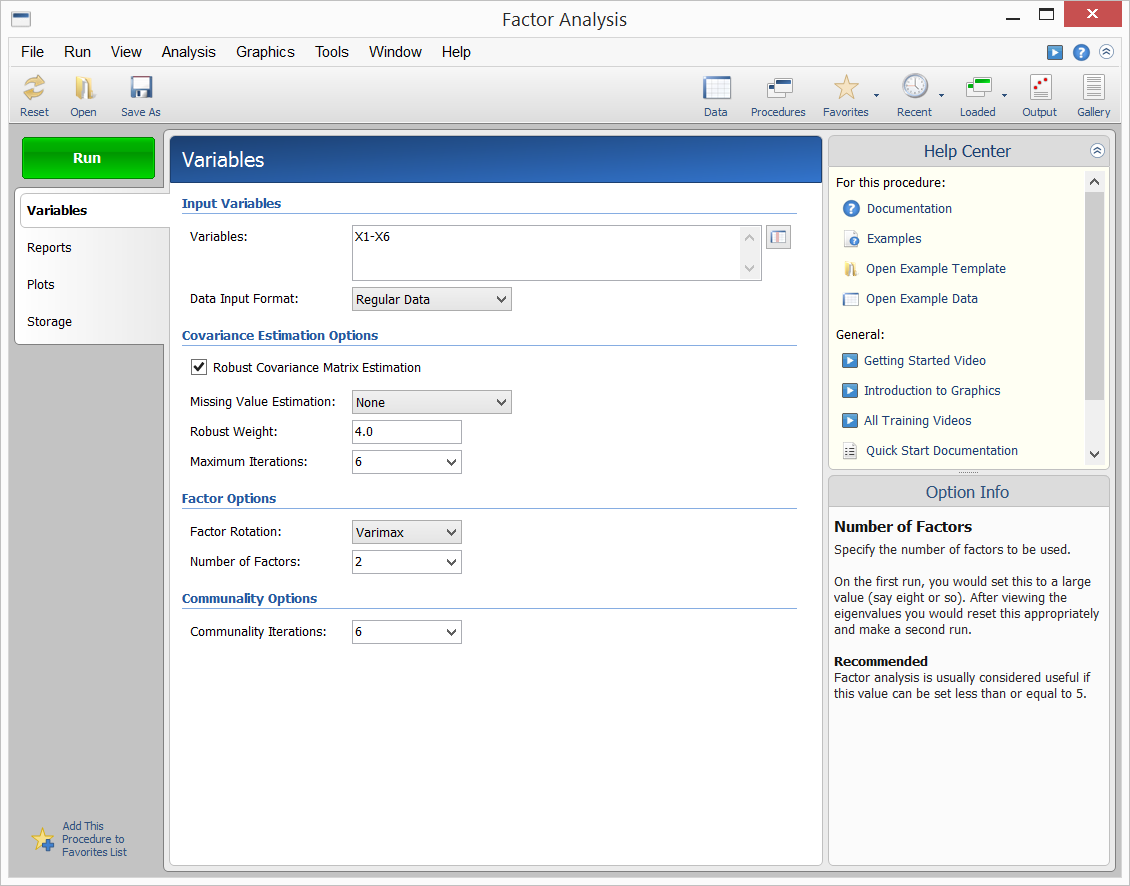
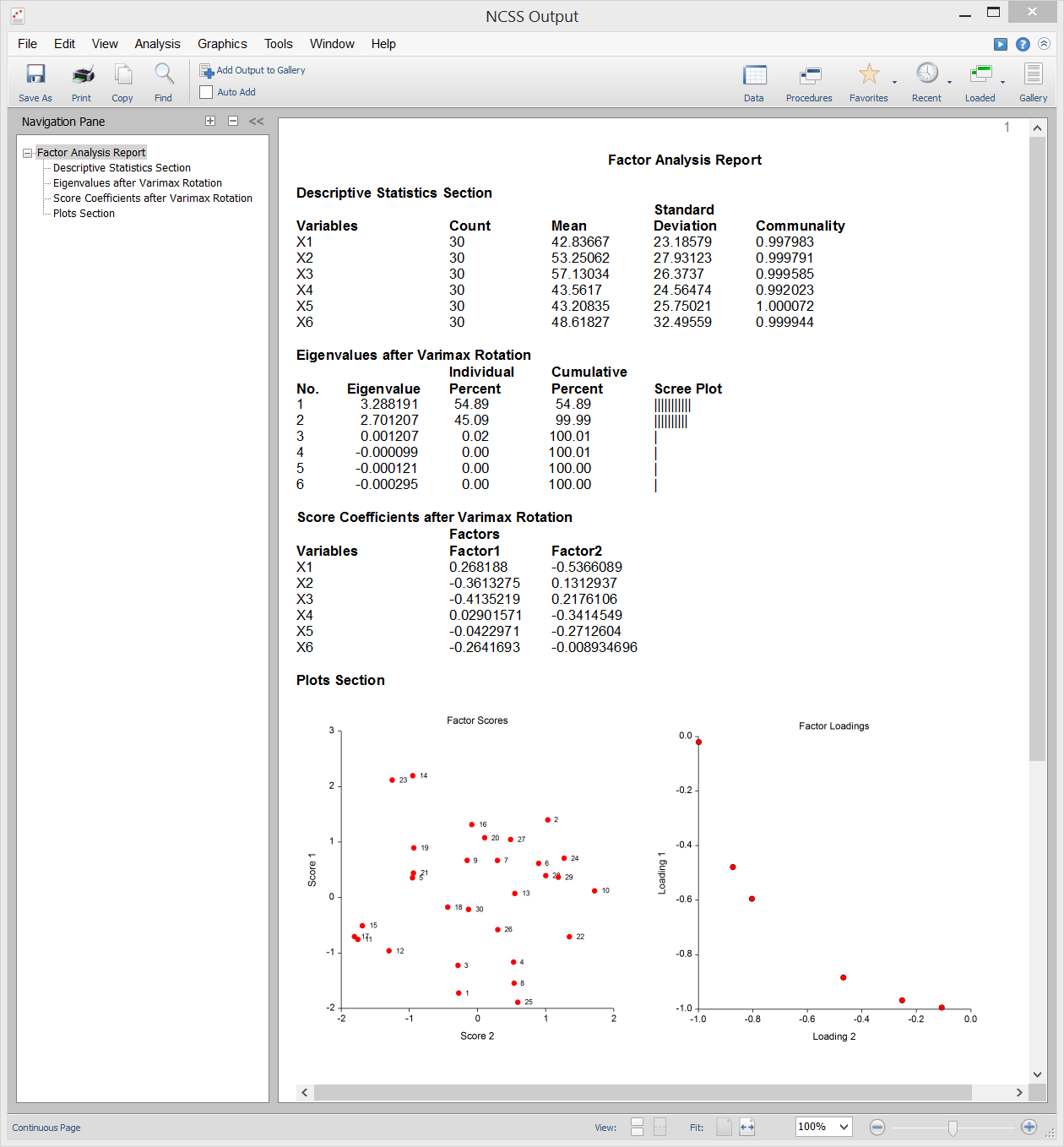
NCSS bietet die Hauptachsenmethode der Faktorenanalyse. Die Ergebnisse können mittels Varimax- oder Quartimax-Rotation gedreht und die Faktorwerte für die weitere Analyse gespeichert werden. Die Beispieldaten, die Eingabe der Prozedur und die Ausgabe sind unten dargestellt.
Beispieldaten
Prozedureingabe
Probenausgabe
Hauptkomponentenanalyse (PCA)
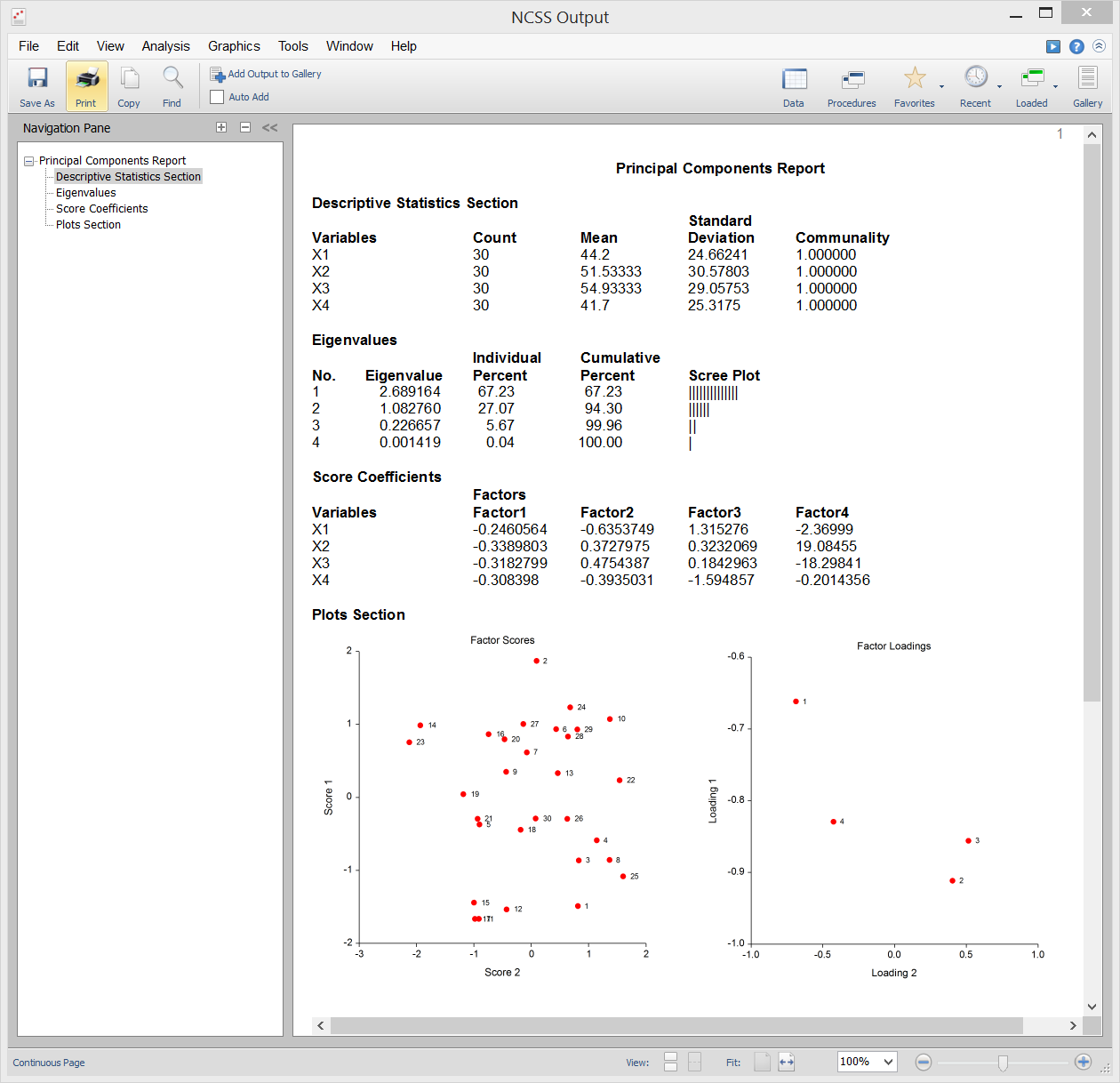
Die Hauptkomponentenanalyse (oder PCA) ist ein Datenanalysewerkzeug, das oft verwendet wird, um die Dimensionalität (oder die Anzahl der Variablen) aus einer großen Anzahl von miteinander verbundenen Variablen zu reduzieren, und dabei möglichst viele Informationen (z. B. Variation) beizubehalten.z. B. Variation) so weit wie möglich zu erhalten. Die PCA berechnet einen unkorrelierten Satz von Variablen, die als Faktoren oder Hauptkomponenten bezeichnet werden. Diese Faktoren werden so geordnet, dass die ersten paar den größten Teil der in allen ursprünglichen Variablen vorhandenen Variation beibehalten. Im Gegensatz zu ihrer Cousine, der Faktorenanalyse, liefert die PCA immer dieselbe Lösung für dieselben Daten.
