Última actualización el 13 de julio de 2020
La teoría de la información es un subcampo de las matemáticas que se ocupa de la transmisión de datos a través de un canal ruidoso.
Una piedra angular de la teoría de la información es la idea de cuantificar cuánta información hay en un mensaje. En términos más generales, esto se puede utilizar para cuantificar la información en un evento y una variable aleatoria, llamada entropía, y se calcula utilizando la probabilidad.
Calcular la información y la entropía es una herramienta útil en el aprendizaje automático y se utiliza como base para técnicas como la selección de características, la construcción de árboles de decisión y, en general, el ajuste de modelos de clasificación. Como tal, un practicante de aprendizaje automático requiere una fuerte comprensión e intuición para la información y la entropía.
En este post, usted descubrirá una suave introducción a la entropía de la información.
Después de leer este post, usted sabrá:
- La teoría de la información se ocupa de la compresión y transmisión de datos y se basa en la probabilidad y apoya el aprendizaje automático.
- La información proporciona una forma de cuantificar la cantidad de sorpresa para un evento medido en bits.
- La entropía proporciona una medida de la cantidad media de información necesaria para representar un evento extraído de una distribución de probabilidad para una variable aleatoria.
- Actualización Nov/2019: Añadido ejemplo de probabilidad vs información y más sobre la intuición de la entropía.
Empiece su proyecto con mi nuevo libro Probability for Machine Learning, que incluye tutoriales paso a paso y los archivos de código fuente de Python para todos los ejemplos.
Comencemos.

Una suave introducción a la entropía informativa
Foto de Cristiano Medeiros Dalbem, algunos derechos reservados.
Resumen
Este tutorial está dividido en tres partes; son:
- ¿Qué es la teoría de la información?
- Calcular la información de un evento
- Calcular la entropía de una variable aleatoria
¿Qué es la teoría de la información?
La teoría de la información es un campo de estudio que se ocupa de cuantificar la información para la comunicación.
Es un subcampo de las matemáticas y se ocupa de temas como la compresión de datos y los límites del procesamiento de señales. El campo fue propuesto y desarrollado por Claude Shannon mientras trabajaba en la compañía telefónica estadounidense Bell Labs.
La teoría de la información se ocupa de representar los datos de forma compacta (tarea conocida como compresión de datos o codificación de fuentes), así como de transmitirlos y almacenarlos de forma robusta frente a los errores (tarea conocida como corrección de errores o codificación de canales).
– Página 56, Machine Learning: A Probabilistic Perspective, 2012.
Un concepto fundacional de la información es la cuantificación de la cantidad de información en cosas como eventos, variables aleatorias y distribuciones.
Cuantificar la cantidad de información requiere el uso de probabilidades, de ahí la relación de la teoría de la información con la probabilidad.
Las mediciones de la información se utilizan ampliamente en la inteligencia artificial y el aprendizaje automático, como en la construcción de árboles de decisión y la optimización de modelos clasificadores.
Como tal, existe una importante relación entre la teoría de la información y el aprendizaje automático y un profesional debe estar familiarizado con algunos de los conceptos básicos del campo.
¿Por qué unificar la teoría de la información y el aprendizaje automático? Porque son dos caras de la misma moneda. La teoría de la información y el aprendizaje automático siguen estando unidos. Los cerebros son los sistemas de compresión y comunicación por excelencia. Y los algoritmos más avanzados tanto de compresión de datos como de códigos de corrección de errores utilizan las mismas herramientas que el aprendizaje automático.
– Página v, Teoría de la información, inferencia y algoritmos de aprendizaje, 2003.
Quieres aprender probabilidad para el aprendizaje automático
Toma ahora mi curso intensivo gratuito de 7 días por correo electrónico (con código de ejemplo).
Haga clic para inscribirse y obtener también una versión gratuita del curso en formato PDF Ebook.
Descargue su minicurso gratuito
Calcular la información de un evento
Calcular la información es la base del campo de la teoría de la información.
La intuición detrás de la cuantificación de la información es la idea de medir cuánta sorpresa hay en un evento. Aquellos eventos que son raros (baja probabilidad) son más sorprendentes y por lo tanto tienen más información que aquellos eventos que son comunes (alta probabilidad).
