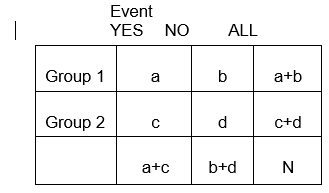
Las variables categóricas pueden representar el desarrollo de una enfermedad, un aumento de la gravedad de la enfermedad, la mortalidad o cualquier otra variable que conste de dos o más niveles. Para resumir la asociación entre dos variables categóricas con niveles R y C, creamos tabulaciones cruzadas, o tablas RxC («Fila «x «Columna» o tablas de contingencia), que resumen las frecuencias observadas de resultados categóricos entre diferentes grupos de sujetos. Aquí nos centraremos en las tablas de 2 x 2.
En general, las tablas de 2 x 2 resumen la frecuencia de los eventos relacionados con la salud (u otros) entre diferentes grupos, como se ilustra a continuación en el que el Grupo 1 puede representar a los pacientes que recibieron una terapia estándar, y el Grupo 2 podría ser los pacientes que recibieron una nueva terapia experimental.
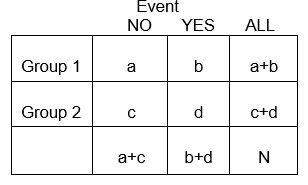
Ejemplo:
La variable de resultado principal en los ensayos de Kawasaki fue el desarrollo de anomalías en las arterias coronarias (AC), una variable dicotómica. Uno de los objetivos del estudio era comparar las probabilidades de desarrollar anomalías en las AC dado el tratamiento con Aspirina (ASA) o Gammaglobulina (GG).

Podríamos estar interesados en saber si la frecuencia de anomalías en las arterias coronarias difería entre estos dos grupos, es decir, si uno de ellos se asoció con menos anormalidades. La respuesta a preguntas como ésta depende de la comparación de las frecuencias de estos eventos de salud en los dos grupos de tratamiento. Dependiendo del diseño del estudio, se puede comparar la probabilidad de los eventos o las probabilidades de que se produzca un evento.
Probabilidad y probabilidades de desarrollar AC en cada uno de los brazos de tratamiento
La probabilidad se calcula como el número de valores «sí» en cada categoría de tratamiento dividido por el número total en la categoría de tratamiento.
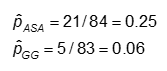
La probabilidad es #Sí / #No. Aquí,
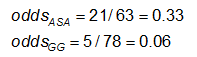
Siempre fíjate si el resultado está en las filas o en las columnas; ¡es muy fácil confundirlos!
Cuando miramos la asociación entre una variable binaria y un resultado continuo, resumimos la asociación en términos de diferencia de medias. Qué estadísticas son apropiadas para representar la diferencia entre dos grupos con respecto a la probabilidad de un evento binario? Hay al menos tres formas de resumir la asociación:
Diferencia de riesgo RD = p1 – p2
Riesgo relativo (Risk Ratio) RR = p1 / p2
Odds Ratio OR = odds1/ odds2 = /
El diseño del estudio determina cuál de estas medidas de efecto es la adecuada. En un estudio de casos y controles, no se puede evaluar el riesgo relativo, y la medida adecuada es la odds ratio (OR). Sin embargo, la OR proporcionará una buena estimación del riesgo relativo para los eventos poco frecuentes (es decir, si p es pequeña, normalmente 0,10 o menor).
Los estudios transversales evalúan la prevalencia de las medidas de salud, por lo que la odds ratio es apropiada. Con los estudios de cohortes prospectivos es apropiada una razón de tasas o una razón de riesgos, aunque también puede calcularse una razón de probabilidades.,
Para una revisión más detallada de las medidas de efecto, véase el módulo de epidemiología en línea sobre «Medidas de asociación.»
Ejemplo: Utilizando los datos anteriores sobre las anomalías del CA, las medidas de efecto para los que utilizan ASA (aspirina) frente a la gammaglobulina (GG) son las siguientes:
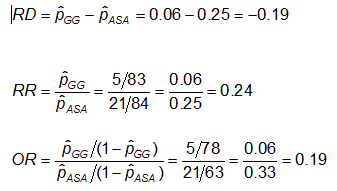

Ejercicio: Considere las medidas de efecto del ejemplo anterior. Por qué son tan diferentes el cociente de riesgos y el cociente de probabilidades (el RR sugiere que, en comparación con el grupo tratado sólo con ASA, el riesgo de anomalías coronarias es 1/4 tan alto para los tratados con GG; mientras que el OR sugiere que el riesgo es 1/5 tan alto)?
Maneras alternativas de expresar la hipótesis nula
Para una tabla de 2×2, la hipótesis nula puede escribirse de forma equivalente en términos de las propias probabilidades, o de la diferencia de riesgo, el riesgo relativo o la razón de momios. En cada caso, la hipótesis nula afirma que no hay diferencia entre los dos grupos.
H0: p1 = p2
H1: p1 ≠ p2
H0: p1 – p2 = 0 (RD=0)
H1: RD ≠ 0
H0: p1/ p2 = 1 (RR=1)
H1: RR ≠ 1
H0: OR = 1
H1: OR ≠ 1
La prueba de chi-cuadrado
La diferencia de frecuencia del resultado entre los dos grupos puede evaluarse con la prueba de chi-cuadrado.
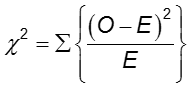
En cada celda de la tabla 2×2, O es la frecuencia de celdas observada y E es la frecuencia de celdas esperada bajo el supuesto de que la hipótesis nula es verdadera. La suma se calcula sobre las 2×2 = 4 celdas de la tabla. Siempre que la frecuencia esperada en cada celda sea al menos cinco, el valor de chi-cuadrado calculado tiene una distribución χ2 con 1 grados de libertad (df).
Rechace la hipótesis nula si ![]() . Para α = 0,05, el valor crítico es 3,84.
. Para α = 0,05, el valor crítico es 3,84.
Ejemplo:
Frecuencias observadas

