NCSS inclui uma série de ferramentas para análise multivariada, a análise de dados com mais do que uma variável dependente ou Y. Análise Factorizada, Análise de Componentes Principais (PCA), e Análise Multivariada de Variância (MANOVA) são todas técnicas de análise multivariada bem conhecidas e todas estão disponíveis em NCSS, juntamente com vários outros procedimentos de análise multivariada como descrito abaixo.
Utilize os links abaixo para saltar para o tópico de análise multivariada que gostaria de examinar. Para ver como estas ferramentas lhe podem beneficiar, recomendamos-lhe que descarregue e instale o teste gratuito do NCSS.
P>Pule para:
- Introdução
- Detalhes técnicos
- Análise de Factores
- Análise de Componentes Principais (PCA)
- Correlação Canónica
- Qualidade de Covariância
- Análise Discriminatória
- Hotelling’s Two-Amostra T²
- Análise de Variância Multivariada (MANOVA)
- Análise de Correspondência
- Modelos Loglineares
- Escala Multidimensional
li>Análise de Componentes Nucleares (PCA)Amostra T²
Introdução
Embora o termo Análise Multivariada possa ser usado para se referir a qualquer análise que envolva mais do que uma variável (e.g. em Regressão Múltipla ou ANOVA GLM), o termo análise multivariada é usado aqui e no NCSS para se referir a situações que envolvam dados multidimensionais com mais do que uma variável dependente, Y, ou variável de resultado. As técnicas de análise multivariada são usadas para compreender como o conjunto de variáveis de resultado como um todo combinado é influenciado por outros factores, como as variáveis de resultado se relacionam entre si, ou que factores subjacentes produzem os resultados observados nas variáveis dependentes.
Cada um dos procedimentos disponíveis na secção Análise Multivariada do NCSS é descrito abaixo.
Detalhes Técnicos