- Evento de baja probabilidad: Información alta (sorprendente).
- Evento de alta probabilidad: Información baja (no sorprendente).
La intuición básica detrás de la teoría de la información es que aprender que un evento poco probable ha ocurrido es más informativo que aprender que un evento probable ha ocurrido.
– Página 73, Deep Learning, 2016.
Los eventos raros son más inciertos o más sorprendentes y requieren más información para representarlos que los eventos comunes.
Podemos calcular la cantidad de información que hay en un evento utilizando la probabilidad del evento. Esto se denomina «información de Shannon», «autoinformación» o simplemente la «información», y se puede calcular para un suceso discreto x de la siguiente manera:
- información(x) = -log( p(x) )
Donde log() es el logaritmo de base 2 y p(x) es la probabilidad del suceso x.
La elección del logaritmo de base 2 significa que las unidades de la medida de información están en bits (dígitos binarios). Esto puede interpretarse directamente en el sentido del tratamiento de la información como el número de bits necesarios para representar el suceso.
El cálculo de la información suele escribirse como h(); por ejemplo:
- h(x) = -log( p(x) )
El signo negativo garantiza que el resultado sea siempre positivo o cero.
La información será cero cuando la probabilidad de un suceso es 1,0 o una certeza, por ejemplo, no hay sorpresa.
Concretemos esto con algunos ejemplos.
Consideremos el lanzamiento de una moneda única y justa. La probabilidad de que salga cara (y cruz) es de 0,5. Podemos calcular la información de lanzar una cara en Python utilizando la función log2().
|
1
2
3
4
5
6
7
8
|
# calcular la información de un lanzamiento de moneda
de math import log2
# probabilidad del evento
p = 0.5
# calcular la información del suceso
h = -log2(p)
# imprimir el resultado
print(‘p(x)=%.3f, información: %.3f bits’ % (p, h))
|
Al ejecutar el ejemplo se imprime la probabilidad del evento como 50% y el contenido de información del evento como 1 bit.
|
1
|
p(x)=0.500, información: 1.000 bits
|
Si la misma moneda se lanzara n veces, entonces la información para esta secuencia de lanzamientos sería de n bits.
Si la moneda no fuera justa y la probabilidad de que saliera cara fuera en cambio del 10% (0,1), entonces el evento sería más raro y requeriría más de 3 bits de información.
|
1
|
p(x)=0.100, información: 3,322 bits
|
También podemos explorar la información de una sola tirada de un dado justo de seis caras, por ejemplo, la información de sacar un 6.
Sabemos que la probabilidad de sacar cualquier número es 1/6, que es un número menor que 1/2 para el lanzamiento de una moneda, por lo que esperaríamos más sorpresa o una mayor cantidad de información.
|
1
2
3
4
5
6
7
8
|
# calcular la información de una tirada de dados
desde math import log2
# probabilidad del evento
p = 1.0 / 6.0
# calcular la información del suceso
h = -log2(p)
# imprimir el resultado
print(‘p(x)=%.3f, información: %.3f bits’ % (p, h))
|
Ejecutando el ejemplo, podemos ver que nuestra intuición es correcta y que, efectivamente, hay más de 2,5 bits de información en una sola tirada de un dado justo.
|
1
|
p(x)=0.167, información: 2,585 bits
|
Se pueden utilizar otros logaritmos en lugar del de base 2. Por ejemplo, también es común utilizar el logaritmo natural que utiliza la base-e (el número de Euler) en el cálculo de la información, en cuyo caso las unidades se denominan «nats».
Podemos desarrollar aún más la intuición de que los eventos de baja probabilidad tienen más información.
Para que esto quede claro, podemos calcular la información para las probabilidades entre 0 y 1 y trazar la información correspondiente a cada una. A continuación, podemos crear un gráfico de la probabilidad frente a la información. Esperaríamos que el gráfico se curvara hacia abajo, desde las probabilidades bajas con información alta hasta las probabilidades altas con información baja.
