Na wypadek, gdybyśmy zapomnieli lub nigdy wcześniej nie zetknęli się z funkcjami inline table-valued, zaczniemy od szybkiego wyjaśnienia, czym one są.
Przywołując definicję funkcji zdefiniowanej przez użytkownika (UDF) z Books Online, inline table-valued function (iTVF) jest wyrażeniem tabelarycznym, które może przyjąć parametry, wykonać akcję i dostarczyć jako wartość zwrotną, tabelę. Definicja iTVF jest trwale przechowywana jako obiekt bazy danych, podobnie jak w przypadku widoku.
Składnia do tworzenia iTVF z Books Online (BOL) znajduje się tutaj i jest następująca:
CREATE FUNCTION function_name ( parameter_data_type } ] ) RETURNS TABLE ] RETURN select_stmt
Poniższy fragment kodu jest przykładem iTVF.
CREATE OR ALTER FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN (SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Comments cWHERE c.UserId = @UserId AND c.CreationDate >= @CommentDateGROUP BY c.UserId);
Kilka rzeczy, o których warto wspomnieć w powyższym skrypcie.
DEFAULT VALUE () – Można ustawić wartości domyślne dla parametrów i w naszym przykładzie @CommentDate ma wartość domyślną 01 Jan 2006.
RETURNS TABLE – Zwraca wirtualną tabelę na podstawie definicji funkcji
SCHEMABINDING – Określa, że funkcja jest związana z obiektami bazy danych, do których się odwołuje. Gdy określone jest powiązanie ze schematem, obiekty bazodanowe nie mogą być modyfikowane w sposób, który wpłynąłby na definicję funkcji. Sama definicja funkcji musi zostać najpierw zmodyfikowana lub usunięta, aby usunąć zależności od obiektu, który ma zostać zmodyfikowany (z BOL).
Patrząc na instrukcję SELECT w przykładzie iTVF, jest ona podobna do zapytania, które umieścilibyśmy w widoku, z wyjątkiem parametru przekazanego do klauzuli WHERE. Jest to krytyczna różnica.
Ale iTVF jest podobny do widoku w tym sensie, że jego definicja jest przechowywana na stałe w bazie danych, dzięki możliwości przekazywania parametrów mamy nie tylko sposób na enkapsulację i ponowne wykorzystanie logiki, ale także elastyczność w możliwości zapytania o konkretne wartości, które chcielibyśmy przekazać. W tym przypadku, możemy sobie wyobrazić funkcję inline table-valued jako rodzaj „sparametryzowanego widoku”.
Dlaczego warto używać iTVF?
Zanim zaczniemy się zastanawiać jak używać iTVF, ważne jest aby rozważyć dlaczego ich używamy. ITVF pozwalają nam dostarczać rozwiązania wspierające takie aspekty, jak (ale nie tylko):
- Rozwój modułowy
- Elastyczność
- Unikanie kar za wydajność
Poniżej omówię każdy z tych aspektów.
Rozwój modułowy
iTVF mogą zachęcać do dobrych praktyk rozwojowych, takich jak rozwój modułowy. Zasadniczo, chcemy mieć pewność, że nasz kod jest „DRY” i nie powtarzać kodu, który wcześniej stworzyliśmy za każdym razem, gdy jest on potrzebny w innym miejscu.
Pomijając przypadki, w których rozwój modularny jest posunięty do n-tego stopnia kosztem kodu możliwego do utrzymania, korzyści z ponownego użycia kodu i enkapsulacji z iTVF są jedną z pierwszych rzeczy, które zauważamy.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Users u INNER JOIN dbo.Comments c ON u.Id = c.UserIdWHERE c.CreationDate >= @CommentDateGROUP BY u.Id, u.Reputation;GO
VS
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u CROSS APPLY .(u.Id, @CommentDate) c;GO
Kwerenda wykorzystująca iTVF jest prosta, a gdy jest używana w bardziej skomplikowanych zapytaniach, może naprawdę pomóc w rozwoju poprzez ukrycie złożoności. W scenariuszach, w których musimy zmienić logikę w funkcji w celu ulepszenia lub debugowania, możemy dokonać zmiany w jednym obiekcie, przetestować go i ta jedna zmiana zostanie odzwierciedlona w innych miejscach, w których funkcja jest wywoływana.
Gdybyśmy powtórzyli logikę w wielu miejscach, musiałbyś dokonać tej samej zmiany wiele razy z ryzykiem błędów, odchyleń lub innych niepowodzeń za każdym razem. Oznacza to, że musimy zrozumieć, gdzie ponownie używamy logiki w iTVF, abyśmy mogli przetestować, czy nie wprowadziliśmy tych kłopotliwych cech znanych jako bugi.
Elastyczność
Jeśli chodzi o elastyczność, ideą jest wykorzystanie zdolności funkcji do przekazywania wartości parametrów i łatwości interakcji z nimi. Jak zobaczymy na przykładach później, możemy wchodzić w interakcję z iTFV tak, jakbyśmy odpytywali tabelę.
Gdyby logika znajdowała się na przykład w procedurze składowanej, prawdopodobnie musielibyśmy przenieść wyniki do tabeli tymczasowej, a następnie odpytywać tabelę tymczasową, aby wejść w interakcję z danymi.
Gdyby logika znajdowała się w widoku, nie moglibyśmy przekazać parametru. Nasze opcje obejmowałyby zapytanie do widoku, a następnie dodanie klauzuli WHERE poza definicją widoku. W tym demo nie ma to większego znaczenia, jednak w przypadku skomplikowanych zapytań, uproszczenie za pomocą iTVF może być bardziej eleganckim rozwiązaniem.
