NCSS incluye una serie de herramientas para el análisis multivariante, el análisis de datos con más de una variable dependiente o Y. El análisis factorial, el análisis de componentes principales (PCA) y el análisis multivariante de la varianza (MANOVA) son técnicas de análisis multivariante muy conocidas y todas ellas están disponibles en NCSS, junto con otros procedimientos de análisis multivariante que se describen a continuación.
Utilice los enlaces que aparecen a continuación para ir al tema de análisis multivariante que desee examinar. Para ver cómo estas herramientas pueden beneficiarle, le recomendamos que descargue e instale la prueba gratuita de NCSS.
Salte a:
- Introducción
- Detalles técnicos
- Análisis de factores
- Análisis de componentes principales (ACP)
- Correlación canónica
- Igualdad de covarianza
- Análisis discriminante
- Asimismo, el análisis de unaMuestra T²
- Asimismo, la muestra de dos de HotellingMuestra T²
- Análisis Multivariante de la Varianza (MANOVA)
- Análisis de Correspondencia
- Modelos Log-lineales
- Escalado Multidimensional
Introducción
Aunque el término Análisis Multivariante se puede utilizar para referirse a cualquier análisis que implique más de una variable (e.p. ej. en Regresión Múltiple o GLM ANOVA), el término análisis multivariante se utiliza aquí y en NCSS para referirse a situaciones que implican datos multidimensionales con más de una variable dependiente, Y, o de resultado. Las técnicas de análisis multivariante se utilizan para entender cómo el conjunto de variables de resultado como un todo combinado están influenciadas por otros factores, cómo las variables de resultado se relacionan entre sí, o qué factores subyacentes producen los resultados observados en las variables dependientes.
A continuación se describe cada uno de los procedimientos disponibles en la sección de Análisis Multivariante de NCSS.
Detalles técnicos
