- li>04/29/2020
- 14 minutos para ler
- ul>
-
 c
c -
 M
M -
 D
D -
 B
B -
 v
v -
+13
/li>/li> p>p>Aplica a:![]() SQL Server (todas as versões suportadas)
SQL Server (todas as versões suportadas)
Este tópico introduz os conceitos de grupos de disponibilidade Always On que são centrais para configurar e gerir um ou mais grupos de disponibilidade no SQL Server. Para um resumo dos benefícios oferecidos pelos grupos de disponibilidade e uma visão geral da terminologia dos grupos de disponibilidade Always On, ver Always On Availability Groups (SQL Server).
Um grupo de disponibilidade suporta um ambiente replicado para um conjunto discreto de bases de dados de utilizadores, conhecido como bases de dados de disponibilidade. Pode-se criar um grupo de disponibilidade para alta disponibilidade (HA) ou para escala de leitura. Um grupo de disponibilidade de HA é um grupo de bases de dados que falham em conjunto. Um grupo de disponibilidade em escala de leitura é um grupo de bases de dados que são copiadas para outras instâncias do SQL Server para carga de trabalho só de leitura. Um grupo de disponibilidade suporta um conjunto de bases de dados primárias e um a oito conjuntos de bases de dados secundárias correspondentes. As bases de dados secundárias não são cópias de segurança. Continue a fazer cópias de segurança das suas bases de dados e dos respectivos registos de transacções numa base regular.
Tip
Pode criar qualquer tipo de cópia de segurança de uma base de dados primária. Em alternativa, pode criar cópias de segurança dos registos e cópias de segurança completas apenas de bases de dados secundárias. Para mais informações, ver Secundários Activos: Cópia de segurança em réplicas secundárias (sempre em grupos de disponibilidade).
Cada conjunto de base de dados de disponibilidade é alojado por uma réplica de disponibilidade. Existem dois tipos de réplicas de disponibilidade: uma única réplica primária. que hospeda as bases de dados primárias, e uma a oito réplicas secundárias, cada uma das quais hospeda um conjunto de bases de dados secundárias e serve como alvo potencial de falhas para o grupo de disponibilidade. Um grupo de disponibilidade falha ao nível de uma réplica de disponibilidade. Uma réplica de disponibilidade fornece redundância apenas ao nível da base de dados para o conjunto de bases de dados de um grupo de disponibilidade. As falhas não são causadas por problemas nas bases de dados, tais como uma base de dados tornar-se suspeita devido à perda de um ficheiro de dados ou corrupção de um registo de transacção.
A réplica primária torna as bases de dados primárias disponíveis para ligações de leitura-escrita dos clientes. A réplica primária envia os registos do diário de transacções de cada base de dados primária para cada base de dados secundária. Este processo – conhecido como sincronização de dados – ocorre ao nível da base de dados. Cada réplica secundária armazena os registos do diário de transacções (endurece o diário) e depois aplica-os à sua base de dados secundária correspondente. A sincronização de dados ocorre entre a base de dados primária e cada base de dados secundária ligada, independentemente das outras bases de dados. Portanto, uma base de dados secundária pode ser suspensa ou falhar sem afectar outras bases de dados secundárias, e uma base de dados primária pode ser suspensa ou falhar sem afectar outras bases de dados primárias.
Oficialmente, é possível configurar uma ou mais réplicas secundárias para suportar o acesso apenas de leitura a bases de dados secundárias, e é possível configurar qualquer réplica secundária para permitir cópias de segurança em bases de dados secundárias.
SQL Server 2017 introduz duas arquitecturas diferentes para grupos de disponibilidade. Os grupos de disponibilidade Always On fornecem alta disponibilidade, recuperação de desastres, e equilíbrio em escala de leitura. Estes grupos de disponibilidade requerem um gestor de cluster. No Windows, o clustering de failover fornece o gestor de cluster. No Linux, pode utilizar o Pacemaker. A outra arquitectura é um grupo de disponibilidade em escala de leitura. Um grupo de disponibilidade em escala de leitura fornece réplicas para cargas de trabalho apenas de leitura, mas não de alta disponibilidade. Num grupo de disponibilidade em escala de leitura não existe um gestor de cluster.
A implementação de grupos de disponibilidade Always On para HA no Windows requer um Cluster de Failover do Windows Server (WSFC). Cada réplica de disponibilidade de um determinado grupo de disponibilidade deve residir num nó diferente do mesmo WSFC. A única excepção é que ao ser migrado para outro WSFC cluster, um grupo de disponibilidade pode transitar temporariamente para dois clusters.