Unikanie kar za wydajność
W tym artykule nie będę się zajmował UDF-ami typu CLR (Common Language Runtime).
W punkcie, w którym zaczynamy dostrzegać rozbieżności pomiędzy iTVF-ami a innymi UDF-ami, jest wydajność. Wiele można powiedzieć o wydajności, a w przeważającej części inne UDF-y bardzo cierpią z powodu wydajności. Alternatywą może być przepisanie ich jako iTVF, ponieważ wydajność jest nieco inna w przypadku iTFV. Nie cierpią one z powodu tych samych kar wydajności, które wpływają na skalarne lub wielostanowiskowe funkcje tabelaryczne (MSTVF).
iTVFs, jak ich nazwa wskazuje, są inlined w planie wykonania. Dzięki temu, że optymalizator nie zagnieżdża elementów definicji zapytania i wchodzi w interakcję z bazowymi tabelami (inlining), masz większe szanse na uzyskanie optymalnego planu, ponieważ optymalizator może wziąć pod uwagę statystyki bazowych tabel i ma do dyspozycji inne optymalizacje, takie jak równoległość, jeśli jest to wymagane.
Dla wielu osób, wydajność sama w sobie jest dużym powodem do używania iTVF zamiast skalarnych lub MSTVF. Nawet jeśli nie zależy nam na wydajności, sytuacja może się zmienić bardzo szybko przy większych wolumenach lub skomplikowanych zastosowaniach logiki, więc zrozumienie pułapek związanych z innymi typami UDF jest ważne. W dalszej części artykułu pokażemy podstawowe porównanie wydajności iTVF i innych typów UDF.
Jak już wymieniliśmy powody, dla których warto używać iTVF, zobaczmy jak możemy je wykorzystać.
Skonfiguruj demo iTVF
W tym demo użyjemy bazy danych StackOverflow2010, która jest dostępna za darmo od uroczych ludzi ze StackOverflow poprzez https://archive.org/details/stackexchange
Alternatywnie, możesz zdobyć bazę danych poprzez innych uroczych ludzi z Brent Ozar Unlimited tutaj : https://www.brentozar.com/archive/2015/10/how-to-download-the-stack-overflow-database-via-bittorrent/
Przywróciłem bazę danych StackOverflow na moim lokalnym SQL Server 2016 Developer Edition, w izolowanym środowisku. Przeprowadzę szybkie demo na mojej zainstalowanej wersji SQL Server Management Studio (SSMS) v18.0 Preview 5. Ustawiłem również tryb zgodności na 2016 (130) i uruchamiam demo na maszynie z procesorem Intel i7 2.11 GHz i 16 GB pamięci RAM.
Po uruchomieniu bazy danych StackOverflow, uruchom T-SQL w pliku 00_iTFV_Setup.sql zawartym w tym artykule, aby utworzyć iTVFs, których będziemy używać. Logika w tych iTVF jest prosta i może być powtarzana w wielu miejscach, ale tutaj napiszemy ją raz i zaoferujemy do ponownego użycia.
Używanie iTVF jako tabeli wirtualnej
Pamiętaj, że iTVF nie są przechowywane w bazie danych. To, co jest przechowywane, to ich definicja. Wciąż możemy oddziaływać z iTVF tak jakby były tabelami, więc pod tym względem traktujemy je jak wirtualne tabele.
Następujące 6 przykładów pokazuje jak możemy traktować iTVF jako wirtualne tabele. Mając bazę danych StackOverflow uruchomioną na swoim komputerze, możesz uruchomić 6 poniższych zapytań z sekcji 1, aby przekonać się o tym na własnej skórze. Możesz je również znaleźć w pliku 01_Demo_SSC_iTVF_Creating_Using.sql.
/**************************************************************************1. Using iTVFs in queries as if it were a table.**************************************************************************/DECLARE @UserId INT= 3, @CommentDate DATE= '2006-01-01T00:00:00.000';--1.1 Get specific columnsSELECT UserId, LatestCommentDateFROM dbo.itvfnGetRecentComment(3, '2006-01-01T00:00:00.000');--1.2 Get all columns SELECT *FROM dbo.itvfnGetRecentComment(@UserId, @CommentDate);--1.3 Use a default valueSELECT UserId, LatestCommentDate, TotalCommentsFROM dbo.itvfnGetRecentComment(@UserId, DEFAULT);--1.4 In the WHERE clauseSELECT u.DisplayName, u.Location, u.ReputationFROM dbo.Users uWHERE u.Reputation <=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(@UserId, DEFAULT));--1.5 In the HAVING clauseSELECT u.Location, SUM(u.Reputation) AS TotalRepFROM dbo.Users uGROUP BY u.LocationHAVING SUM(u.Reputation) >=( SELECT rc.TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT) rc);--1.6 In the SELECT clauseSELECT u.Location, CASE WHEN SUM(u.Reputation) >=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT)) THEN 'YES' ELSE 'NO' END AS InRepLimitFROM dbo.Users uGROUP BY u.Location;
Jak pokazano powyżej, kiedy wchodzimy w interakcję z iTVF, możemy:
- Przywrócić pełną listę kolumn
- Przywrócić określone kolumny
- Użyć wartości domyślnych przekazując słowo kluczowe, DEFAULT
- Przekaż iTVF w klauzuli WHERE
- Użyj iTVF w klauzuli HAVING
- Użyj iTVF w klauzuli SELECT
Aby przedstawić to w perspektywie, Zazwyczaj w przypadku procedury przechowywanej, wstawiamy zestaw wyników do tabeli tymczasowej, a następnie wchodzimy w interakcję z tabelą tymczasową, aby wykonać powyższe czynności. W przypadku iTVF, nie ma wymogu interakcji z innymi obiektami poza definicją funkcji w przypadkach podobnych do 6, które właśnie widzieliśmy.
iTVF w zagnieżdżonych funkcjach
Ale zagnieżdżanie funkcji może powodować własne problemy, jeśli jest źle wykonane, jest to coś, co możemy zrobić w iTVF. W naszym wymyślonym przykładzie, funkcja dbo.itvfnGetRecentCommentByRep, zwraca ostatni komentarz użytkownika, całkowitą liczbę komentarzy itd, dodając dodatkowy filtr dla reputacji.
