Au cas où nous aurions oublié ou n’aurions jamais rencontré de fonctions en ligne à valeur de tableau, nous allons commencer par une explication rapide de ce qu’elles sont.
En reprenant la définition de ce qu’est une fonction définie par l’utilisateur (UDF) de Books Online, une fonction en ligne à valeur de tableau (iTVF) est une expression de tableau qui peut accepter des paramètres, effectuer une action et fournir comme valeur de retour, un tableau. La définition d’une iTVF est stockée en permanence comme un objet de base de données, comme le ferait une vue.
La syntaxe pour créer un iTVF à partir de Books Online (BOL) se trouve ici et est la suivante :
CREATE FUNCTION function_name ( parameter_data_type } ] ) RETURNS TABLE ] RETURN select_stmt
Le bout de code suivant est un exemple d’un iTVF.
CREATE OR ALTER FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN (SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Comments cWHERE c.UserId = @UserId AND c.CreationDate >= @CommentDateGROUP BY c.UserId);
Quelques points à mentionner dans le script ci-dessus.
DEFAULT VALUE () – Vous pouvez définir des valeurs par défaut pour les paramètres et dans notre exemple, @CommentDate a une valeur par défaut de 01 Jan 2006.
RETURNS TABLE – Renvoie une table virtuelle basée sur la définition de la fonction
SCHEMABINDING – Spécifie que la fonction est liée aux objets de la base de données qu’elle référence. Lorsque le schemabinding est spécifié, les objets de base ne peuvent pas être modifiés d’une manière qui affecterait la définition de la fonction. La définition de la fonction elle-même doit d’abord être modifiée ou abandonnée pour supprimer les dépendances à l’objet qui doit être modifié (à partir de BOL).
En regardant l’instruction SELECT dans l’exemple iTVF, elle est similaire à une requête que vous placeriez dans une vue, sauf pour le paramètre passé dans la clause WHERE. Il s’agit d’une différence essentielle.
Bien qu’un iTVF soit similaire à une vue en ce sens que la définition est stockée de façon permanente dans la base de données, en ayant la possibilité de passer des paramètres, nous avons non seulement un moyen d’encapsuler et de réutiliser la logique, mais aussi la flexibilité de pouvoir interroger des valeurs spécifiques que nous voudrions passer. Dans ce cas, nous pouvons imaginer une fonction en ligne à valeur de tableau comme une sorte de » vue paramétrée « .
Pourquoi utiliser une iTVF ?
Avant de se lancer dans l’examen de la façon dont nous utilisons les iTVF, il est important de considérer pourquoi nous les utiliserions. Les iTVF nous permettent de fournir des solutions à l’appui d’aspects tels que (mais pas seulement) :
- Développement modulaire
- Flexibilité
- Éviter les pénalités de performance
J’aborderai chacun de ces aspects un peu plus bas.
Développement modulaire
Les iTVF peuvent encourager les bonnes pratiques de développement, telles que le développement modulaire. Essentiellement, nous voulons nous assurer que notre code est » DRY » et ne pas répéter le code que nous avons produit précédemment chaque fois qu’il est nécessaire à un endroit différent.
En oubliant les cas où le développement modulaire est poussé au énième degré au détriment d’un code maintenable, les avantages de la réutilisation et de l’encapsulation du code avec les iTVF sont l’une des premières choses que nous remarquons.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Users u INNER JOIN dbo.Comments c ON u.Id = c.UserIdWHERE c.CreationDate >= @CommentDateGROUP BY u.Id, u.Reputation;GO
VS
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u CROSS APPLY .(u.Id, @CommentDate) c;GO
La requête utilisant l’iTVF est simple et lorsqu’elle est utilisée dans des requêtes plus compliquées, elle peut vraiment aider les efforts de développement en cachant la complexité sous-jacente. Dans les scénarios où nous devons modifier la logique de la fonction à des fins d’amélioration ou de débogage, nous pouvons apporter le changement à un objet, le tester et ce seul changement sera reflété dans les autres endroits où la fonction est appelée.
Si nous avions répété la logique à plusieurs endroits, il faudrait apporter le même changement plusieurs fois avec le risque d’erreurs, d’écarts ou d’autres mésaventures à chaque fois. Cela signifie effectivement que nous devons comprendre où nous réutilisons la logique dans les iTVF, afin de pouvoir tester que nous n’avons pas introduit ces fonctionnalités gênantes connues sous le nom de bugs.
Flexibilité
Lorsqu’il s’agit de flexibilité, l’idée d’utiliser la capacité des fonctions à passer des valeurs de paramètres et à être faciles à interagir. Comme nous le verrons avec des exemples plus tard, nous pouvons interagir avec l’iTFV comme si nous interrogions une table.
Si la logique était dans une procédure stockée par exemple, nous devrions probablement prendre les résultats dans une table temporaire et ensuite interroger la table temporaire pour interagir avec les données.
Si la logique était dans une vue, nous ne serions pas en mesure de passer un paramètre. Nos options incluraient l’interrogation de la vue, puis l’ajout d’une clause WHERE en dehors de la définition de la vue. Bien que ce ne soit pas un gros problème pour cette démo, dans les requêtes compliquées, la simplification avec un iTVF peut être une solution plus élégante.
Éviter les pénalités de performance
Pour la portée de cet article, je ne vais pas examiner les UDF du Common Language Runtime (CLR).
