Variáveis categóricas podem representar o desenvolvimento de uma doença, um aumento da gravidade da doença, mortalidade, ou qualquer outra variável que consista em dois ou mais níveis. Para resumir a associação entre duas variáveis categóricas com níveis R e C, criamos tabulações cruzadas, ou tabelas RxC (“Linha “x “Coluna” ou tabelas de contingência), que resumem as frequências observadas de resultados categóricos entre diferentes grupos de sujeitos. Aqui centrar-nos-emos em 2 x 2 tabelas.
Em geral, 2 x 2 tabelas resumem a frequência de eventos relacionados com a saúde (ou outros) entre diferentes grupos, como ilustrado abaixo, no qual o Grupo 1 pode representar pacientes que receberam uma terapia padrão, e o Grupo 2 pode ser pacientes que receberam uma nova terapia experimental.
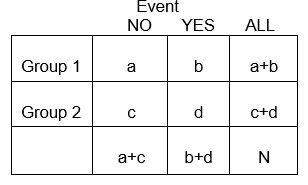
Exemplo:
A variável de resultado primário nos ensaios Kawasaki foi o desenvolvimento de anomalias coronárias (AC), uma variável dicotómica. Um dos objectivos do estudo foi comparar as probabilidades de desenvolvimento de anomalias coronárias com Aspirina (ASA) ou Gamma globulin (GG).

Poderíamos estar interessados em saber se a frequência das anomalias coronárias diferia entre estes dois grupos, ou seja foi uma delas associada a menos anomalias. A resposta a perguntas como esta depende de uma comparação das frequências destes eventos de saúde nos dois grupos de tratamento. Dependendo da concepção do estudo, é possível comparar a probabilidade de ocorrência de eventos ou as probabilidades de ocorrência de um evento.
Probabilidade e probabilidades de desenvolver CA em cada um dos Braços de Tratamento
A probabilidade é calculada como o número de valores “sim” em cada categoria de tratamento dividido pelo número total na categoria de tratamento.
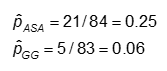
As probabilidades são #Sim / #Não. Aqui,
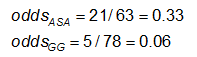
Notem sempre se o resultado está nas filas ou nas colunas; é muito fácil misturá-los!
Quando olhámos para a associação entre uma variável binária e um resultado contínuo, resumimos a associação em termos de diferença de meios. Que estatísticas são apropriadas para representar a diferença entre dois grupos no que respeita à probabilidade de um evento binário? Há pelo menos três formas de resumir a associação:
Diferença de risco RD = p1 – p2
Risco Relativo (Relação de Risco) RR = p1 / p2
Rácio OU = odds1/ odds2 = /
O desenho do estudo determina qual destas medidas de efeito é apropriada. Num estudo de caso/controlo, o risco relativo não pode ser avaliado, e o odds ratio (OR) é a medida apropriada. No entanto, o OR fornecerá uma boa estimativa do risco relativo para eventos raros (ou seja, se p for pequeno, normalmente 0,10 ou menor).
Os estudos transversais avaliam a prevalência de medidas de saúde, pelo que o odds ratio é apropriado. Com estudos de coorte prospectivos, ou um rácio de taxa ou um rácio de risco é apropriado, embora também possa ser calculado um odds ratio.,
Para uma revisão mais detalhada das medidas de efeito, ver o módulo de epidemiologia em linha sobre “Medidas de Associação”.
Exemplo: Utilizando os dados anteriores sobre anomalias CA, as medidas de efeito para quem usa ASA (aspirina) versus gamaglobulina (GG) são as seguintes:
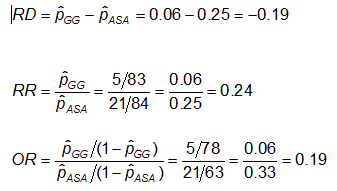

Exercício: Considerar as medidas de efeito no exemplo anterior. Porque é que o rácio de risco e odds ratio são tão diferentes (o RR sugere que, comparado com o grupo tratado apenas com ASA, o risco de anomalias coronárias é de 1/4 tão elevado para aqueles tratados com GG; enquanto o OR sugere que o risco é de 1/5 tão elevado)?
Modas Alternativas de Expressão da Hipótese Nula
Para uma tabela 2×2, a hipótese nula pode equivalentemente ser escrita em termos das próprias probabilidades, ou da diferença de risco, do risco relativo, ou do odds ratio. Em cada caso, a hipótese nula afirma que não há diferença entre os dois grupos.
H0: p1 = p2
H1: p1 ≠ p2
H0: p1 – p2 = 0 (RD=0)
H1: RD ≠ 0
H0: p1/ p2 = 1 (RR=1)
H1: RR ≠ 1
H0: OR = 1
H1: OU ≠ 1
O Teste Qui-quadrado
A diferença na frequência do resultado entre os dois grupos pode ser avaliada com o teste do qui-quadrado.
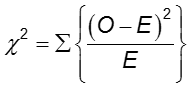
Em cada célula da tabela 2×2, O é a frequência celular observada e E é a frequência celular esperada sob a suposição de que a hipótese nula é verdadeira. A soma é calculada sobre os 2×2 = 4 células da tabela. Desde que a frequência esperada em cada célula seja pelo menos cinco, o valor qui-quadrado calculado tem uma distribuição χ2 com 1 graus de liberdade (df).
Rejeitar a hipótese nula se ![]() . Para α = 0,05, o valor crítico é 3,84.
. Para α = 0,05, o valor crítico é 3,84.
Exemplo:
Frequências observadas