NCSS verwendet eine doppelt genaue Version des modernen QL-Algorithmus, wie er von Press (1986) beschrieben wurde, um das Eigenwert-Eigenvektor-Problem zu lösen, das in die Berechnungen der PCA einbezogen ist. NCSS führt die PCA entweder auf einer Korrelations- oder einer Kovarianzmatrix durch. Die Analyse kann mit robusten Schätzverfahren durchgeführt werden.
Beispielausgabe
Kanonische Korrelation
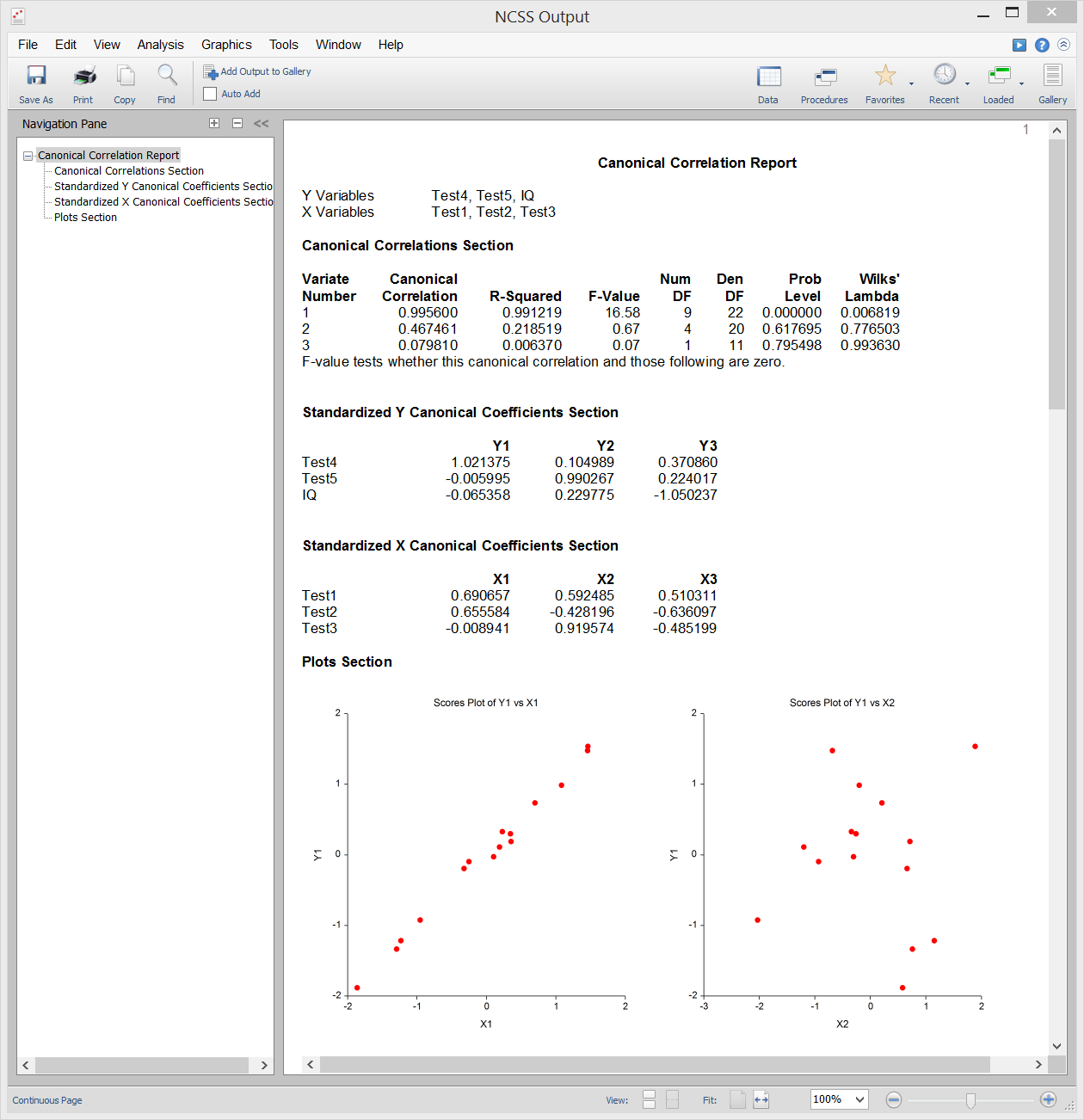
Die kanonische Korrelationsanalyse ist die Untersuchung der linearen Beziehung zwischen zwei Mengen von Variablen. Sie ist die multivariate Erweiterung der Korrelationsanalyse. Zur Veranschaulichung: Nehmen wir an, eine Gruppe von Studenten erhält zwei Tests mit jeweils zehn Fragen und Sie möchten die Gesamtkorrelation zwischen diesen beiden Tests bestimmen. Bei der kanonischen Korrelation wird ein gewichteter Mittelwert der Fragen aus dem ersten Test ermittelt und dieser mit einem gewichteten Mittelwert der Fragen aus dem zweiten Test korreliert. Die Gewichte werden so konstruiert, dass die Korrelation zwischen diesen beiden Mittelwerten maximiert wird. Diese Korrelation wird als der erste kanonische Korrelationskoeffizient bezeichnet. Sie können dann einen weiteren Satz gewichteter Durchschnitte erstellen, die nicht mit dem ersten in Beziehung stehen, und deren Korrelation berechnen. Diese Korrelation ist der zweite kanonische Korrelationskoeffizient. Der Prozess wird so lange fortgesetzt, bis die Anzahl der kanonischen Korrelationen gleich der Anzahl der Variablen in der kleinsten Gruppe ist.
