In het geval dat we inline tabelgewaardeerde functies zijn vergeten of nog nooit eerder zijn tegengekomen, beginnen we met een korte uitleg van wat ze zijn.
Als we de definitie van een door de gebruiker gedefinieerde functie (UDF) van Books Online overnemen, is een inline tabelgewaardeerde functie (iTVF) een tabeluitdrukking die parameters kan accepteren, een actie kan uitvoeren en als retourwaarde een tabel kan leveren. De definitie van een iTVF wordt permanent opgeslagen als een database object, vergelijkbaar met een view zou.
De syntax om een iTVF van Books Online (BOL) te maken kan hier worden gevonden en is als volgt:
CREATE FUNCTION function_name ( parameter_data_type } ] ) RETURNS TABLE ] RETURN select_stmt
De volgende code snippet is een voorbeeld van een iTVF.
CREATE OR ALTER FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN (SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Comments cWHERE c.UserId = @UserId AND c.CreationDate >= @CommentDateGROUP BY c.UserId);
Een paar dingen die het vermelden waard zijn in het bovenstaande script.
DEFAULT VALUE () – Je kunt standaardwaarden instellen voor parameters en in ons voorbeeld heeft @CommentDate een standaardwaarde van 01 jan 2006.
RETURNS TABLE – Geeft een virtuele tabel terug op basis van de definitie van de functie
SCHEMABINDING – Specificeert dat de functie gebonden is aan de databaseobjecten waarnaar hij verwijst. Wanneer schemabinding is gespecificeerd, kunnen de basisobjecten niet worden gewijzigd op een manier die van invloed zou zijn op de functiedefinitie. De functie-definitie zelf moet eerst worden gewijzigd of verwijderd om de afhankelijkheid van het object dat moet worden gewijzigd (van BOL) te verwijderen.
Kijkend naar het SELECT statement in het voorbeeld iTVF, is het vergelijkbaar met een query die je in een view zou plaatsen, behalve de parameter die in de WHERE clausule wordt doorgegeven. Dit is een belangrijk verschil.
Hoewel een iTVF vergelijkbaar is met een view in die zin dat de definitie permanent in de database wordt opgeslagen, hebben we door de mogelijkheid om parameters mee te geven niet alleen een manier om logica in te kapselen en te hergebruiken, maar ook flexibiliteit in de mogelijkheid om query’s uit te voeren voor specifieke waarden die we willen meegeven. In dit geval kunnen we ons voorstellen dat een inline tabel-gewaardeerde functie een soort “geparametriseerde view” is.
Waarom een iTVF gebruiken?
Voordat we ons gaan verdiepen in hoe we iTVF’s gebruiken, is het belangrijk om te overwegen waarom we ze zouden gebruiken. ITVF’s stellen ons in staat oplossingen te bieden ter ondersteuning van aspecten zoals (maar niet beperkt tot):
- Modulaire ontwikkeling
- Flexibiliteit
- Vermijden van prestatie nadelen
Ik zal elk van deze hieronder een beetje bespreken.
Modulaire ontwikkeling
iTFV’s kunnen goede ontwikkelingspraktijken aanmoedigen, zoals modulaire ontwikkeling. In wezen willen we ervoor zorgen dat onze code “DRY” is en dat we niet telkens code herhalen die we eerder hebben gemaakt als die op een andere plaats nodig is.
Als we de gevallen buiten beschouwing laten waarin modulaire ontwikkeling tot de nulde graad is doorgevoerd ten koste van onderhoudbare code, zijn de voordelen van codehergebruik en inkapseling met iTVF’s een van de eerste dingen die ons opvallen.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Users u INNER JOIN dbo.Comments c ON u.Id = c.UserIdWHERE c.CreationDate >= @CommentDateGROUP BY u.Id, u.Reputation;GO
VS
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u CROSS APPLY .(u.Id, @CommentDate) c;GO
De query die gebruik maakt van de iTVF is eenvoudig en wanneer deze wordt gebruikt in meer gecompliceerde queries, kan dit echt helpen bij de ontwikkeling door de onderliggende complexiteit te verbergen. In scenario’s waar we de logica in de functie moeten aanpassen voor verbetering of debugging doeleinden, kunnen we de wijziging in één object aanbrengen, het testen en die ene wijziging zal worden weerspiegeld in de andere plaatsen waar de functie wordt aangeroepen.
Als we de logica op meerdere plaatsen hadden herhaald, zou je dezelfde wijziging meerdere keren moeten aanbrengen met het risico van fouten, afwijkingen of andere ongelukken elke keer. Dit betekent wel dat we moeten begrijpen waar we logica hergebruiken in iTVF’s, zodat we kunnen testen of we niet van die lastige functies hebben geïntroduceerd die bekend staan als bugs.
Flexibiliteit
Als het op flexibiliteit aankomt, is het idee om gebruik te maken van de mogelijkheid van functies om parameterwaarden door te geven en gemakkelijk te interacteren te zijn. Zoals we straks aan de hand van voorbeelden zullen zien, kunnen we met de iTFV werken alsof we een query in een tabel uitvoeren.
Als de logica bijvoorbeeld in een opgeslagen procedure zou staan, zouden we de resultaten waarschijnlijk in een tijdelijke tabel moeten opnemen en vervolgens de tijdelijke tabel moeten bevragen om met de gegevens te kunnen werken.
Als de logica in een view zou staan, zouden we geen parameter kunnen invoeren. Onze opties zouden zijn om de view te bevragen en dan een WHERE clausule toe te voegen buiten de definitie van de view. Voor deze demo is dat niet zo erg, maar bij gecompliceerde query’s kan vereenvoudiging met een iTVF een elegantere oplossing zijn.