SELECT DisplayName, LatestCommentDate, ReputationFROM .(3, DEFAULT, DEFAULT);GO
Gdy zwracamy datę ostatniego komentarza, dzieje się to poprzez wywołanie innej funkcji, dbo.itvfnGetRecentComment.
CREATE OR ALTER FUNCTION . (@UserId int, @Reputation int = 100, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN ( SELECT u.DisplayName, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) cWHERE u.Id = @UserId AND u.Reputation >= @Reputation);GO
W przykładzie widzimy, że nawet przy zagnieżdżaniu funkcji, bazowa definicja zostaje zinlinedowana, a obiekty, z którymi wchodzimy w interakcję to klastrowe indeksy, dbo.Users i dbo.Comments.
W planie, bez przyzwoitego indeksu do obsługi naszych predykatów, wykonywane jest skanowanie klastrowego indeksu tabeli Comments, jak również przechodzenie równoległe, gdzie kończymy liczbę wykonań na 8. Filtrujemy dla UserId 3 z tabeli Users, więc uzyskujemy wyszukiwanie w tabeli Users, a następnie dołączamy do tabeli Comments po GROUP BY (agregat strumienia) dla najnowszej daty komentarza.
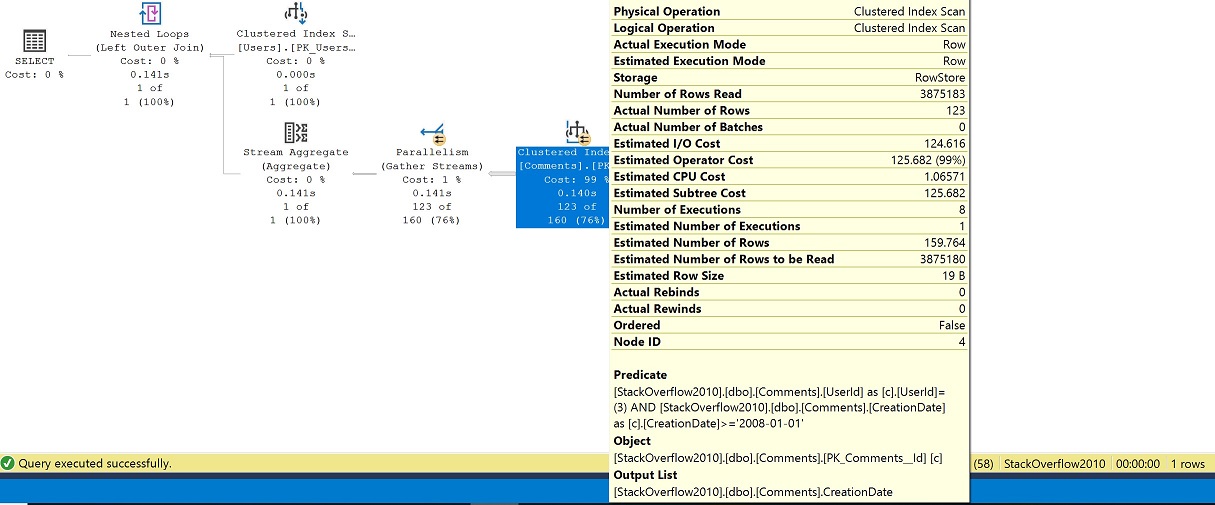
Użycie operatora APPLY
Operator APPLY oferuje tak wiele kreatywnych zastosowań i jest to z pewnością opcja, którą możemy zastosować (pun intended) do interakcji z iTVF. Więcej na temat operatora APPLY można znaleźć w następujących dokumentach: https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms175156(v=sql.105) oraz http://www.sqlservercentral.com/articles/Stairway+Series/121318/
W poniższym przykładzie chcemy wywołać iTVF dla wszystkich użytkowników i zwrócić ich LatestCommentDate, Total Comments, Id oraz Reputation od 01 Jan 2008. Aby to zrobić używamy operatora APPLY, gdzie wykonujemy dla każdego wiersza całej tabeli Users, przekazując Id z tabeli Users oraz CommentDate. W ten sposób zachowujemy zalety enkapsulacji wynikające z użycia iTVF, stosując naszą logikę do wszystkich wierszy w tabeli Users.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
iTVFs in JOINs
Podobnie jak w przypadku łączenia 2 lub więcej tabel, możemy zaangażować iTVFs w złączenia z innymi tabelami. Tutaj chcemy uzyskać DisplayName z tabeli Users oraz UserId, BadgeName i BadgeDate z iTVF, dla użytkowników, którzy otrzymali odznakę 'Student' w dniu lub po 01.01.2008.
DECLARE @BadgeName varchar(40)= 'Student', @BadgeDate datetime= '2008-01-01T00:00:00.000';SELECT u.DisplayName, b.UserId, b.BadgeName, b.BadgeDateFROM dbo.Users u INNER JOIN .(@BadgeName, @BadgeDate) b ON b.UserId = u.Id;GO
Alternatywa dla innych UDF-ów
Wcześniej w tym artykule wspomnieliśmy, że powodem używania iTVF-ów było uniknięcie kary za wydajność, na którą cierpią inne typy UDF-ów, takie jak skalarne i MSTVF-y. W tej części zademonstrujemy jak możemy zastąpić skalarne i MSTVF przez iTVF, a w następnej części zastanowimy się dlaczego możemy się na to zdecydować.