Si no hay asociación entre el tratamiento y la enfermedad, la proporción de casos entre los tratados y los no tratados sería la misma y sería igual a la proporción de casos en toda la población del estudio.
Frecuencias esperadas:
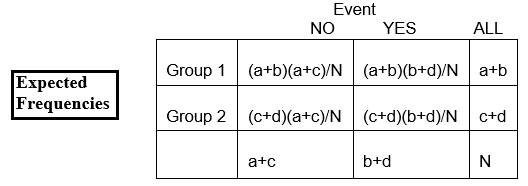
En total, entre los 167 niños, hay 26 con anomalías del CA y 141 sin anomalías del CA. La proporción con anomalías del CA es de 26/167, es decir, el 16%. Si la hipótesis nula es cierta, y los dos grupos de tratamiento tienen la misma probabilidad de anomalías de la CA, entonces esperaríamos que aproximadamente el 16% de cada grupo tuviera anomalías de la CA.
Así, en el grupo GG de n=83, esperaríamos que el 16% de 83 tuviera anomalías de la CA. Esto se calcula como 0,16 x 83 = 13, y se llama la frecuencia esperada en esa celda.
Podemos escribir esto como
E11 = frecuencia esperada en la fila 1, columna 1
= número esperado en el grupo 1 que tiene el evento (fila 1, columna 1)
Y lo calculamos como
E11 = (proporción que esperamos que tenga el evento) x número total en (grupo) fila 1
= x número en (grupo) fila 1
Utilizando la notación de la tabla,
E11 = x (a+b)
Y a menudo reescribimos esto simplemente como
E11 = (a+b)(a+c)/N
En nuestro ejemplo, vamos a calcular la frecuencia esperada en la primera celda ( E11) :
E11 = (83)(26)/167 = 12.92
Podemos calcular las frecuencias esperadas en las otras celdas de la misma manera
La proporción global sin anomalías en la CA es de 141/167, o sea el 84%. Esperamos que alrededor del 84% de los del grupo ASA no tengan anomalías de CA, por lo que la frecuencia esperada en la fila 2, columna 2, es E22 = 84% de 84, o 0,84 x 84, o aproximadamente 71.
Usando la tabla anterior, podríamos calcularla simplemente como
E22 = (c+d)(b+d)/N = (84)(141)/167 = 70.92
Ejercicio: ¿Cuántos de los niños del grupo ASA esperarías que tuvieran anomalías en la CA si la hipótesis nula es cierta? Intenta resolverlo antes de mirar la respuesta de abajo.
Nota que las frecuencias observadas toman valores enteros, mientras que las frecuencias esperadas pueden tomar valores decimales.
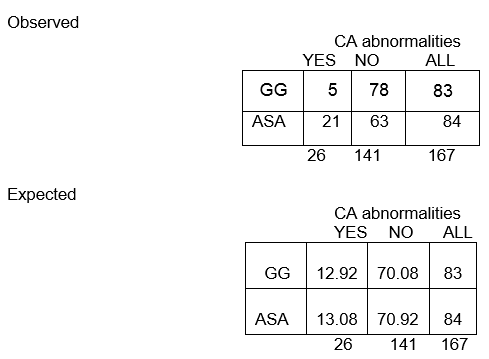
¡Esperamos que casi 13 niños del grupo GG tengan anomalías en la CA, pero sólo 5 las tuvieron realmente!
¡Observe que una vez que hemos calculado una frecuencia esperada, las otras se pueden obtener fácilmente por sustracción! El número de grados de libertad es igual al número de celdas cuya frecuencia esperada necesita ser calculada; en una tabla de 2 x 2, esto es 1.
Estadística de la prueba Chi-cuadrado
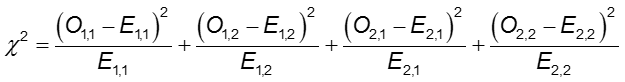
Donde O1,1 y E1,1 son los recuentos observados y esperados en la celda de la primera fila y la primera columna. Por ejemplo, O1,1 = a y E1,1 =(a+b)(a+c)/N. Si los recuentos de celdas observados son lo suficientemente diferentes de los esperados, entonces no podemos concluir que las dos probabilidades son iguales.
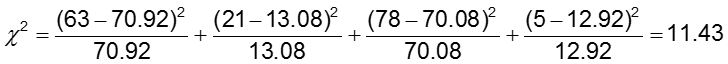
H0: Las probabilidades de anomalías del CA son las mismas en todos los grupos de tratamiento (OR=1)
H1: Las probabilidades de anormalidades de CA no son las mismas entre los grupos de tratamiento (OR≠1)
El nivel de significación es 0.05.
El estadístico de prueba se calcula en 11,43. Dado que nuestro estadístico de prueba es mayor que 3,84 (el valor crítico de chi-cuadrado para 1 grado de libertad), rechazamos la hipótesis nula y concluimos que las probabilidades de anomalías de CA no son las mismas en los dos grupos de tratamiento.
Volver al principio | página anterior | página siguiente