Là où nous commençons à voir une divergence entre les iTVF et les autres UDF, c’est la performance. On peut dire beaucoup de choses sur les performances, et pour la plupart, les autres UDFs souffrent beaucoup, en termes de performances. Une alternative pourrait être de les réécrire comme des iTVFs à la place, car les performances sont un peu différentes pour les iTFVs. Elles ne souffrent pas des mêmes pénalités de performance que celles qui affectent les fonctions scalaires ou les Multi Statement Table-Valued Functions (MSTVFs).
Les iTVFs, comme leur nom l’indique, sont inlined dans le plan d’exécution. Avec l’optimiseur qui désimbrique les éléments de requête de la définition et interagit avec les tables sous-jacentes (inlining), vous avez plus de chances d’obtenir un plan optimal, car l’optimiseur peut prendre en compte les statistiques des tables sous-jacentes et a à sa disposition d’autres optimisations comme le parallélisme, si cela est nécessaire.
Pour beaucoup de gens, les performances seules ont été une grande raison d’utiliser les iTVF à la place des fonctions scalaires ou MSTVF. Même si vous ne vous souciez pas encore des performances, les choses peuvent changer très rapidement avec des volumes plus importants ou des applications compliquées de votre logique ; il est donc important de comprendre les pièges des autres types d’UDF. Plus tard dans cet article, nous montrerons une comparaison de base des performances impliquant les iTVF et les autres types d’UDF.
Maintenant que nous avons énuméré quelques raisons d’utiliser les iTVF, allons-y et voyons comment nous pouvons les utiliser.
Mise en place de la démo iTVF
Dans cette démo, nous utiliserons la base de données StackOverflow2010, qui est disponible gratuitement auprès des charmantes personnes de StackOverflow via https://archive.org/details/stackexchange
Alternativement, vous pouvez obtenir la base de données via les autres charmantes personnes de Brent Ozar Unlimited ici : https://www.brentozar.com/archive/2015/10/how-to-download-the-stack-overflow-database-via-bittorrent/
J’ai restauré la base de données StackOverflow sur mon SQL Server 2016 Developer Edition local, dans un environnement isolé. Je vais exécuter une démo rapide sur ma version installée de SQL Server Management Studio (SSMS) v18.0 Preview 5. J’ai également défini le mode de compatibilité sur 2016 (130) et j’exécute la démo sur une machine dotée d’un processeur Intel i7 2,11 GHz et de 16 Go de RAM.
Une fois que vous êtes opérationnel avec la base de données StackOverflow, exécutez la T-SQL dans le fichier de ressources 00_iTFV_Setup.sql contenu dans cet article pour créer les iTVF que nous allons utiliser. La logique de ces iTVF est simple et peut être répétée à plusieurs endroits, mais ici nous l’écrirons une fois et l’offrirons à la réutilisation.
Utilisation d’une iTVF comme table virtuelle
Rappellez-vous que les iTVF ne sont persistées nulle part dans la base de données. Ce qui est persistant, c’est leur définition. Nous pouvons toujours interagir avec les iTVF comme si elles étaient des tables, donc à cet égard, nous les traitons comme des tables virtuelles.
Les 6 exemples suivants montrent comment nous pouvons traiter les iTVF comme des tables virtuelles. Avec la base de données StackOverflow opérationnelle sur votre ordinateur, n’hésitez pas à exécuter les 6 requêtes suivantes de la section 1 pour voir cela par vous-même. Vous pouvez également les trouver dans le fichier, 01_Demo_SSC_iTVF_Creating_Using.sql.
/**************************************************************************1. Using iTVFs in queries as if it were a table.**************************************************************************/DECLARE @UserId INT= 3, @CommentDate DATE= '2006-01-01T00:00:00.000';--1.1 Get specific columnsSELECT UserId, LatestCommentDateFROM dbo.itvfnGetRecentComment(3, '2006-01-01T00:00:00.000');--1.2 Get all columns SELECT *FROM dbo.itvfnGetRecentComment(@UserId, @CommentDate);--1.3 Use a default valueSELECT UserId, LatestCommentDate, TotalCommentsFROM dbo.itvfnGetRecentComment(@UserId, DEFAULT);--1.4 In the WHERE clauseSELECT u.DisplayName, u.Location, u.ReputationFROM dbo.Users uWHERE u.Reputation <=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(@UserId, DEFAULT));--1.5 In the HAVING clauseSELECT u.Location, SUM(u.Reputation) AS TotalRepFROM dbo.Users uGROUP BY u.LocationHAVING SUM(u.Reputation) >=( SELECT rc.TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT) rc);--1.6 In the SELECT clauseSELECT u.Location, CASE WHEN SUM(u.Reputation) >=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT)) THEN 'YES' ELSE 'NO' END AS InRepLimitFROM dbo.Users uGROUP BY u.Location;
Comme indiqué ci-dessus, lorsque nous interagissons avec les iTVF, nous pouvons :
- Retourner la liste complète des colonnes
- Retourner les colonnes spécifiées
- Utiliser les valeurs par défaut en passant le mot-clé, DEFAULT
- Passer le iTVF dans la clause WHERE
- utiliser le iTVF dans la clause HAVING
- utiliser le iTVF dans la clause SELECT
Pour mettre cela en perspective, typiquement avec une procédure stockée, on insère l’ensemble des résultats dans une table temporaire, puis on interagit avec la table temporaire pour faire ce qui précède. Avec un iTVF, il n’est pas nécessaire d’interagir avec d’autres objets en dehors de la définition de la fonction pour des cas similaires aux 6 que nous venons de voir.