Alternatywa skalarnego FROM
Zanim przejdziemy dalej, uruchommy poniższe zapytanie, aby utworzyć skalarny FROM, dbo.sfnGetRecentComment, którego będziemy wkrótce używać.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS datetimeWITH SCHEMABINDING, RETURNS NULL ON NULL INPUTASBEGIN DECLARE @LatestCreationDate datetime; SELECT @LatestCreationDate = MAX(CreationDate) FROM dbo.Comments WHERE UserId = @UserId AND CreationDate >= @CommentDate GROUP BY UserId; RETURN @LatestCreationDate;END;GO
Po utworzeniu funkcji skalarnej, uruchom następujące zapytanie. Chcemy tutaj użyć logiki zawartej w funkcji skalarnej do zapytania całej tabeli Users i zwrócić Id oraz datę ostatniego komentarza każdego użytkownika od 01.01.2008. Zrobimy to poprzez dodanie funkcji w klauzuli SELECT, gdzie jako wartości parametrów przekażemy Id z tabeli Users oraz datę komentarza, którą właśnie ustaliliśmy na 01 Jan 2008.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Podobne zapytanie można napisać używając iTVF, co przedstawia poniższe zapytanie. Tutaj chcemy uzyskać Id oraz datę ostatniego komentarza od 01.01.2008 używając iTVF i osiągamy to poprzez użycie operatora APPLY względem wszystkich wierszy tabeli Users. Dla każdego wiersza przekazujemy Id użytkownika i datę komentarza.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Alternatywa MSTVF
Wykonaj poniższe zapytanie, aby utworzyć MSTVF dbo.mstvfnGetRecentComment, którego użyjemy za chwilę.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS @RecentComment TABLE( int NULL, date NULL, int NULL)WITH SCHEMABINDING ASBEGIN INSERT INTO @RecentComment SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalComments FROM dbo.Comments c WHERE c.UserId = @UserId AND c.CreationDate >= @CommentDate GROUP BY c.UserId; RETURN;END;GO
Teraz, gdy utworzyliśmy MSTVF, użyjemy go do zwrócenia najnowszej daty komentarza dla wszystkich wierszy w tabeli Użytkownicy od 01 stycznia 2008. Podobnie jak w przykładzie iTVF z operatorem APPLY we wcześniejszej części artykułu, „zastosujemy” naszą funkcję do wszystkich wierszy w tabeli Users, używając operatora APPLY i podając identyfikator użytkownika dla każdego wiersza, jak również ustawioną przez nas datę komentarza.
DECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Gdy zastąpimy MSTVF w naszym przykładzie operatorem iTVF, rezultat będzie bardzo podobny, z wyjątkiem nazwy wywoływanej funkcji. W naszym przypadku wywołamy itvfnGetRecentComment w miejsce MSTVF w poprzednim przykładzie, zachowując kolumny w klauzuli SELECT. W ten sposób możemy uzyskać Id oraz datę ostatniego komentarza od 01.01.2008 używając iTVF dla wszystkich wierszy tabeli Users. Pokazuje to poniższe zapytanie.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Preferencje dla iTVF
Powodem, dla którego warto wybrać iTVF zamiast funkcji skalarnej lub MSTVF jest wydajność.
W skrócie przedstawimy wydajność 3 funkcji w oparciu o przykładowe zapytania, które uruchomiliśmy w poprzedniej sekcji i nie będziemy wchodzić w szczegóły, poza porównaniem wydajności w metrykach takich jak czas wykonania i liczba wykonań dla funkcji. Kod dla statystyk wydajności, który będziemy używać w całym tym demo, pochodzi z Listingu 9.3 w próbkach kodu z trzeciego wydania SQL Server Execution Plans autorstwa Grant Fritchey https://www.red-gate.com/simple-talk/books/sql-server-execution-plans-third-edition-by-grant-fritchey/
Wydajność skalarna
Oto poprzednie zapytanie, które uruchomiliśmy wywołując funkcję skalarną.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Powszechnie wiadomo, że funkcje skalarne hamują paralelizm i że instrukcja z funkcją skalarną jest wywoływana raz dla każdego wiersza. Jeśli twoja tabela ma 10 wierszy, możesz być w porządku. Kilka tysięcy wierszy, i możesz być zaskoczony (lub nie) drastycznym spadkiem wydajności. Zobaczmy to w akcji uruchamiając następujący wycinek kodu.
To co chcemy zrobić najpierw to wyczyścić (w izolowanym środowisku) cache SQL Servera i istniejący plan, który może być ponownie użyty(FREEPROCCACHE), upewniając się, że najpierw uzyskamy dane z dysku (DROPPCLEANBUFFERS), aby rozpocząć od zimnego cache. Luźno mówiąc, w ten sposób zaczynamy od czystego konta.
Potem uruchamiamy zapytanie SELECT na tabeli Users, gdzie zwracamy Id i LatestCommentDate używając funkcji skalarnej. Jako wartości parametrów, przekażemy Id z tabeli Users oraz datę komentarza, którą właśnie ustawiliśmy na 01.01.2008. Przykład wygląda następująco.
-- run in an isolated environmentCHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Pomimo, że zapytanie SELECT, w którym wykorzystujemy funkcję skalarną może wydawać się proste w strukturze, po 4 minutach na moim komputerze nadal się wykonywało.
