Lest Updated on July 13, 2020
Teoria da informação é um subcampo da matemática relacionado com a transmissão de dados através de um canal ruidoso.
Uma pedra angular da teoria da informação é a ideia de quantificar a quantidade de informação que existe numa mensagem. Mais geralmente, isto pode ser usado para quantificar a informação num evento e numa variável aleatória, chamada entropia, e é calculado usando probabilidade.
Calcular informação e entropia é uma ferramenta útil na aprendizagem de máquinas e é usada como base para técnicas como a selecção de características, construção de árvores de decisão, e, mais geralmente, modelos de classificação de ajuste. Como tal, um profissional da aprendizagem de máquinas requer uma forte compreensão e intuição da informação e entropia.
Neste post, descobrirá uma introdução suave à entropia da informação.
Depois de ler este post, saberá:
- A teoria da informação preocupa-se com a compressão e transmissão de dados e baseia-se na probabilidade e apoia a aprendizagem de máquinas.
- A informação fornece uma forma de quantificar a quantidade de surpresa para um evento medido em bits.
- Entropia fornece uma medida da quantidade média de informação necessária para representar um evento extraída de uma distribuição de probabilidade para uma variável aleatória.
P>Dê início ao seu projecto com o meu novo livro Probability for Machine Learning, incluindo tutoriais passo-a-passo e os ficheiros de código fonte Python para todos os exemplos.
Dê início ao seu projecto.
- Actualização Nov/2019: Adicionado exemplo de probabilidade vs informação e mais sobre a intuição para entropia.

A Gentle Introduction to Information Entropy
Foto de Cristiano Medeiros Dalbem, alguns direitos reservados.
Overvisão
Este tutorial está dividido em três partes; são:
- O que é a Teoria da Informação?
- Calcular a Informação para um Evento
- Calcular a Entropia para uma Variável Aleatória
O que é a Teoria da Informação?
Teoria da Informação é um campo de estudo preocupado com a quantificação da informação para a comunicação.
É um subcampo da matemática e preocupa-se com tópicos como a compressão de dados e os limites do processamento de sinais. O campo foi proposto e desenvolvido por Claude Shannon enquanto trabalhava na companhia telefónica norte-americana Bell Labs.
A teoria da informação preocupa-se em representar dados de forma compacta (uma tarefa conhecida como compressão de dados ou codificação de fonte), bem como em transmiti-los e armazená-los de forma robusta a erros (uma tarefa conhecida como correcção de erros ou codificação de canal).
– Página 56, Machine Learning: A Probabilistic Perspective, 2012.
Um conceito fundamental da informação é a quantificação da quantidade de informação em coisas como eventos, variáveis aleatórias, e distribuições.
Quantificar a quantidade de informação requer o uso de probabilidades, daí a relação da teoria da informação com a probabilidade.
As medições de informação são amplamente utilizadas na inteligência artificial e na aprendizagem de máquinas, tais como na construção de árvores de decisão e na optimização de modelos de classificadores.
Como tal, existe uma importante relação entre a teoria da informação e a aprendizagem de máquinas e um profissional deve estar familiarizado com alguns dos conceitos básicos do campo.
Porquê unificar a teoria da informação e a aprendizagem de máquinas? Porque são duas faces da mesma moeda. A teoria da informação e a aprendizagem de máquinas ainda pertencem uma à outra. Os cérebros são os derradeiros sistemas de compressão e comunicação. E os algoritmos de última geração tanto para compressão de dados como para códigos correctores de erros utilizam as mesmas ferramentas que a aprendizagem de máquinas.
– Página v, Information Theory, Inference, and Learning Algorithms, 2003.
Quer aprender a probabilidade de aprendizagem de máquinas
Realizar agora o meu curso de 7 dias grátis de aprendizagem de máquinas por correio electrónico (com código de amostra).
p>Clique para se inscrever e também obter uma versão PDF Ebook gratuita do curso.p>Download Your FREE Mini-Course
Calcular a Informação para um Evento
Quantificar informação é a base do campo da teoria da informação.