Die kanonische Korrelation stellt den allgemeinsten multivariaten Rahmen dar (Diskriminanzanalyse, MANOVA und multiple Regression sind alles Spezialfälle der kanonischen Korrelation). Aufgrund dieser Allgemeinheit ist die kanonische Korrelation wahrscheinlich die am wenigsten verwendete der multivariaten Verfahren.
Beispielausgabe
Kovarianzgleichheit
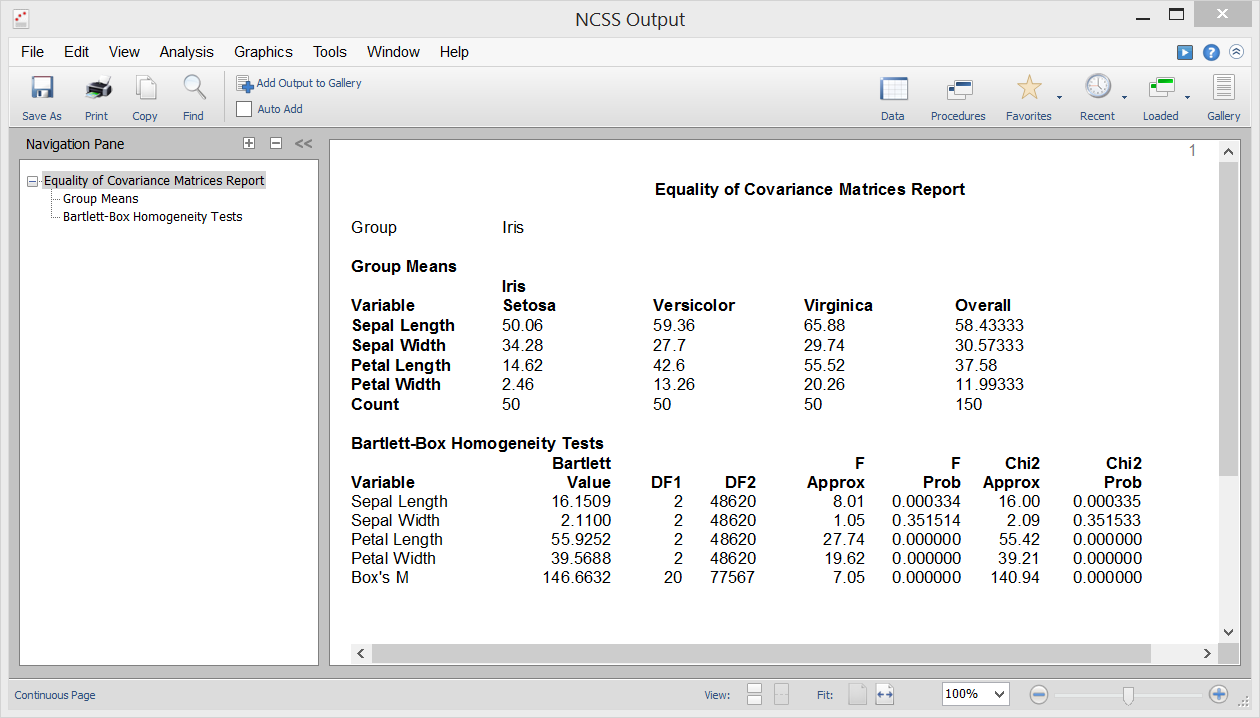
Eine der Annahmen in der Diskriminanzanalyse, MANOVA und verschiedenen anderen multivariaten Prozeduren ist, dass die Kovarianzmatrizen der einzelnen Gruppen gleich sind (d. h. homogen über die Gruppen hinweg). Mit der Prozedur „Gleichheit der Kovarianz“ in NCSS können Sie diese Hypothese mit dem Box’s M-Test testen, der erstmals von Box (1949) vorgestellt wurde. Diese Prozedur gibt auch Bartlett’s univariaten Homogenitätstest für Varianz aus, um die Gleichheit der Varianz zwischen einzelnen Variablen zu testen.