El ejemplo completo aparece a continuación.
|
1
2
3
4
5
7
8
9
11
12
13
|
# comparar la probabilidad frente a la entropía de la información
from math import log2
from matplotlib import pyplot
# lista de probabilidades
probs =
# calcular información
info =
# trazar probabilidad vs información
pyplot.plot(probs, info, marker=’.’)
pyplot.title(‘Probability vs Information’)
pyplot.xlabel(‘Probability’)
pyplot.ylabel(‘Information’)
pyplot.show()
|
Al ejecutar el ejemplo se crea el gráfico de probabilidad vs información en bits.
Podemos ver la relación esperada donde los eventos de baja probabilidad son más sorprendentes y llevan más información, y el complemento de los eventos de alta probabilidad llevan menos información.
También podemos ver que esta relación no es lineal, es de hecho ligeramente sub-lineal. Esto tiene sentido dado el uso de la función logarítmica.
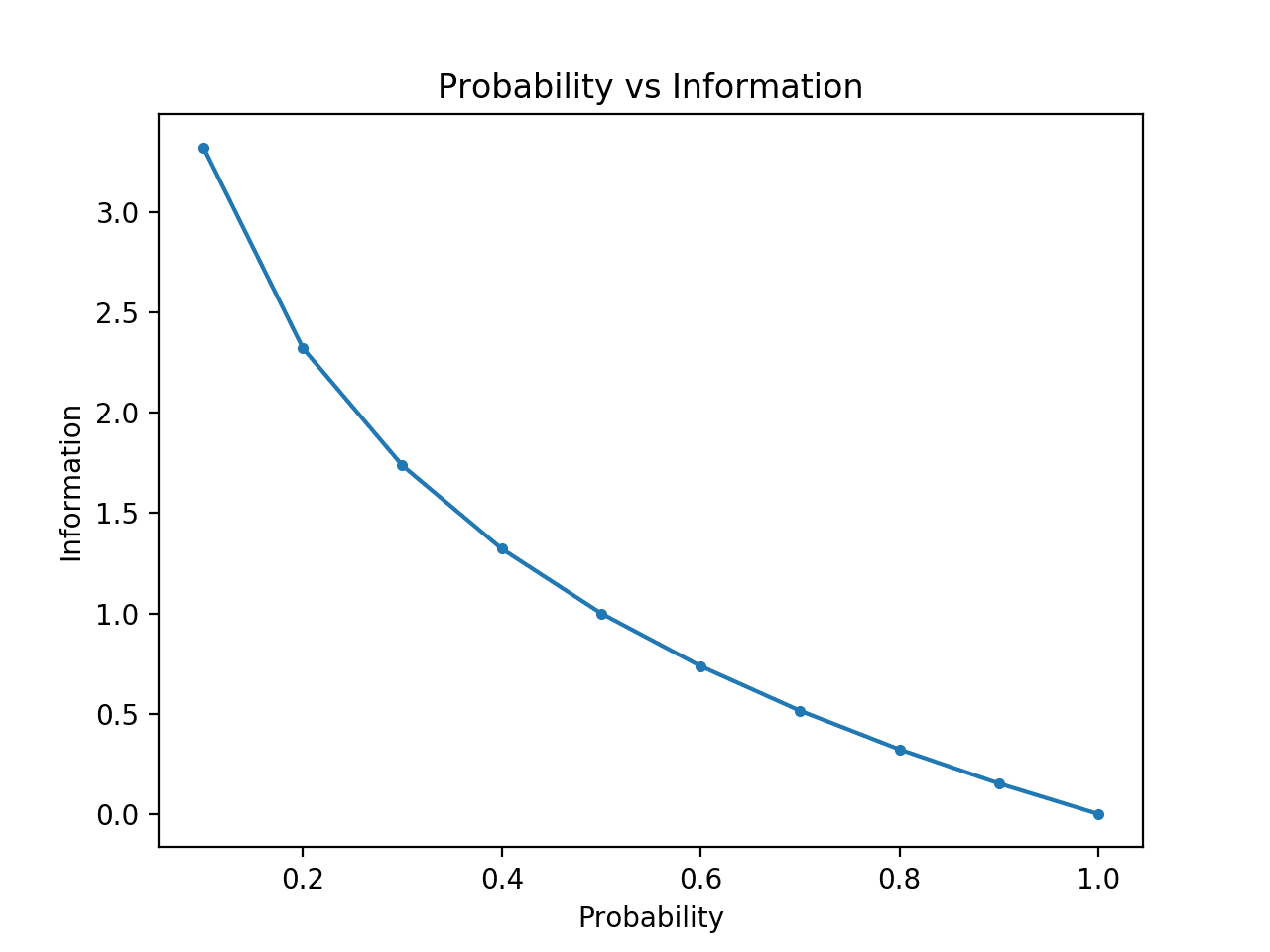
Planificación de la probabilidad frente a la información
Calcular la entropía de una variable aleatoria
También podemos cuantificar cuánta información hay en una variable aleatoria.