Prestatie-penalty’s vermijden
In het kader van dit artikel zal ik niet kijken naar Common Language Runtime (CLR) UDF’s.
Waar we een verschil beginnen te zien tussen iTVF’s en andere UDF’s is de prestatie. Er valt veel te zeggen over de prestaties, en voor het grootste deel hebben andere UDF’s veel te lijden van de prestaties. Een alternatief zou kunnen zijn om ze te herschrijven als iTVF’s, omdat de prestaties voor iTFV’s een beetje anders zijn. Ze hebben niet te lijden onder dezelfde prestatiebeperkingen die gelden voor scalaire of Multi Statement Table-Valued Functions (MSTVF’s).
iTVF’s worden, zoals hun naam al aangeeft, in het uitvoeringsplan geïntegreerd. Als de optimizer de query-elementen uit de definitie haalt en met de onderliggende tabellen interageert (inlining), is de kans groter dat het plan optimaal is, omdat de optimiser rekening kan houden met de statistieken van de onderliggende tabellen en andere optimalisaties, zoals parallellisme, tot zijn beschikking heeft als dat nodig is.
Voor veel mensen is alleen al de prestatie een belangrijke reden om iTVF’s te gebruiken in plaats van scalaire of MSTVF’s. Zelfs als je je nu nog niet druk maakt over de prestaties, kunnen dingen snel veranderen met grotere volumes of ingewikkelde toepassingen van je logica, dus het begrijpen van de valkuilen van de andere soorten UDF’s is belangrijk. Later in dit artikel laten we een vergelijking zien van de prestaties van iTVF’s en andere UDF’s.
Nu we een aantal redenen hebben genoemd om iTVF’s te gebruiken, laten we eens kijken hoe we ze kunnen gebruiken.
Opzetten iTVF-demo
In deze demo gebruiken we de StackOverflow2010-database, die gratis verkrijgbaar is bij de lieve mensen van StackOverflow via https://archive.org/details/stackexchange
Als alternatief kun je de database ook krijgen via de andere lieve mensen van Brent Ozar Unlimited hier : https://www.brentozar.com/archive/2015/10/how-to-download-the-stack-overflow-database-via-bittorrent/
Ik heb de StackOverflow-database hersteld op mijn lokale SQL Server 2016 Developer Edition, in een geïsoleerde omgeving. Ik zal een snelle demo uitvoeren op mijn geïnstalleerde versie van SQL Server Management Studio (SSMS) v18.0 Preview 5. Ik heb ook de compatibiliteitsmodus ingesteld op 2016 (130) en ik voer de demo uit op een machine met een Intel i7 2,11 GHz CPU en 16 GB RAM.
Als de StackOverflow-database eenmaal draait, voert u de T-SQL uit in het bronbestand 00_iTFV_Setup.sql in dit artikel om de iTVF’s te maken die we zullen gebruiken. De logica in deze iTVF’s is eenvoudig en kan op meerdere plaatsen worden herhaald, maar hier schrijven we het eenmalig en bieden het aan voor hergebruik.
Een iTVF als Virtuele Tabel gebruiken
Opgemerkt moet worden dat iTVF’s nergens in de database worden bewaard. Wat wel wordt opgeslagen is hun definitie. We kunnen nog steeds met iTVFs werken alsof het tabellen zijn, dus in dit opzicht behandelen we ze als virtuele tabellen.
De volgende 6 voorbeelden laten zien hoe we iTVFs als virtuele tabellen kunnen behandelen. Als je de StackOverflow database op je computer hebt draaien, kun je de volgende 6 queries uit Sectie 1 uitvoeren om dit zelf te zien. Je kunt deze ook vinden in het bestand, 01_Demo_SSC_iTVF_Creating_Using.sql.
/**************************************************************************1. Using iTVFs in queries as if it were a table.**************************************************************************/DECLARE @UserId INT= 3, @CommentDate DATE= '2006-01-01T00:00:00.000';--1.1 Get specific columnsSELECT UserId, LatestCommentDateFROM dbo.itvfnGetRecentComment(3, '2006-01-01T00:00:00.000');--1.2 Get all columns SELECT *FROM dbo.itvfnGetRecentComment(@UserId, @CommentDate);--1.3 Use a default valueSELECT UserId, LatestCommentDate, TotalCommentsFROM dbo.itvfnGetRecentComment(@UserId, DEFAULT);--1.4 In the WHERE clauseSELECT u.DisplayName, u.Location, u.ReputationFROM dbo.Users uWHERE u.Reputation <=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(@UserId, DEFAULT));--1.5 In the HAVING clauseSELECT u.Location, SUM(u.Reputation) AS TotalRepFROM dbo.Users uGROUP BY u.LocationHAVING SUM(u.Reputation) >=( SELECT rc.TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT) rc);--1.6 In the SELECT clauseSELECT u.Location, CASE WHEN SUM(u.Reputation) >=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT)) THEN 'YES' ELSE 'NO' END AS InRepLimitFROM dbo.Users uGROUP BY u.Location;
Zoals hierboven getoond, kunnen we bij interactie met iTVFs:
- De volledige kolomlijst teruggeven
- Gespecificeerde kolommen teruggeven
- De standaardwaarden gebruiken door het sleutelwoord door te geven, DEFAULT
- Geef de iTVF door in de WHERE-clausule
- Gebruik de iTVF in de HAVING-clausule
- Gebruik de iTVF in de SELECT-clausule
Om dit in perspectief te plaatsen, typisch met een opgeslagen procedure, zou men de resultatenset invoegen in een tijdelijke tabel en dan interageren met de tijdelijke tabel om het bovenstaande te doen. Met een iTVF is er geen noodzaak tot interactie met andere objecten buiten de definitie van de functie voor gevallen zoals de 6 die we zojuist hebben gezien.
iTVFs in geneste functies
Hoewel het nesten van functies zijn eigen problemen met zich mee kan brengen als het slecht wordt gedaan, is het iets wat we kunnen doen binnen een iTVF.
