Estatisticas SPSS
Interpretando e Reportando a Saída de uma Análise de Regressão Logística Binomial
As Estatísticas SPSS geram muitas tabelas de saída quando se realiza uma regressão logística binomial. Nesta secção, mostramos apenas as três tabelas principais necessárias para compreender os seus resultados do procedimento de regressão logística binomial, assumindo que não foram violados quaisquer pressupostos. Uma explicação completa dos resultados que tem de interpretar ao verificar os seus dados para as suposições necessárias à realização da regressão logística binomial é fornecida no nosso guia melhorado.
No entanto, neste guia de “início rápido”, concentramo-nos apenas nas três tabelas principais de que necessita para compreender os resultados da sua regressão logística binomial, assumindo que os seus dados já cumpriram as suposições necessárias para a regressão logística binomial para lhe dar um resultado válido:
Variância explicada
Para compreender quanta variação na variável dependente pode ser explicada pelo modelo (o equivalente de R2 em regressão múltipla), pode consultar a tabela abaixo, “Resumo do Modelo”:
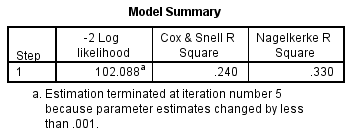
Esta tabela contém os valores Cox & Snell R Square e Nagelkerke R Square, que são ambos métodos de cálculo da variação explicada. Estes valores são por vezes referidos como valores pseudo R2 (e terão valores mais baixos do que em regressão múltipla). No entanto, são interpretados da mesma forma, mas com mais cautela. Portanto, a variação explicada na variável dependente baseada no nosso modelo varia de 24,0% a 33,0%, dependendo se se faz referência aos métodos Cox & Snell R2 ou Nagelkerke R2, respectivamente. Nagelkerke R2 é uma modificação de Cox & Snell R2, o último dos quais não pode atingir um valor de 1. Por esta razão, é preferível reportar o valor Nagelkerke R2.
Previsão da categoria
Regressão logística binomial estima a probabilidade de ocorrência de um evento (neste caso, com doença cardíaca). Se a probabilidade estimada de ocorrência do evento for maior ou igual a 0,5 (melhor que o acaso), as Estatísticas SPSS classificam o evento como tendo ocorrido (por exemplo, doença cardíaca presente). Se a probabilidade for inferior a 0,5, as Estatísticas SPSS classificam o evento como não ocorrendo (p. ex., sem doença cardíaca). É muito comum utilizar a regressão logística binomial para prever se os casos podem ser correctamente classificados (ou seja, previstos) a partir das variáveis independentes. Portanto, torna-se necessário ter um método para avaliar a eficácia da classificação prevista em comparação com a classificação real. Há muitos métodos para avaliar isto com a sua utilidade, muitas vezes dependendo da natureza do estudo realizado. No entanto, todos os métodos giram em torno das classificações observadas e previstas, que são apresentadas na “Tabela de Classificação”, como mostrado abaixo:
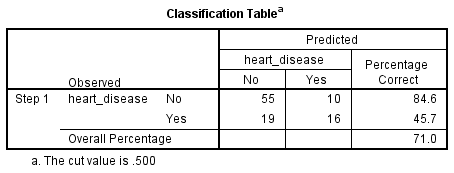
P>Primeiro, repare que a tabela tem um subscrito que diz: “O valor de corte é .500”. Isto significa que se a probabilidade de um caso ser classificado na categoria “sim” for superior a .500, então esse caso específico é classificado na categoria “sim”. Caso contrário, o caso é classificado como na categoria “não” (como mencionado anteriormente). Embora a tabela de classificação pareça ser muito simples, ela fornece na realidade muitas informações importantes sobre o resultado da sua regressão logística binomial, incluindo:
- A. A percentagem de precisão na classificação (PAC), que reflecte a percentagem de casos que podem ser correctamente classificados como “não” com as variáveis independentes adicionadas (não apenas o modelo global).
- B. Sensibilidade, que é a percentagem de casos que tinham a característica observada (por exemplo “sim” para doença cardíaca) que foram correctamente previstos pelo modelo (ou seja, verdadeiros positivos).