A intuição por detrás da quantificação da informação é a ideia de medir quanta surpresa existe num evento. Os eventos que são raros (baixa probabilidade) são mais surpreendentes e, portanto, têm mais informação do que os eventos que são comuns (alta probabilidade).
- Evento de Baixa Probabilidade: Informação Alta (surpreendente).
- Evento de Probabilidade Alta: Baixa Informação (não surpreendente).
A intuição básica por detrás da teoria da informação é que aprender que um evento improvável ocorreu é mais informativo do que aprender que um evento provável ocorreu.
– Página 73, Aprendizagem Profunda, 2016.
Acontecimentos raros são mais incertos ou mais surpreendentes e requerem mais informação para os representar do que os eventos comuns.
Podemos calcular a quantidade de informação que existe num evento usando a probabilidade do evento. Isto chama-se “informação Shannon”, “auto-informação”, ou simplesmente “informação”, e pode ser calculado para um evento discreto x da seguinte forma:
- li>informação(x) = -log( p(x) )
Where log() is the base-2 logarithm and p(x) is the probability of the event x.
A escolha do logaritmo base-2 significa que as unidades da medida de informação estão em bits (dígitos binários). Isto pode ser directamente interpretado no sentido do processamento da informação como o número de bits necessários para representar o evento.
O cálculo da informação é frequentemente escrito como h(); por exemplo:
- h(x) = -log( p(x) )
O sinal negativo assegura que o resultado é sempre positivo ou zero.
Informação será zero quando a probabilidade de um evento for 1.0 ou uma certeza, por exemplo, não há surpresa.
Vamos tornar isto concreto com alguns exemplos.
Considerar uma moeda única de feira. A probabilidade de cabeças (e caudas) é de 0,5. Podemos calcular a informação para virar uma cabeça em Python usando a função log2().
|
1
2
3
4
5
6
7
8
|
# calcular a informação para uma moeda flip
a partir do log de importação matemática2
# probabilidade do evento
p = 0.5
# calcular informação para o evento
h = -log2(p)
# imprimir o resultado
imprimir(‘p(x)=%.3f, informação: %.3f bits’ % (p, h))
|
Executar o exemplo imprime a probabilidade do evento como 50% e o conteúdo da informação para o evento como 1 bit.
|
1
|
p(x)=0.500, informação: 1.000 bits
|
Se a mesma moeda fosse invertida n vezes, então a informação para esta sequência de inversões seria n bits.
Se a moeda não fosse justa e a probabilidade de uma cabeça fosse em vez disso 10% (0,1), então o evento seria mais raro e exigiria mais de 3 bits de informação.
|
1
|
p(x)=0.100, informação: 3.322 bits
|
Também podemos explorar a informação num único rolo de dados de seis lados, por exemplo, a informação ao lançar um 6.
Sabemos que a probabilidade de lançar qualquer número é de 1/6, o que é um número menor do que 1/2 para um lançamento de moeda, por isso esperaríamos mais surpresa ou uma quantidade maior de informação.
|
1
2
3
4
5
6
7
8
|
# calcular a informação para um lançamento de dados
a partir do log de importação matemática2
# probabilidade do evento
p = 1.0 / 6.0
# calcular informação para o evento
h = -log2(p)
# imprimir o resultado
imprimir(‘p(x)=%.3f, informação: %.3f bits’ % (p, h))
|
Executando o exemplo, podemos ver que a nossa intuição está correcta e que, de facto, existem mais de 2,5 bits de informação num único rolo de um dado justo.
|
1
|
p(x)=0.167, informação: 2.585 bits
|
Outros logaritmos podem ser utilizados em vez da base -2. Por exemplo, também é comum utilizar o logaritmo natural que utiliza o base-e (número de Euler) no cálculo da informação, caso em que as unidades são referidas como “nats”
Podemos desenvolver ainda mais a intuição de que os eventos de baixa probabilidade têm mais informação.
Para tornar isto claro, podemos calcular a informação para probabilidades entre 0 e 1 e traçar a informação correspondente para cada um. Podemos então criar um gráfico de probabilidade versus informação. Seria de esperar que o gráfico curvasse para baixo de probabilidades baixas com informação alta para probabilidades altas com informação baixa.
O exemplo completo está listado abaixo.