In ons voorbeeld geeft de functie dbo.itvfnGetRecentCommentByRep de laatste reactie van een gebruiker, het totaal aantal reacties enz, en voegt een extra filter voor de reputatie toe.
SELECT DisplayName, LatestCommentDate, ReputationFROM .(3, DEFAULT, DEFAULT);GO
Wanneer we de datum van de laatste opmerking teruggeven, is dit via de aanroep van de andere functie, dbo.itvfnGetRecentComment.
CREATE OR ALTER FUNCTION . (@UserId int, @Reputation int = 100, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN ( SELECT u.DisplayName, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) cWHERE u.Id = @UserId AND u.Reputation >= @Reputation);GO
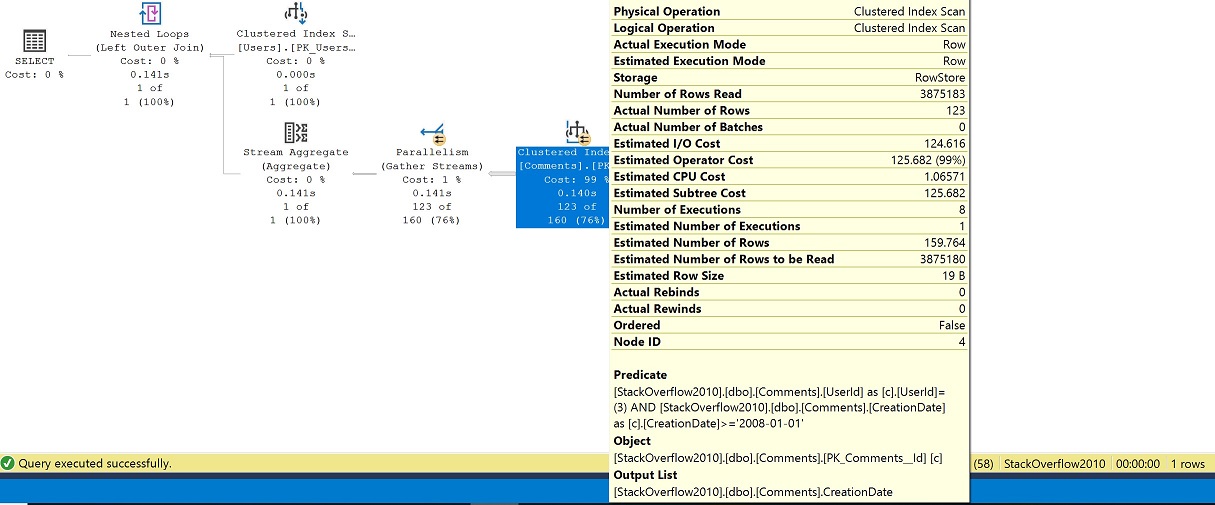
In het voorbeeld zien we dat zelfs met het nesten van functies, de onderliggende definitie wordt inlined en dat de objecten waarmee we interageren de geclusterde indexen, dbo.Users en dbo.Comments zijn.
In het plan, zonder een fatsoenlijke index om onze predicaten te ondersteunen, wordt een geclusterde index-scan van de tabel Comments uitgevoerd, en parallel gaan waar we eindigen aantal executies als 8. We filteren voor UserId 3 uit de tabel Users, zodat we een seek op de tabel Users en vervolgens join naar de tabel Comments na de GROUP BY (stroom aggregaat) voor de laatste comment datum.
De APPLY operator
De APPLY operator biedt zo veel creatieve toepassingen, en het is zeker een optie die we kunnen toepassen (woordspeling bedoeld) op de interactie met een iTVF. Voor meer over de APPLY operator, zie de volgende documenten: https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms175156(v=sql.105) en http://www.sqlservercentral.com/articles/Stairway+Series/121318/
In het volgende voorbeeld willen we de iTVF voor alle gebruikers oproepen en hun LatestCommentDate, Total Comments, Id en Reputation sinds 01 jan 2008 teruggeven. Om dit te doen gebruiken we de APPLY operator, waarbij we voor elke rij van de hele tabel Gebruikers uitvoeren, en de Id uit de tabel Gebruikers en de CommentDate doorgeven. Op deze manier behouden we de encapsulatie voordelen van het gebruik van iTVF, door onze logica toe te passen op alle rijen in de tabel Gebruikers.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
iTVFs in JOINs
Gelijk aan het joinen van 2 of meer tabellen, kunnen we iTVFs betrekken in joins met andere tabellen. Hier willen we de DisplayName uit de tabel Users en de UserId, BadgeName en BadgeDate uit de iTVF, voor gebruikers die op of na 01 jan 2008 de badge ‘Student’ hebben gekregen.