Przypomnijmy, że dla funkcji skalarnych, są one wykonywane raz dla każdego wiersza. Problem z tym jest taki, że operacje wiersz po wierszu bardzo rzadko są najbardziej efektywnym sposobem pobierania danych w SQL Server w porównaniu do operacji opartych na pojedynczych zestawach.
Aby zaobserwować powtarzające się wykonania, możemy uruchomić zapytanie o statystyki wydajności. Są one zbierane przez SQL Server podczas uruchamiania naszych zapytań i w tym przypadku chcemy uzyskać instrukcję zapytania, czas utworzenia, liczbę wykonań instrukcji, jak również plan zapytania. Poniższe zapytanie jest przykładem tego, jak możemy uzyskać statystyki wydajności.
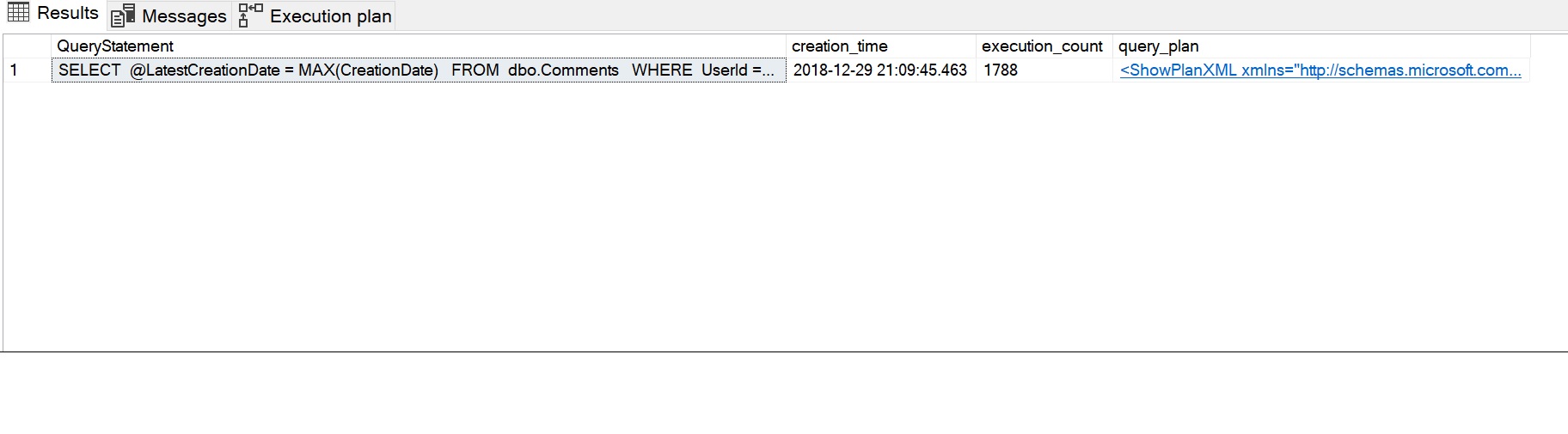
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.sfnGetRecentComment')ORDER BY deqs.last_execution_time DESC;GO
Wynikowe wykonanie statystyk wydajności można zobaczyć na poniższym obrazku. Instrukcja zapytania pokazuje instrukcję SELECT używaną przez funkcję skalarną, licznik wykonania 1788 uchwycił powtarzający się licznik wykonania (raz dla każdego wiersza), a plan, który jest używany przez funkcję można zobaczyć klikając na wiadomość XML planu zapytania.
Dodatkowym sposobem na zobaczenie ważnych metryk wydajności jest użycie rozszerzonych zdarzeń. Aby dowiedzieć się więcej na temat rozszerzonych zdarzeń, kliknij tutaj, ale dla celów naszego demo, uruchom następujące zapytanie, aby utworzyć sesję rozszerzonych zdarzeń.
CREATE EVENT SESSION QuerySession ON SERVER ADD EVENT sqlserver.module_end( WHERE (.(.,(??)))), -- enter your Session Id ADD EVENT sqlserver.sp_statement_completed( WHERE (.(.,(??)))),-- enter your Session Id ADD EVENT sqlserver.sql_batch_completed( WHERE (.(.,(??)))); -- enter your Session IdGOALTER EVENT SESSION QuerySession ON SERVER STATE = START;GO
Po utworzeniu sesji rozszerzonych zdarzeń, przejdź do Zarządzanie w Object Explorer, rozwiń sesje i otwórz menu kontekstowe dla „QuerySession”, które właśnie utworzyliśmy. Wybierz opcję „Obserwuj dane na żywo”.
W nowo otwartym oknie zaobserwuj liczne wiersze deklaracji funkcji skalarnej jako dowód na powtarzające się wykonania.
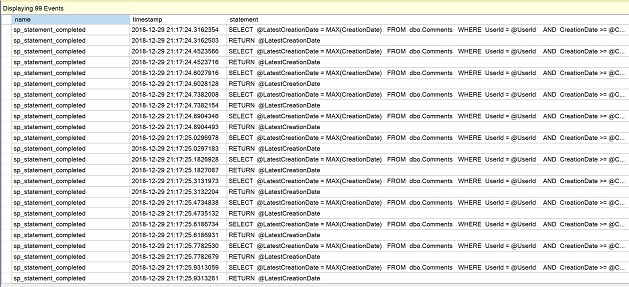
Kliknij na czerwony kwadrat, aby „Zatrzymać podawanie danych”.
Wydajność MSTVF
W przypadku MSTVF mogą również wystąpić kary za wydajność w wyniku ich użycia i jest to związane z wyborem przez SQL Server suboptymalnych planów wykonania z powodu niedokładnych statystyk. SQL Server opiera się na wewnętrznych statystykach, aby zrozumieć ile wierszy danych zwróci zapytanie, dzięki czemu może stworzyć optymalny plan. Proces ten znany jest jako szacowanie kardynalności.