Correr o exemplo cria o gráfico de probabilidade vs informação em bits.
Podemos ver a relação esperada onde os eventos de baixa probabilidade são mais surpreendentes e transportam mais informação, e o complemento de eventos de alta probabilidade transportam menos informação.
Podemos também ver que esta relação não é linear, é de facto ligeiramente sub-linear. Isto faz sentido dado o uso da função de registo.
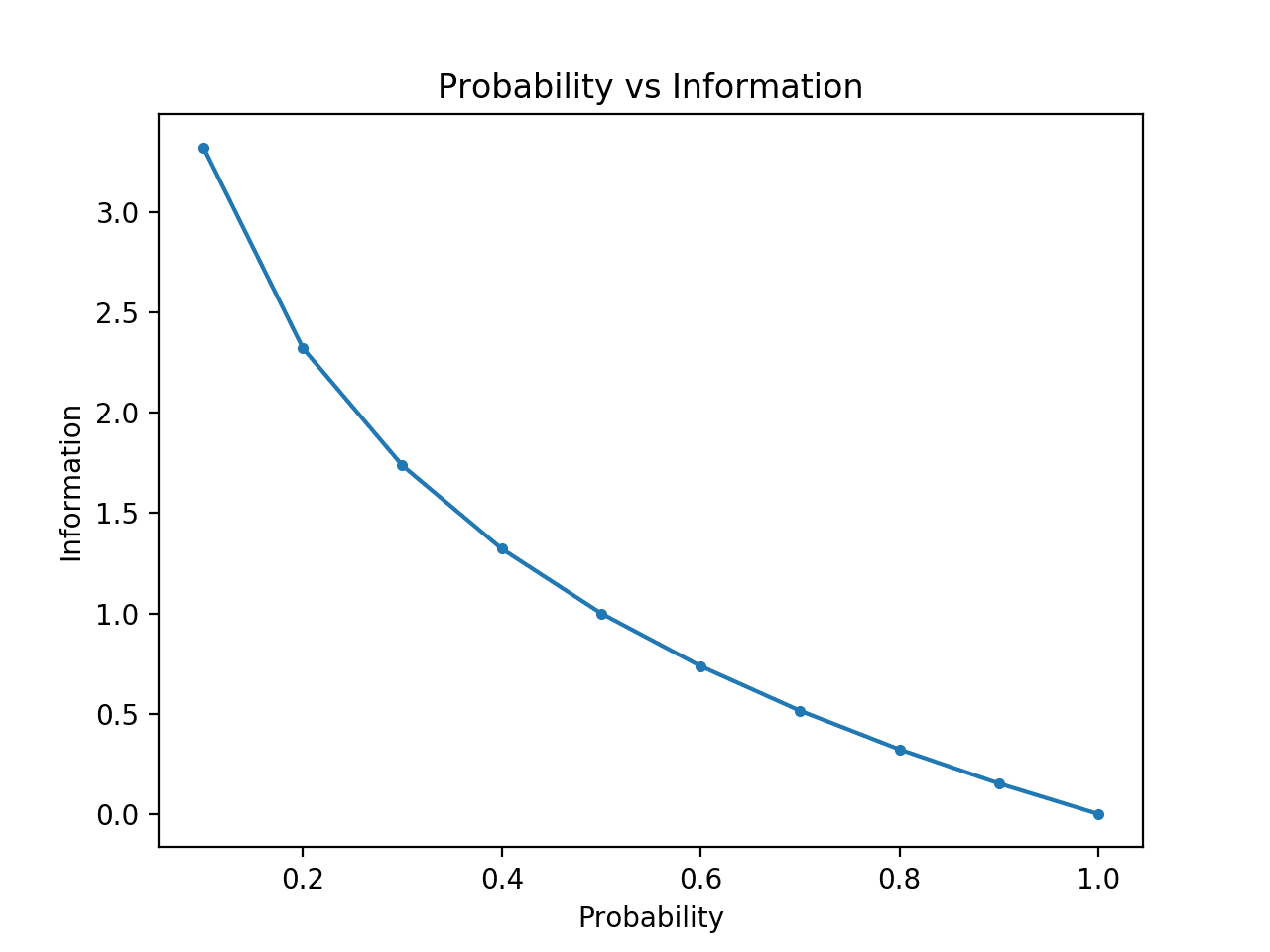
Plot of Probability vs Information
Calcular a Entropia para uma Variável Aleatória
Podemos também quantificar a quantidade de informação que existe numa variável aleatória.