Nota
Para informações sobre grupos de disponibilidade no Linux, ver grupo de disponibilidade Always On para SQL Server no Linux.
Numa configuração HA, é criada uma função de cluster para cada grupo de disponibilidade que se cria. O cluster WSFC monitoriza esta função para avaliar a saúde da réplica primária. O quórum para grupos de disponibilidade Always On é baseado em todos os nós do cluster WSFC, independentemente de um dado nó de cluster hospedar ou não réplicas de disponibilidade. Em contraste com o espelhamento de bases de dados, não há papel de testemunha nos grupos de disponibilidade Always On.
Nota
Para informações sobre a relação dos componentes do SQL Server Always On com o cluster WSFC, ver Clustering do Windows Server Failover (WSFC) com SQL Server.
A ilustração seguinte mostra um grupo de disponibilidade que contém uma réplica primária e quatro réplicas secundárias. São suportadas até oito réplicas secundárias, incluindo uma réplica primária e duas réplicas secundárias síncronas.
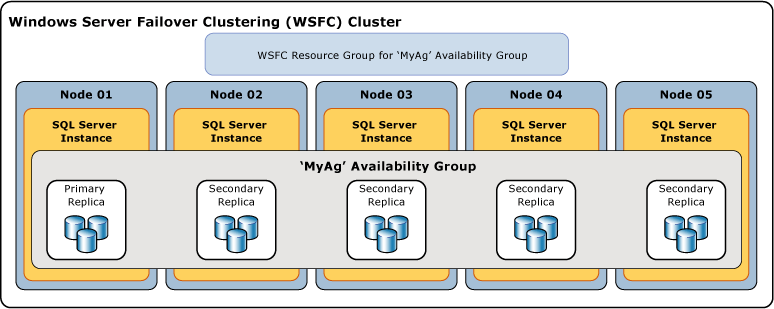
Bases de dados de disponibilidade
Para adicionar uma base de dados a um grupo de disponibilidade, a base de dados deve ser uma base de dados online, de leitura-escrita, existente na instância do servidor que aloja a réplica primária. Quando se adiciona uma base de dados, esta junta-se ao grupo de disponibilidade como uma base de dados primária, enquanto permanece disponível para os clientes. Não existe uma base de dados secundária correspondente até que as cópias de segurança da nova base de dados primária sejam restauradas na instância do servidor que aloja a réplica secundária (utilizando RESTORE COM A NORECOVERIA). A nova base de dados secundária está no estado de RESTORAÇÃO até que se junte ao grupo de disponibilidade. Para mais informações, ver Iniciar Movimento de Dados numa Base de Dados Secundária Sempre Em Funcionamento (SQL Server).
Joining coloca a base de dados secundária no estado ONLINE e inicia a sincronização de dados com a base de dados primária correspondente. A sincronização de dados é o processo pelo qual as alterações a uma base de dados primária são reproduzidas numa base de dados secundária. A sincronização de dados envolve o envio de registos de registo de transacções da base de dados primária para a base de dados secundária.
Important
Uma base de dados de disponibilidade é por vezes chamada uma réplica da base de dados em nomes Transact-SQL, PowerShell, e SQL Server Management Objects (SMO). Por exemplo, o termo “réplica de base de dados” é utilizado nos nomes das vistas de gestão dinâmica Always On que devolvem informações sobre bases de dados de disponibilidade: sys.dm_hadr_database_replica_estados e sys.dm_hadr_database_replica_estados. Contudo, no SQL Server Books Online, o termo “réplica” refere-se tipicamente a réplicas de disponibilidade. Por exemplo, “réplica primária” e “réplica secundária” referem-se sempre a réplicas de disponibilidade.
Réplicas de disponibilidade
Cada grupo de disponibilidade define um conjunto de dois ou mais parceiros de failover conhecidos como réplicas de disponibilidade. As réplicas de disponibilidade são componentes do grupo de disponibilidade. Cada réplica de disponibilidade hospeda uma cópia das bases de dados de disponibilidade no grupo de disponibilidade. Para um determinado grupo de disponibilidade, as réplicas de disponibilidade devem ser alojadas por instâncias separadas do SQL Server residentes em diferentes nós de um cluster WSFC. Cada uma destas instâncias do servidor deve ser activada para Always On.
Uma determinada instância pode alojar apenas uma réplica de disponibilidade por grupo de disponibilidade. No entanto, cada instância pode ser utilizada para muitos grupos de disponibilidade. Uma dada instância pode ser uma instância isolada ou uma instância de cluster de failover do SQL Server (FCI). Se necessitar de redundância a nível de servidor, utilize Instâncias de Cluster de Failover.