Esta página está diseñada para dar una visión general de las capacidades de NCSS para las técnicas de análisis multivariante. Si desea examinar las fórmulas y los detalles técnicos relativos a un procedimiento específico de NCSS, haga clic en el enlace » correspondiente debajo de cada título para cargar la documentación completa del procedimiento. Allí encontrará fórmulas, referencias, discusiones y ejemplos o tutoriales que describen el procedimiento en detalle.
Análisis Factorial
El Análisis Factorial (AF) es una técnica exploratoria aplicada a un conjunto de variables de resultado que busca encontrar los factores subyacentes (o subconjuntos de variables) a partir de los cuales se generaron las variables observadas. Por ejemplo, la respuesta de un individuo a las preguntas de un examen está influida por variables subyacentes como la inteligencia, los años de estudio, la edad, el estado emocional el día del examen, la cantidad de práctica en la realización de exámenes, etc. Las respuestas a las preguntas son las variables observadas o de resultado. Las variables subyacentes e influyentes son los factores.
El análisis factorial se realiza sobre la matriz de correlación de las variables observadas. Un factor es una media ponderada de las variables originales. El analista de factores espera encontrar unos cuantos factores a partir de los cuales se pueda generar la matriz de correlación original.
El objetivo del análisis de factores suele ser ayudar a la interpretación de los datos. El analista de factores espera identificar cada factor como representación de un factor teórico específico. Otro objetivo del análisis factorial es reducir el número de variables. El analista espera reducir la interpretación de una prueba de 200 preguntas al estudio de 4 o 5 factores.
El NCSS proporciona el método del eje principal del análisis factorial. Los resultados pueden rotarse utilizando la rotación varimax o quartimax y las puntuaciones de los factores pueden almacenarse para su posterior análisis. A continuación se muestran los datos de muestra, la entrada del procedimiento y la salida.
Datos de la muestra
Entrada del procedimiento
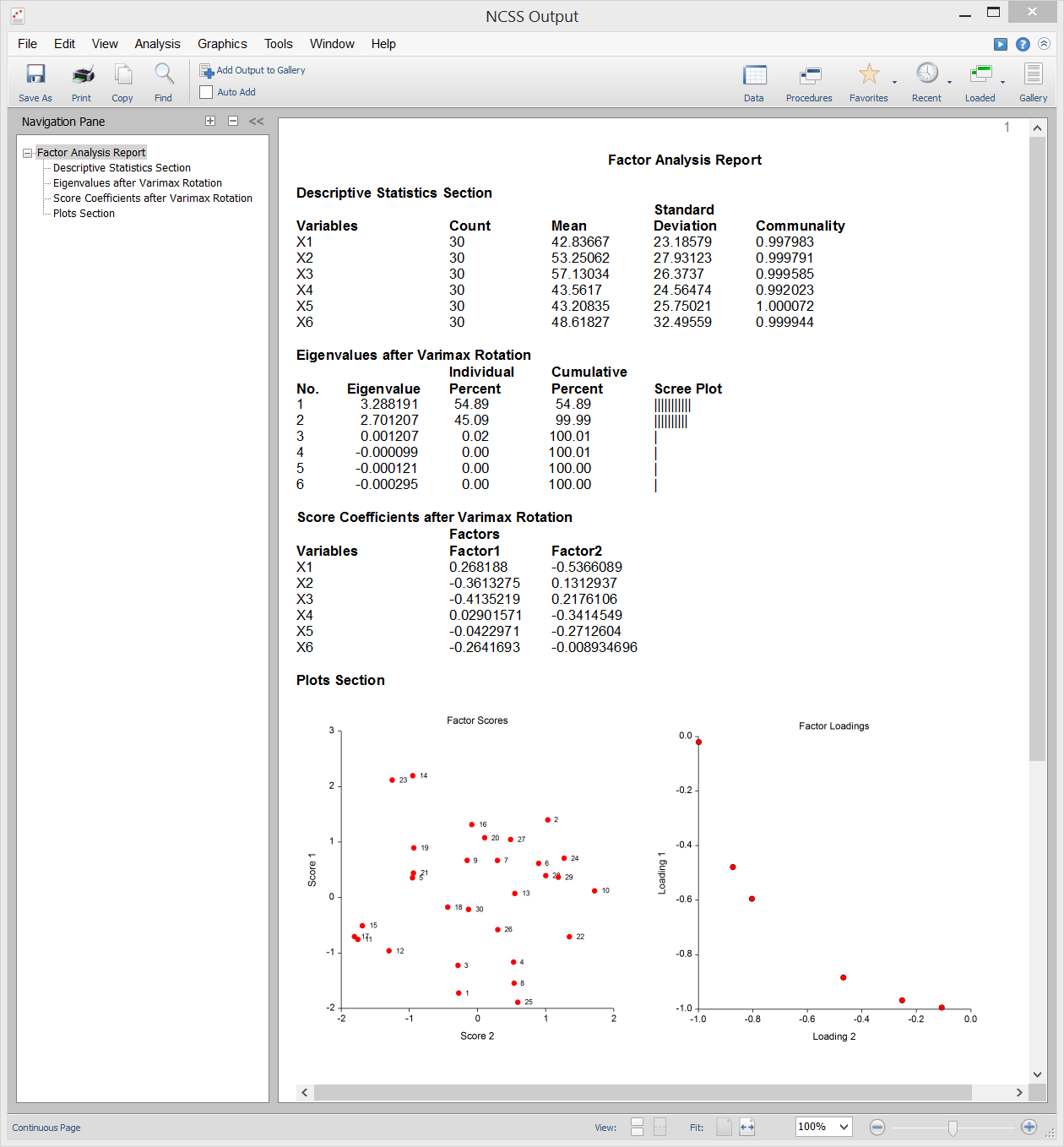
Muestra de salida
Análisis de componentes principales (PCA)