Por exemplo, se quiséssemos calcular a informação para uma variável aleatória X com distribuição de probabilidade p, esta poderia ser escrita como uma função H(); por exemplo:
- H(X)
Em efeito, calcular a informação para uma variável aleatória é o mesmo que calcular a informação para a distribuição de probabilidade dos eventos para a variável aleatória.
Cálculo da informação para uma variável aleatória chama-se “entropia de informação”, “entropia de Shannon”, ou simplesmente “entropia”. Está relacionada com a ideia de entropia a partir da física por analogia, na medida em que ambas estão preocupadas com a incerteza.
A intuição para a entropia é que é o número médio de bits necessários para representar ou transmitir um evento retirado da distribuição de probabilidade para a variável aleatória.
… a entropia Shannon de uma distribuição é a quantidade de informação esperada num evento retirado dessa distribuição. Dá um limite inferior ao número de bits necessários em média para codificar símbolos extraídos de uma distribuição P.
– Página 74, Deep Learning, 2016.
Entropia pode ser calculada para uma variável aleatória X com k em K estados discretos como se segue:
- H(X) = -sum(cada k em K p(k) * log(p(k)))
Isso é o negativo da soma da probabilidade de cada evento multiplicada pelo log da probabilidade de cada evento.
Como informação, a função log() utiliza base-2 e as unidades são bits. Pode ser utilizado um logaritmo natural e as unidades serão nats.
A entropia mais baixa é calculada para uma variável aleatória que tem um único evento com uma probabilidade de 1,0, uma certeza. A maior entropia para uma variável aleatória será se todos os eventos forem igualmente prováveis.
Podemos considerar um rolo de um dado justo e calcular a entropia para a variável. Cada resultado tem a mesma probabilidade de 1/6, portanto é uma distribuição uniforme de probabilidade. Por conseguinte, seria de esperar que a informação média fosse a mesma informação para um único evento calculado na secção anterior.
|
1
2
3
4
5
6
7
8
9
10
|
# calcular a entropia para um dado roll
do log de importação matemática2
# o número de eventos
n = 6
# probabilidade de um evento
p = 1.0 /n
# calcular entropia
entropia = -sum()
# imprimir o resultado
# imprimir(‘entropia: %.3f bits’ % entropia)
|
Executar o exemplo calcula a entropia como mais de 2,5 bits, que é o mesmo que a informação para um único resultado. Isto faz sentido, pois a informação média é a mesma que o limite inferior da informação, uma vez que todos os resultados são igualmente prováveis.
|
1
|
div>entropy: 2.585 bits
|
Se soubermos a probabilidade de cada evento, podemos usar a função de entropia() SciPy para calcular directamente a entropia.
Por exemplo:
|
1
2
3
4
5
6
7
8
|
# calcular a entropia para um lançamento de dados
a partir de scipy.stats importar entropia
# probabilidades discretas
p =
# calcular entropia
e = entropia(p, base=2)
# imprimir o resultado
imprimir(‘entropia: %.3f bits’ % e)
|
Executar o exemplo relata o mesmo resultado que calculámos manualmente.
|
1
|
div>entropy: 2.585 bits
|
Podemos desenvolver ainda mais a intuição para a entropia das distribuições de probabilidade.
Relembrar que a entropia é o número de bits necessários para representar uma distribuição aleatória mesmo a partir da distribuição, por exemplo, um evento médio. Podemos explorar isto para uma distribuição simples com dois eventos, como uma virada de moeda, mas explorar probabilidades diferentes para estes dois eventos e calcular a entropia para cada.
No caso em que um evento domina, como uma distribuição de probabilidade enviesada, então há menos surpresa e a distribuição terá uma entropia mais baixa. No caso em que nenhum evento domina outro, tal como uma distribuição de probabilidade igual ou aproximadamente igual, então esperaríamos uma entropia maior ou máxima.