Se não houver associação entre tratamento e doença, a proporção de casos entre os tratados e não tratados seria a mesma e seria igual à proporção de casos em toda a população do estudo.
Frequências esperadas:
Em todas as 167 crianças, existem 26 com anormalidades de CA e 141 sem anormalidades de CA. A proporção com anomalias CA é de 26/167, ou 16%. Se a hipótese nula for verdadeira, e os dois grupos de tratamento tiverem a mesma probabilidade de anomalias CA, então esperaríamos cerca de 16% em cada grupo ter anomalias CA.
Então, no grupo GG de n=83, esperaríamos 16% de 83 anomalias CA. Isto é calculado como 0,16 x 83 = 13, e é chamado a frequência esperada naquela célula.
Podemos escrever isto como
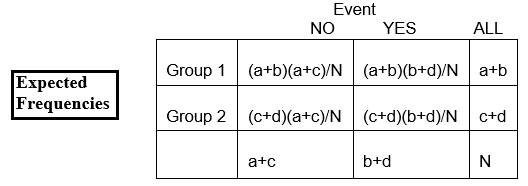
E11 = frequência esperada na linha 1, coluna 1
= número esperado no grupo 1 que tem o evento (linha 1, coluna 1)
E calculamos como
E11 = (proporção que esperamos que tenha o evento) x número total em (grupo) linha 1
= x número na (grupo) linha 1
usando a notação na tabela,
E11 = x (a+b)
E frequentemente reescrevemos isto simplesmente como
E11 = (a+b)(a+c)/N
No nosso exemplo, vamos calcular a frequência esperada na primeira célula ( E11) :
E11 = (83)(26)/167 = 12.92
Podemos calcular as frequências esperadas nas outras células da mesma forma
A proporção global sem anomalias CA é de 141/167, ou 84%. Esperamos que cerca de 84% das pessoas do grupo ASA não apresentem anomalias CA, pelo que a frequência esperada na linha 2, coluna 2, é E22 = 84% de 84, ou 0,84 x 84, ou aproximadamente 71,
Utilizando a tabela acima, poderíamos simplesmente calculá-la como
E22 = (c+d)(b+d)/N = (84)(141)/167 = 70.92
Exercício: Quantas crianças do grupo ASA esperaria ter anormalidades CA se a hipótese nula fosse verdadeira? Tente resolver isto antes de olhar para a resposta abaixo.
Nota que as frequências observadas assumem valores inteiros, enquanto que as frequências esperadas podem assumir valores decimais.
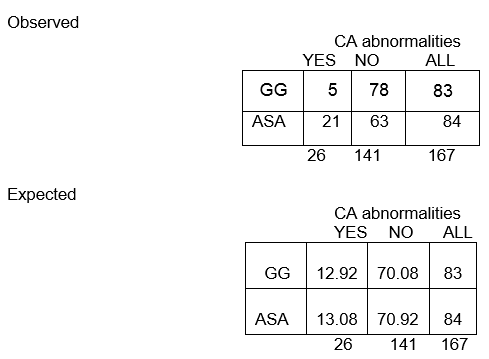
Esperamos que quase 13 crianças do grupo GG tenham anomalias CA, mas apenas 5 de facto tiveram!
Nota que uma vez calculada uma frequência esperada, as outras podem ser obtidas facilmente por subtracção! O número de graus de liberdade é igual ao número de células cuja frequência esperada precisa de ser calculada; numa tabela de 2 x 2, isto é 1.
estatística do teste de Qui-quadrado
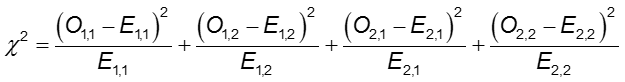
onde O1,1 e E1,1 são as contagens observadas e esperadas na célula da primeira linha e da primeira coluna. Por exemplo, O1,1 = a e E1,1 =(a+b)(a+c)/N. Se as contagens das células observadas forem suficientemente diferentes das esperadas, então não podemos concluir que as duas probabilidades são iguais.
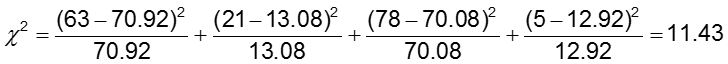
H0: As probabilidades de anomalias CA são as mesmas entre grupos de tratamento (OR=1)
H1: As probabilidades de anomalias CA não são as mesmas entre os grupos de tratamento (OR≠1)
O nível de significância é 0.05.
A estatística do teste é calculada para ser 11.43. Uma vez que a nossa estatística de teste é superior a 3,84 (o valor crítico do qui-quadrado para 1 grau de liberdade), rejeitamos a hipótese nula e concluímos que as probabilidades de anomalias CA não são as mesmas nos dois grupos de tratamento.
retornar ao topo | página anterior | página seguinte