El análisis de componentes principales (o PCA) es una herramienta de análisis de datos que se suele utilizar para reducir la dimensionalidad (o número de variables) de un gran número de variables interrelacionadas, conservando la mayor cantidad de información (por ejemplo, la variación).por ejemplo, la variación) como sea posible. El ACP calcula un conjunto no correlacionado de variables conocidas como factores o componentes principales. Estos factores se ordenan de forma que los primeros retengan la mayor parte de la variación presente en todas las variables originales. A diferencia de su primo el Análisis Factorial, el PCA siempre produce la misma solución a partir de los mismos datos.
El NCSS utiliza una versión de doble precisión del moderno algoritmo QL descrito por Press (1986) para resolver el problema de valores propios y vectores propios que conlleva el cálculo del PCA. NCSS realiza el ACP sobre una matriz de correlación o de covarianza. El análisis puede llevarse a cabo utilizando técnicas de estimación robustas.
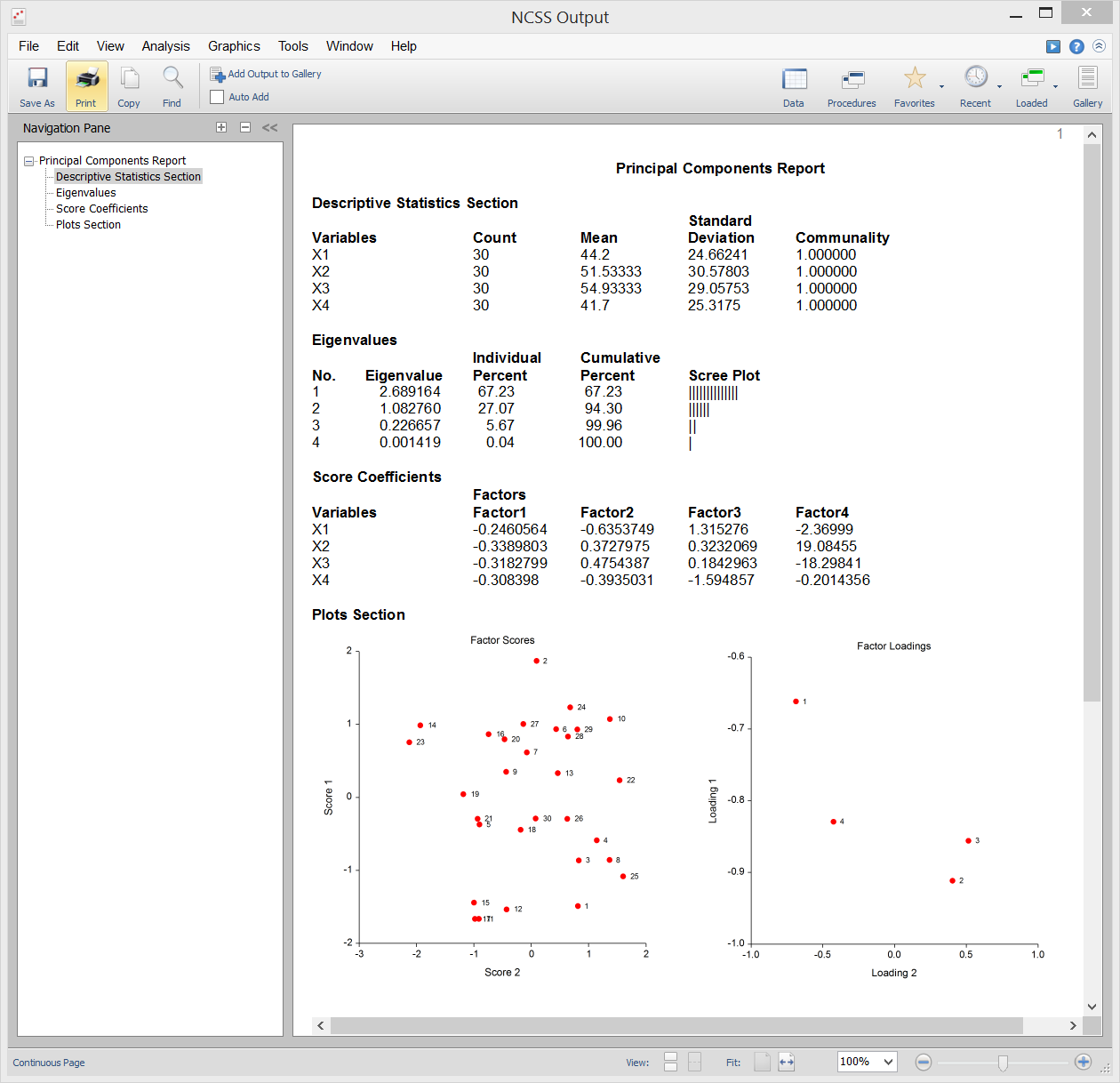
Salida de la muestra
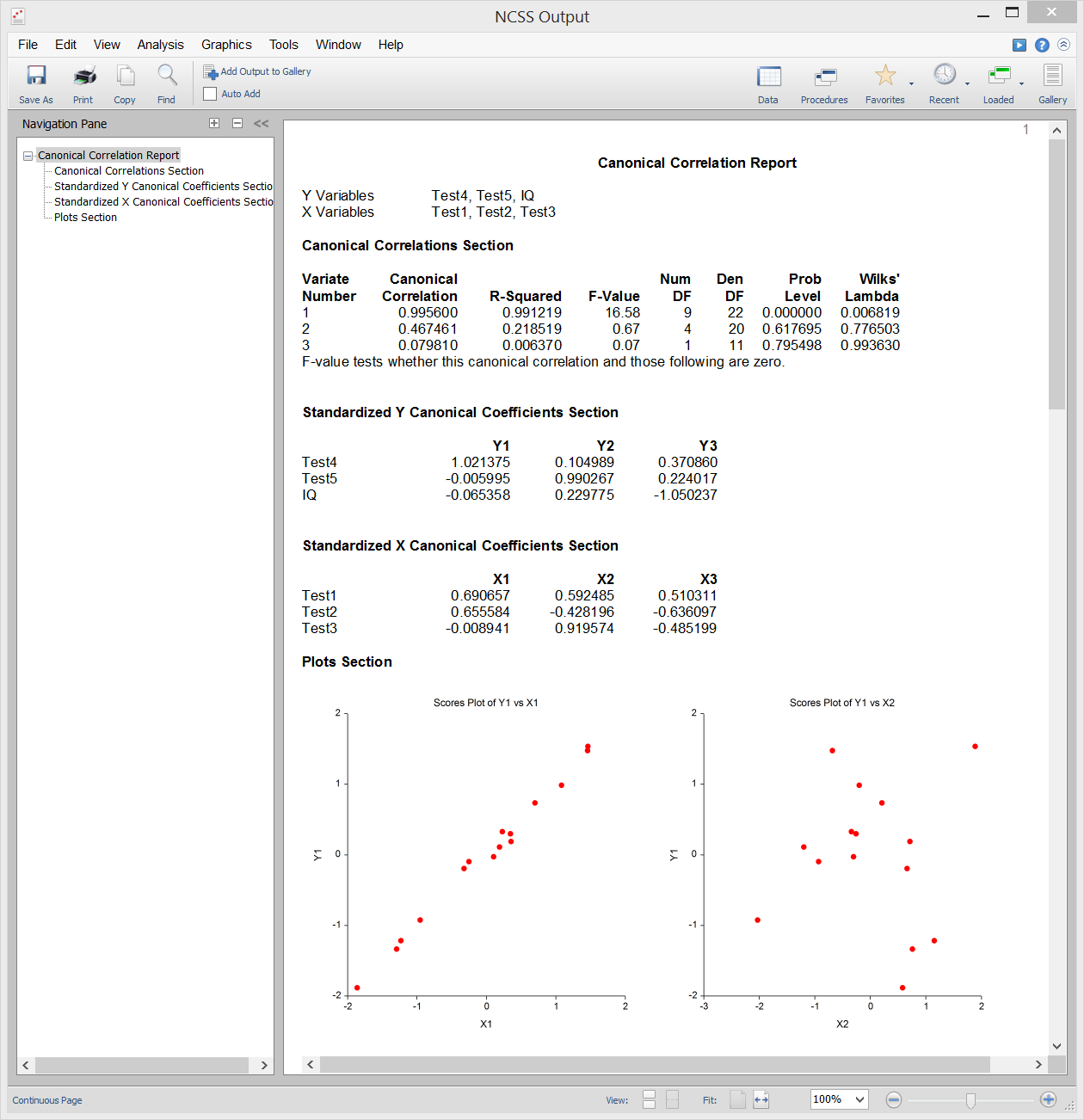
Correlación canónica
El análisis de correlación canónica es el estudio de la relación lineal entre dos conjuntos de variables. Es la extensión multivariante del análisis de correlación. A modo de ilustración, supongamos que un grupo de estudiantes recibe dos pruebas de diez preguntas cada una y se desea determinar la correlación global entre estas dos pruebas. La correlación canónica encuentra una media ponderada de las preguntas de la primera prueba y la correlaciona con una media ponderada de las preguntas de la segunda prueba. Las ponderaciones se construyen para maximizar la correlación entre estas dos medias. Esta correlación se denomina primer coeficiente de correlación canónica. A continuación, se puede crear otro conjunto de medias ponderadas no relacionadas con la primera y calcular su correlación. Esta correlación es el segundo coeficiente de correlación canónica. El proceso continúa hasta que el número de correlaciones canónicas es igual al número de variables en el grupo más pequeño.