Les iTVF dans les fonctions imbriquées
Bien que l’imbrication des fonctions puisse apporter ses propres problèmes si elle est mal faite, c’est quelque chose que nous pouvons faire dans un iTVF. Inversement, lorsqu’elle est utilisée de manière appropriée, elle peut être très utile pour cacher la complexité.
Dans notre exemple inventé, la fonction, dbo.itvfnGetRecentCommentByRep, renvoie le dernier commentaire d’un utilisateur, le total des commentaires, etc, ajoutant un filtre supplémentaire pour la réputation.
SELECT DisplayName, LatestCommentDate, ReputationFROM .(3, DEFAULT, DEFAULT);GO
Lorsque nous retournons la date du dernier commentaire, cela se fait via l’appel à l’autre fonction, dbo.itvfnGetRecentComment.
CREATE OR ALTER FUNCTION . (@UserId int, @Reputation int = 100, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN ( SELECT u.DisplayName, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) cWHERE u.Id = @UserId AND u.Reputation >= @Reputation);GO
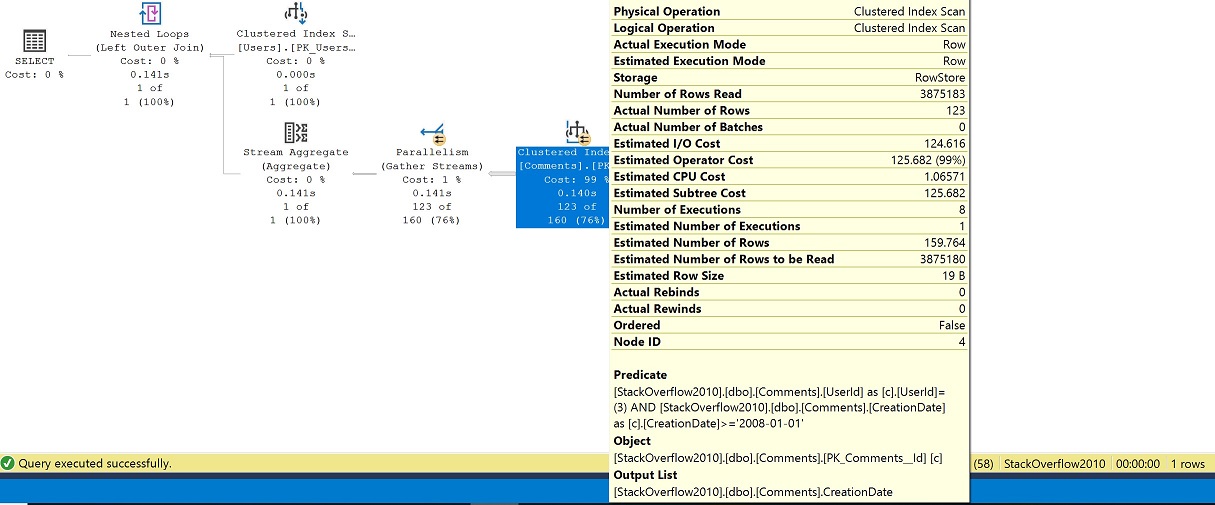
Dans l’exemple, nous pouvons voir que même avec l’imbrication des fonctions, la définition sous-jacente est inlined et les objets avec lesquels nous interagissons sont les index clusterisés, dbo.Users et dbo.Comments.
Dans le plan, sans un index décent pour supporter nos prédicats, un scan de l’index clusterisé de la table Comments est effectué, ainsi qu’un passage en parallèle où nous finissons par avoir un nombre d’exécutions égal à 8. Nous filtrons pour UserId 3 de la table Users donc nous obtenons une recherche sur la table Users et ensuite une jointure à la table Comments après le GROUP BY (agrégat de flux) pour la dernière date de commentaire.
Utilisation de l’opérateur APPLY
L’opérateur APPLY offre tellement d’utilisations créatives, et c’est certainement une option que nous pouvons appliquer (jeu de mots) pour interagir avec un iTVF. Pour en savoir plus sur l’opérateur APPLY, consultez les documents suivants : https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms175156(v=sql.105) et http://www.sqlservercentral.com/articles/Stairway+Series/121318/
Dans l’exemple suivant, nous voulons appeler l’iTVF pour tous les utilisateurs et retourner leur LatestCommentDate, Total Comments, Id et Reputation depuis le 01 Jan 2008. Pour ce faire, nous utilisons l’opérateur APPLY, où exécuter pour chaque ligne de la table Users entière, en passant l’Id de la table Users et le CommentDate. Ce faisant, nous conservons les avantages d’encapsulation de l’utilisation de l’iTVF, en appliquant notre logique à toutes les lignes de la table Users.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Les iTVF dans les JOIN
Similairement à la jointure de 2 ou plusieurs tables, nous pouvons impliquer les iTVF dans les jointures avec d’autres tables. Ici, nous voulons le DisplayName de la table Utilisateurs et l’UserId, BadgeName et BadgeDate de l’iTVF, pour les utilisateurs qui ont obtenu le badge de ‘Student’ le ou après le 01 Jan 2008.