DECLARE @BadgeName varchar(40)= 'Student', @BadgeDate datetime= '2008-01-01T00:00:00.000';SELECT u.DisplayName, b.UserId, b.BadgeName, b.BadgeDateFROM dbo.Users u INNER JOIN .(@BadgeName, @BadgeDate) b ON b.UserId = u.Id;GO
Alternatief voor andere UDF’s
Eerder in dit artikel hebben we gezegd dat een reden om iTVF’s te gebruiken was om prestatieverlies te voorkomen waar andere soorten UDF’s, zoals scalaire en MSTVF’s, last van hebben. In dit deel laten we zien hoe we scalaire en MSTVF’s kunnen vervangen door iTVF’s, en in het volgende deel bekijken we waarom we daarvoor kunnen kiezen.
Scalar UDF alternatief
Voordat we verder gaan, laten we de volgende query uitvoeren om de scalar UDF, dbo.sfnGetRecentComment te maken die we straks zullen gebruiken.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS datetimeWITH SCHEMABINDING, RETURNS NULL ON NULL INPUTASBEGIN DECLARE @LatestCreationDate datetime; SELECT @LatestCreationDate = MAX(CreationDate) FROM dbo.Comments WHERE UserId = @UserId AND CreationDate >= @CommentDate GROUP BY UserId; RETURN @LatestCreationDate;END;GO
Nadat we de scalar functie hebben gemaakt, voeren we de volgende query uit. Hier willen we de logica gebruiken die is ingekapseld in de scalaire functie om de volledige tabel Gebruikers te bevragen en de Id en de laatste commentaardatum van elke gebruiker sinds 01 jan 2008 terug te geven. We doen dit door de functie toe te voegen aan de SELECT-clausule waar we als parameterwaarden de Id uit de tabel Gebruikers en de commentaardatum die we zojuist op 01 jan 2008 hebben gezet, doorgeven.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Een soortgelijke query kan worden geschreven met een iTVF, die in de volgende query wordt getoond. Hier willen we de Id en de laatste comment datum sinds 01 Jan 2008 met behulp van de iTVF en we bereiken dit door gebruik te maken van de APPLY operator tegen alle rijen van de Gebruikers tabel. Voor elke rij geven we het gebruikers-id en de commentaardatum door.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
MSTVF-alternatief
Run de volgende query om de MSTVF dbo.mstvfnGetRecentComment aan te maken, die we zo meteen zullen gebruiken.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS @RecentComment TABLE( int NULL, date NULL, int NULL)WITH SCHEMABINDING ASBEGIN INSERT INTO @RecentComment SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalComments FROM dbo.Comments c WHERE c.UserId = @UserId AND c.CreationDate >= @CommentDate GROUP BY c.UserId; RETURN;END;GO
Nu we de MSTVF hebben gemaakt, gaan we die gebruiken om de laatste commentaardatum terug te geven voor alle rijen in de tabel Gebruikers sinds 01 jan 2008. Net als het iTVF voorbeeld met de APPLY operator in het eerdere deel van dit artikel, zullen we onze functie “toepassen” op alle rijen in de tabel Gebruikers door gebruik te maken van de APPLY operator en voor elke rij de gebruikers-id door te geven, evenals de commentaardatum die we hebben ingesteld.
DECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Wanneer we de MSTVF in ons voorbeeld vervangen door een iTVF, is het resultaat zeer vergelijkbaar, behalve voor de naam van de functie die wordt aangeroepen. In ons geval roepen we itvfnGetRecentComment op in plaats van de MSTVF in het vorige voorbeeld, met behoud van de kolommen in de SELECT-clausule. Op die manier kunnen we de Id en de laatste commentaardatum sinds 01 januari 2008 verkrijgen met behulp van de iTVF voor alle rijen van de tabel Gebruikers. Dit wordt getoond in de query die volgt.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Een voorkeur voor iTVFs
Een reden om een iTVF boven een scalaire functie of MSTVF te kiezen is performance.
We zullen in het kort de prestaties van de 3 functies vastleggen op basis van de voorbeeld queries die we in de vorige sectie hebben uitgevoerd en niet in veel detail treden, anders dan het vergelijken van de prestaties in metrieken zoals uitvoeringstijd en aantal uitgevoerde functies voor de functies. De code voor performance stats die we in deze demo zullen gebruiken, komt uit Listing 9.3 in de code samples van de 3e editie van SQL Server Execution Plans door Grant Fritchey https://www.red-gate.com/simple-talk/books/sql-server-execution-plans-third-edition-by-grant-fritchey/
Scalar performance
Hier ziet u de vorige query die we hebben uitgevoerd met de scalar functie.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Het is bekend dat scalaire functies parallellisme tegengaan en dat een statement met een scalaire functie eenmaal wordt aangeroepen voor elke rij. Als je tabel 10 rijen heeft, zit je misschien goed. Een paar duizend rijen, en je zou verbaasd kunnen zijn (of niet) over de drastische prestatievermindering. Laten we dit eens in actie zien door de volgende code snippet uit te voeren.
Wat we eerst willen doen is (in een geïsoleerde omgeving) de SQL Server cache en het bestaande plan dat hergebruikt zou kunnen worden leegmaken(FREEPROCCACHE), ervoor zorgend dat we eerst data van schijf halen (DROPPCLEANBUFFERS) om te beginnen met een koude cache. We beginnen dus losjes met een schone lei.
Daarna voeren we de SELECT query uit op de Gebruikers tabel waar we de Id en de LatestCommentDate teruggeven met de scalar functie. Als parameterwaarden geven we de Id uit de tabel Users en de commentaardatum door, die we zojuist op 01 jan 2008 hebben gezet. Een voorbeeld ziet er als volgt uit.
-- run in an isolated environmentCHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Hoewel de SELECT query waarin we de scalar functie gebruiken eenvoudig van structuur lijkt, was hij na 4 minuten op mijn machine nog steeds aan het uitvoeren.