La correlación canónica proporciona el marco multivariante más general (el análisis discriminante, el MANOVA y la regresión múltiple son todos casos especiales de la correlación canónica). Debido a esta generalidad, la correlación canónica es probablemente el menos utilizado de los procedimientos multivariantes.
Salida de la muestra
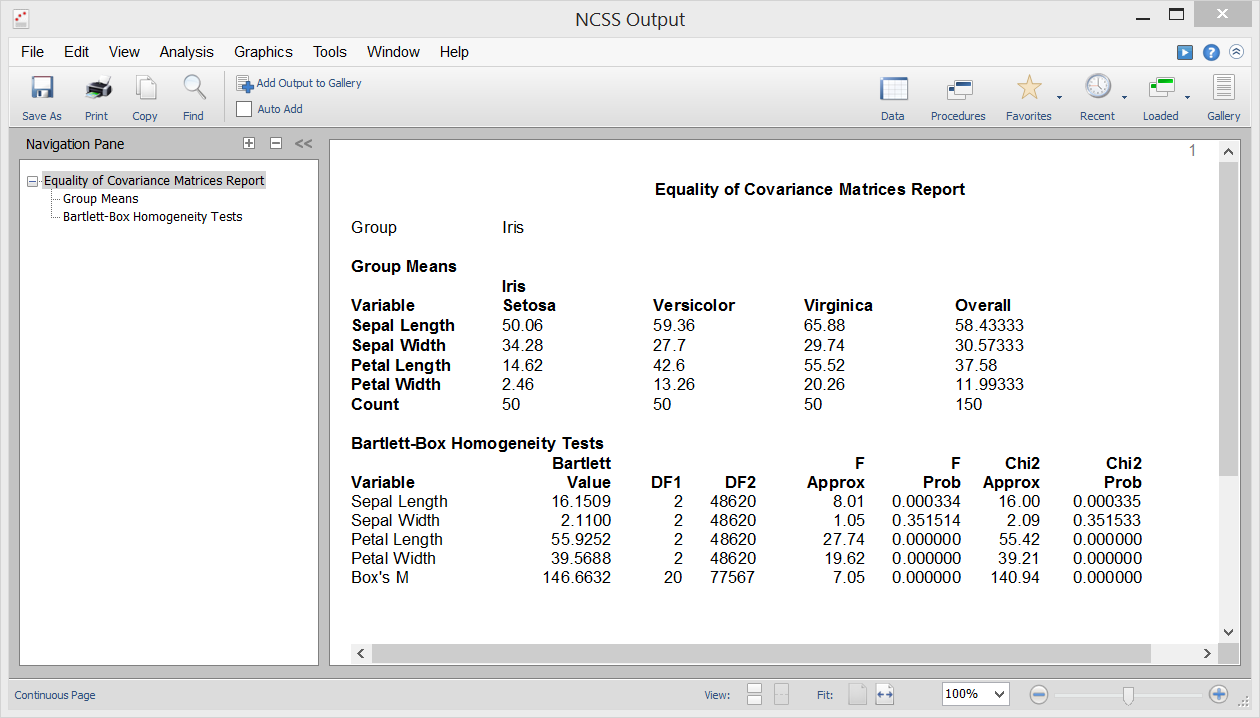
Igualdad de covarianza
Una de las suposiciones en el Análisis Discriminante, MANOVA y otros procedimientos multivariantes es que las matrices de covarianza de los grupos individuales son iguales (es decir, homogéneas entre los grupos). El procedimiento de Igualdad de Covarianza en el NCSS le permite probar esta hipótesis utilizando la prueba M de Box, que fue presentada por primera vez por Box (1949). Este procedimiento también produce la prueba de homogeneidad de varianza univariante de Bartlett para probar la igualdad de varianza entre variables individuales.