DECLARE @BadgeName varchar(40)= 'Student', @BadgeDate datetime= '2008-01-01T00:00:00.000';SELECT u.DisplayName, b.UserId, b.BadgeName, b.BadgeDateFROM dbo.Users u INNER JOIN .(@BadgeName, @BadgeDate) b ON b.UserId = u.Id;GO
Alternative aux autres UDF
Plus tôt dans cet article, nous avons mentionné qu’une raison d’utiliser les iTVF était d’éviter les pénalités de performance dont souffrent d’autres types d’UDF tels que les scalaires et les MSTVF. Cette section va démontrer comment nous pouvons remplacer les scalaires et les MSTVFs par des iTVFs et la partie suivante examinera pourquoi nous pouvons choisir de le faire.
Alternative d’UDF scalaire
Avant de poursuivre, exécutons la requête suivante pour créer l’UDF scalaire, dbo.sfnGetRecentComment que nous utiliserons prochainement.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS datetimeWITH SCHEMABINDING, RETURNS NULL ON NULL INPUTASBEGIN DECLARE @LatestCreationDate datetime; SELECT @LatestCreationDate = MAX(CreationDate) FROM dbo.Comments WHERE UserId = @UserId AND CreationDate >= @CommentDate GROUP BY UserId; RETURN @LatestCreationDate;END;GO
Après avoir créé la fonction scalaire, exécutez la requête suivante. Ici, nous voulons utiliser la utiliser la logique encapsulée dans la fonction scalaire pour interroger l’ensemble de la table Users et retourner l’Id et la dernière date de commentaire de chaque utilisateur depuis le 01 Jan 2008. Nous faisons cela en ajoutant la fonction dans la clause SELECT où, pour les valeurs des paramètres, nous passerons l’Id de la table Users et la date du commentaire que nous venons de fixer au 01 Jan 2008.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Une requête similaire peut être écrite en utilisant un iTVF, ce qui est montré dans la requête suivante. Ici, nous voulons obtenir l’Id et la dernière date de commentaire depuis le 01 janvier 2008 en utilisant l’iTVF et nous y parvenons en utilisant l’opérateur APPLY contre toutes les lignes de la table Users. Pour chaque ligne, nous passons l’Id de l’utilisateur et la date du commentaire.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Alternative MSTVF
Exécutez la requête suivante pour créer le MSTVF dbo.mstvfnGetRecentComment, que nous utiliserons prochainement.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS @RecentComment TABLE( int NULL, date NULL, int NULL)WITH SCHEMABINDING ASBEGIN INSERT INTO @RecentComment SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalComments FROM dbo.Comments c WHERE c.UserId = @UserId AND c.CreationDate >= @CommentDate GROUP BY c.UserId; RETURN;END;GO
Maintenant que nous avons créé le MSTVF, nous allons l’utiliser pour retourner la dernière date de commentaire pour toutes les lignes de la table Utilisateurs depuis le 01 janvier 2008. Comme l’exemple d’iTVF avec l’opérateur APPLY dans la partie précédente de cet article, nous allons » appliquer » notre fonction à toutes les lignes de la table Users en utilisant l’opérateur APPLY et en passant l’Id de l’utilisateur pour chaque ligne, ainsi que la date de commentaire que nous avons définie.
DECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Lorsque nous remplaçons le MSTVF de notre exemple par un iTVF, le résultat est très similaire, sauf pour le nom de la fonction appelée. Dans notre cas, nous allons l’appelervfnGetRecentComment à la place de la MSTVF dans l’exemple précédent, en conservant les colonnes dans la clause SELECT. Cela nous permet d’obtenir l’identifiant et la date du dernier commentaire depuis le 1er janvier 2008 en utilisant l’iTVF pour toutes les lignes de la table Users. Ceci est illustré dans la requête qui suit.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Une préférence pour les iTVF
Une raison de choisir une iTVF plutôt qu’une fonction scalaire ou une MSTVF est la performance.
Nous allons brièvement capturer les performances des 3 fonctions sur la base des requêtes d’exemple que nous avons exécutées dans la section précédente et ne pas entrer dans les détails, si ce n’est pour comparer les performances à travers des métriques telles que le temps d’exécution et le nombre d’exécutions pour les fonctions. Le code pour les statistiques de performance que nous utiliserons tout au long de cette démo, provient du Listing 9.3 dans les échantillons de code de la 3e édition de SQL Server Execution Plans par Grant Fritchey https://www.red-gate.com/simple-talk/books/sql-server-execution-plans-third-edition-by-grant-fritchey/
Performances scalaires
Voici la requête précédente que nous avons exécutée en invoquant la fonction scalaire.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Il est bien connu que les fonctions scalaires inhibent le parallélisme et qu’une instruction avec une fonction scalaire est invoquée une fois pour chaque ligne. Si votre tableau comporte 10 rangs, il se peut que tout aille bien. Quelques milliers de lignes, et vous serez surpris (ou non) par la chute drastique des performances. Voyons cela en action en exécutant l’extrait de code suivant.
Ce que nous voulons faire d’abord, c’est vider (dans un environnement isolé) le cache de SQL Server et le plan existant qui pourrait être réutilisé(FREEPROCCACHE), en s’assurant que nous obtenons d’abord les données du disque (DROPPCLEANBUFFERS) pour commencer avec un cache froid. Librement parlant, nous partons d’une ardoise propre en faisant cela.
Après cela, nous exécutons la requête SELECT sur la table Users où nous retournons l’Id et le LatestCommentDate en utilisant la fonction scalaire. Comme valeurs de paramètre, nous passerons l’Id de la table Users et la date du commentaire que nous venons de définir au 01 Jan 2008. En voici un exemple.
