SPSS Statistics
Interpretación e informe de los resultados de un análisis de regresión logística binomial
SPSS Statistics genera muchas tablas de resultados cuando se lleva a cabo una regresión logística binomial. En esta sección, le mostramos sólo las tres tablas principales necesarias para entender sus resultados del procedimiento de regresión logística binomial, asumiendo que no se han violado los supuestos. En nuestra guía mejorada se ofrece una explicación completa de los resultados que tiene que interpretar al comprobar sus datos en relación con los supuestos necesarios para llevar a cabo la regresión logística binomial.
Sin embargo, en esta guía de «inicio rápido», nos centramos sólo en las tres tablas principales que necesita para entender los resultados de su regresión logística binomial, asumiendo que sus datos ya han cumplido los supuestos requeridos para que la regresión logística binomial le dé un resultado válido:
Varianza explicada
Para entender cuánta variación de la variable dependiente puede explicar el modelo (el equivalente a R2 en la regresión múltiple), puede consultar la tabla siguiente, «Resumen del modelo»:
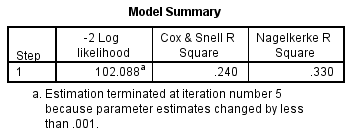
Esta tabla contiene los valores de Cox & Snell R Square y Nagelkerke R Square, que son ambos métodos para calcular la variación explicada. Estos valores se denominan a veces valores pseudo R2 (y tendrán valores más bajos que en la regresión múltiple). Sin embargo, se interpretan de la misma manera, pero con más precaución. Por lo tanto, la variación explicada en la variable dependiente basada en nuestro modelo oscila entre el 24,0% y el 33,0%, dependiendo de si se hace referencia a los métodos Cox & Snell R2 o Nagelkerke R2, respectivamente. La R2 de Nagelkerke es una modificación de la & R2 de Cox, esta última no puede alcanzar un valor de 1. Por esta razón, es preferible informar del valor de la R2 de Nagelkerke.
Predicción de la categoría
La regresión logística binomial estima la probabilidad de que se produzca un evento (en este caso, tener una enfermedad cardíaca). Si la probabilidad estimada de que se produzca el evento es mayor o igual a 0,5 (mejor que el azar), SPSS Statistics clasifica el evento como ocurrido (por ejemplo, la presencia de una enfermedad cardíaca). Si la probabilidad es inferior a 0,5, SPSS Statistics clasifica el evento como no ocurrido (por ejemplo, no hay enfermedad cardíaca). Es muy común utilizar la regresión logística binomial para predecir si los casos se pueden clasificar correctamente (es decir, predecir) a partir de las variables independientes. Por lo tanto, se hace necesario disponer de un método para evaluar la eficacia de la clasificación predicha frente a la clasificación real. Existen muchos métodos para evaluar esto, cuya utilidad suele depender de la naturaleza del estudio realizado. Sin embargo, todos los métodos giran en torno a las clasificaciones observadas y predichas, que se presentan en la «Tabla de clasificación», como se muestra a continuación:
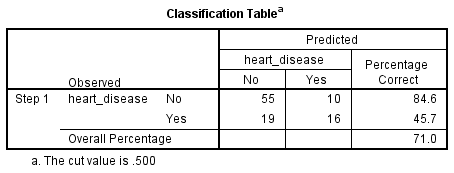
En primer lugar, observe que la tabla tiene un subíndice que dice: «El valor de corte es .500». Esto significa que si la probabilidad de que un caso se clasifique en la categoría «sí» es mayor que 0,500, entonces ese caso concreto se clasifica en la categoría «sí». En caso contrario, el caso se clasifica en la categoría «no» (como se ha mencionado anteriormente). Aunque la tabla de clasificación parece muy sencilla, en realidad proporciona mucha información importante sobre el resultado de su regresión logística binomial, incluyendo:
- A. El porcentaje de precisión en la clasificación (PAC), que refleja el porcentaje de casos que pueden clasificarse correctamente como «no» a la enfermedad cardíaca con las variables independientes añadidas (no sólo el modelo global).
- B. La sensibilidad, que es el porcentaje de casos que tenían la característica observada (por ejemplo, «sí» para la enfermedad cardíaca) que fueron predichos correctamente por el modelo (es decir, verdaderos positivos).