Esta página foi concebida para dar uma visão geral das capacidades do NCSS para técnicas de análise multivariada. Se desejar examinar as fórmulas e detalhes técnicos relativos a um procedimento NCSS específico, clique na ligação correspondente ” sob cada título para carregar a documentação completa do procedimento. Aí encontrará fórmulas, referências, discussões, e exemplos ou tutoriais descrevendo o procedimento em pormenor.
Análise de Factores
Análise de Factores (FA) é uma técnica exploratória aplicada a um conjunto de variáveis de resultado que procura encontrar os factores subjacentes (ou subconjuntos de variáveis) a partir dos quais as variáveis observadas foram geradas. Por exemplo, a resposta de um indivíduo às perguntas de um exame é influenciada por variáveis subjacentes tais como inteligência, anos na escola, idade, estado emocional no dia do teste, quantidade de prática a fazer testes, e assim por diante. As respostas às perguntas são as variáveis observadas ou de resultado. As variáveis subjacentes e influentes são os factores.
Análise de factores é realizada sobre a matriz de correlação das variáveis observadas. Um factor é uma média ponderada das variáveis originais. O analista de factores espera encontrar alguns factores a partir dos quais a matriz de correlação original pode ser gerada.
Usualmente, o objectivo da análise de factores é ajudar na interpretação dos dados. O analista de factores espera identificar cada factor como representando um factor teórico específico. Outro objectivo da análise de factores é reduzir o número de variáveis. O analista espera reduzir a interpretação de um teste de 200 perguntas para o estudo de 4 ou 5 factores.
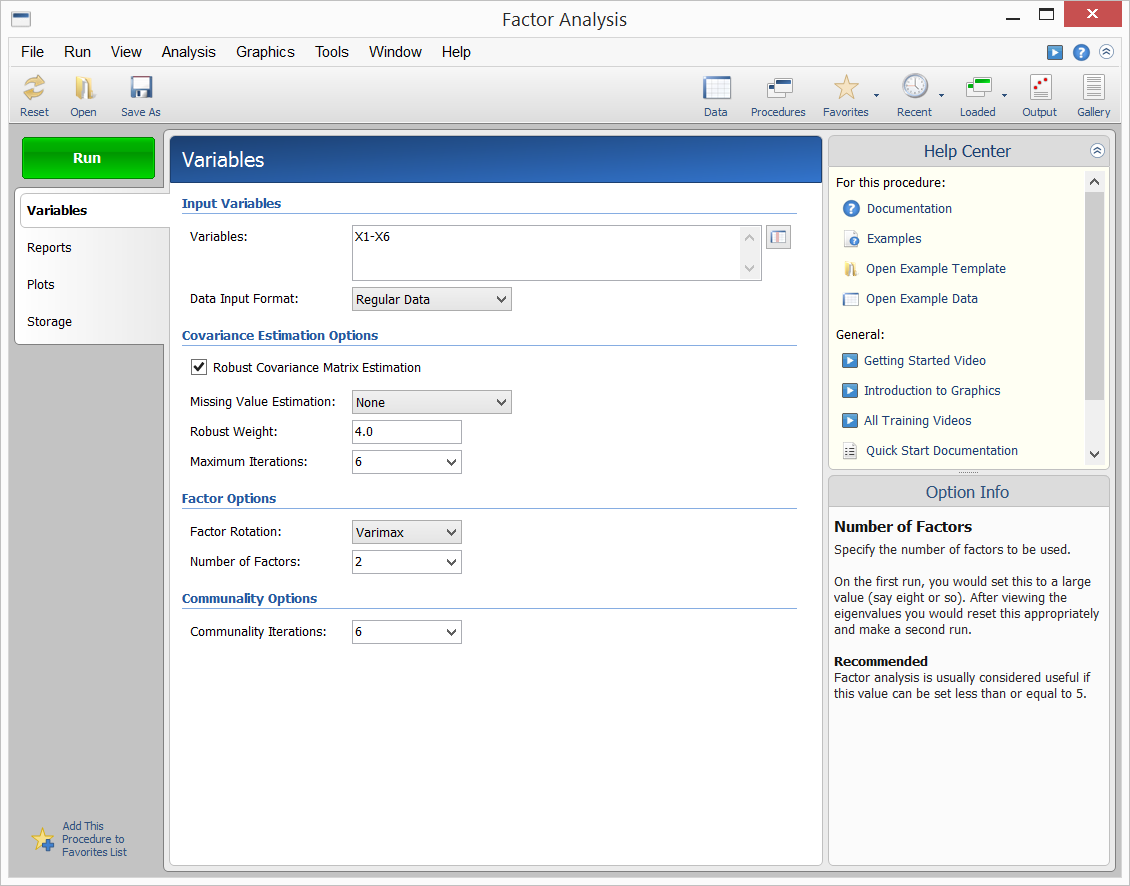
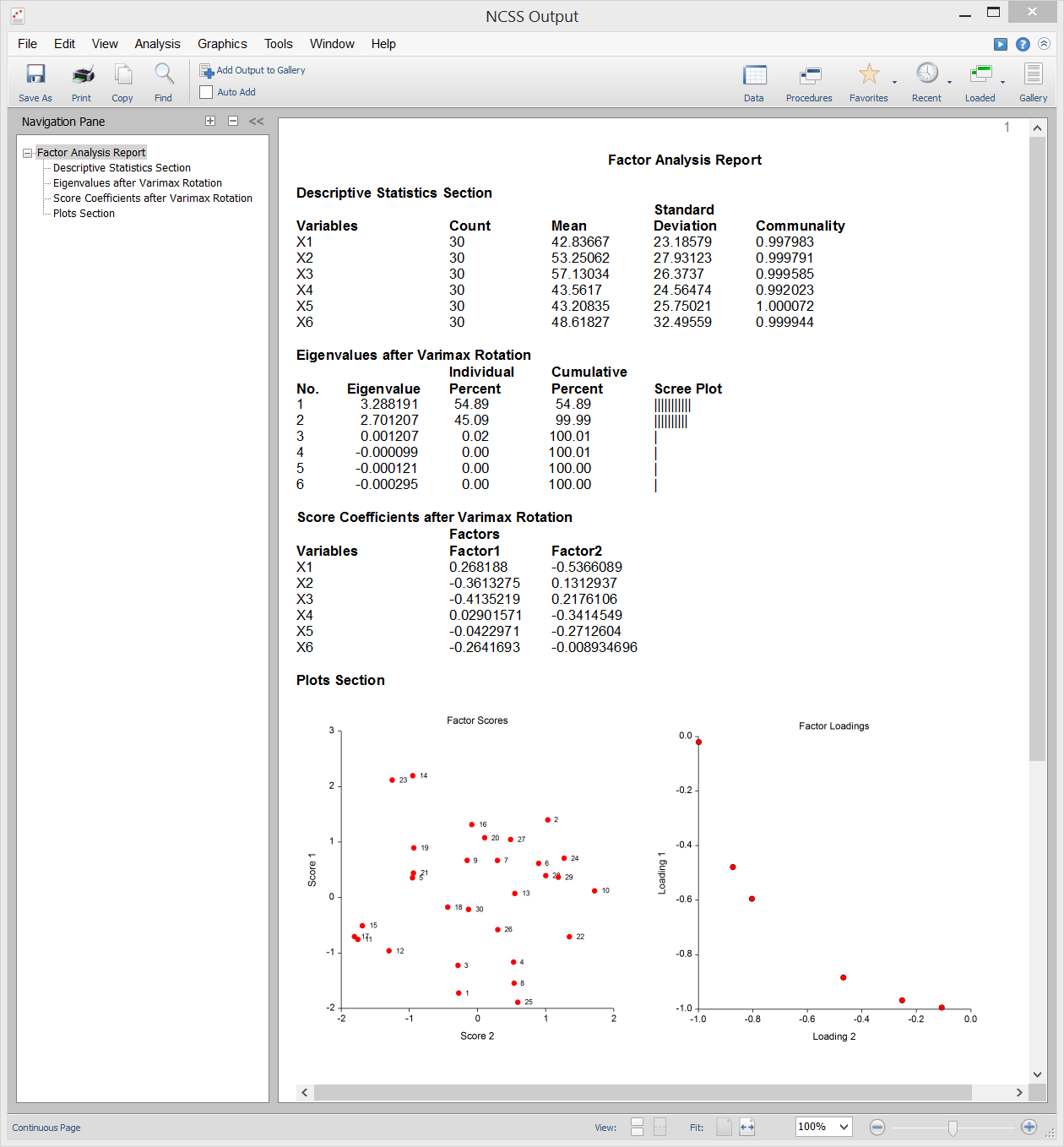
NCSS fornece o método do eixo principal da análise de factores. Os resultados podem ser rodados utilizando rotação varimax ou quartimax e as pontuações dos factores podem ser armazenadas para análise posterior. Os dados da amostra, entrada e saída do procedimento são mostrados abaixo.