-- run in an isolated environmentCHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Bien que la requête SELECT où nous utilisons la fonction scalaire puisse paraître simple dans sa structure, après 4 minutes sur ma machine, elle s’exécutait toujours.
Rappellez-vous que pour les fonctions scalaires, elles s’exécutent une fois pour chaque ligne. Le problème avec cela est que les opérations ligne par ligne sont très rarement le moyen le plus efficace de récupérer des données dans SQL Server par rapport aux opérations basées sur un seul ensemble.
Pour observer les exécutions répétées, nous pouvons exécuter une requête pour certaines statistiques de performance. Celles-ci sont collectées par SQL Server lorsque nous exécutons nos requêtes et ici, nous voulons obtenir l’énoncé de la requête, le temps de création, le compte d’exécution de l’énoncé ainsi que le plan de requête. La requête suivante est un exemple de la façon dont nous pouvons obtenir les statistiques de performance.
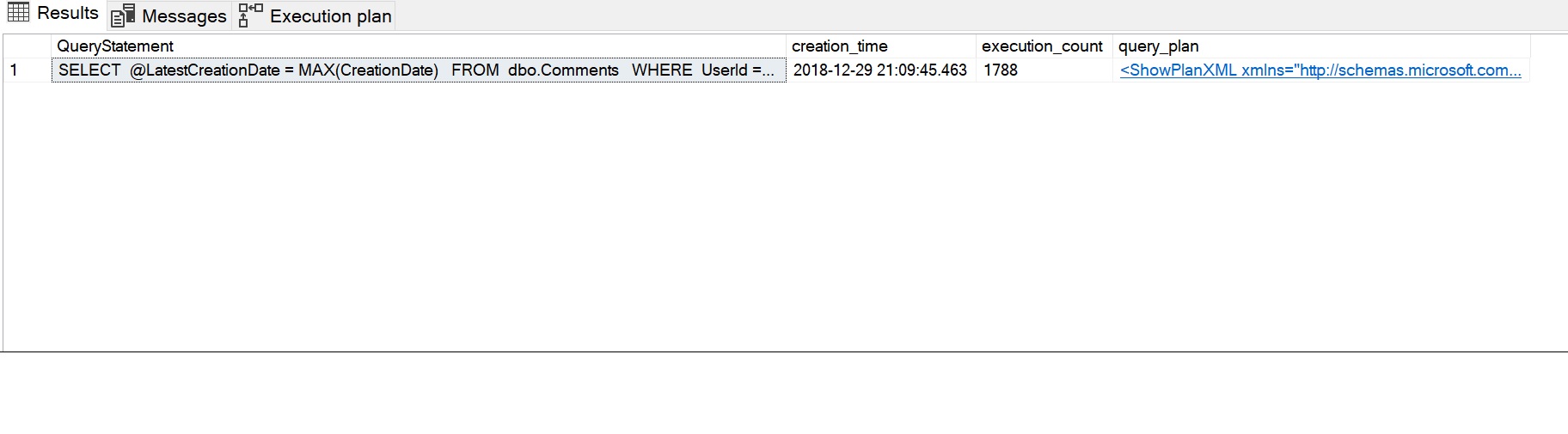
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.sfnGetRecentComment')ORDER BY deqs.last_execution_time DESC;GO
L’exécution résultante des statistiques de performance peut être vue dans l’image suivante. L’instruction de requête montre l’instruction SELECT utilisée par la fonction scalaire, le compte d’exécution de 1788 a capturé le compte d’exécution répété (une fois pour chaque ligne) et le plan qui est utilisé par la fonction peut être visualisé en cliquant sur le message XML du plan de requête.
Un moyen supplémentaire de voir les métriques de performance importantes est d’utiliser les événements étendus. Pour en savoir plus sur les événements étendus, cliquez ici mais pour les besoins de notre démonstration, exécutez la requête suivante pour créer une session d’événements étendus.
CREATE EVENT SESSION QuerySession ON SERVER ADD EVENT sqlserver.module_end( WHERE (.(.,(??)))), -- enter your Session Id ADD EVENT sqlserver.sp_statement_completed( WHERE (.(.,(??)))),-- enter your Session Id ADD EVENT sqlserver.sql_batch_completed( WHERE (.(.,(??)))); -- enter your Session IdGOALTER EVENT SESSION QuerySession ON SERVER STATE = START;GO
Une fois que la session d’événements étendus a été créée, allez dans Gestion dans l’Explorateur d’objets, développez les sessions et ouvrez le menu contextuel de « QuerySession » que nous venons de créer. Sélectionnez « Watch live data ».
Dans la fenêtre nouvellement ouverte, observez les multiples lignes d’instruction de la fonction scalaire comme preuve des exécutions répétées.
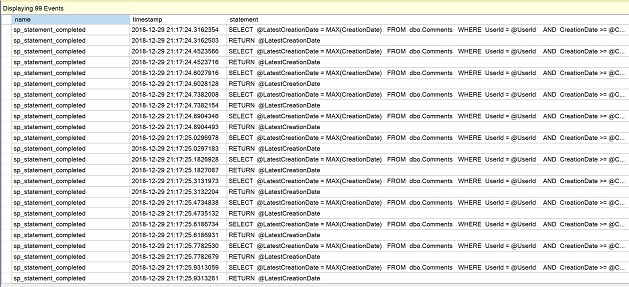
Cliquez sur le carré rouge pour « Arrêter le flux de données » pour le moment.