Salida de la muestra
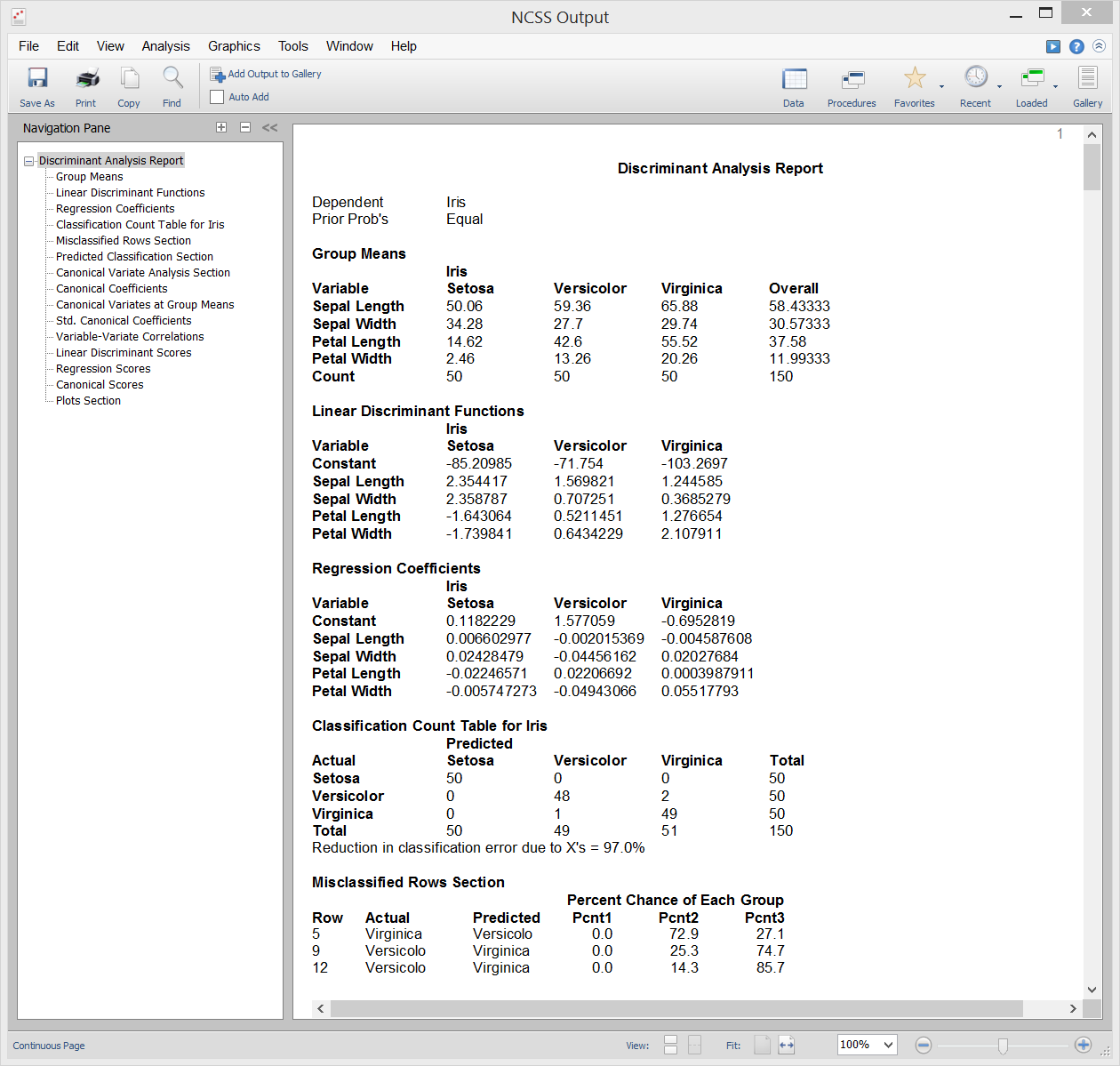
Análisis discriminante
El análisis discriminante es una técnica utilizada para encontrar un conjunto de ecuaciones de predicción basadas en una o más variables independientes. Estas ecuaciones de predicción se utilizan después para clasificar a los individuos en grupos. Hay dos objetivos comunes en el análisis discriminante: 1. encontrar una ecuación de predicción para clasificar nuevos individuos, y 2. interpretar la ecuación de predicción para comprender mejor las relaciones entre las variables.
En muchos sentidos, el análisis discriminante es muy parecido al análisis de regresión logística. La metodología utilizada para completar un análisis discriminante es similar al análisis de regresión logística. A menudo se traza cada variable independiente frente a la variable de grupo, se pasa por una fase de selección de variables para determinar qué variables independientes son beneficiosas y se lleva a cabo un análisis residual para determinar la precisión de las ecuaciones discriminantes.
Los cálculos del análisis discriminante están muy relacionados con el MANOVA unidireccional. De hecho, los papeles de las variables simplemente se invierten. La variable de clasificación (factor) en el MANOVA se convierte en la variable dependiente en el análisis discriminante. Las variables dependientes en el MANOVA unidireccional se convierten en las variables independientes en el análisis discriminante.