A cada réplica de disponibilidade é atribuída uma função inicial – a função primária ou a função secundária, que é herdada pelas bases de dados de disponibilidade dessa réplica. O papel de uma determinada réplica determina se ela hospeda bases de dados de leitura-escrita ou bases de dados só de leitura. A uma réplica, conhecida como réplica primária, é atribuído o papel primário e hospeda bases de dados de leitura-escrita, que são conhecidas como bases de dados primárias. Pelo menos a uma outra réplica, conhecida como réplica secundária, é atribuída a função secundária. Uma réplica secundária hospeda bases de dados só de leitura, conhecidas como bases de dados secundárias.
Nota
Quando o papel de uma réplica disponível é indeterminado, tal como durante uma falha, as suas bases de dados estão temporariamente num estado NÃO SINCRONIZADOR. O seu papel está definido para RESOLVER até que o papel da réplica de disponibilidade tenha sido resolvido. Se uma réplica de disponibilidade resolver o seu papel primário, as suas bases de dados tornam-se as bases de dados primárias. Se uma réplica de disponibilidade se resolver ao papel secundário, as suas bases de dados tornam-se bases de dados secundárias.
Modos de disponibilidade
O modo de disponibilidade é uma propriedade de cada réplica de disponibilidade. O modo de disponibilidade determina se a réplica primária espera para cometer transacções numa base de dados até que uma determinada réplica secundária tenha escrito os registos do diário de transacções no disco (endureceu o diário). Sempre em grupos de disponibilidade suporta dois modos de disponibilidade – modo de compromisso assíncrono e modo de compromisso síncrono.
-
modo de compromisso assíncrono
Uma réplica de disponibilidade que usa este modo de disponibilidade é conhecida como réplica de compromisso assíncrono. No modo assíncrono-commit, a réplica primária efectua transacções sem esperar pelo reconhecimento de que uma réplica secundária assíncrono-commit endureceu o registo. O modo assíncrono-commit minimiza a latência das transacções nas bases de dados secundárias mas permite que estas fiquem atrás das bases de dados primárias, tornando possível alguma perda de dados.
-
Modo assíncrono-commit
Uma réplica de disponibilidade que utiliza este modo de disponibilidade é conhecida como réplica síncrono-commit. Em modo síncrono-commit, antes de submeter transacções, uma réplica síncrono-commit primária espera por uma réplica síncrono-commit secundária para reconhecer que terminou de endurecer o registo. O modo Synchronous-commit assegura que, uma vez sincronizada uma dada base de dados secundária com a base de dados primária, as transacções comprometidas são totalmente protegidas. Esta protecção vem ao custo do aumento da latência das transacções.
Para mais informações, ver Modos de Disponibilidade (Always On Availability Groups).
Tipos de failover
No contexto de uma sessão entre a réplica primária e uma réplica secundária, as funções primária e secundária são potencialmente permutáveis num processo conhecido como failover. Durante um failover, a réplica secundária alvo transita para o papel primário, tornando-se a nova réplica primária. A nova réplica primária coloca as suas bases de dados em linha como as bases de dados primárias, e as aplicações clientes podem ligar-se a elas. Quando a antiga réplica primária está disponível, ela transita para o papel secundário, tornando-se uma réplica secundária. As antigas bases de dados primárias tornam-se bases de dados secundárias e a sincronização de dados é retomada.
Três formas de failover exist-automático, manual, e forçado (com possível perda de dados). A forma ou formas de failover suportadas por uma determinada réplica secundária depende do seu modo de disponibilidade, e, para o modo de autorização síncrona, do modo de failover na réplica primária e na réplica secundária alvo, como se segue.
-
modo de autorização síncrona suporta duas formas de failover manual planeado e automático, se a réplica secundária alvo estiver actualmente sincronizada com a réplica primária. O suporte para estas formas de failover depende da definição da propriedade do modo de failover nos parceiros de failover. Se o modo de failover estiver definido para “manual” na réplica primária ou secundária, apenas o failover manual é suportado para essa réplica secundária. Se o modo de failover estiver definido para “automático” tanto na réplica primária como na secundária, tanto o failover automático como o manual são suportados nessa réplica secundária.
-
failover manual planeado (sem perda de dados)
Um failover manual ocorre após um administrador de base de dados emitir um comando de failover e faz com que uma réplica secundária sincronizada faça a transição para a função primária (com protecção de dados garantida) e a réplica primária faça a transição para a função secundária. Um failover manual requer que tanto a réplica primária como a réplica secundária alvo estejam a correr em modo de autorização síncrona, e a réplica secundária já deve estar sincronizada.