Performances des MSTVF
Pour les MSTVF, il peut également y avoir des pénalités de performance suite à leur utilisation et cela est lié au fait que SQL Server choisit des plans d’exécution non optimaux en raison de statistiques imprécises. SQL Server s’appuie sur des statistiques capturées en interne pour comprendre combien de lignes de données une requête va renvoyer afin de produire un plan optimal. Ce processus de est connu sous le nom d’estimation de cardinalité.
Avant SQL Server 2014, l’estimation de cardinalité pour les variables de table était définie à 1 ligne. À partir de SQL Server 2014, elle est fixée à 100 lignes, que l’on effectue une requête contre 100 lignes ou 1 million de lignes. Les MSTVF renvoient des données via des variables de table qui sont déclarées au début de la définition de la fonction. En réalité, l’optimiseur ne cherchera pas toujours le meilleur plan qu’il puisse trouver, quel que soit le temps, et il doit maintenir un équilibre à ce niveau (en termes très simples). Avec les MSTVF, l’absence de statistiques précises (causée par une estimation imprécise de la cardinalité des variables de la table dans leur définition) peut inhiber les performances en faisant produire à l’optimiseur des plans sous-optimaux.
En pratique, le remplacement des MSTVF par des iTVF peut apporter de meilleures performances car les iTVF utiliseront les statistiques des tables sous-jacentes.
Le bout de code suivant utilise l’opérateur APPLY pour exécuter la MSTVF contre la table Users entière. Nous retournons l’Id de la table Users et la LatestCommentDate de la fonction pour chaque ligne de la table Users, en passant l’Id de l’utilisateur et la date du commentaire qui est fixée au 01 Jan 2008. Comme pour l’exécution de la fonction scalaire, nous allons procéder à partir d’un cache froid. Avec ce test, ayez également le plan d’exécution réel sélectionné dans SSMS, en cliquant sur Ctrl + M. Exécutez la requête.
CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
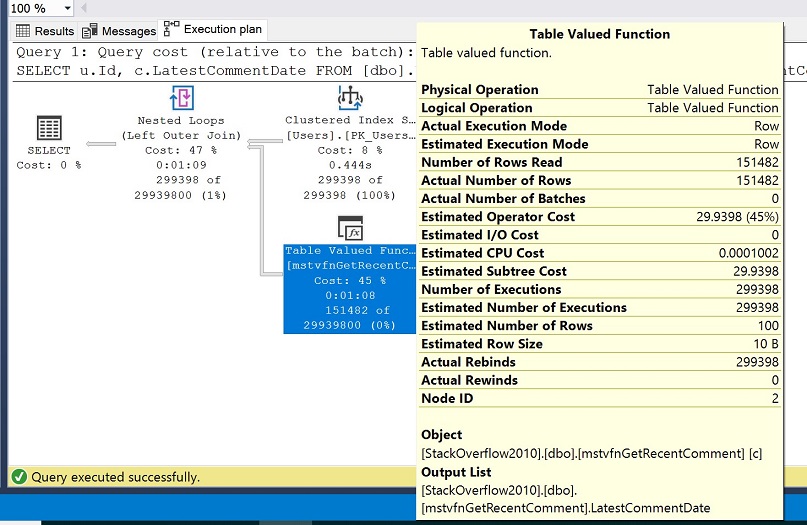
Le plan d’exécution résultant est montré dans l’image suivante et dans la boîte de propriétés jaune, remarquez les valeurs pour le nombre estimé de lignes vs le nombre réel de lignes.
Vous devriez voir que le nombre estimé de lignes de la fonction de valeur de la table est fixé à 100 mais que le nombre réel de lignes est fixé à 151 482. Rappelez-vous que dans notre mise en place, nous avons choisi le mode de compatibilité SQL Server 2016 (130) et qu’à partir de SQL Server 2014, l’estimation de la cardinalité est fixée à 100 pour les variables de table.
Des valeurs aussi follement différentes pour le nombre de lignes estimé par rapport au nombre réel de lignes nuisent généralement aux performances et peuvent nous empêcher d’obtenir des plans plus optimaux et, au final, des requêtes plus performantes.
Similairement à la fonction scalaire que nous avons exécutée précédemment, nous allons exécuter une requête par rapport aux statistiques de performance de SQL Server. Ici, nous voulons également obtenir l’instruction de la requête, l’heure de création, le compte d’exécution de l’instruction et le plan de requête utilisé et filtrer pour la MSTVF dans la clause WHERE.
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs OUTER APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp OUTER APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.mstvfnGetRecentComment');
Le plan d’exécution que nous avons initialement observé pour la MSTVF est trompeur car il ne reflète pas le travail réel effectué par la fonction. En utilisant les statistiques de performance que nous venons d’exécuter et en sélectionnant le Showplan XML, nous devrions voir un plan de requête différent qui montre le travail effectué par la MSTVF. Voici un exemple de plan différent de celui que nous avons vu initialement. Ici, nous pouvons maintenant voir que le MSTVF insère des données dans une variable de table appelée @RecentComment. Les données de la variable de table @RecentComment sont ce qui est ensuite renvoyé par le MSTVF pour renvoyer la dernière date de commentaire.