Salida de la muestra
La prueba T² de una muestra de Hotelling
La prueba T² de una muestra de Hotelling es la extensión multivariante de la prueba T de una muestra o de Student emparejada común. Esta prueba se utiliza cuando el número de variables de respuesta es de dos o más, aunque puede utilizarse cuando sólo hay una variable de respuesta. La prueba requiere la suposición de que los datos son aproximadamente normales multivariados, sin embargo se proporcionan pruebas de aleatorización que no dependen de esta suposición.
Salida de la muestra

T² de dos muestras de Hotelling
La prueba T² de dos muestras de Hotelling es la extensión multivariante de la prueba T de Student común de dos muestras para la diferencia de medias. Esta prueba se utiliza cuando el número de variables de respuesta es de dos o más, aunque puede utilizarse cuando sólo hay una variable de respuesta. La prueba requiere las suposiciones de varianzas iguales y residuos normalmente distribuidos, sin embargo se proporcionan pruebas de aleatorización que no dependen de estas suposiciones.
Salida de la muestra

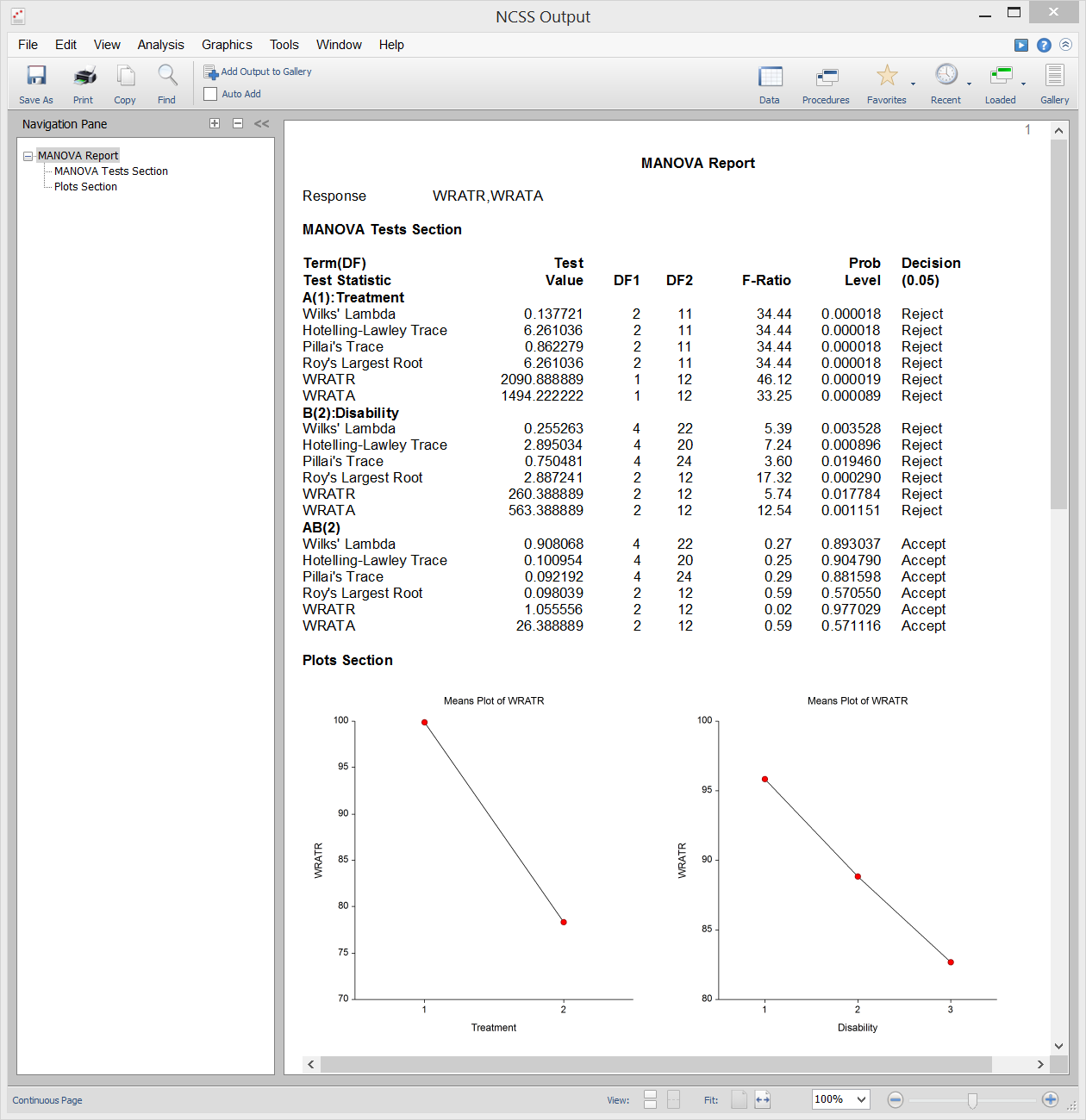
Análisis multivariante de la varianza (MANOVA)
El análisis multivariante de la varianza (o MANOVA) es una extensión de ANOVA al caso en el que hay dos o más variables de respuesta. El MANOVA está diseñado para el caso en el que se tienen uno o más factores independientes (cada uno con dos o más niveles) y dos o más variables dependientes. Las pruebas de hipótesis implican la comparación de vectores de medias de grupos.