-
Failover automático (sem perda de dados)
Ocorre um failover automático em resposta a uma falha que provoca a transição de uma réplica secundária sincronizada para a função primária (com garantia de protecção de dados). Quando a primeira réplica primária se torna disponível, transita para a função secundária. O failover automático requer que tanto a réplica primária como a réplica secundária alvo estejam a funcionar em modo de compromisso sincronizado com o modo de failover definido para “Automático”. Além disso, a réplica secundária já deve estar sincronizada, ter quórum WSFC, e satisfazer as condições especificadas pela política flexível de failover do grupo de disponibilidade.
Important
SQL Server Failover Cluster Instances (FCIs) não suportam o failover automático por grupos de disponibilidade, pelo que qualquer réplica de disponibilidade hospedada por um FCI só pode ser configurada para failover manual.
Nota
Nota que se emitir um comando de failover forçado numa réplica secundária sincronizada, a réplica secundária comporta-se da mesma forma que para um failover manual planeado.
-
- p>>a>a em modo assíncrono de compromisso, a única forma de failover é o failover manual forçado (com possível perda de dados), normalmente chamado failover forçado. O failover forçado é considerado uma forma de failover manual porque só pode ser iniciado manualmente. O failover forçado é uma opção de recuperação de desastres. É a única forma de failover possível quando a réplica secundária alvo não está sincronizada com a réplica primária.
Para mais informações, ver Modos de Failover e Failover (Always On Availability Groups).
Conexões do cliente
Pode fornecer conectividade do cliente à réplica primária de um dado grupo de disponibilidade, criando um ouvinte do grupo de disponibilidade. Um ouvinte do grupo de disponibilidade fornece um conjunto de recursos que está ligado a um determinado grupo de disponibilidade para dirigir as ligações do cliente à réplica de disponibilidade apropriada.
Um ouvinte do grupo de disponibilidade está associado a um nome DNS único que serve como nome de rede virtual (VNN), um ou mais endereços IP virtuais (VIPs), e um número de porta TCP. Para mais informações, ver Ouvintes do Grupo de Disponibilidade, Conectividade do Cliente, e Failover da Aplicação (SQL Server).
Tip
Se um grupo de disponibilidade possuir apenas duas réplicas de disponibilidade e não estiver configurado para permitir o acesso de leitura à réplica secundária, os clientes podem ligar-se à réplica primária utilizando uma cadeia de ligação espelhada de base de dados. Esta abordagem pode ser útil temporariamente depois de se migrar uma base de dados do espelhamento de bases de dados para grupos de disponibilidade Always On. Antes de adicionar réplicas secundárias adicionais, terá de criar um grupo de disponibilidade de ouvinte o grupo de disponibilidade e actualizar as suas aplicações para usar o nome da rede do ouvinte.
Réplicas secundárias activas
Always On availability groups suporta réplicas secundárias activas. As capacidades secundárias activas incluem suporte para:
-
Realizar operações de backup em réplicas secundárias
As réplicas secundárias suportam a realização de backups de registo e backups apenas de cópia de uma base de dados completa, ficheiro, ou grupo fileg. É possível configurar o grupo de disponibilidade para especificar a preferência para onde as cópias de segurança devem ser realizadas. É importante compreender que a preferência não é aplicada pelo SQL Server, pelo que não tem impacto sobre as cópias de segurança ad-hoc. A interpretação desta preferência depende da lógica, caso exista, de que se escreva nos seus trabalhos de backup para cada uma das bases de dados de um dado grupo de disponibilidade. Para uma réplica de disponibilidade individual, pode especificar a sua prioridade para efectuar cópias de segurança nesta réplica em relação às outras réplicas do mesmo grupo de disponibilidade. Para mais informações, ver Secundários Activos: Backup em réplicas secundárias (Sempre em Grupos de Disponibilidade).
-
Acesso apenas de leitura a uma ou mais réplicas secundárias (réplicas secundárias legíveis)
Ainda réplica de disponibilidade secundária pode ser configurada para permitir apenas acesso apenas de leitura às suas bases de dados locais, embora algumas operações não sejam totalmente suportadas. Isto impedirá tentativas de ligação só de leitura-escrita à réplica secundária. Também é possível evitar cargas de trabalho apenas de leitura na réplica primária, permitindo apenas o acesso de leitura-escrita. Isto evitará que sejam feitas ligações só de leitura à réplica primária. Para mais informações, ver Secundários Activos: Réplicas secundárias legíveis (Always On Availability Groups).