Przed SQL Server 2014, szacowanie kardynalności dla zmiennych tabelarycznych było ustawione na 1 wiersz. Od SQL Server 2014 jest to 100 wierszy, niezależnie od tego, czy zapytujemy o 100 wierszy, czy o 1 milion wierszy. MSTVF zwracają dane poprzez zmienne tabelaryczne, które są deklarowane na początku definicji funkcji. Rzeczywistość jest taka, że optymalizator nie będzie szukał najlepszego planu, jaki może znaleźć, niezależnie od czasu i musi zachować równowagę w tym zakresie (mówiąc bardzo prosto). W przypadku MSTVF, brak dokładnych statystyk (spowodowany niedokładnym oszacowaniem kardynalności zmiennych tabelarycznych w ich definicji) może ograniczyć wydajność, ponieważ optymalizator będzie produkował mniej optymalne plany.
W praktyce, zastąpienie MSTVF przez iTVF może przynieść lepszą wydajność, ponieważ iTVF będą korzystać ze statystyk bazowych tabel.
Poniższy fragment kodu używa operatora APPLY do wykonania MSTVF względem całej tabeli Users. Zwracamy Id z tabeli Użytkownicy i LatestCommentDate z funkcji dla każdego wiersza w tabeli Użytkownicy, przekazując Id użytkownika i datę komentarza, która jest ustawiona na 01.01.2008. Podobnie jak w przypadku uruchamiania funkcji skalarnej, zrobimy to z zimnej pamięci podręcznej. W tym teście należy również wybrać Actual execution plan w SSMS, poprzez kliknięcie Ctrl + M. Uruchom zapytanie.
CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
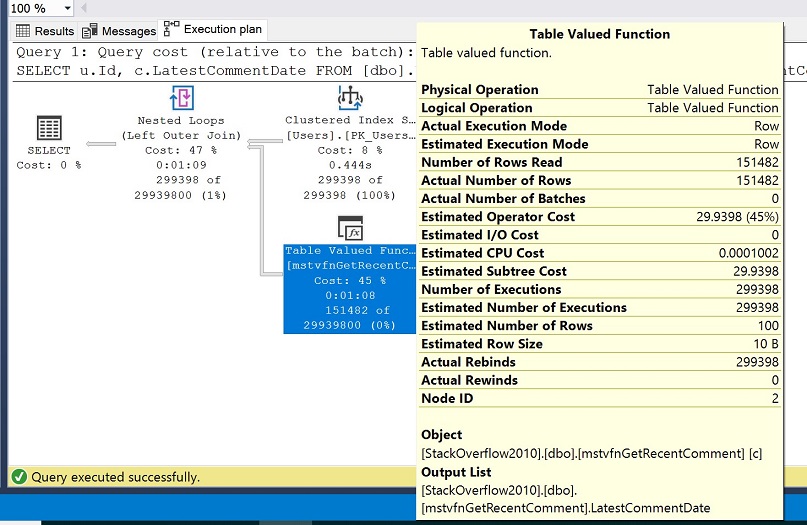
Wynikowy plan wykonania jest pokazany na poniższym obrazku i w żółtym polu właściwości, zauważ wartości dla szacowanej liczby wierszy vs rzeczywista liczba wierszy.
Powinieneś zobaczyć, że szacunkowa liczba wierszy z funkcji wartości tabeli jest ustawiona na 100, ale rzeczywista liczba wierszy jest ustawiona na 151,482. Przypomnijmy, że w naszej konfiguracji wybraliśmy tryb zgodności z SQL Server 2016 (130) i że od SQL Server 2014 szacowanie kardynalności jest ustawione na 100 dla zmiennych tabelarycznych.
Tak dziko różniące się wartości dla szacowanej liczby wierszy vs rzeczywistej liczby wierszy zazwyczaj szkodzą wydajności i mogą uniemożliwić nam uzyskanie bardziej optymalnych planów i ostatecznie lepiej działających zapytań.
Podobnie jak w przypadku funkcji skalarnej, którą uruchomiliśmy poprzednio, uruchomimy zapytanie względem statystyk wydajnościowych SQL Servera. W tym przypadku chcemy również uzyskać instrukcję zapytania, czas utworzenia, liczbę wykonań instrukcji oraz plan zapytania użyty i przefiltrowany dla MSTVF w klauzuli WHERE.
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs OUTER APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp OUTER APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.mstvfnGetRecentComment');
Plan wykonania, który początkowo zaobserwowaliśmy dla MSTVF jest mylący, ponieważ nie odzwierciedla faktycznej pracy wykonanej przez funkcję. Używając statystyk wydajności, które właśnie uruchomiliśmy i wybierając Showplan XML, powinniśmy zobaczyć inny plan zapytania, który pokazuje pracę, która jest wykonywana przez MSTVF. Przykład innego planu niż ten, który widzieliśmy na początku jest następujący. Tutaj możemy teraz zobaczyć, że MSTVF wstawia dane do zmiennej tabelarycznej o nazwie @RecentComment. Dane w zmiennej @RecentComment są tym, co jest następnie zwracane przez MSTVF, aby zwrócić najnowszą datę komentarza.