La extensión multivariante de la prueba F de ANOVA no es completamente directa. En su lugar, hay otros estadísticos de prueba disponibles en MANOVA: Lambda de Wilks, Traza de Hotelling-Lawley, Traza de Pillai y Raíz más grande de Roy. Las distribuciones reales de estos estadísticos de prueba son difíciles de calcular, por lo que nos basamos en aproximaciones basadas en la distribución F para calcular los valores p.
Salida de la muestra
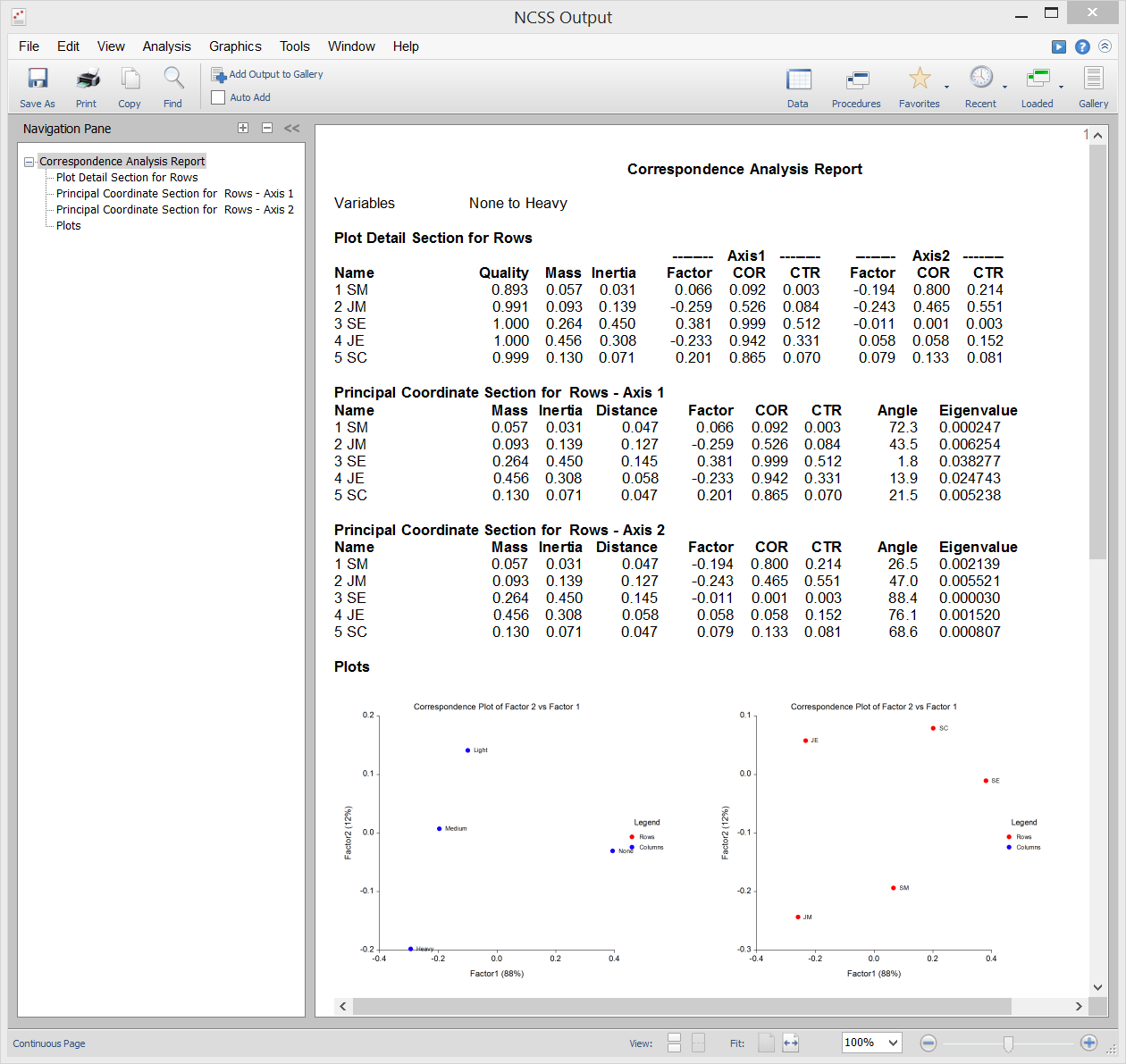
Análisis de Correspondencias
El Análisis de Correspondencias (o AC) es una técnica para mostrar gráficamente una tabla de dos vías de datos categóricos utilizando coordenadas calculadas que representan las filas y columnas de la tabla. Estas coordenadas son análogas a los factores en un análisis de componentes principales (utilizado para datos continuos), excepto que dividen el valor de Chi-cuadrado utilizado en la prueba de independencia en lugar de la varianza total.