Stichprobenausgabe
Diskriminanzanalyse
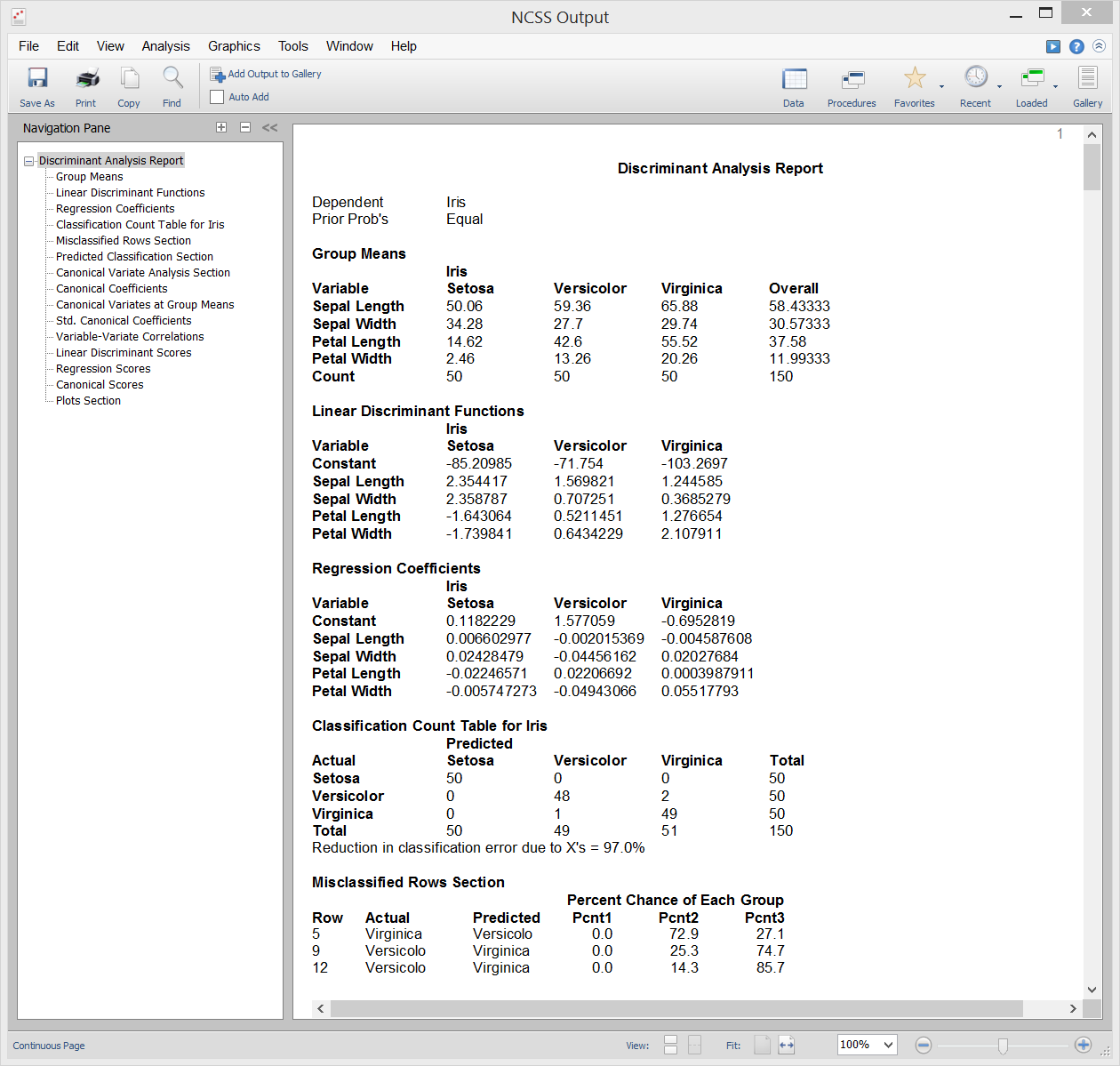
Die Diskriminanzanalyse ist eine Technik, die verwendet wird, um einen Satz von Vorhersagegleichungen zu finden, die auf einer oder mehreren unabhängigen Variablen basieren. Diese Vorhersagegleichungen werden dann verwendet, um Individuen in Gruppen zu klassifizieren. Es gibt zwei allgemeine Ziele bei der Diskriminanzanalyse: 1. eine Vorhersagegleichung für die Klassifizierung neuer Individuen zu finden und 2. die Vorhersagegleichung zu interpretieren, um die Beziehungen zwischen den Variablen besser zu verstehen.
In vielerlei Hinsicht ist die Diskriminanzanalyse der logistischen Regressionsanalyse sehr ähnlich. Die Methodik, die zur Durchführung einer Diskriminanzanalyse verwendet wird, ähnelt der logistischen Regressionsanalyse. Sie stellen oft jede unabhängige Variable gegen die Gruppenvariable dar, durchlaufen eine Variablenauswahlphase, um zu bestimmen, welche unabhängigen Variablen vorteilhaft sind, und führen eine Residualanalyse durch, um die Genauigkeit der Diskriminanzgleichungen zu bestimmen.
Die Berechnungen in der Diskriminanzanalyse sind sehr eng mit der einseitigen MANOVA verwandt. Tatsächlich sind die Rollen der Variablen einfach umgedreht. Die Klassifikationsvariable (Faktor) in der MANOVA wird zur abhängigen Variable in der Diskriminanzanalyse. Die abhängigen Variablen in der einseitigen MANOVA werden zu den unabhängigen Variablen in der Diskriminanzanalyse.
Beispielausgabe
Hotellings T²-Test für eine Stichprobe
Der T²-Test für eine Stichprobe von Hotelling ist die multivariate Erweiterung des üblichen T-Tests für eine Stichprobe oder für gepaarte Studenten. Dieser Test wird verwendet, wenn die Anzahl der Antwortvariablen zwei oder mehr ist, obwohl er auch verwendet werden kann, wenn es nur eine Antwortvariable gibt. Der Test erfordert die Annahme, dass die Daten annähernd multivariat normal sind, es gibt jedoch Randomisierungstests, die sich nicht auf diese Annahme stützen.