Dados da amostra
Entrada de procedimento
Saída de amostra
Análise de componentes principais (PCA)
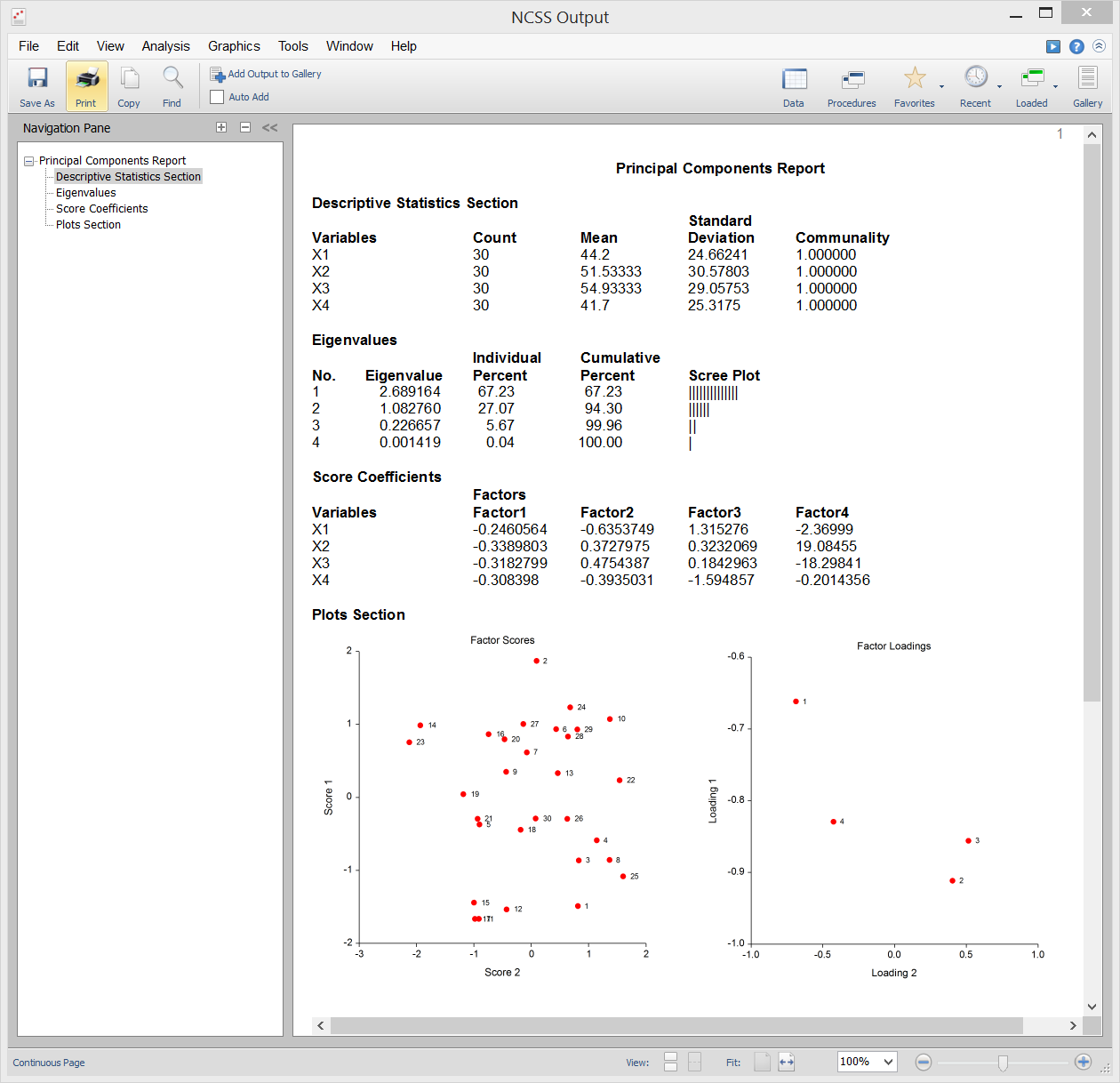
Análise de componentes principais (ou PCA) é uma ferramenta de análise de dados que é frequentemente utilizada para reduzir a dimensionalidade (ou número de variáveis) a partir de um grande número de variáveis inter-relacionadas, enquanto conserva o máximo de informação (e.g. variação) o mais possível. A PCA calcula um conjunto de variáveis não correlacionadas, conhecidas como factores ou componentes principais. Estes factores são ordenados de modo a que os primeiros retenham a maior parte da variação presente em todas as variáveis originais. Ao contrário da sua prima Análise de Factores, PCA produz sempre a mesma solução a partir dos mesmos dados.
NCSS utiliza uma versão de dupla precisão do moderno algoritmo QL, tal como descrito por Press (1986), para resolver o problema do auto-valor-elevador próprio envolvido nos cálculos de PCA. O NCSS executa PCA numa matriz de correlação ou de covariância. A análise pode ser realizada utilizando técnicas de estimação robustas.