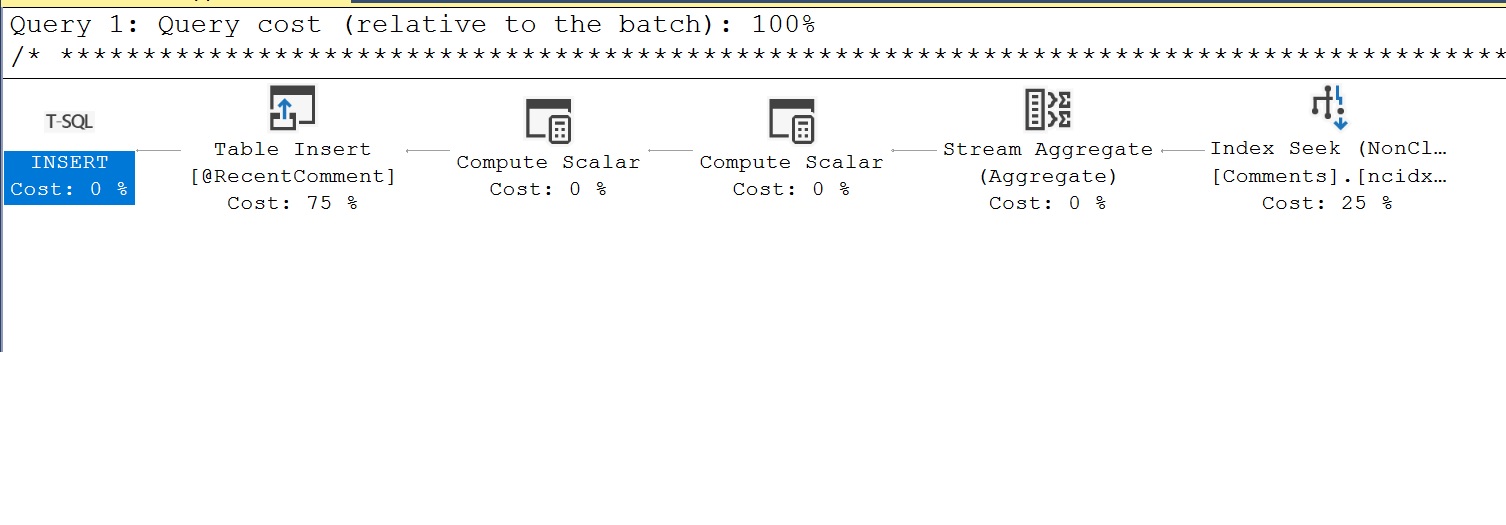
Un autre aspect des mesures de performance que nous avons capturé est le compte d’exécution. Ici, nous voulons nous méfier du nombre d’exécutions multiples, car celles-ci sont généralement mauvaises pour les performances, comme mentionné lors de l’examen des performances scalaires.
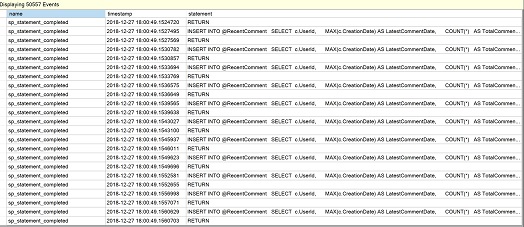
Ce que nous voyons dans l’image suivante pour le nombre d’exécutions, c’est une valeur de 76 qui est la preuve de plusieurs exécutions de notre MSTVF.

Retournons dans Gestion dans l’Explorateur d’objets, développez les sessions et Sélectionnez « Watch live data » pour la session « QuerySessions » que nous avons créée plus tôt lorsque nous avons regardé les performances scalaires. Cliquez sur le triangle vert « Start data feed » dans SSMS si la session a été arrêtée précédemment et nous devrions voir pour notre exemple, plusieurs lignes d’instruction du MSTVF qui représentent les exécutions répétées de l’instruction.
N’hésitez pas à annuler la requête à ce stade si elle n’est pas encore terminée.
Performances de l’iTVF
Lorsque nous remplaçons soit les fonctions scalaires, soit les fonctions à instructions multiples par une iTVF, nous voulons le faire pour éviter les pénalités de performance que nous venons de voir, par exemple le temps d’exécution, les exécutions multiples. En utilisant l’exemple précédent, nous allons interroger la table Users pour obtenir l’Id et la date du dernier commentaire de l’iTVF depuis le 1er janvier 2008, en utilisant l’opérateur APPLY. Nous le ferons également à partir d’un cache froid en vidant le cache du serveur SQL et en obtenant les données à partir du disque pour commencer.
--run in an isolated environment CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
La requête suivante se compose des statistiques de performance qui nous aident à voir l’instruction qui est exécutée, le compte d’exécution et le plan de requête pour cette instruction.
