No caso de termos esquecido ou nunca nos termos deparado com funções avaliadas de tabela em linha antes, começaremos com uma rápida explicação do que são.
Tomando a definição do que é uma função definida pelo utilizador (UDF) a partir do Books Online, uma função avaliada em tabela em linha (iTVF) é uma expressão de tabela que pode aceitar parâmetros, executar uma acção e fornecer como seu valor de retorno, uma tabela. A definição de um iTVF é armazenada permanentemente como um objecto de base de dados, semelhante a uma visualização.
A sintaxe para criar um iTVF a partir de Livros Online (BOL) pode ser encontrada aqui e é a seguinte:
CREATE FUNCTION function_name ( parameter_data_type } ] ) RETURNS TABLE ] RETURN select_stmt
O seguinte trecho de código é um exemplo de um iTVF.
CREATE OR ALTER FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN (SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Comments cWHERE c.UserId = @UserId AND c.CreationDate >= @CommentDateGROUP BY c.UserId);
Algumas coisas que vale a pena mencionar no script acima.
DEFAULT VALUE () – Pode definir valores por defeito para parâmetros e no nosso exemplo, @CommentDate tem um valor por defeito de 01 Jan 2006.
RETURNS TABLE – Retorna uma tabela virtual baseada na definição da função
SCHEMABINDING – Especifica que a função está vinculada aos objectos da base de dados que refere. Quando o esquema de encadernação é especificado, os objectos de base não podem ser modificados de forma a afectar a definição da função. A própria definição da função deve primeiro ser modificada ou abandonada para remover dependências do objecto a ser modificado (de BOL).
Locando a declaração SELECT no exemplo iTVF, é semelhante a uma consulta que se colocaria numa visualização, excepto no caso do parâmetro passado para a cláusula WHERE. Esta é uma diferença crítica.
Embora um iTVF seja semelhante a uma visualização na medida em que a definição é armazenada permanentemente na base de dados, ao termos a capacidade de passar em parâmetros temos não só uma forma de encapsular e reutilizar a lógica, mas também flexibilidade em ser capaz de consultar valores específicos que gostaríamos de passar. Neste caso, podemos imaginar uma função em linha valorizada em tabela para ser uma espécie de “vista parametrizada”.
Porquê usar um iTVF?
Antes de ficarmos presos a ver como usamos iTVFs, é importante considerar por que razão os usaríamos. Os iTVFs permitem-nos fornecer soluções de apoio a aspectos como (mas não limitados a):
- Desenvolvimento Modular
- Flexibilidade
- Anular penalidades de desempenho
Discutirei cada uma delas um pouco abaixo.
Desenvolvimento Modular
iTFVs podem incentivar boas práticas de desenvolvimento, tais como o desenvolvimento modular. Essencialmente, queremos assegurar que o nosso código é “DRY” e não repetir o código que produzimos anteriormente cada vez que é necessário num local diferente.
Ignorar os casos em que o desenvolvimento modular é levado ao nésimo grau ao custo de código passível de manutenção, os benefícios da reutilização de código e encapsulamento com iTVFs são uma das primeiras coisas que notamos.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Users u INNER JOIN dbo.Comments c ON u.Id = c.UserIdWHERE c.CreationDate >= @CommentDateGROUP BY u.Id, u.Reputation;GO
VS
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u CROSS APPLY .(u.Id, @CommentDate) c;GO
A consulta utilizando o iTVF é simples e, quando utilizada em consultas mais complicadas, pode realmente ajudar os esforços de desenvolvimento, escondendo a complexidade subjacente. Em cenários em que precisamos de ajustar a lógica na função para fins de melhoramento ou depuração, podemos fazer a alteração a um objecto, testá-lo e que uma alteração será reflectida nos outros locais a que a função é chamada.
Se tivéssemos repetido a lógica em vários locais, teríamos de fazer a mesma alteração várias vezes com o risco de erros, desvios ou outros contratempos de cada vez. Isto significa que precisamos de compreender onde reutilizamos a lógica no iTVFs, para podermos testar que não introduzimos aquelas características problemáticas conhecidas como bugs.
Flexibilidade
Quando se trata de flexibilidade, a ideia de usar a capacidade das funções para passar nos valores dos parâmetros e ser fácil de interagir com eles. Como veremos com exemplos mais tarde, podemos interagir com o iTFV como se estivéssemos a consultar uma tabela.
Se a lógica estivesse num procedimento armazenado, por exemplo, teríamos provavelmente de levar os resultados para uma tabela temporária e depois consultar a tabela temporária para interagir com os dados.
Se a lógica estivesse numa vista, não seríamos capazes de passar num parâmetro. As nossas opções incluiriam consultar a vista e depois adicionar uma cláusula WHERE fora da definição da vista. Embora não seja uma grande coisa para esta demonstração, em consultas complicadas, simplificar com um iTVF pode ser uma solução mais elegante.
Anular Penalizações de Desempenho
Para o âmbito deste artigo, não vou olhar para UDFs Common Language Runtime (CLR).
Onde começamos a ver uma divergência entre iTVFs e outros UDFs é o desempenho. Muito se pode dizer sobre o desempenho, e, na sua maioria, outros UDFs sofrem muito, com base no desempenho. Uma alternativa poderia ser reescrevê-los como iTVFs, uma vez que o desempenho é um pouco diferente para o iTFV. Eles não sofrem das mesmas penalidades de desempenho que afectam as funções escalar ou Multi Statement Table-Valued Functions (MSTVFs).
iTVFs, como o seu nome sugeriria, são simplificados no plano de execução. Com o optimizador a retirar os elementos de consulta da definição e a interagir com as tabelas subjacentes (inlining), tem mais hipóteses de obter um plano óptimo, pois o optimizador pode considerar as estatísticas das tabelas subjacentes e tem à sua disposição, outras optimizações como o paralelismo, se necessário.