Sample Output
Correlação Canónica
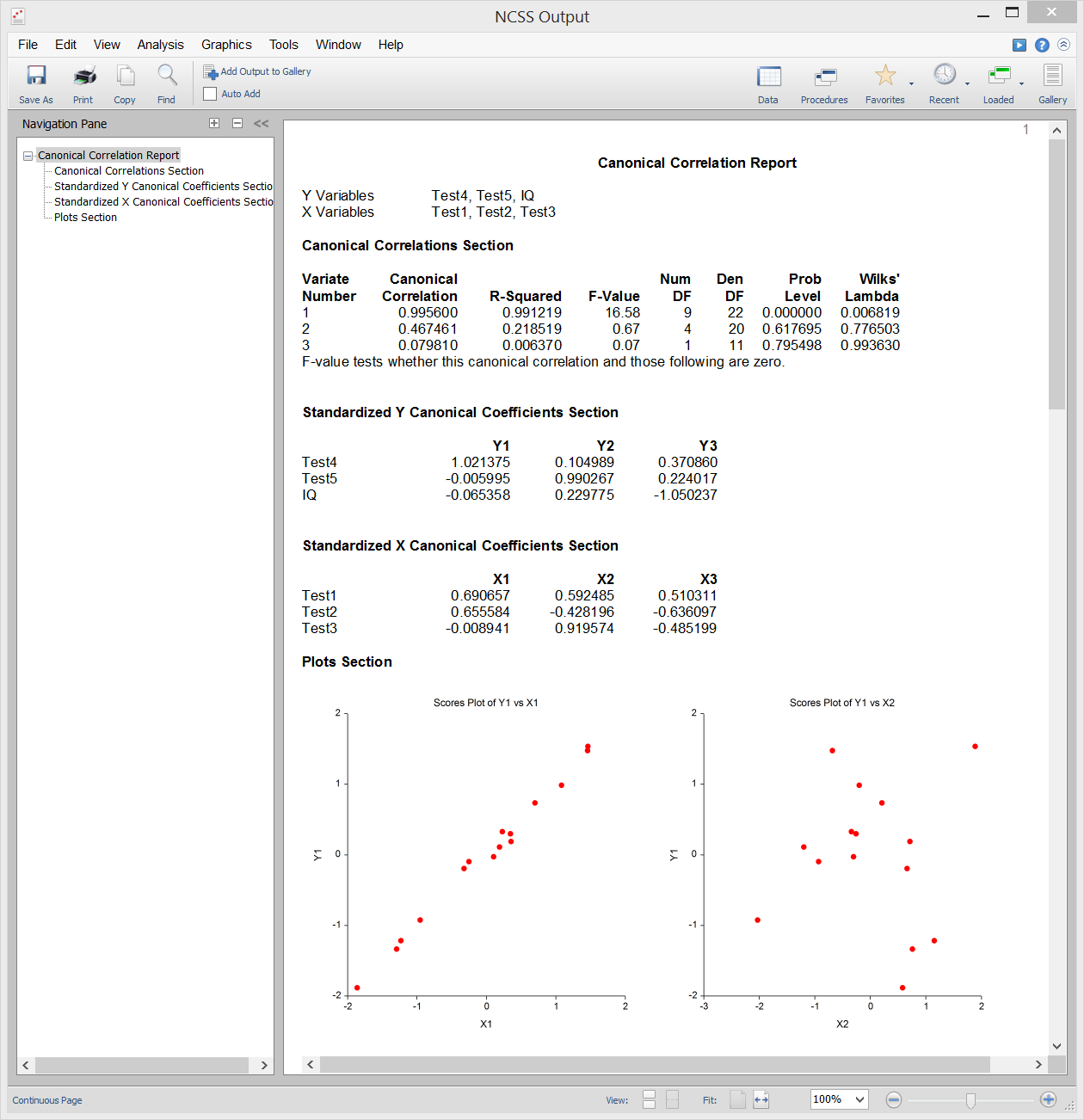
Análise de correlação canónica é o estudo da relação linear entre dois conjuntos de variáveis. É a extensão multivariada da análise de correlação. A título de ilustração, suponhamos que um grupo de estudantes recebe cada um dois testes de dez perguntas cada um e deseja determinar a correlação global entre estes dois testes. A correlação canónica encontra uma média ponderada das perguntas do primeiro teste e correlaciona-a com uma média ponderada das perguntas do segundo teste. Os pesos são construídos para maximizar a correlação entre estas duas médias. Esta correlação é chamada o primeiro coeficiente de correlação canónica. Pode-se então criar outro conjunto de médias ponderadas não relacionadas com a primeira e calcular a sua correlação. Esta correlação é o segundo coeficiente de correlação canónica. O processo continua até que o número de correlações canónicas seja igual ao número de variáveis no grupo mais pequeno.
A correlação canónica fornece o quadro multivariado mais geral (Análise discriminante, MANOVA, e regressão múltipla são todos casos especiais de correlação canónica). Devido a esta generalidade, a correlação canónica é provavelmente o menos utilizado dos procedimentos multivariados.