Por ejemplo, si quisiéramos calcular la información de una variable aleatoria X con distribución de probabilidad p, ésta podría escribirse como una función H(); por ejemplo:
- H(X)
En efecto, calcular la información de una variable aleatoria es lo mismo que calcular la información de la distribución de probabilidad de los sucesos de la variable aleatoria.
El cálculo de la información de una variable aleatoria se denomina «entropía de la información», «entropía de Shannon» o simplemente «entropía». Se relaciona con la idea de entropía de la física por analogía, en el sentido de que ambas tienen que ver con la incertidumbre.
La intuición de la entropía es que es el número medio de bits necesarios para representar o transmitir un evento extraído de la distribución de probabilidad para la variable aleatoria.
… la entropía de Shannon de una distribución es la cantidad esperada de información en un evento extraído de esa distribución. Da un límite inferior al número de bits necesarios en promedio para codificar símbolos extraídos de una distribución P.
– Página 74, Deep Learning, 2016.
La entropía se puede calcular para una variable aleatoria X con k en K estados discretos de la siguiente manera:
- H(X) = -suma(cada k en K p(k) * log(p(k)))
Es decir, el negativo de la suma de la probabilidad de cada evento multiplicado por el log de la probabilidad de cada evento.
Al igual que la información, la función log() utiliza base-2 y las unidades son bits. En su lugar se puede utilizar un logaritmo natural y las unidades serán nats.
La menor entropía se calcula para una variable aleatoria que tiene un único evento con una probabilidad de 1,0, una certeza. La mayor entropía para una variable aleatoria será si todos los eventos son igualmente probables.
Podemos considerar una tirada de un dado justo y calcular la entropía para la variable. Cada resultado tiene la misma probabilidad de 1/6, por lo tanto es una distribución de probabilidad uniforme. Por lo tanto, esperaríamos que la información media fuera la misma información para un solo evento calculada en la sección anterior.
|
1
2
3
4
5
6
7
8
9
10
|
# calcular la entropía de un dado tirada
from math import log2
# el número de eventos
n = 6
# probabilidad de un evento
p = 1.0 /n
# calcular la entropía
entropía = -suma()
# imprimir el resultado
print(‘entropía: %.3f bits’ % entropía)
|
Al ejecutar el ejemplo se calcula la entropía como más de 2,5 bits, que es lo mismo que la información de un solo resultado. Esto tiene sentido, ya que la información media es la misma que el límite inferior de la información ya que todos los resultados son igualmente probables.
|
1
|
entropía: 2.585 bits
|
Si conocemos la probabilidad de cada evento, podemos utilizar la función entropy() SciPy para calcular la entropía directamente.
Por ejemplo:
|
1
2
3
4
5
6
7
8
|
# calcula la entropía de una tirada de dados
from scipy.stats import entropy
# probabilidades discretas
p =
# calcular la entropía
e = entropy(p, base=2)
# imprimir el resultado
print(‘entropía: %.3f bits’ % e)
|
La ejecución del ejemplo informa del mismo resultado que hemos calculado manualmente.
|
1
|
entropía: 2.585 bits
|
Podemos desarrollar aún más la intuición de la entropía de las distribuciones de probabilidad.
Recordemos que la entropía es el número de bits necesarios para representar un par extraído aleatoriamente de la distribución, por ejemplo, un evento medio. Podemos explorar esto para una distribución simple con dos eventos, como el lanzamiento de una moneda, pero explorar diferentes probabilidades para estos dos eventos y calcular la entropía para cada uno.
En el caso donde un evento domina, como una distribución de probabilidad sesgada, entonces hay menos sorpresa y la distribución tendrá una entropía más baja. En el caso en el que ningún evento domina a otro, como una distribución de probabilidad igual o aproximadamente igual, entonces esperaríamos una entropía mayor o máxima.