- C. Especificidade, que é a percentagem de casos que não tinham a característica observada (por exemplo, “não” para doença cardíaca) e que também foram correctamente previstos como não tendo a característica observada (ou seja verdadeiros negativos).
- D. O valor preditivo positivo, que é a percentagem de casos correctamente previstos “com” a característica observada, em comparação com o número total de casos previstos como tendo a característica.
- E. O valor preditivo negativo, que é a percentagem de casos correctamente previstos “sem” a característica observada, em comparação com o número total de casos previstos como não tendo a característica.
Se não tiver a certeza de como interpretar o CAP, sensibilidade, especificidade, valor preditivo positivo e valor preditivo negativo da “Tabela de Classificação”, explicamos como no nosso guia de regressão logística binomial melhorada.
Variáveis na equação
A tabela “Variáveis na Equação” mostra a contribuição de cada variável independente para o modelo e o seu significado estatístico. Esta tabela é mostrada abaixo:
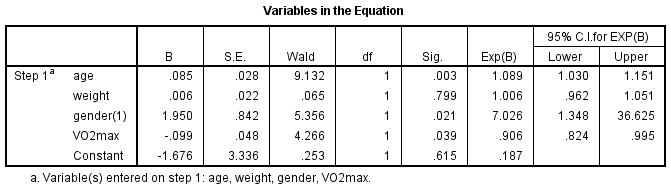
O teste de Wald (coluna “Wald”) é utilizado para determinar a significância estatística para cada uma das variáveis independentes. A significância estatística do teste é encontrada na coluna “Sig. A partir destes resultados pode-se ver que idade (p = .003), sexo (p = .021) e VO2max (p = .039) acrescentados significativamente ao modelo/previsão, mas o peso (p = .799) não acrescentou significativamente ao modelo. Pode-se usar a informação da tabela “Variáveis na Equação” para prever a probabilidade de um evento ocorrer com base numa mudança de uma unidade numa variável independente quando todas as outras variáveis independentes são mantidas constantes. Por exemplo, a tabela mostra que a probabilidade de ter doenças cardíacas (categoria “sim”) é 7,026 vezes maior para os homens do que para as mulheres. Se não tiver a certeza de como utilizar os rácios de probabilidade para fazer previsões, conheça os nossos guias melhorados sobre as nossas Características: Página de resumo.
Pondo tudo junto
Com base nos resultados acima, poderíamos relatar os resultados do estudo da seguinte forma (N.B., isto não inclui os resultados dos seus testes de hipóteses):
- Geral
Foi realizada uma regressão logística para verificar os efeitos da idade, peso, sexo e VO2max na probabilidade de os participantes terem doenças cardíacas. O modelo de regressão logística foi estatisticamente significativo, χ2(4) = 27.402, p < .0005. O modelo explicou 33,0% (Nagelkerke R2) da variância em doença cardíaca e classificou correctamente 71,0% dos casos. Os homens eram 7,02 vezes mais propensos a apresentar doenças cardíacas do que as mulheres. O aumento da idade estava associado a um aumento da probabilidade de exibir doença cardíaca, mas o aumento do VO2max estava associado a uma redução na probabilidade de exibir doença cardíaca.
Além da escrita acima, deve também incluir: (a) os resultados dos testes de hipóteses que realizou; (b) os resultados da “Tabela de Classificação”, incluindo sensibilidade, especificidade, valor preditivo positivo e valor preditivo negativo; e (c) os resultados da tabela “Variáveis da Equação”, incluindo quais das variáveis preditoras foram estatisticamente significativas e quais as previsões que podem ser feitas com base na utilização de odds ratios. Se não tiver a certeza de como o fazer, mostramos-lhe no nosso guia melhorado de regressão logística binomial. Também lhe mostramos como escrever os resultados dos seus testes de suposições e do resultado da regressão logística binomial se precisar de relatar isto numa dissertação/téese, atribuição ou relatório de investigação. Fazemo-lo utilizando os estilos de Harvard e APA. Pode saber mais sobre o nosso conteúdo melhorado nas nossas Características: Página de resumo.