Houd in gedachten dat voor scalar functies geldt dat ze voor elke rij één keer worden uitgevoerd. Het probleem hiermee is dat rij-voor-rij operaties zelden de meest efficiënte manier zijn om gegevens op te halen in SQL Server in vergelijking met enkelvoudige set-gebaseerde operaties.
Om herhaalde executies te observeren, kunnen we een query uitvoeren voor een aantal performance stats. Deze worden door SQL Server verzameld wanneer we onze query’s uitvoeren en hier willen we het query statement, de aanmaak tijd, het aantal uitgevoerde query’s en het query plan verkrijgen. De volgende query is een voorbeeld van hoe we de performance stats kunnen krijgen.
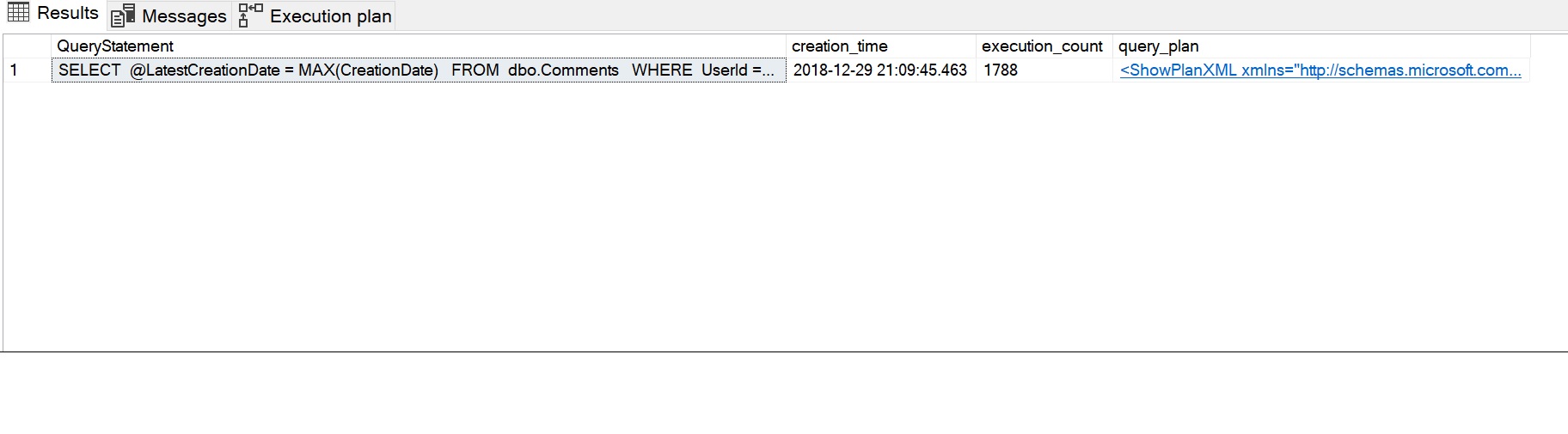
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.sfnGetRecentComment')ORDER BY deqs.last_execution_time DESC;GO
De resulterende uitvoering van de performance stats is te zien in de volgende afbeelding. Het query statement toont het SELECT statement dat door de scalar functie wordt gebruikt, de execution count van 1788 heeft de herhaalde execution count (één keer voor elke rij) vastgelegd en het plan dat door de functie wordt gebruikt kan worden bekeken door op het query plan XML-bericht te klikken.
Een extra manier om belangrijke performance metrics te zien is door extended events te gebruiken. Klik hier voor meer informatie over uitgebreide events, maar voer voor deze demo de volgende query uit om een uitgebreide eventsessie te maken.
CREATE EVENT SESSION QuerySession ON SERVER ADD EVENT sqlserver.module_end( WHERE (.(.,(??)))), -- enter your Session Id ADD EVENT sqlserver.sp_statement_completed( WHERE (.(.,(??)))),-- enter your Session Id ADD EVENT sqlserver.sql_batch_completed( WHERE (.(.,(??)))); -- enter your Session IdGOALTER EVENT SESSION QuerySession ON SERVER STATE = START;GO
Als de uitgebreide eventsessie is gemaakt, ga je naar Management in Object Explorer, breid je sessies uit en open je het contextmenu voor de “QuerySessie” die we zojuist hebben gemaakt. Selecteer “Live gegevens bekijken”.
In het nieuw geopende venster ziet u de meerdere statementregels van de scalaire functie als bewijs van de herhaalde uitvoeringen.
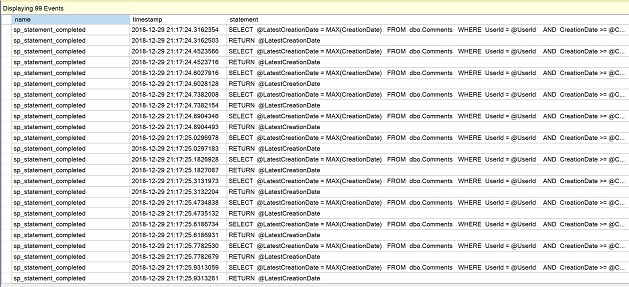
Klik op het rode vierkantje om “Gegevensinvoer stoppen” voor nu.
MSTVF-prestaties
Voor MSTVF’s kan het gebruik ervan ook nadelige gevolgen hebben voor de prestaties. Dit houdt verband met het feit dat SQL Server vanwege onnauwkeurige statistieken voor suboptimale uitvoeringsplannen kiest. SQL Server vertrouwt op intern verzamelde statistieken om te begrijpen hoeveel rijen data een query zal retourneren zodat het een optimaal plan kan produceren. Dit proces staat bekend als cardinality estimation.