Stichprobenausgabe

Hotellings T²-Test für zwei Stichproben
Hotellings T²-Test für zwei Stichproben ist die multivariate Erweiterung des üblichen Student’s T-Tests für Mittelwertunterschiede für zwei Stichproben. Dieser Test wird verwendet, wenn die Anzahl der Antwortvariablen zwei oder mehr ist, obwohl er auch verwendet werden kann, wenn es nur eine Antwortvariable gibt. Der Test erfordert die Annahmen gleicher Varianzen und normalverteilter Residuen, es werden jedoch Randomisierungstests bereitgestellt, die sich nicht auf diese Annahmen stützen.
Stichprobenausgabe

Multivariate Varianzanalyse (MANOVA)
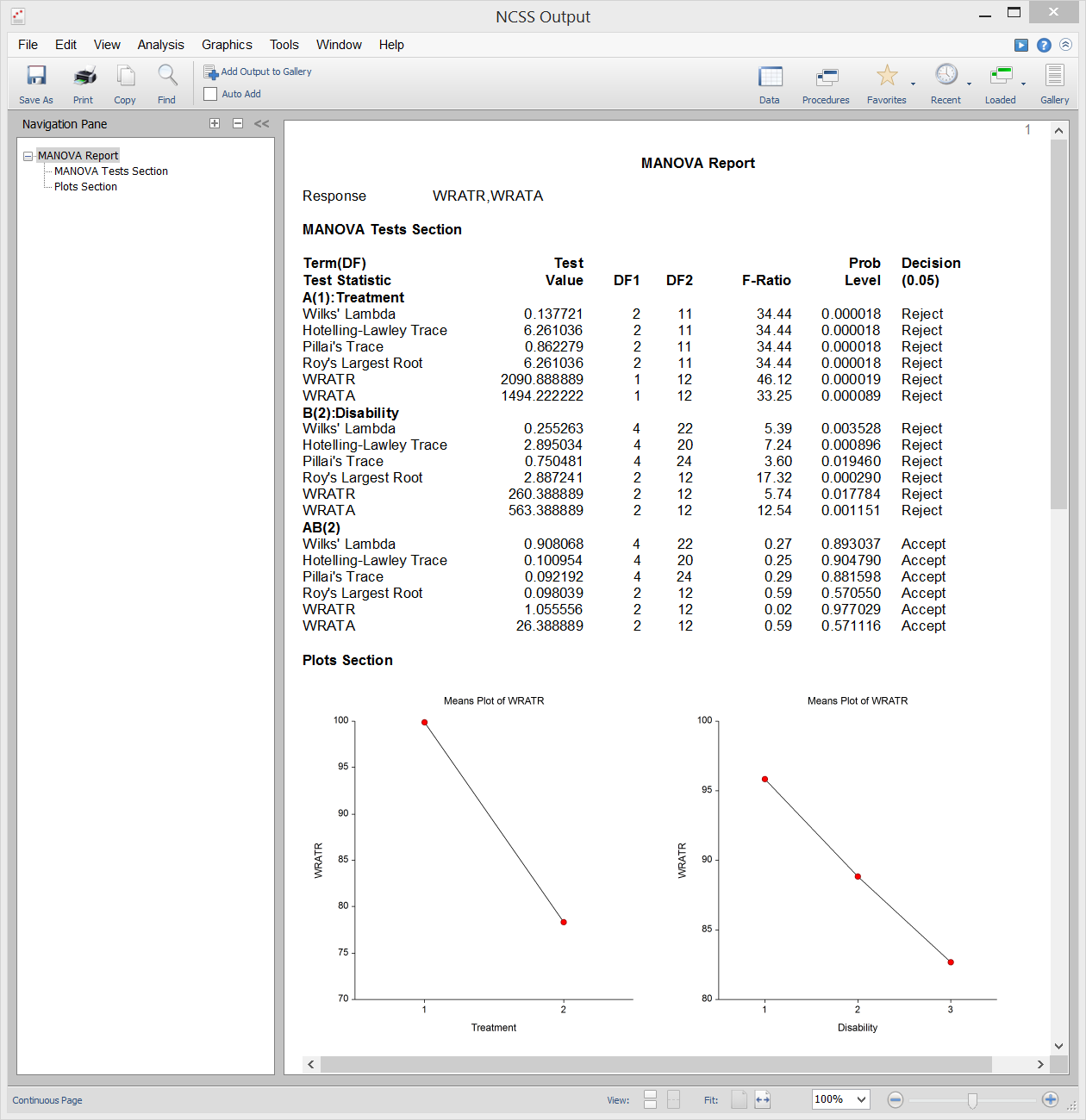
Die multivariate Varianzanalyse (oder MANOVA) ist eine Erweiterung der ANOVA für den Fall, dass es zwei oder mehr Antwortvariablen gibt. Die MANOVA ist für den Fall konzipiert, dass Sie einen oder mehrere unabhängige Faktoren (jeweils mit zwei oder mehr Stufen) und zwei oder mehr abhängige Variablen haben. Die Hypothesentests beinhalten den Vergleich von Vektoren der Gruppenmittelwerte.