Salida de la muestra
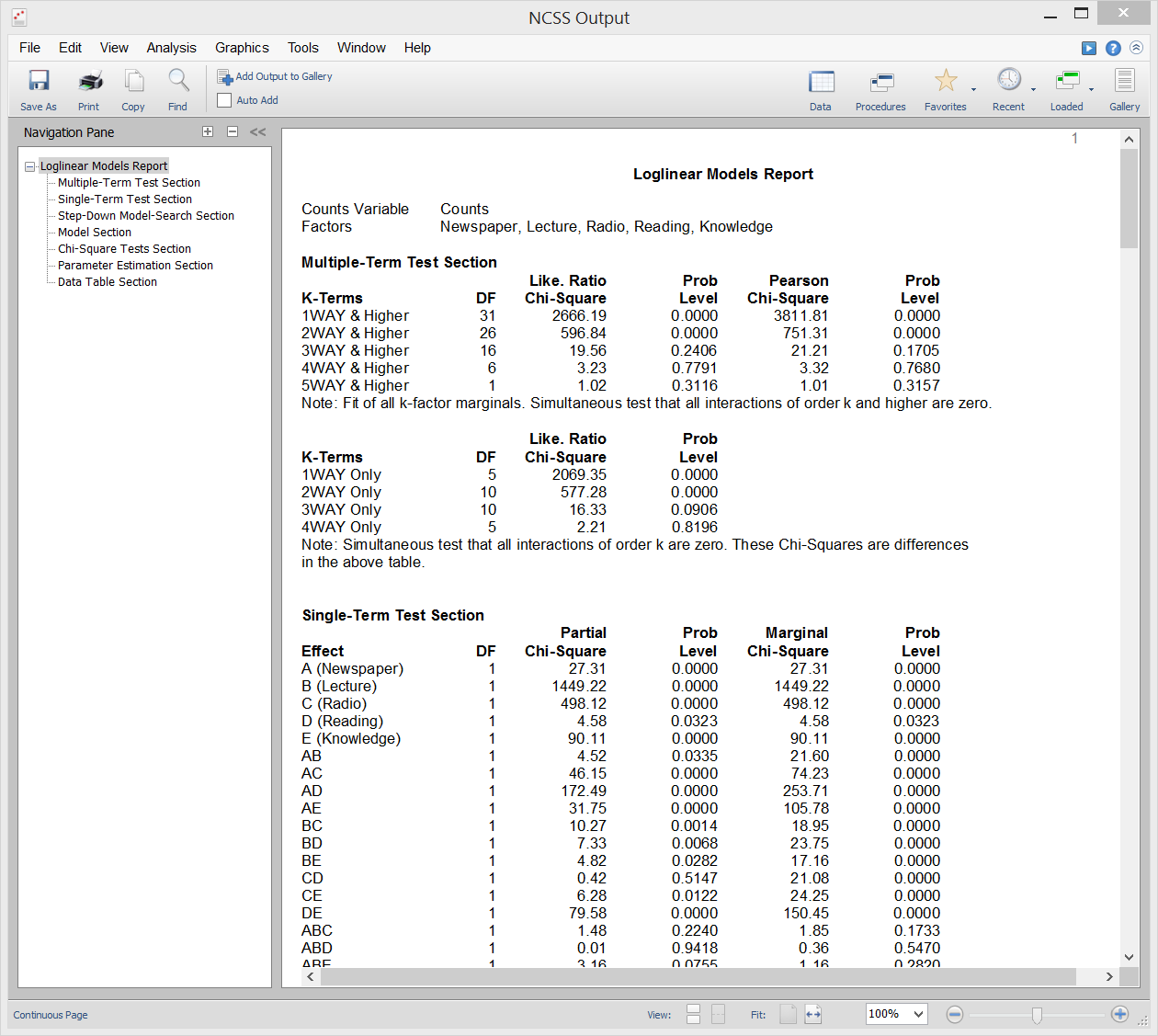
Modelos Loglineales
Los modelos Loglineales (LLM) se utilizan para estudiar las relaciones entre dos o más variables discretas. A menudo se denominan análisis de frecuencia multidireccional y son una extensión de la conocida prueba de chi-cuadrado para la independencia en tablas de contingencia de dos vías.
Los LLM pueden utilizarse para analizar encuestas y cuestionarios que tienen interrelaciones complejas entre las preguntas. Aunque los cuestionarios se analizan a menudo considerando sólo dos preguntas a la vez, esto ignora importantes relaciones de tres vías (y multidireccionales) entre las preguntas. El uso del LLM en este tipo de datos es análogo al uso de la regresión múltiple en lugar de las correlaciones simples en datos continuos.
Los informes de este procedimiento incluyen informes de varios términos, informes de un solo término, informes de chi-cuadrado, informes de modelos, informes de estimación de parámetros e informes de tablas.
Salida de la muestra
Escalado multidimensional
El escalado multidimensional (MDS) es una técnica que crea un mapa que muestra las posiciones relativas de un número de objetos, dada sólo una tabla de las distancias entre ellos. El mapa puede constar de una, dos, tres o más dimensiones. El procedimiento calcula la solución métrica o la no métrica. La tabla de distancias se conoce como matriz de proximidad. Surge directamente de los experimentos o indirectamente como una matriz de correlación.
El programa ofrece dos métodos generales para resolver el problema MDS. El primero se denomina Métrico, o Clásico, de Escalamiento Multidimensional (CMDS) porque trata de reproducir la métrica o las distancias originales. El segundo método, llamado Escalamiento Multidimensional No Métrico (NMMDS), supone que sólo se conocen los rangos de las distancias. Por lo tanto, este método produce un mapa que intenta reproducir los rangos. Las distancias en sí no se reproducen.