Saída de amostras
Igualdade de Covariância
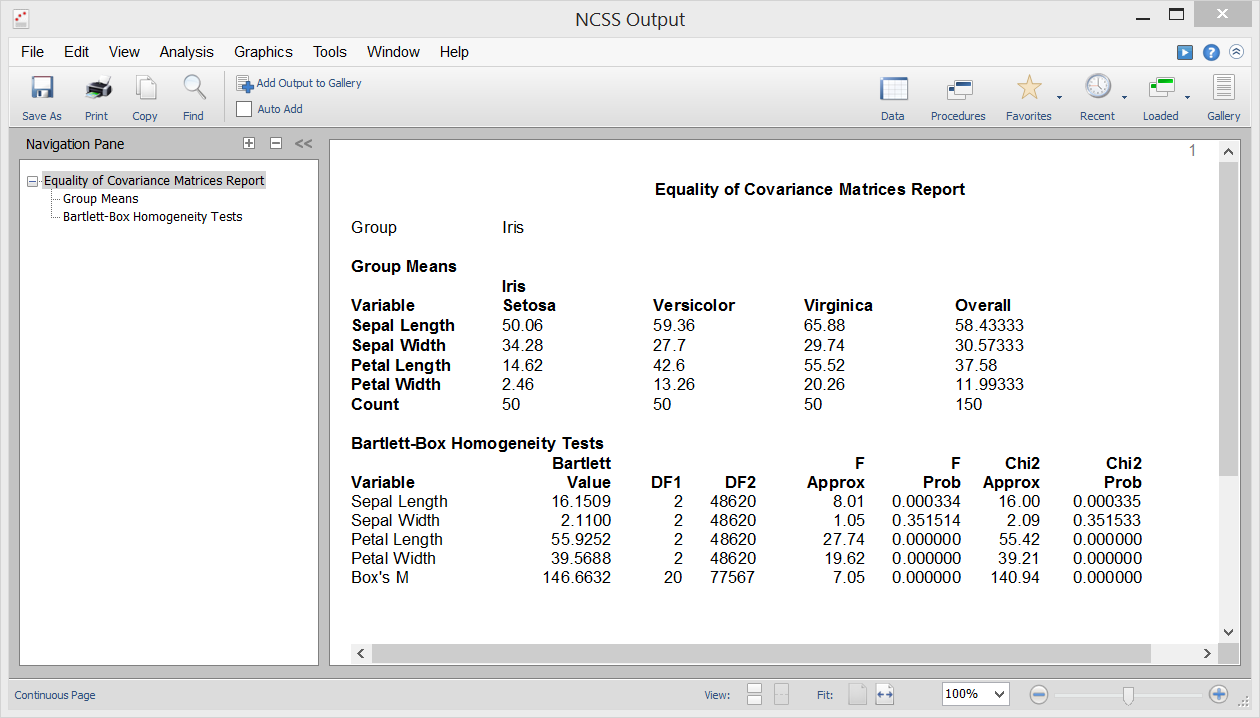
Uma das suposições da Análise Discriminatória, MANOVA, e vários outros procedimentos multivariados é que as matrizes de covariância de grupos individuais são iguais (ou seja, homogéneas entre grupos). O procedimento de Igualdade de Covariância no NCSS permite testar esta hipótese usando o teste M de Box, que foi apresentado pela primeira vez por Box (1949). Este procedimento também produz o teste univariado de homogeneidade de variância de Bartlett para testar a igualdade de variância entre variáveis individuais.
Saída de Amostra
Análise Discriminatória
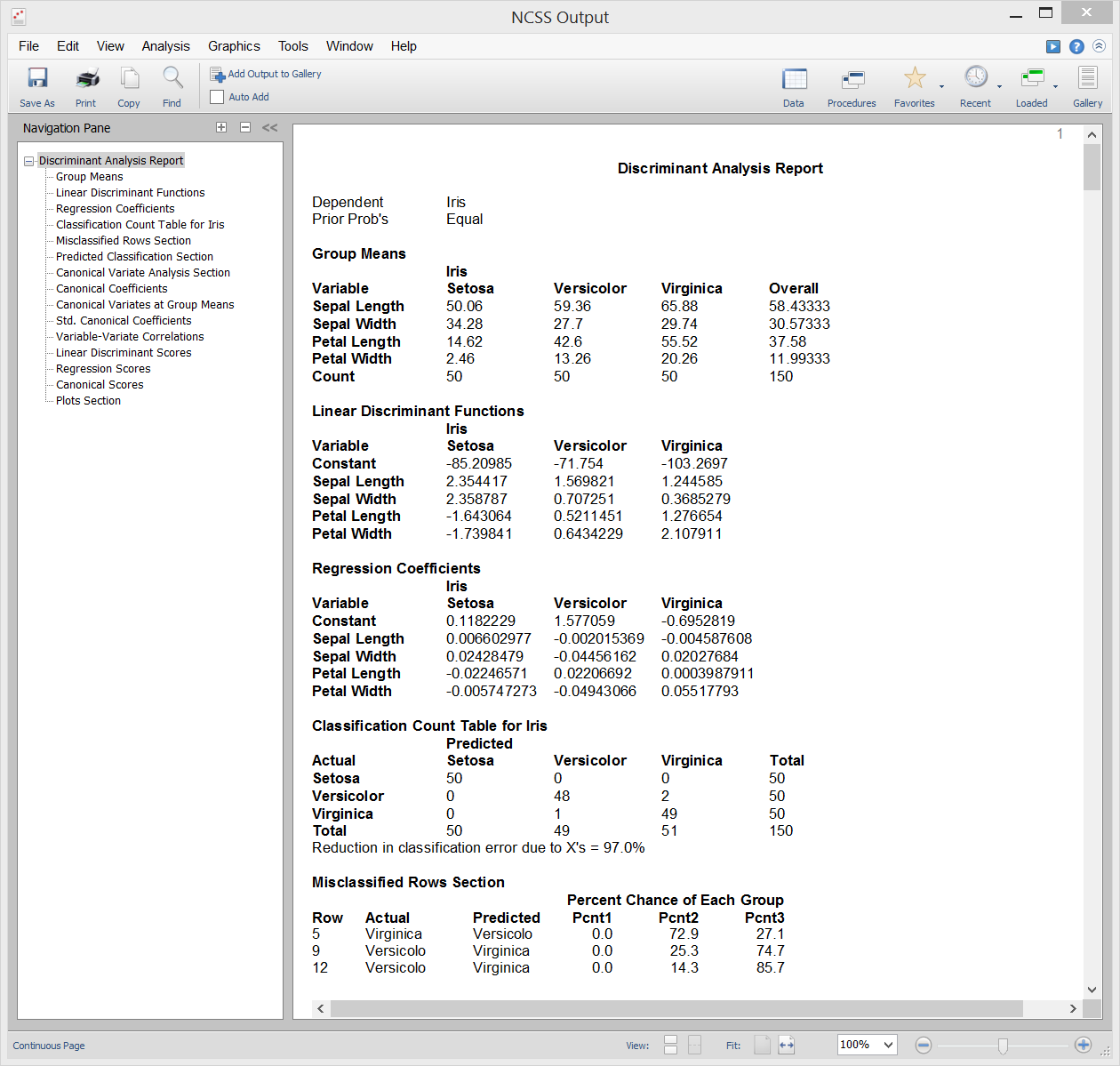
Análise Discriminatória é uma técnica utilizada para encontrar um conjunto de equações de previsão baseadas em uma ou mais variáveis independentes. Estas equações de previsão são então utilizadas para classificar os indivíduos em grupos. Há dois objectivos comuns na análise discriminante: 1. encontrar uma equação de previsão para classificar novos indivíduos, e 2. interpretar a equação de previsão para melhor compreender as relações entre as variáveis.