- C. Especificidad, que es el porcentaje de casos que no tenían la característica observada (por ejemplo, «no» para la enfermedad cardíaca) y que también fueron predichos correctamente como no teniendo la característica observada (es decir, verdaderos negativos).
- D. El valor predictivo positivo, que es el porcentaje de casos correctamente predichos «con» la característica observada en comparación con el número total de casos predichos como poseedores de la característica.
- E. El valor predictivo negativo, que es el porcentaje de casos correctamente predichos «sin» la característica observada en comparación con el número total de casos predichos como no poseedores de la característica.
- General
Si no está seguro de cómo interpretar el PAC, la sensibilidad, la especificidad, el valor predictivo positivo y el valor predictivo negativo de la «Tabla de clasificación», le explicamos cómo hacerlo en nuestra guía de regresión logística binomial mejorada.
Variables en la ecuación
La tabla «Variables en la ecuación» muestra la contribución de cada variable independiente al modelo y su significación estadística. Esta tabla se muestra a continuación:
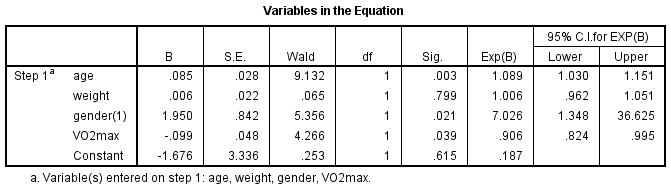
La prueba de Wald (columna «Wald») se utiliza para determinar la significación estadística de cada una de las variables independientes. La significación estadística de la prueba se encuentra en la columna «Sig.». A partir de estos resultados puede ver que la edad (p = 0,003), el género (p = 0,021) y el VO2máx (p = 0,039) se sumaron significativamente al modelo/predicción, pero el peso (p = 0,799) no se sumó significativamente al modelo. Puede utilizar la información de la tabla «Variables en la ecuación» para predecir la probabilidad de que ocurra un evento basado en un cambio de una unidad en una variable independiente cuando todas las demás variables independientes se mantienen constantes. Por ejemplo, la tabla muestra que la probabilidad de padecer una enfermedad cardíaca (categoría «sí») es 7,026 veces mayor para los hombres que para las mujeres. Si no está seguro de cómo utilizar las odds ratios para hacer predicciones, conozca nuestras guías mejoradas en nuestra Características: Página de información general.
Poniéndolo todo junto
En base a los resultados anteriores, podríamos informar de los resultados del estudio de la siguiente manera (N.B., esto no incluye los resultados de sus pruebas de suposición):
Se realizó una regresión logística para determinar los efectos de la edad, el peso, el género y el VO2máx en la probabilidad de que los participantes tengan una enfermedad cardíaca. El modelo de regresión logística fue estadísticamente significativo, χ2(4) = 27,402, p < .0005. El modelo explicó el 33,0% (R2 de Nagelkerke) de la varianza de la enfermedad cardíaca y clasificó correctamente el 71,0% de los casos. Los varones tenían 7,02 veces más probabilidades de presentar una cardiopatía que las mujeres. El aumento de la edad se asoció con un aumento de la probabilidad de presentar enfermedades del corazón, pero el aumento del VO2máx se asoció con una reducción de la probabilidad de presentar enfermedades del corazón.
Además de la redacción anterior, también debe incluir: (a) los resultados de las pruebas de suposición que ha realizado; (b) los resultados de la «Tabla de clasificación», incluyendo la sensibilidad, la especificidad, el valor predictivo positivo y el valor predictivo negativo; y (c) los resultados de la tabla de «Variables en la ecuación», incluyendo cuáles de las variables predictoras fueron estadísticamente significativas y qué predicciones se pueden hacer basándose en el uso de odds ratios. Si no está seguro de cómo hacer esto, se lo mostramos en nuestra guía mejorada de regresión logística binomial. También le mostramos cómo redactar los resultados de sus pruebas de suposición y los resultados de la regresión logística binomial en caso de que tenga que presentarlos en una disertación/tesis, un trabajo o un informe de investigación. Lo hacemos utilizando los estilos Harvard y APA. Puede obtener más información sobre nuestro contenido mejorado en nuestra página Características: Página de descripción general.