Vóór SQL Server 2014 was de cardinality estimation voor tabelvariabelen ingesteld op 1 rij. Vanaf SQL Server 2014 is dit ingesteld op 100 rijen, ongeacht of we een query uitvoeren tegen 100 rijen of 1 miljoen rijen. MSTVF’s retourneren gegevens via tabelvariabelen die aan het begin van de definitie van de functie worden gedeclareerd. De realiteit is dat de optimizer niet altijd het beste plan zal zoeken dat hij kan vinden, ongeacht de tijd, en dat hij daar een evenwicht moet bewaren (heel eenvoudig gezegd). Met MSTVF’s kan het gebrek aan nauwkeurige statistieken (veroorzaakt door onnauwkeurige kardinaliteitsschatting van tabelvariabelen binnen hun definitie) de prestaties remmen doordat de optimizer suboptimale plannen produceert.
In de praktijk kan het vervangen van MSTVF’s door iTVF’s betere prestaties opleveren, omdat iTVF’s de statistieken van de onderliggende tabellen zullen gebruiken.
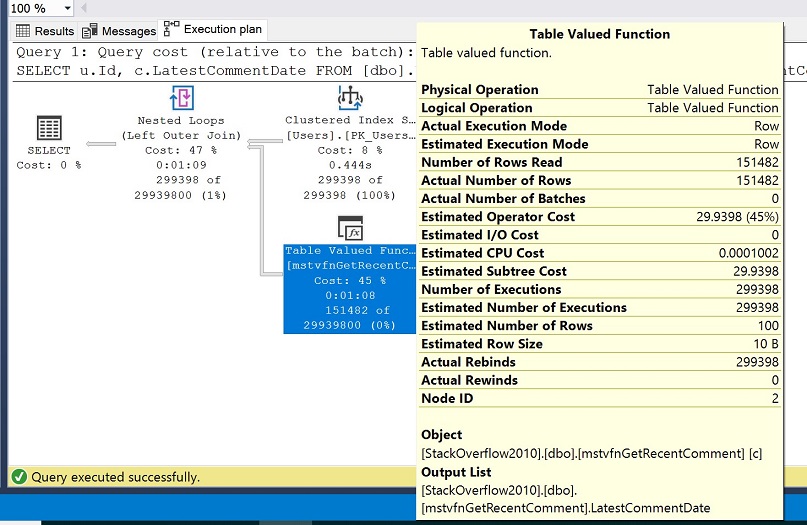
De volgende code snippet gebruikt de APPLY operator om de MSTVF uit te voeren tegen de gehele Users tabel. We retourneren de Id uit de tabel Gebruikers en de LatestCommentDate uit de functie voor elke rij in de tabel Gebruikers, waarbij we de Id van de gebruiker en de commentaardatum die is ingesteld voor 01 jan 2008, doorgeven. Vergelijkbaar met de scalaire functie run, zullen we dit doen vanuit een koude cache. Met deze test, hebben ook de Actual execution plan geselecteerd in SSMS, door te klikken op Ctrl + M. Voer de query.
CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Het resulterende uitvoeringsplan wordt getoond in de volgende afbeelding en in de gele eigenschappen box, let op de waarden voor het geschatte aantal rijen versus het werkelijke aantal rijen.
Je zou moeten zien dat het geschatte aantal rijen van de tabel gewaardeerde functie is ingesteld op 100, maar het werkelijke aantal rijen is ingesteld op 151.482. Denk eraan dat we in onze opzet hebben gekozen voor de compatibiliteitsmodus van SQL Server 2016 (130) en dat vanaf SQL Server 2014 de schatting van de cardinaliteit is ingesteld op 100 voor tabelvariabelen.
Zulke sterk verschillende waarden voor het geschatte aantal rijen versus het werkelijke aantal rijen is typisch nadelig voor de prestaties en kan voorkomen dat we optimalere plannen krijgen en uiteindelijk beter lopende query’s.
Gelijk aan de scalaire functie die we eerder hebben uitgevoerd, zullen we een query uitvoeren tegen de prestatiestats van SQL Server. Ook hier willen we het querystatement, de aanmaaktijd, het aantal executies van het statement en het gebruikte queryplan verkrijgen en filteren op de MSTVF in de WHERE-clausule.
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs OUTER APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp OUTER APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.mstvfnGetRecentComment');
Het uitvoeringsplan dat we aanvankelijk voor de MSTVF hebben waargenomen, is misleidend omdat het niet het werkelijke werk weergeeft dat door de functie wordt verricht. Met behulp van de performance stats die we zojuist hebben uitgevoerd en het selecteren van de Showplan XML, zouden we een ander query plan moeten zien dat het werk laat zien dat door de MSTVF wordt gedaan. Een voorbeeld van een ander plan dan we in eerste instantie zagen is als volgt. Hier kunnen we nu zien dat de MSTVF gegevens invoegt in een tabelvariabele genaamd @RecentComment. De gegevens in de tabelvariabele @RecentComment is wat vervolgens wordt geretourneerd door de MSTVF om de laatste commentaardatum terug te geven.