- Distribuição de Probabilidade Inclinada (sem surpresa): Baixa entropia.
- Distribuição Equilibrada de Probabilidade (surpreendente): Alta entropia.
Se passarmos de enviesada para igual probabilidade de eventos na distribuição, esperaríamos que a entropia começasse baixa e aumentasse, especificamente a partir da mais baixa entropia de 0.0 para eventos com impossibilidade/certeza (probabilidade de 0 e 1 respectivamente) para a maior entropia de 1,0 para eventos com probabilidade igual.
O exemplo abaixo implementa isto, criando cada distribuição de probabilidade nesta transição, calculando a entropia para cada um e traçando o resultado.
p> Executar o exemplo cria as 6 distribuições de probabilidade com probabilidade até às probabilidades.
Como esperado, podemos ver que à medida que a distribuição de eventos muda de distorcida para equilibrada, a entropia aumenta de valores mínimos para máximos.
Isto é, se o evento médio retirado de uma distribuição de probabilidade não for surpreendente, obtemos uma entropia mais baixa, enquanto que se for surpreendente, obtemos uma entropia maior.
Podemos ver que a transição não é linear, que é super linear. Também podemos ver que esta curva é simétrica se continuarmos a transição para e para os dois eventos, formando uma parábola invertida.
Nota que tivemos de adicionar um pequeno valor à probabilidade ao calcular a entropia para evitar calcular o log de um valor zero, o que resultaria num infinito sobre não um número.
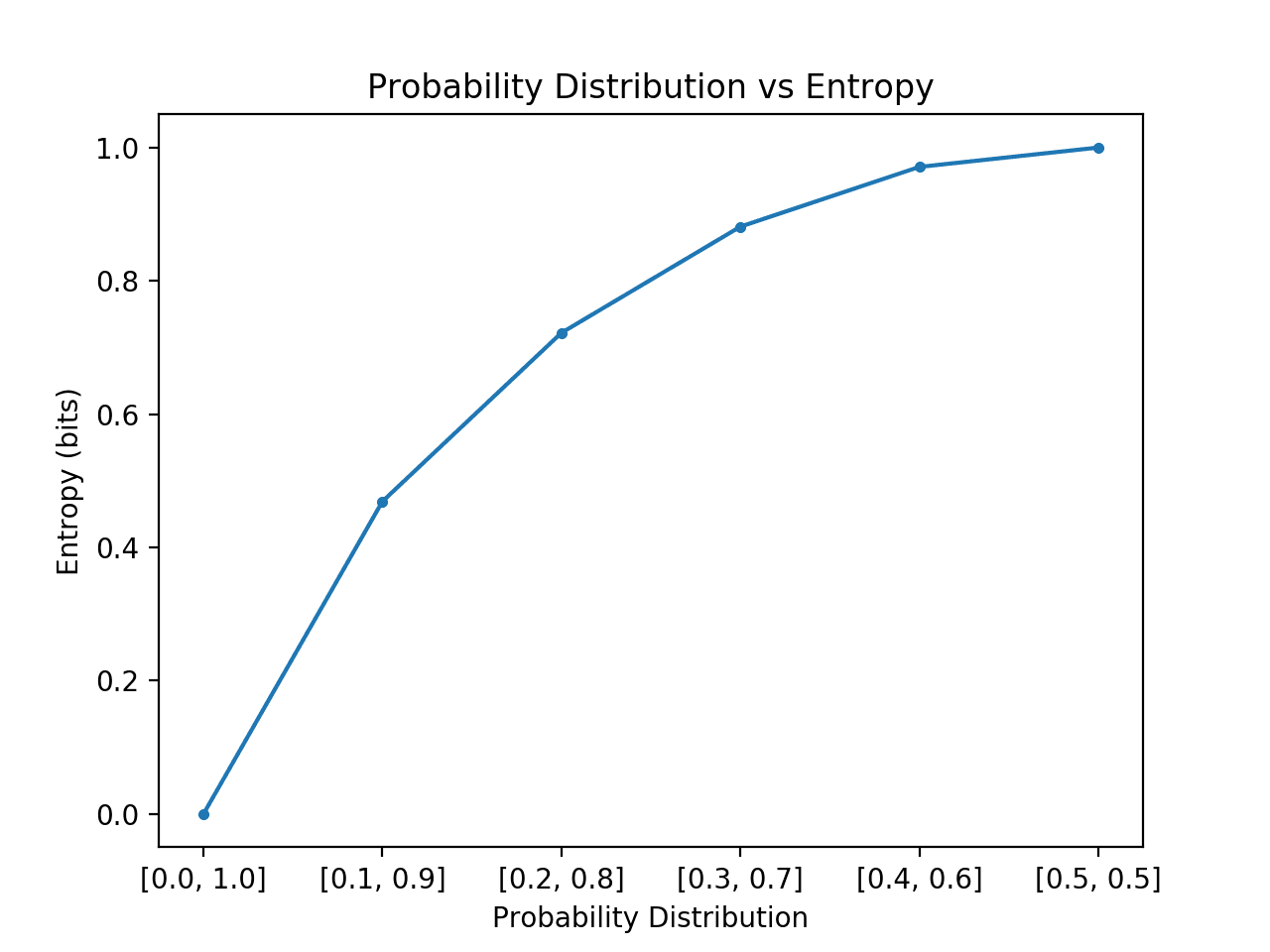 p>Plot of Probability Distribution vs Entropy
p>Plot of Probability Distribution vs Entropy Calcular a entropia para uma variável aleatória fornece a base para outras medidas, tais como informação mútua (ganho de informação).
Entropia também fornece a base para o cálculo da diferença entre duas distribuições de probabilidade com a centralidade cruzada e a divergência KL.
Outra Leitura
Esta secção fornece mais recursos sobre o tópico se estiver a procurar ir mais fundo.
Livros
- li> Teoria da Informação, Inferência, e Algoritmos de Aprendizagem, 2003.
Capítulos