Die multivariate Erweiterung des F-Tests aus der ANOVA ist nicht ganz direkt. Stattdessen stehen in der MANOVA mehrere andere Teststatistiken zur Verfügung: Wilks‘ Lambda, Hotelling-Lawley Trace, Pillai’s Trace und Roy’s Largest Root. Die tatsächlichen Verteilungen dieser Teststatistiken sind schwer zu berechnen, daher verlassen wir uns auf Näherungen, die auf der F-Verteilung basieren, um p-Werte zu berechnen.
Stichprobenausgabe
Korrespondenzanalyse
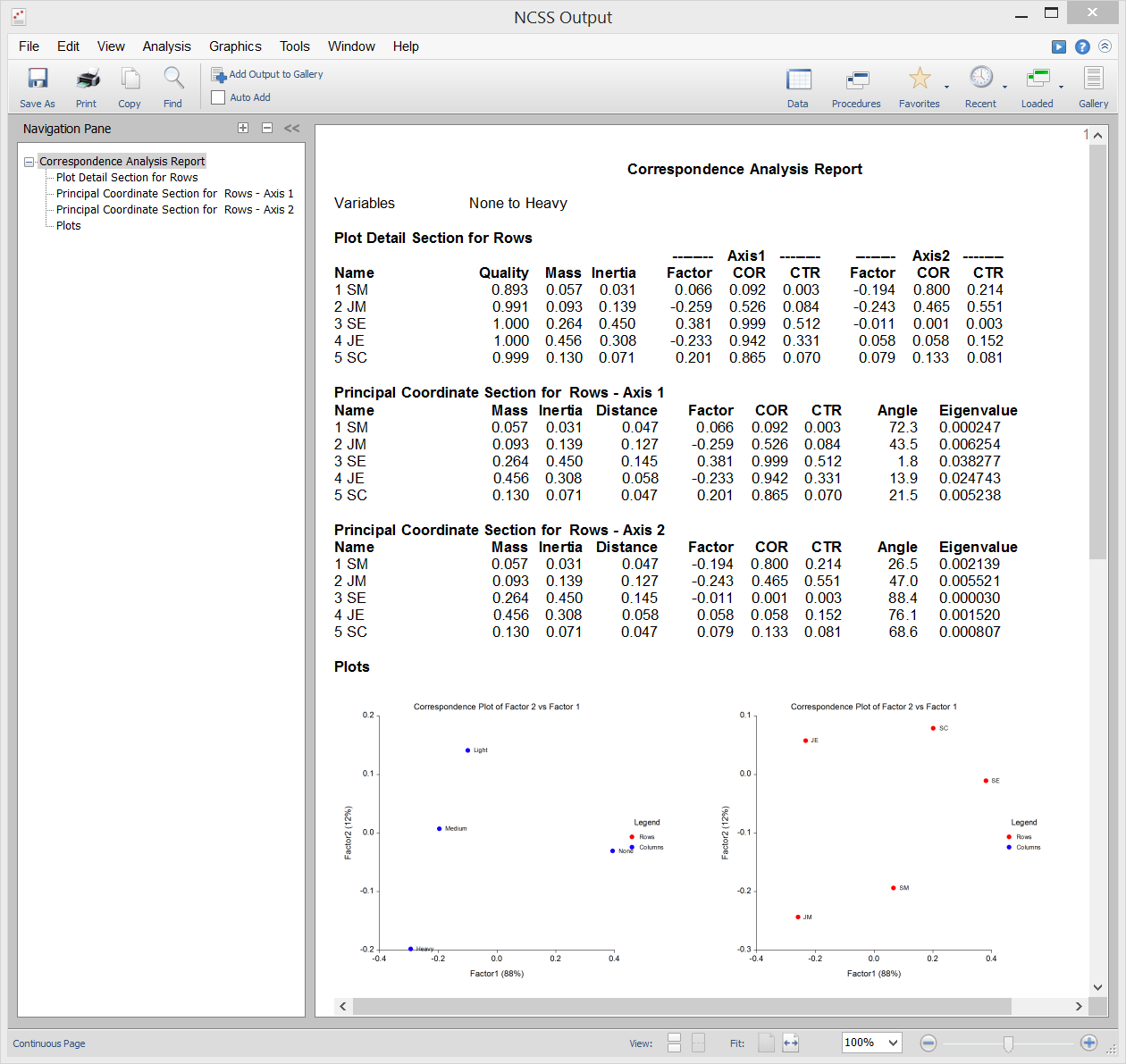
Die Korrespondenzanalyse (oder CA) ist eine Technik zur grafischen Darstellung einer Zwei-Wege-Tabelle mit kategorialen Daten unter Verwendung berechneter Koordinaten, die die Zeilen und Spalten der Tabelle darstellen. Diese Koordinaten sind analog zu Faktoren in einer Hauptkomponentenanalyse (die für kontinuierliche Daten verwendet wird), mit der Ausnahme, dass sie den Chi-Quadrat-Wert partitionieren, der beim Testen der Unabhängigkeit verwendet wird, anstatt die Gesamtvarianz.