- Distribución de probabilidad sesgada (sin sorpresa): Baja entropía.
- Distribución de probabilidad equilibrada (sorprendente): Alta entropía.
- Teoría de la información, inferencia y algoritmos de aprendizaje, 2003.
- Sección 2.8: Teoría de la información, Aprendizaje automático: Una perspectiva probabilística, 2012.
- Sección 1.6: Teoría de la información, Reconocimiento de patrones y aprendizaje automático, 2006.
- Sección 3.13 Teoría de la información, Aprendizaje profundo, 2016.
- scipy.stats.entropy API
- Entropía (teoría de la información), Wikipedia.
- Ganancia de información en árboles de decisión, Wikipedia.
- Razón de ganancia de información, Wikipedia.
- La teoría de la información se ocupa de la compresión y transmisión de datos y se basa en la probabilidad y apoya el aprendizaje automático.
- La información proporciona una forma de cuantificar la cantidad de sorpresa de un evento medido en bits.
- La entropía proporciona una medida de la cantidad media de información necesaria para representar un evento extraído de una distribución de probabilidad para una variable aleatoria.
Si pasamos de una probabilidad sesgada a una igual de eventos en la distribución esperaríamos que la entropía empezara baja y aumentara, concretamente desde la entropía más baja de 0.0 para los eventos con imposibilidad/certeza (probabilidad de 0 y 1 respectivamente) hasta la mayor entropía de 1,0 para los eventos con igual probabilidad.
El ejemplo siguiente implementa esto, creando cada distribución de probabilidad en esta transición, calculando la entropía para cada una y trazando el resultado.
|
1
2
3
4
5
7
8
9
11
12
13
14
15
16
17
18
19
20
21
|
# comparar distribuciones de probabilidad vs entropía
from math import log2
from matplotlib import pyplot
# calcular entropía
def entropía(eventos, ets=1e-15):
devolver -suma()
# definir probabilidades
probabilidades =
# crear distribución de probabilidad
dists = para p en probs]
# calcular la entropía de cada distribución
ents =
# trazar la distribución de probabilidad frente a la entropía
pyplot.plot(probs, ents, marker=’.’)
pyplot.title(‘Distribución de la probabilidad vs Entropía’)
pyplot.xticks(probs, )
pyplot.xlabel(‘Distribución de Probabilidad’)
pyplot.ylabel(‘Entropía (bits)’)
pyplot.show()
|
Al ejecutar el ejemplo se crean las 6 distribuciones de probabilidad con probabilidad a través de probabilidades.
Como era de esperar, podemos ver que a medida que la distribución de sucesos pasa de ser sesgada a equilibrada, la entropía aumenta de valores mínimos a máximos.
Es decir, si el suceso medio extraído de una distribución de probabilidad no es sorprendente obtenemos una entropía menor, mientras que si es sorprendente, obtenemos una entropía mayor.
Podemos ver que la transición no es lineal, que es superlineal. También podemos ver que esta curva es simétrica si continuáramos la transición hacia y hacia para los dos sucesos, formando una forma de parábola invertida.
Nótese que hemos tenido que añadir un valor minúsculo a la probabilidad al calcular la entropía para evitar calcular el logaritmo de un valor cero, que daría como resultado un infinito en no un número.