De muitas maneiras, a análise discriminante é muito semelhante à análise de regressão logística. A metodologia utilizada para completar uma análise discriminante é semelhante à análise de regressão logística. Traça-se frequentemente cada variável independente versus a variável de grupo, passa-se por uma fase de selecção de variáveis para determinar que variáveis independentes são benéficas, e realiza-se uma análise residual para determinar a exactidão das equações discriminantes.
Os cálculos na análise discriminante estão muito estreitamente relacionados com a MANOVA unidireccional. Na realidade, os papéis das variáveis são simplesmente invertidos. A variável de classificação (factor) na MANOVA torna-se a variável dependente na análise discriminante. As variáveis dependentes no MANOVA unidireccional tornam-se as variáveis independentes na análise discriminante.
Saída de amostra
Hotelling’s One-Sample T²
Hotelling’s One-Sample T² test is the multivariate extension of the common one-sample or parred Student’s T-test. Este teste é usado quando o número de variáveis de resposta é duas ou mais, embora possa ser usado quando existe apenas uma variável de resposta. O teste requer a suposição de que os dados são aproximadamente multivariados normais, embora sejam fornecidos testes de aleatorização que não se baseiam nesta suposição.
Saída de amostra

Hotelling’s Two-Sample T²
Hotelling’s Two-Sample T² test is the multivariate extension of the common two-sample Student’s T-test for difference in means. Este teste é utilizado quando o número de variáveis de resposta é de duas ou mais, embora possa ser utilizado quando existe apenas uma variável de resposta. O teste requer os pressupostos de variâncias iguais e resíduos normalmente distribuídos, embora sejam fornecidos testes de aleatorização que não se baseiam nestes pressupostos.
Saída de Amostra

Análise Multivariada de Variância (MANOVA)
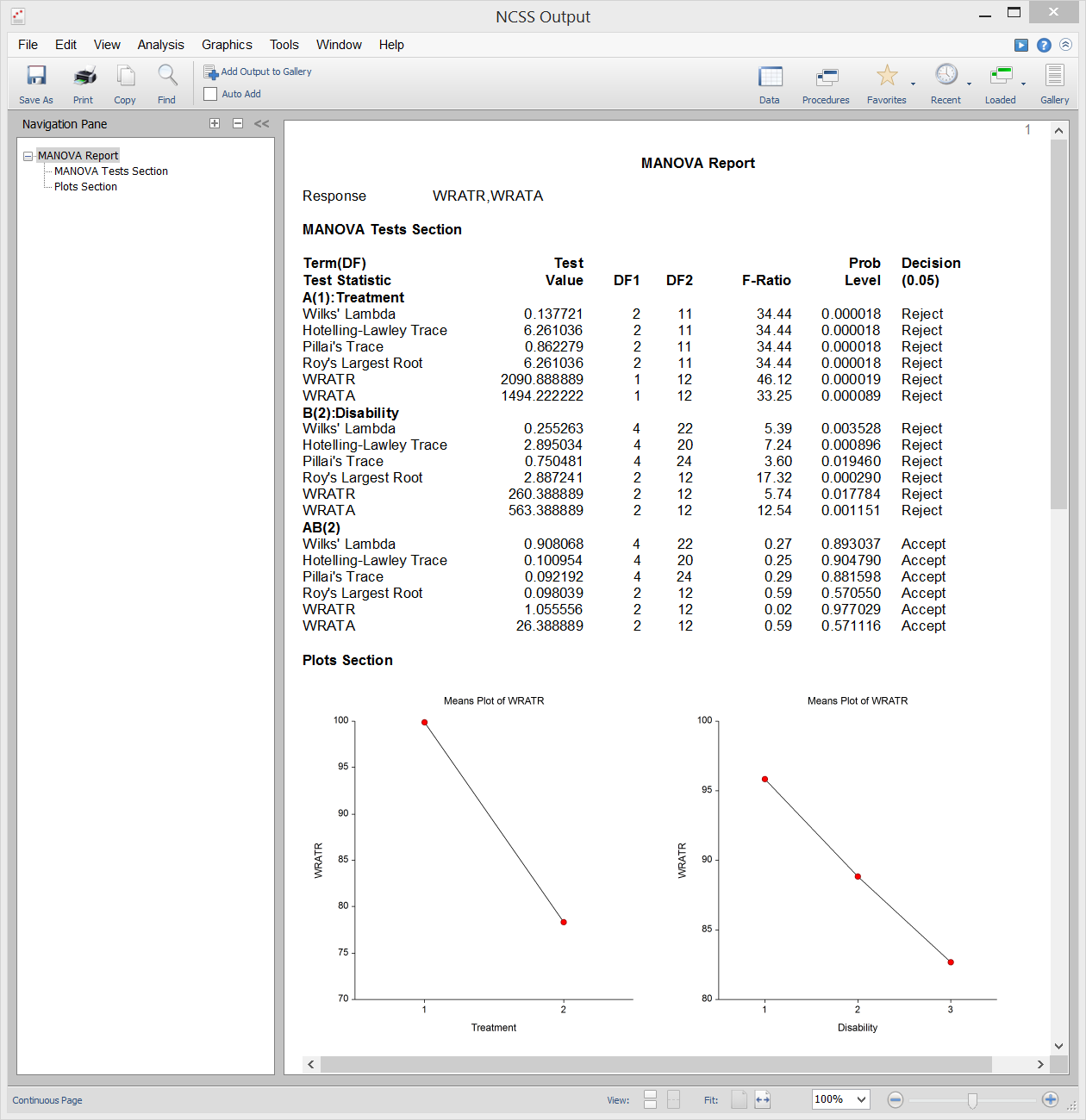
Análise Multivariada de Variância (ou MANOVA) é uma extensão da ANOVA ao caso em que existem duas ou mais variáveis de resposta. MANOVA é concebida para o caso em que se tem um ou mais factores independentes (cada um com dois ou mais níveis) e duas ou mais variáveis dependentes. Os testes de hipóteses envolvem a comparação de vectores de meios de grupo.