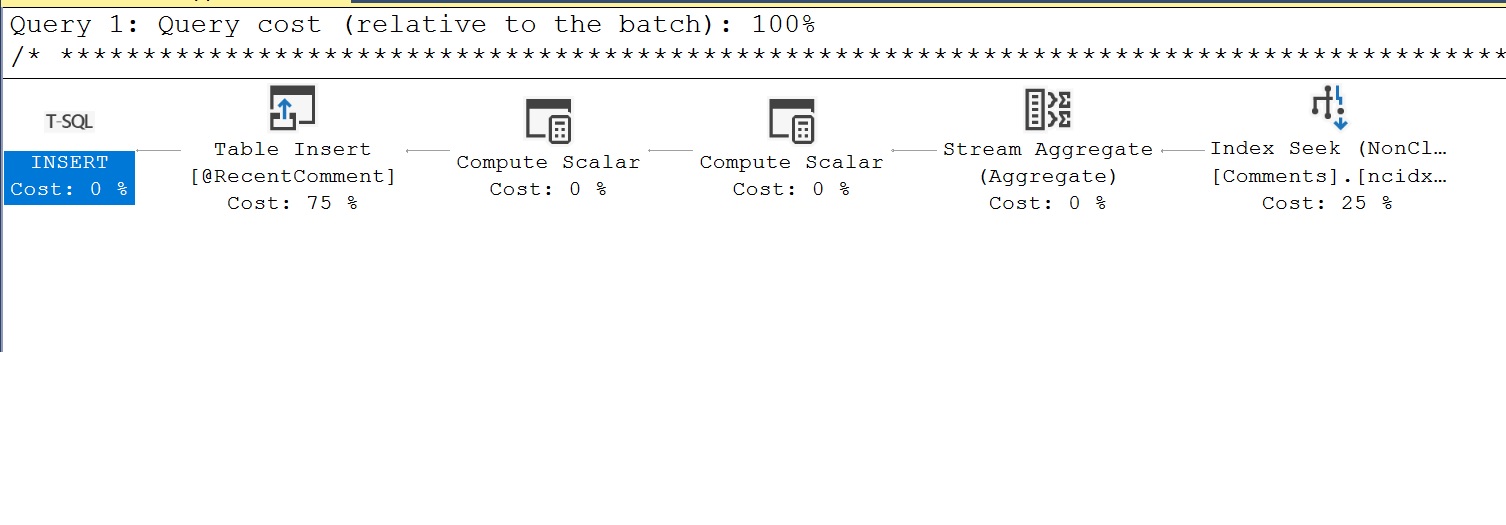
Innym aspektem wydajności, który uchwyciliśmy jest liczba wykonań. Tutaj chcemy być ostrożni z liczbą wielokrotnych wykonań, jako że są one zazwyczaj złe dla wydajności, jak wspomniano przyglądając się wydajności skalarnej.
Co widzimy na poniższym obrazku dla liczby wykonań, to wartość 76, która jest dowodem na wielokrotne wykonanie naszego MSTVF.

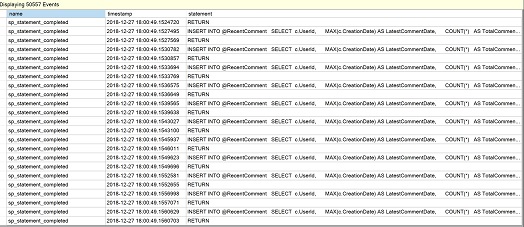
Powróćmy do Zarządzania w Object Explorer, rozwińmy sesje i wybierzmy „Oglądaj dane na żywo” dla sesji „QuerySessions”, którą utworzyliśmy wcześniej, gdy patrzyliśmy na wydajność skalarną. Klikamy na zielony trójkąt „Rozpocznij podawanie danych” w SSMS jeśli sesja została wcześniej zatrzymana i powinniśmy zobaczyć dla naszego przykładu wiele linii zestawienia MSTVF, które reprezentują wielokrotne wykonania zestawienia.
Nie krępuj się anulować zapytania w tym momencie, jeśli nie zostało ono jeszcze zakończone.
Wydajność iTVF
Kiedy zastępujemy funkcje skalarne lub wielowyrazowe funkcjami iTVF, chcemy to zrobić tak, aby uniknąć kar za wydajność, które właśnie widzieliśmy, np. czas wykonania, wielokrotne wykonanie. Używając poprzedniego przykładu, wykonamy zapytanie do tabeli Użytkownicy, aby uzyskać Id i Datę Najnowszego Komentarza z iTVF od 01 stycznia 2008 roku. używając operatora APPLY. Zrobimy to również z zimnej pamięci podręcznej poprzez wyczyszczenie pamięci podręcznej SQL Server i pozyskanie danych z dysku na początek.
--run in an isolated environment CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Następujące zapytanie składa się ze statystyk wydajnościowych, które pomagają nam zobaczyć wykonywane wyrażenie, liczbę wykonań oraz plan zapytania dla tego wyrażenia.