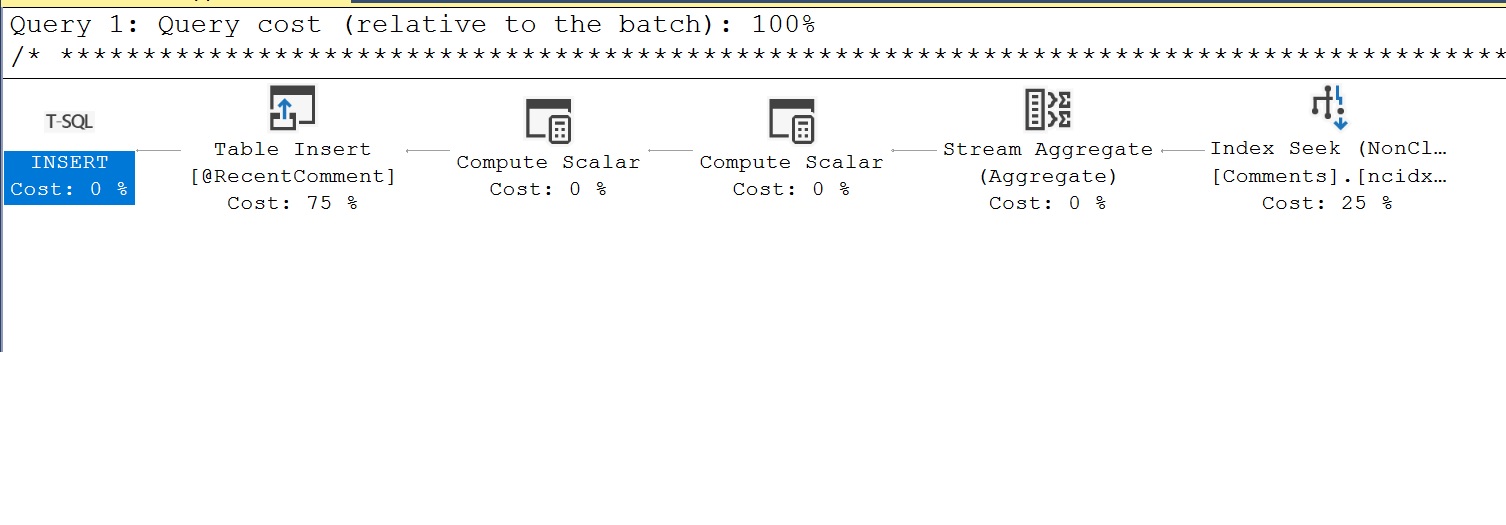
Een ander aspect van de performance metrics die we hebben vastgelegd is het aantal executies. Hier moeten we op onze hoede zijn voor meervoudige executietellingen, omdat deze doorgaans slecht zijn voor de prestaties, zoals vermeld bij de scalaire performance.
Wat we in de volgende afbeelding zien voor executietelling, is een waarde van 76, wat wijst op meervoudige executies van onze MSTVF.

Laten we teruggaan naar Management in Object Explorer, sessies uitbreiden en “Live gegevens bekijken” selecteren voor de “QuerySessions”-sessie die we eerder hebben gemaakt toen we naar de scalaire prestaties keken. Klik op het groene driehoekje “Start data feed” in SSMS als de sessie eerder was gestopt en we zouden voor ons voorbeeld meerdere statement regels van de MSTVF moeten zien die de herhaalde executies van het statement vertegenwoordigen.
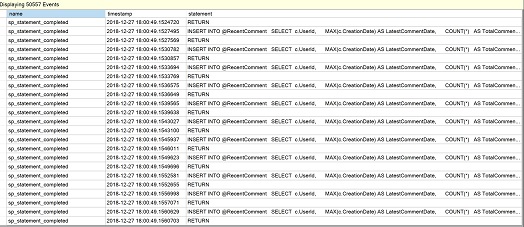
Voel je vrij om de query op dit punt te annuleren als deze nog niet is voltooid.
iTVF performance
Wanneer we de scalar of multi statement functies vervangen door een iTVF, willen we dat doen om de prestatie nadelen te vermijden die we zojuist hebben gezien, bijv. uitvoeringstijd, meerdere executies. Met behulp van het vorige voorbeeld dat volgt, zullen we een query uitvoeren op de tabel Gebruikers om de Id en de Laatste commentaardatum op te halen uit de iTVF sinds 01 januari 2008. met behulp van de APPLY operator. We zullen dit ook doen vanuit een koude cache door de SQL Server cache te legen en gegevens van schijf te halen om mee te beginnen.
--run in an isolated environment CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
De volgende query bestaat uit de performance stats die ons helpen om te zien welk statement wordt uitgevoerd, het aantal executies en het query plan voor dat statement.