-- Query stats and execution planSELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.dbid = DB_ID('StackOverflow2010')ORDER BY deqs.last_execution_time DESC;
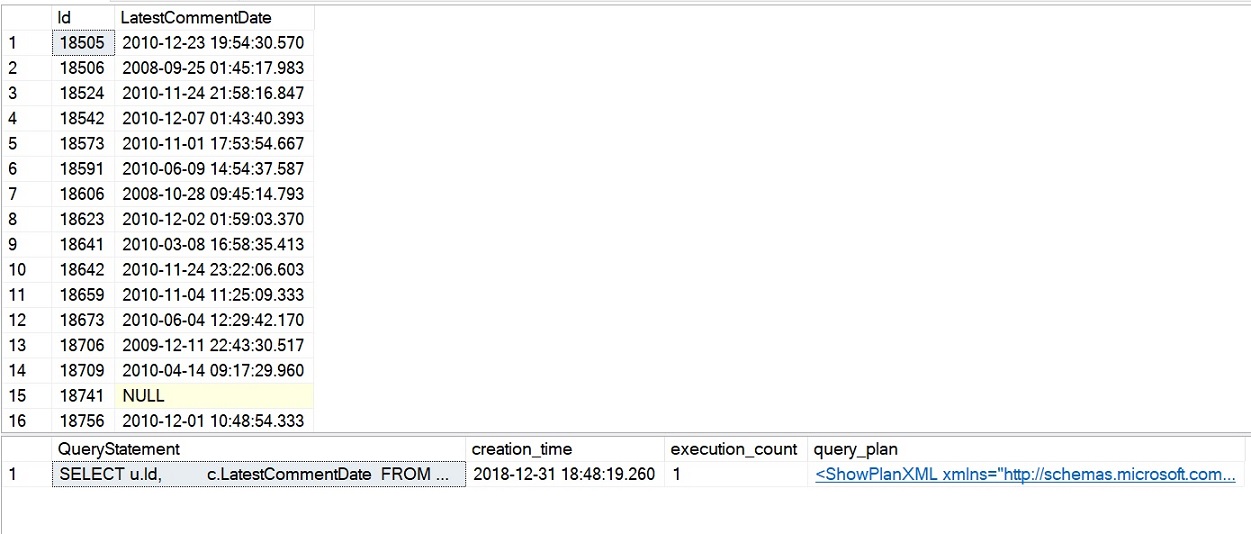
La requête d’exemple pour l’iTVF que nous venons d’exécuter s’est terminée en un peu plus de 4 secondes et les statistiques de performance que nous avons interrogées devraient montrer un compte d’exécution de 1 pour l’iTVF comme le montre l’image suivante. Il s’agit d’une nette amélioration des performances par rapport à nos exemples précédents avec des tentatives scalaires et MSTFV.
Comparaison des performances scalaires, MSTVF et iTVF
Le tableau suivant capture la comparaison des 3 UDF que nous venons d’exécuter pour montrer leurs performances en termes de temps d’exécution et de compte d’exécution.
| Scalaire | MSTVF | iTVF | |
| Temps d’exécution |
.>
5 minutes |
> 5 minutes | 4 secondes |
| Compte des exécutions | > 10,000 | > 10 000 | 1 |
La différence de temps d’exécution et de nombre d’exécutions en utilisant l’iTVF est immédiatement apparente. Dans notre exemple, l’iTVF a renvoyé les mêmes données plus rapidement et avec seulement 1 exécution. Dans les environnements où il y a de lourdes charges de travail ou pour les scénarios où la logique est utilisée dans plusieurs rapports qui sont lents en raison de l’utilisation de scalaires ou de MSTVF, un changement vers un iTVF peut aider à atténuer les graves problèmes de performance.
Limitations
Les iTVF entrent vraiment en jeu lorsque vous devez réutiliser la logique sans sacrifier les performances, mais ils ne sont pas parfaits. Elles ont aussi des limitations.
Pour une liste des limitations et restrictions des fonctions définies par l’utilisateur en général, vous pouvez visiter Books Online ici. En dehors de cette liste et spécifiquement pour les fonctions valorisées par une table en ligne, voici des points généraux à méditer pour évaluer si elles sont le bon outil pour un problème que vous pouvez avoir.
Single SELECT statement
Comme la définition d’une iTVF est limitée à 1 SELECT statement, les solutions qui nécessitent une logique au-delà de ce 1 SELECT statement où peut-être une affectation de variable, une logique conditionnelle ou une utilisation de table temporaire est nécessaire, ne sont probablement pas adaptées à une mise en œuvre dans une iTVF seule.
Gestion des erreurs
C’est une restriction qui affecte toutes les fonctions définies par l’utilisateur où des constructions telles que TRY CATCH ne sont pas autorisées.
Appeler des procédures stockées
Vous ne pouvez pas appeler des procédures stockées à partir du corps de l’iTVF à moins qu’il ne s’agisse d’une procédure stockée étendue. Ceci est lié à un principe de conception de l’UDF de SQL Server où il ne peut pas modifier l’état de la base de données, ce qui, si vous utilisiez une procédure stockée, vous pourriez éventuellement le faire.
Conclusion
Cet article a commencé avec l’intention de revisiter les fonctions en ligne à valeur de table (iTVF) telles qu’elles sont actuellement en 2016, en montrant la variété des façons dont elles peuvent être utilisées.
Les iTVF ont un avantage clé en ce qu’elles ne sacrifient pas les performances contrairement à d’autres types de fonctions définies par l’utilisateur (UDF) et peuvent encourager les bonnes pratiques de développement grâce à leurs capacités de réutilisation et d’encapsulation.
Avec les récentes fonctionnalités de SQL Server, tout d’abord dans SQL Server 2017 et dans le prochain SQL Server 2019, les performances de l’une ou l’autre des fonctions scalaires et MSTVF ont une aide supplémentaire. Pour plus de détails, consultez l’exécution entrelacée qui cherche à fournir une estimation précise de la cardinalité pour les MSTVF plutôt que les nombres fixes ou 1 ou 100 et l’inlining UDF scalaire. Avec scalar UDF inlining en 2019, l’accent est mis sur la résolution de la faiblesse des performances des UDF scalaires.
Pour vos solutions, assurez-vous de tester et d’être conscient de leurs limites. Lorsqu’ils sont bien utilisés, ils constituent l’un des meilleurs outils que nous pourrions avoir dans notre arsenal SQL.
Merci de votre lecture.