Beispielausgabe
Loglineare Modelle
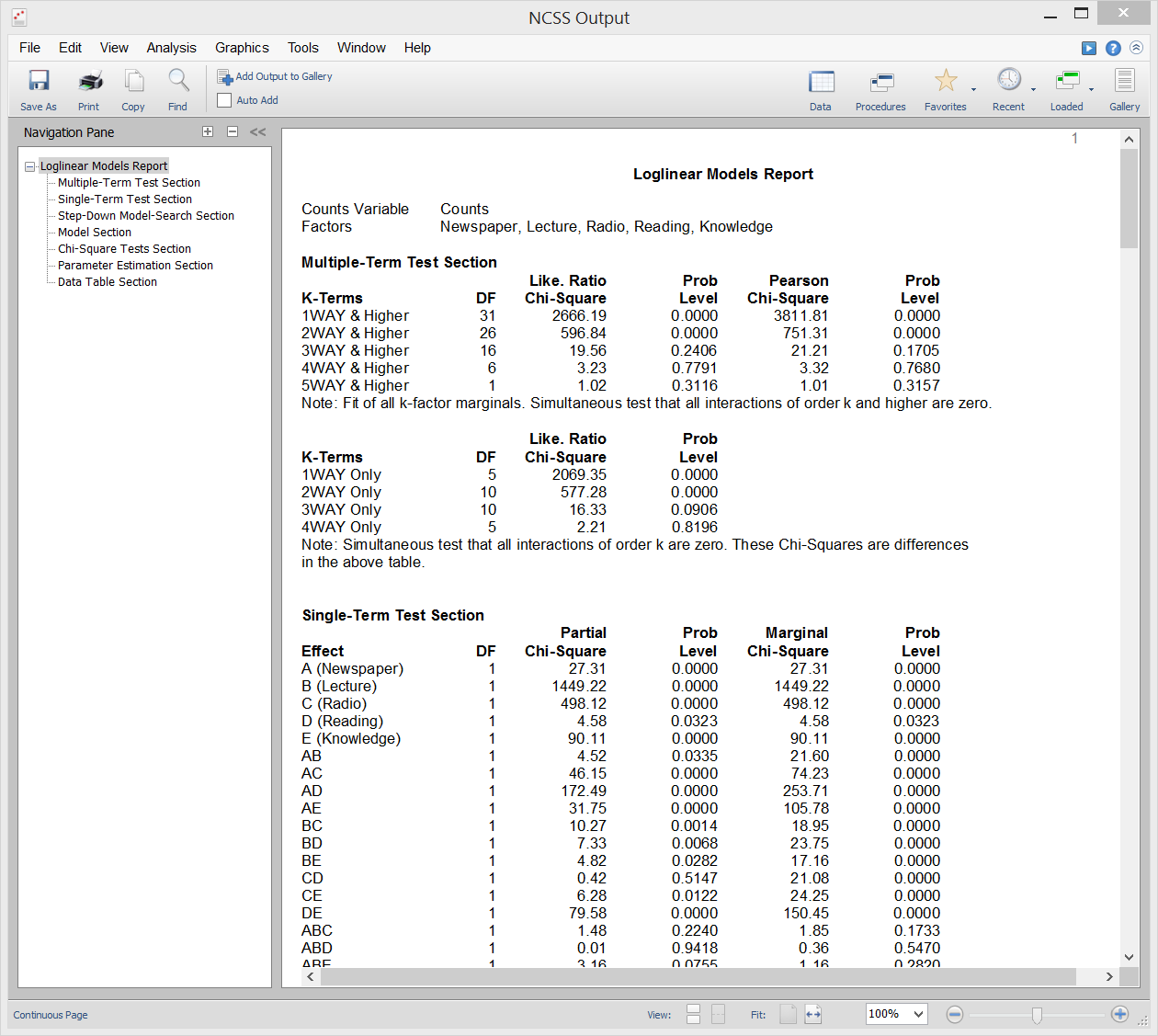
Loglineare Modelle (LLM) werden verwendet, um die Beziehungen zwischen zwei oder mehr diskreten Variablen zu untersuchen. Es wird oft als Mehrweg-Häufigkeitsanalyse bezeichnet und ist eine Erweiterung des bekannten Chi-Quadrat-Tests auf Unabhängigkeit in Zweiweg-Kontingenztabellen.
LLM kann zur Analyse von Umfragen und Fragebögen verwendet werden, die komplexe Zusammenhänge zwischen den Fragen aufweisen. Obwohl Fragebögen oft durch die Betrachtung von jeweils nur zwei Fragen analysiert werden, ignoriert dies wichtige Drei-Wege- (und Mehr-Wege-) Beziehungen zwischen den Fragen. Die Verwendung von LLM bei dieser Art von Daten ist analog zur Verwendung von multiplen Regressionen anstelle von einfachen Korrelationen bei kontinuierlichen Daten.
Die Berichte in diesem Verfahren umfassen Berichte mit mehreren Termen, Berichte mit einem Termen, Chi-Quadrat-Berichte, Modellberichte, Parameterschätzungsberichte und Tabellenberichte.
Beispielausgabe
Multidimensionale Skalierung
Multidimensionale Skalierung (MDS) ist eine Technik, die eine Karte erstellt, die die relativen Positionen einer Anzahl von Objekten anzeigt, wenn nur eine Tabelle mit den Abständen zwischen ihnen vorliegt. Die Karte kann aus einer, zwei, drei oder mehr Dimensionen bestehen. Das Verfahren berechnet entweder die metrische oder die nicht-metrische Lösung. Die Tabelle der Abstände wird als Proximity-Matrix bezeichnet. Sie ergibt sich entweder direkt aus Experimenten oder indirekt als Korrelationsmatrix.
Das Programm bietet zwei allgemeine Methoden zur Lösung des MDS-Problems. Die erste wird Metric oder Classical, Multidimensional Scaling (CMDS) genannt, weil sie versucht, die ursprüngliche Metrik bzw. die Abstände zu reproduzieren. Die zweite Methode, Non-Metric Multidimensional Scaling (NMMDS) genannt, geht davon aus, dass nur die Ränge der Abstände bekannt sind. Daher erzeugt diese Methode eine Karte, die versucht, die Ränge zu reproduzieren. Die Abstände selbst werden nicht reproduziert.