-- Query stats and execution planSELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.dbid = DB_ID('StackOverflow2010')ORDER BY deqs.last_execution_time DESC;
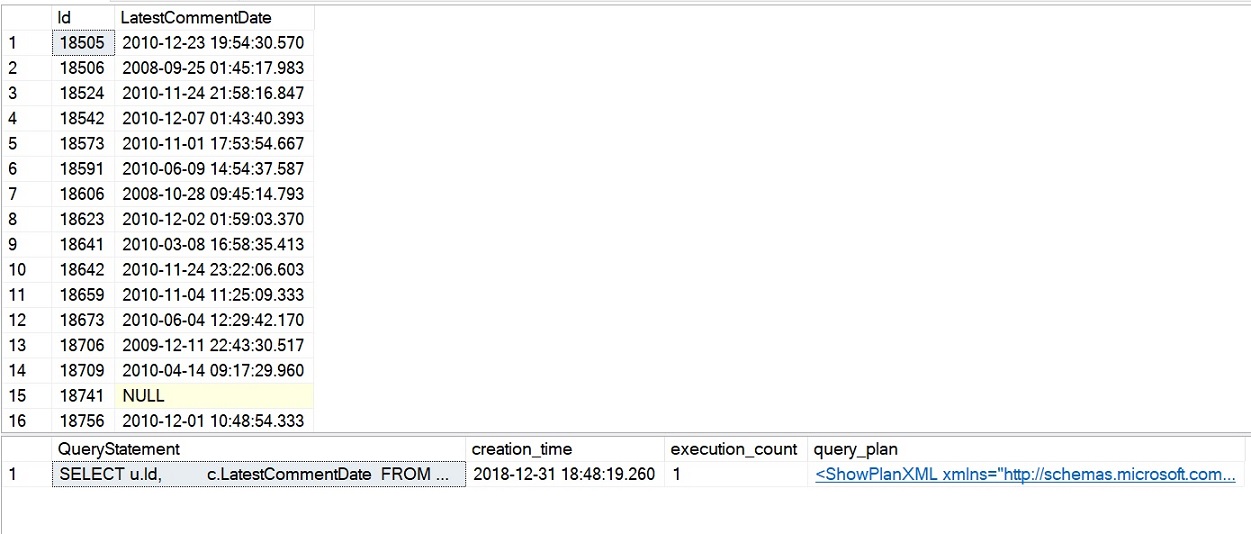
De voorbeeld query voor de iTVF die we zojuist hebben uitgevoerd, is in iets meer dan 4 seconden voltooid en de performance stats die we hebben opgevraagd laten een execution count zien van 1 voor de iTVF, zoals te zien is in de volgende afbeelding. Dit is een duidelijke verbetering van de prestaties vergeleken met onze eerdere voorbeelden met scalaire en MSTFV-pogingen.
Vergelijking van scalaire, MSTVF- en iTVF-prestaties
De volgende tabel geeft de vergelijking weer van de 3 UDF’s die we zojuist hebben uitgevoerd om te laten zien hoe ze presteerden in termen van uitvoeringstijd en aantal uitgevoerde opdrachten.
| Scalar | MSTVF | iTVF | |
| Uitvoeringstijd | > 5 minuten | > 5 minuten | 4 seconden |
| Telling uitvoering | > 10,000 | >10,000 | 1 |
Het verschil in uitvoeringstijd en aantal executies door het gebruik van de iTVF is direct duidelijk. In ons voorbeeld retourneerde de iTVF dezelfde gegevens sneller en met slechts 1 uitvoering. In omgevingen met een zware werklast of voor scenario’s waarin logica wordt gebruikt in meerdere rapporten die traag zijn door scalar of MSTVF gebruik, kan een verandering naar een iTVF helpen om ernstige prestatieproblemen te verlichten.
Beperkingen
iTVF’s komen echt in het spel wanneer je logica moet hergebruiken zonder dat dit ten koste gaat van de prestaties, maar ze zijn niet perfect. Ook zij hebben beperkingen.
Voor een lijst van beperkingen en restricties van door de gebruiker gedefinieerde functies in het algemeen kun je hier Books Online bezoeken. Buiten die lijst en specifiek voor inline tabel gewaardeerde functies, zijn de volgende algemene punten om over na te denken bij het evalueren of ze de juiste tool zijn voor een probleem dat je mogelijk hebt.
Een SELECT statement
Aangezien de definitie van een iTVF beperkt is tot 1 SELECT statement, zijn oplossingen die logica vereisen buiten dat 1 SELECT statement waar misschien variabelentoekenning, conditionele logica of tijdelijk tabelgebruik vereist is, waarschijnlijk niet geschikt om alleen in een iTVF te implementeren.
Foutafhandeling
Dit is een beperking die geldt voor alle door de gebruiker gedefinieerde functies, waarbij constructen zoals TRY CATCH niet zijn toegestaan.
Oproepen van opgeslagen procedures
U kunt geen opgeslagen procedures aanroepen vanuit de body van de iTVF, tenzij het een extended opgeslagen procedure is. Dit is gekoppeld aan een principe van het SQL Server UDF-ontwerp waarbij het de toestand van de database niet kan wijzigen, wat mogelijk wel zou kunnen als u een opgeslagen procedure zou gebruiken.
Conclusie
Dit artikel begon met de bedoeling om inline tabelgewaardeerde functies (iTVF’s) zoals ze nu in 2016 zijn, opnieuw te bekijken en de verscheidenheid aan manieren te laten zien waarop ze kunnen worden gebruikt.
iTVF’s hebben als belangrijk voordeel dat ze geen prestaties opofferen in tegenstelling tot andere soorten door de gebruiker gedefinieerde functies (UDF’s) en goede ontwikkelingspraktijken kunnen aanmoedigen met hun mogelijkheden voor hergebruik en inkapseling.
Met recente functies in SQL Server, eerst in SQL Server 2017 en in de aankomende SQL Server 2019, heeft de prestatie van ofwel scalaire en MSTVF’s wat extra hulp. Kijk voor meer details naar interleaved execution, dat een nauwkeurige cardinaliteitsschatting voor MSTVF’s lijkt te bieden in plaats van de vaste getallen of 1 of 100 en scalar UDF inlining. Met scalar UDF inlining ligt in 2019 de nadruk op het aanpakken van de prestatiezwakte van scalar UDF’s.
Voor uw oplossingen geldt dat u ze moet testen en zich bewust moet zijn van hun beperkingen. Wanneer ze goed worden gebruikt, zijn ze een van de betere hulpmiddelen die we in ons SQL-arsenaal kunnen hebben.
Dank voor het lezen.