A extensão multivariada do teste F da ANOVA não é completamente directa. Em vez disso, várias outras estatísticas de teste estão disponíveis em MANOVA: Wilks’ Lambda, Hotelling-Lawley Trace, Pillai’s Trace, e Roy’s Largest Root. As distribuições reais destas estatísticas de teste são difíceis de calcular, por isso contamos com aproximações baseadas na distribuição F para calcular os valores p.
Saída de amostras
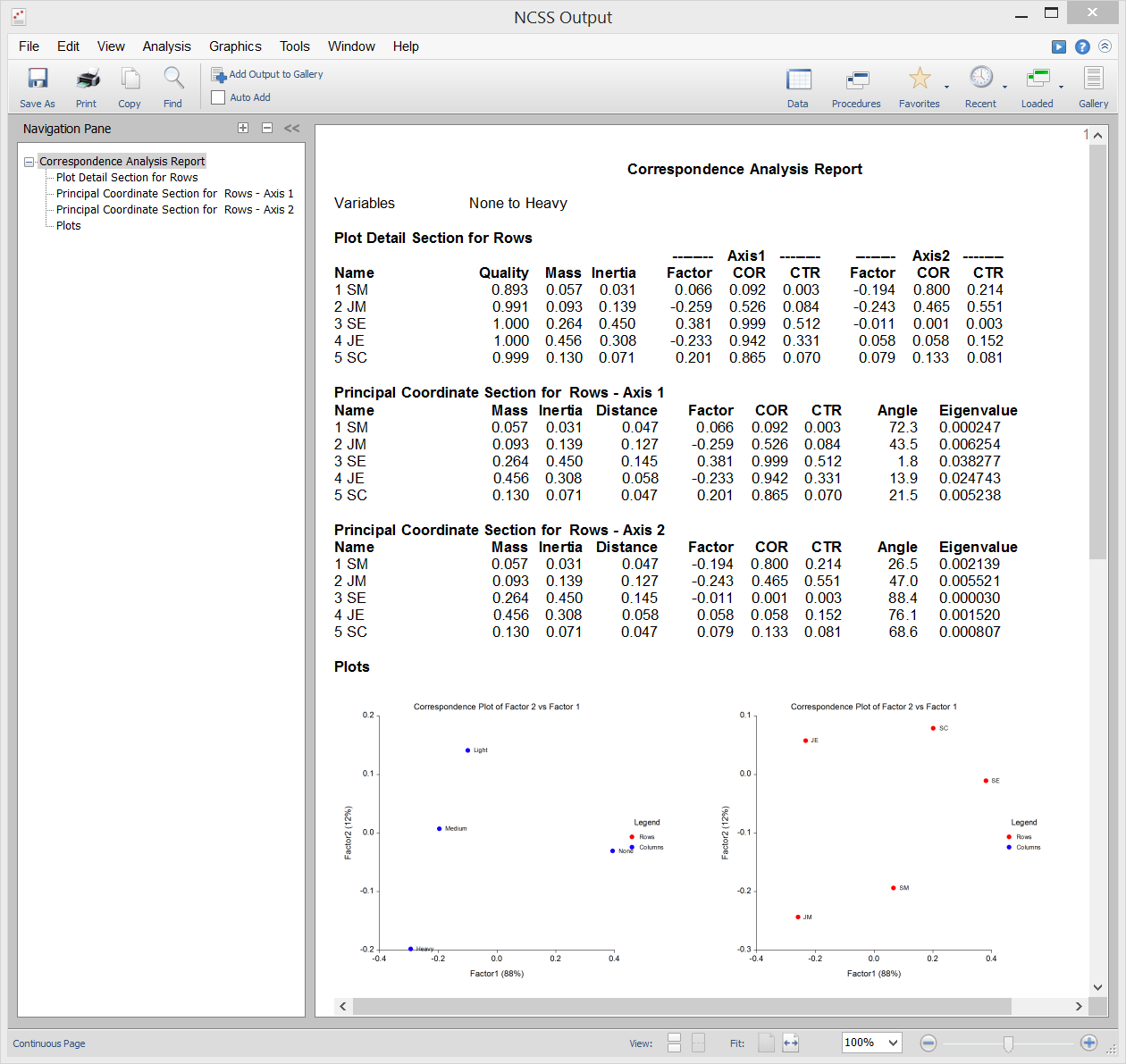
Análise de correspondência
Análise de correspondência (ou CA) é uma técnica para exibir graficamente uma tabela bidireccional de dados categóricos utilizando coordenadas calculadas representando as linhas e colunas da tabela. Estas coordenadas são análogas a factores numa análise de componentes principais (utilizadas para dados contínuos), excepto que dividem o valor Qui-quadrado utilizado para testar a independência em vez da variância total.