-- Query stats and execution planSELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.dbid = DB_ID('StackOverflow2010')ORDER BY deqs.last_execution_time DESC;
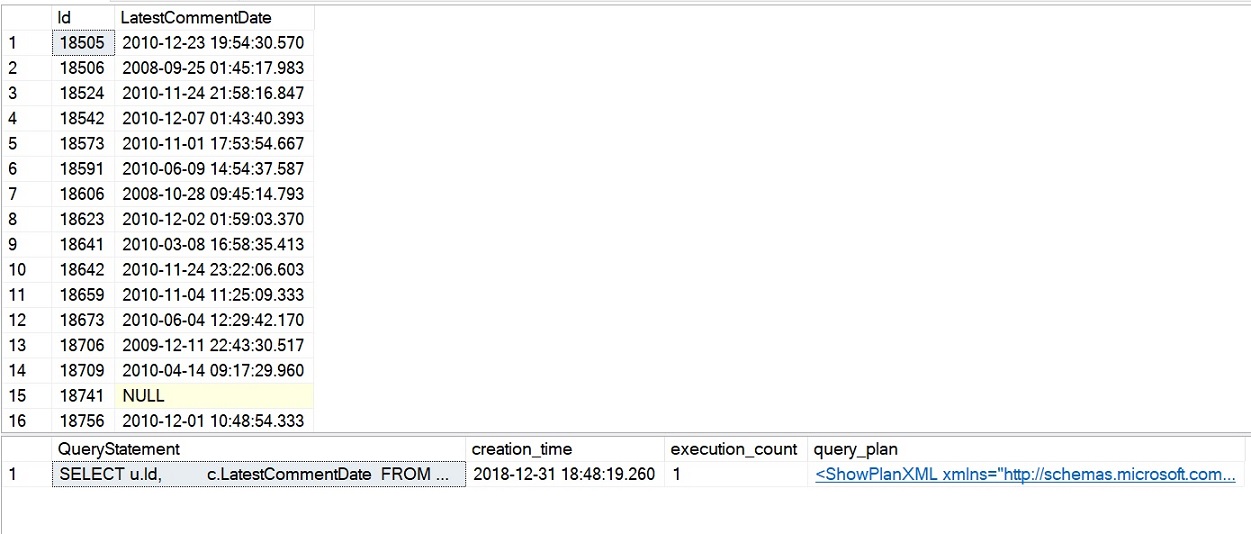
Przykładowe zapytanie dla iTVF, które właśnie wykonaliśmy zakończyło się w nieco ponad 4 sekundy, a statystyki wydajności, które zapytaliśmy powinny pokazać liczbę wykonań równą 1 dla iTVF, jak pokazano na poniższym obrazku. Jest to znacząca poprawa wydajności w porównaniu do naszych wcześniejszych przykładów z próbami skalarnymi i MSTFV.
Porównanie wydajności skalarnej, MSTVF i iTVF
Następująca tabela przedstawia porównanie 3 UDF-ów, które właśnie uruchomiliśmy, aby pokazać, jak wypadły pod względem czasu wykonania i liczby wykonań.
| Scalar | MSTVF | iTVF | |
| Czas wykonania | > 5 minut | > 5 minut | 4 sekundy |
| Liczba wykonań | > 10,000 | >10,000 | 1 |
Różnica w czasie wykonania i liczbie wykonań przy użyciu iTVF jest natychmiast widoczna. W naszym przykładzie, iTVF zwrócił te same dane szybciej i tylko z 1 wykonaniem. W środowiskach, w których występuje duże obciążenie lub w scenariuszach, w których logika jest używana w wielu raportach, które są powolne z powodu użycia skalarnego lub MSTVF, zmiana na iTVF może pomóc złagodzić poważne problemy z wydajnością.
Ograniczenia
iTVF naprawdę wchodzą w grę, gdy trzeba ponownie wykorzystać logikę bez poświęcania wydajności, ale nie są idealne. One również mają ograniczenia.
Aby zapoznać się z listą ograniczeń i restrykcji funkcji zdefiniowanych przez użytkownika w ogóle, możesz odwiedzić Books Online tutaj. Poza tą listą, a w szczególności dla funkcji wycenianych w tabelach inline, poniżej znajdują się ogólne punkty do rozważenia podczas oceny, czy są one odpowiednim narzędziem dla problemu, który możesz mieć.
Jedna instrukcja SELECT
Jako, że definicja iTVF jest ograniczona do 1 instrukcji SELECT, rozwiązania, które wymagają logiki poza tą 1 instrukcją SELECT, gdzie być może wymagane jest przypisanie zmiennych, logika warunkowa lub użycie tabeli tymczasowej, prawdopodobnie nie nadają się do implementacji tylko w iTVF.
Obsługa błędów
To jest ograniczenie, które dotyczy wszystkich funkcji zdefiniowanych przez użytkownika, gdzie konstrukcje takie jak TRY CATCH nie są dozwolone.
Wywoływanie procedur składowanych
Nie można wywoływać procedur składowanych z ciała iTVF, chyba że jest to rozszerzona procedura składowana. Jest to związane z założeniem projektu SQL Server UDF, w którym nie może on zmieniać stanu bazy danych, co w przypadku użycia procedury składowanej mogłoby mieć miejsce.
Podsumowanie
Ten artykuł rozpoczął się z zamiarem ponownego przyjrzenia się funkcjom inline table-valued (iTVF), jakie są obecnie w 2016 roku, pokazując różnorodność sposobów, w jaki można je wykorzystać.
iTVFs mają kluczową zaletę w tym, że nie poświęcają wydajności w przeciwieństwie do innych typów funkcji zdefiniowanych przez użytkownika (UDFs) i mogą zachęcać do dobrych praktyk programistycznych z ich ponownym wykorzystaniem i możliwościami enkapsulacji.
Dzięki ostatnim funkcjom w SQL Server, najpierw w SQL Server 2017, a w nadchodzącym SQL Server 2019, wydajność zarówno skalarnych, jak i MSTVFs ma pewną dodatkową pomoc. Aby uzyskać więcej szczegółów, sprawdź interleaved execution, który wygląda na zapewnienie dokładnego oszacowania kardynalności dla MSTVFs zamiast stałych liczb lub albo 1 lub 100 i skalarnego UDF inlining. Ze skalarnym inliningiem UDF w 2019 roku, koncentrujemy się na adresowaniu słabości wydajności skalarnych UDF.
Dla twoich rozwiązań, upewnij się, że testujesz i jesteś świadomy ich ograniczeń. Kiedy są dobrze używane, są jednym z lepszych narzędzi, które możemy mieć w naszym arsenale SQL.
Dzięki za przeczytanie.