Se um grupo de disponibilidade possuir actualmente um ouvinte de grupo de disponibilidade e uma ou mais réplicas secundárias legíveis, o SQL Server pode encaminhar pedidos de ligação só de leitura para uma delas (encaminhamento só de leitura). Para mais informações, ver Ouvintes do Grupo de Disponibilidade, Conectividade do Cliente, e Failover da Aplicação (SQL Server).
Período de tempo limite da sessão
O período de tempo limite da sessão é uma propriedade de disponibilidade-replicativa que determina quanto tempo a ligação com outra réplica de disponibilidade pode permanecer inactiva antes de a ligação ser fechada. As réplicas primárias e secundárias ligam-se umas às outras para sinalizar que ainda estão activas. A recepção de um ping da outra réplica durante o período de timeout indica que a ligação ainda está aberta e que as instâncias do servidor estão a comunicar. Ao receber um ping, uma réplica disponível repõe o seu contador de tempo limite de sessão nessa ligação.
O período de tempo limite de sessão evita que uma réplica espere indefinidamente para receber um ping da outra réplica. Se não for recebido nenhum ping da outra réplica dentro do período de tempo limite de sessão, o tempo limite de sessão da réplica termina. A sua ligação é fechada, e a réplica com tempo limite entra no estado DISCONNECTED. Mesmo que uma réplica desconectada esteja configurada para o modo de compromisso síncrono, as transacções não irão esperar que essa réplica volte a ligar-se e a ressincronizar.
O período padrão de tempo limite de sessão para cada réplica disponível é de 10 segundos. Este valor é configurável pelo utilizador, com um mínimo de 5 segundos. Geralmente, recomendamos que se mantenha o período de tempo limite em 10 segundos ou mais. Definir o valor para menos de 10 segundos cria a possibilidade de um sistema fortemente carregado declarar uma falsa falha.
Nota
Na função de resolução, o período de tempo limite de sessão não se aplica porque o pinging não ocorre.
Reparação automática da página
Cada réplica de disponibilidade tenta recuperar automaticamente de páginas corrompidas numa base de dados local, resolvendo certos tipos de erros que impedem a leitura de uma página de dados. Se uma réplica secundária não conseguir ler uma página, a réplica solicita uma nova cópia da página da réplica primária. Se a réplica primária não conseguir ler uma página, a réplica transmite um pedido de uma cópia nova a todas as réplicas secundárias e recebe a página da primeira a responder. Se este pedido tiver êxito, a página ilegível é substituída pela cópia, o que normalmente resolve o erro.
Para mais informações, ver Reparação Automática de Página (Grupos de Disponibilidade: Espelhamento de Base de Dados).
Tarefas relacionadas
- li>A começar com Grupos Sempre Disponíveis (SQL Server)
Conteúdo relacionado
-
Blogs:
Sempre Ligado – Série de Aprendizagem HADRON: Utilização de Worker Pool para bases de dados HADRON Enabled Databases
Servidor deSQL Always On Team Blogs: O Blog oficial do SQL Server Always On Team
CSS SQL Server Engineers Blogs
-
Videos:
Microsoft SQL Server Code-Named “Denali” Always On Series,Part 1: Introduzindo a Próxima Geração de Solução de Alta Disponibilidade
Código do SQL Server da Microsoft – denominado “Denali” Always On Series,Parte 2: Construindo uma Solução de Missão-Crítica de Alta Disponibilidade Usando Always On
-
Whitepapers:
Microsoft SQL Server Always On Solutions Guide for High Availability and Disaster Recovery
Microsoft White Papers for SQL Server 2012
SQL Server Customer Advisory Team Whitepapers
Ver Também
Modos de Disponibilidade (Sempre em Grupos de Disponibilidade)
Modos de Falha e Falha (Sempre em Grupos de Disponibilidade)
Visualização de Transact-Declarações SQL para Grupos Sempre Em Disponibilidade (SQL Server)
Visão geral do PowerShell Cmdlets para Grupos Sempre Em Disponibilidade (SQL Server)
Suporte de Alta Disponibilidade para bases de dados In-Memory OLTP
Prerequisitos, Restrições, e Recomendações para Grupos Sempre Disponíveis (SQL Server)
Criação e Configuração de Grupos Disponíveis (SQL Server)
Active Secondaries: Réplicas secundárias legíveis (Always On Availability Groups)
Active Secondaries: Cópia de segurança em réplicas secundárias (Always On Availability Groups)
Availability Group Listeners, Client Connectivity, and Application Failover (SQL Server)