Saída de amostra
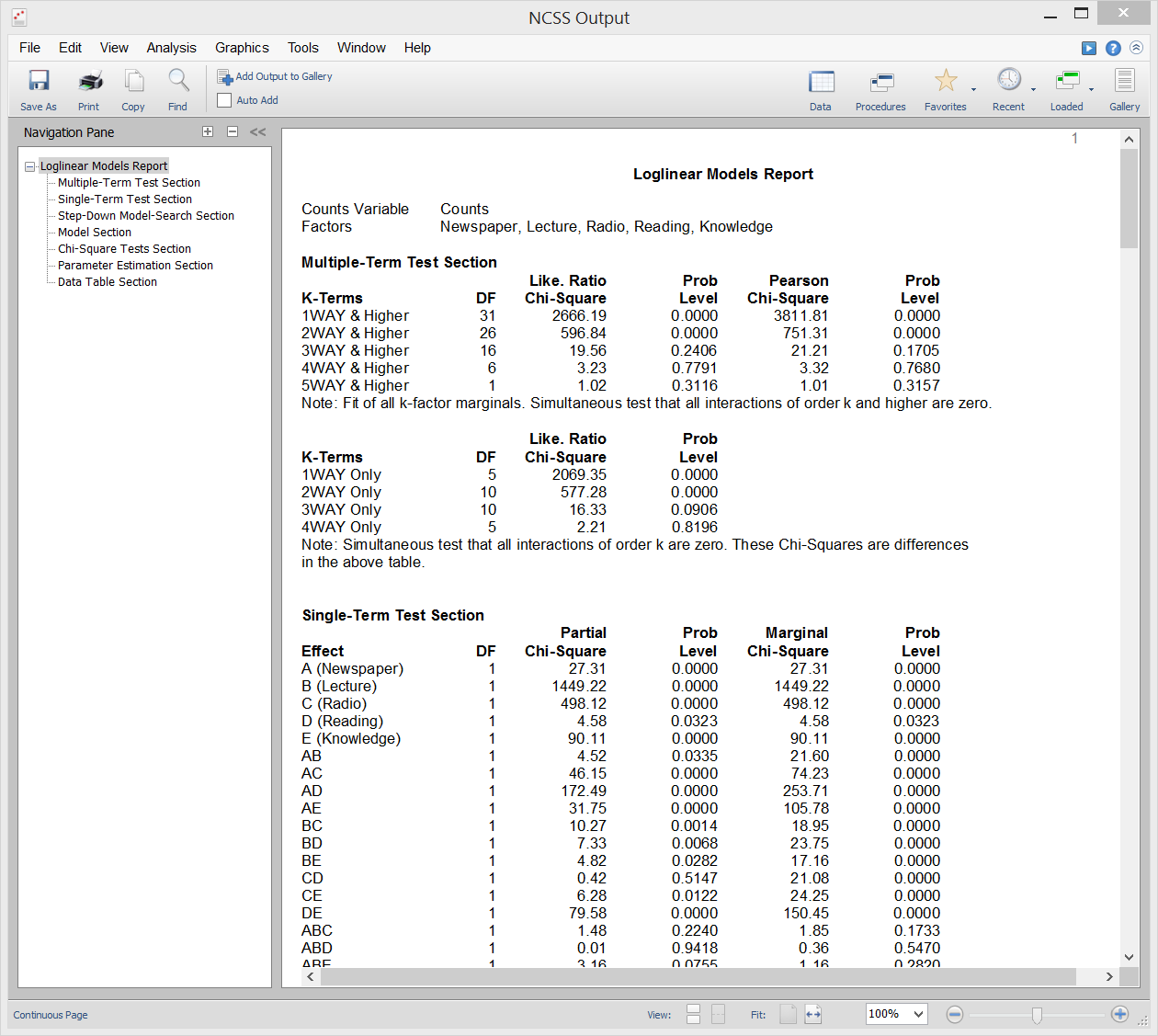
Modelos Loglinear
Modelos Loglinear (LLM) são utilizados para estudar as relações entre duas ou mais variáveis discretas. Muitas vezes referido como análise de frequência multidireccional, é uma extensão do teste qui-quadrado familiar para independência em tabelas de contingência bidireccionais.
LLLM pode ser utilizado para analisar inquéritos e questionários que têm inter-relações complexas entre as perguntas. Embora os questionários sejam frequentemente analisados considerando apenas duas perguntas de cada vez, isto ignora importantes relações de três vias (e multidireccionais) entre as perguntas. O uso de LLM neste tipo de dados é análogo ao uso de regressão múltipla em vez de simples correlações em dados contínuos.
Relatórios neste procedimento incluem relatórios multi-termo, relatórios de prazo único, relatórios qui-quadrados, relatórios modelo, relatórios de estimativa de parâmetros, e relatórios de tabela.
Saída de amostra
Escala Multidimensional
Escala Multidimensional (MDS) é uma técnica que cria um mapa que mostra as posições relativas de um número de objectos, dada apenas uma tabela das distâncias entre eles. O mapa pode consistir em uma, duas, três, ou mais dimensões. O procedimento calcula ou a métrica ou a solução não métrica. A tabela de distâncias é conhecida como a matriz de proximidade. Surge directamente de experiências ou indirectamente como uma matriz de correlação.
O programa oferece dois métodos gerais para resolver o problema do MDS. O primeiro chama-se Métrico, ou Clássico, Escala Multidimensional (CMDS) porque tenta reproduzir a métrica ou distâncias originais. O segundo método, chamado Escala Multidimensional Não-Métrica (NMMDS), assume que apenas as classificações das distâncias são conhecidas. Por conseguinte, este método produz um mapa que tenta reproduzir as classificações. As distâncias em si não são reproduzidas.