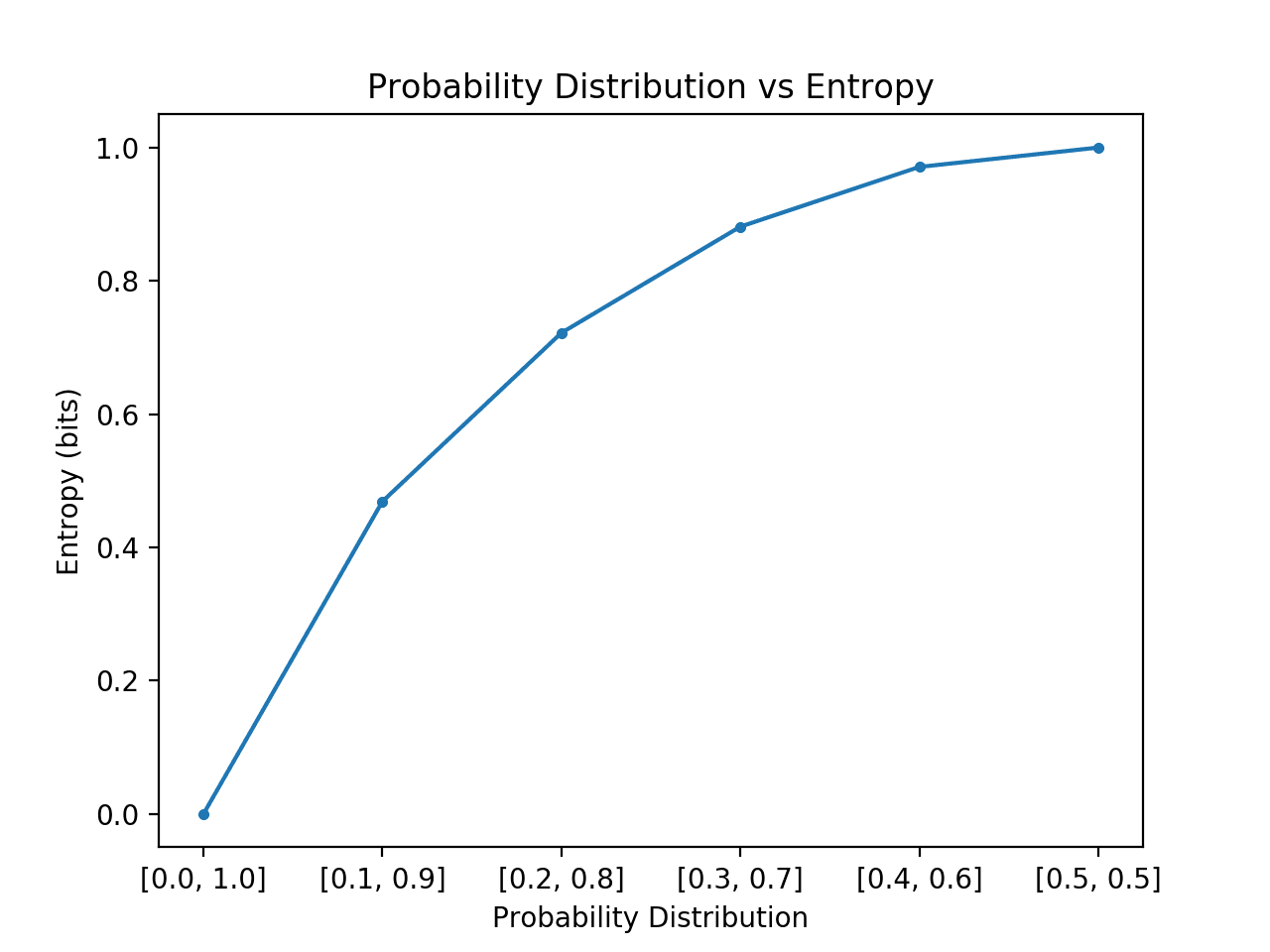
Planificación de la distribución de la probabilidad frente a la entropía
La entropía también proporciona la base para calcular la diferencia entre dos distribuciones de probabilidad con la entropía cruzada y la divergencia KL.
Lectura adicional
Esta sección proporciona más recursos sobre el tema si quieres profundizar.
Libros
Capítulos
API
Artículos
Resumen
En este post, has descubierto una suave introducción a la entropía de la información.
Específicamente, has aprendido:
¿Tienes alguna pregunta?
Haz tus preguntas en los comentarios de abajo y haré todo lo posible por responderlas.
¡Conoce la probabilidad para el aprendizaje automático!

Desarrolla tu comprensión de la probabilidad
…con sólo unas líneas de código python
Descubre cómo en mi nuevo Ebook:
Probabilidad para el Aprendizaje Automático
Proporciona tutoriales de autoaprendizaje y proyectos integrales sobre:
Teorema de Bayes, Optimización Bayesiana, Distribuciones, Máxima Verosimilitud, Entropía Cruzada, Calibración de Modelos
y mucho más…
Aproveche por fin la incertidumbre en sus proyectos
Olvídese de lo académico. Sólo resultados.Vea lo que hay dentro