- Secção 2.8: Teoria da Informação, Aprendizagem Máquina: A Probabilistic Perspective, 2012.
- Secção 1.6: Teoria da Informação, Reconhecimento de Padrões e Aprendizagem Mecânica, 2006.
- Secção 3.13: Teoria da Informação, Aprendizagem Profunda, 2016.
API
- li>scipy.stats.entropy API
Artigos
- Entropia (teoria da informação), Wikipedia.
- Ganho de informação em árvores de decisão, Wikipedia.
- Razão de ganho de informação, Wikipedia.
Resumo
Neste post, descobriu uma suave introdução à entropia da informação.
Especificamente, aprendeu:
- A teoria da informação preocupa-se com a compressão e transmissão de dados e baseia-se na probabilidade e suporta a aprendizagem de máquinas.
- A informação fornece uma forma de quantificar a quantidade de surpresa de um evento medido em bits.
- Entropia fornece uma medida da quantidade média de informação necessária para representar um evento tirada de uma distribuição de probabilidade para uma variável aleatória.
Tem alguma pergunta?
Ponha as suas perguntas nos comentários abaixo e farei o meu melhor para responder.
Ponha o meu melhor para responder.
Ponha o meu melhor para responder.

Develop Your Understanding of Probability
…com apenas algumas linhas de código python
Descobre como no meu novo Ebook:
Probabilidade para Aprendizagem Automática
p>P>Proporciona tutoriais de auto-estudo e projectos ponta-a-ponta em:
Teoria Bayesiana, Optimização Bayesiana, Distribuições, Máxima Probabilidade, Cross-Entropy, Modelos de Calibração
e muito mais…
Finally Harness Uncertainty in Your Projects
Skip the Academics. Just Results.See What’s Inside
Ponha o meu melhor para responder.
Develop Your Understanding of Probability
…com apenas algumas linhas de código python
Descobre como no meu novo Ebook:
Probabilidade para Aprendizagem Automática
p>P>Proporciona tutoriais de auto-estudo e projectos ponta-a-ponta em:
Teoria Bayesiana, Optimização Bayesiana, Distribuições, Máxima Probabilidade, Cross-Entropy, Modelos de Calibração
e muito mais…
Finally Harness Uncertainty in Your Projects
Skip the Academics. Just Results.See What’s Inside