Para muitas pessoas, o desempenho por si só tem sido uma grande razão para utilizar iTVFs em vez de scalar ou MSTVFs. Mesmo que ainda não se importe com o desempenho, as coisas podem mudar muito rapidamente com volumes maiores ou aplicações complicadas da sua lógica, por isso é importante compreender as armadilhas dos outros tipos de UDFs. Mais adiante neste artigo, mostraremos uma comparação básica de desempenho envolvendo iTVFs e outros tipos de UDF.
Agora que listamos algumas razões para utilizar iTVFs, vamos em frente e ver como podemos utilizá-los.
Configurar iTVF demo
Neste demo, utilizaremos a base de dados StackOverflow2010, que está disponível gratuitamente na StackOverflow via https://archive.org/details/stackexchange
Alternativamente, poderá obter a base de dados através de outras pessoas encantadoras na Brent Ozar Unlimited aqui : https://www.brentozar.com/archive/2015/10/how-to-download-the-stack-overflow-database-via-bittorrent/
Eu restaurei a base de dados StackOverflow no meu SQL Server 2016 Developer Edition local, num ambiente isolado. Vou executar uma rápida demonstração na minha versão instalada do SQL Server Management Studio (SSMS) v18.0 Preview 5. Também configurei o modo de compatibilidade para 2016 (130) e estou a executar a demonstração numa máquina com um CPU Intel i7 2.11 GHz e 16GB de RAM.
Actualizar e executar com a base de dados StackOverflow, executar o T-SQL no ficheiro de recursos 00_iTFV_Setup.sql contido neste artigo para criar os iTVFs que vamos utilizar. A lógica nestes iTVFs é simples e pode ser repetida em vários locais, mas aqui iremos escrevê-la uma vez e oferecê-la para reutilização.
Utilizar um iTVF como Tabela Virtual
Lembrar que os iTVFs não persistem em qualquer parte da base de dados. O que é persistido é a sua definição. Ainda podemos interagir com iTVFs como se fossem tabelas, por isso, a este respeito, tratamo-las como tabelas virtuais.
Os 6 exemplos seguintes mostram formas de tratar iTVFs como tabelas virtuais. Com a base de dados StackOverflow a funcionar na sua máquina, sinta-se à vontade para executar as 6 consultas seguintes da Secção 1 para ver isto por si próprio. Também as pode encontrar no ficheiro, 01_Demo_SSC_iTVF_Creating_Using.sql.
/**************************************************************************1. Using iTVFs in queries as if it were a table.**************************************************************************/DECLARE @UserId INT= 3, @CommentDate DATE= '2006-01-01T00:00:00.000';--1.1 Get specific columnsSELECT UserId, LatestCommentDateFROM dbo.itvfnGetRecentComment(3, '2006-01-01T00:00:00.000');--1.2 Get all columns SELECT *FROM dbo.itvfnGetRecentComment(@UserId, @CommentDate);--1.3 Use a default valueSELECT UserId, LatestCommentDate, TotalCommentsFROM dbo.itvfnGetRecentComment(@UserId, DEFAULT);--1.4 In the WHERE clauseSELECT u.DisplayName, u.Location, u.ReputationFROM dbo.Users uWHERE u.Reputation <=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(@UserId, DEFAULT));--1.5 In the HAVING clauseSELECT u.Location, SUM(u.Reputation) AS TotalRepFROM dbo.Users uGROUP BY u.LocationHAVING SUM(u.Reputation) >=( SELECT rc.TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT) rc);--1.6 In the SELECT clauseSELECT u.Location, CASE WHEN SUM(u.Reputation) >=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT)) THEN 'YES' ELSE 'NO' END AS InRepLimitFROM dbo.Users uGROUP BY u.Location;
Como mostrado acima, quando interagimos com iTVFs, podemos:
- Retornar a lista completa de colunas
- Retornar as colunas especificadas
- Utilizar valores por defeito, passando a palavra-chave, DEFAULT
li>Passar o iTVF na cláusula WHEREli>utilizar o iTVF na cláusula HAVINGli>utilizar o iTVF na cláusula SELECT
Para colocar isto em perspectiva, normalmente com um procedimento armazenado, inserir-se-ia o resultado definido numa mesa temporária e depois interagiria com a mesa temporária para fazer o acima referido. Com um iTVF, não há necessidade de interagir com outros objectos fora da definição da função para casos semelhantes aos 6 que acabámos de ver.
iTVFs em funções aninhadas
Embora o aninhamento de funções possa trazer os seus próprios problemas se feito de forma deficiente, é algo que podemos fazer dentro de um iTVF. Pelo contrário, quando usado apropriadamente, pode ser muito útil para esconder a complexidade.
No nosso exemplo, a função, dbo.itvfnGetRecentCommentByRep, retorna o último comentário de um utilizador, comentários totais, etc, adicionando um filtro adicional para a reputação.
SELECT DisplayName, LatestCommentDate, ReputationFROM .(3, DEFAULT, DEFAULT);GO
Quando retornamos a data do último comentário, isto é através da chamada para a outra função, dbo.itvfnGetRecentComment.
CREATE OR ALTER FUNCTION . (@UserId int, @Reputation int = 100, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN ( SELECT u.DisplayName, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) cWHERE u.Id = @UserId AND u.Reputation >= @Reputation);GO
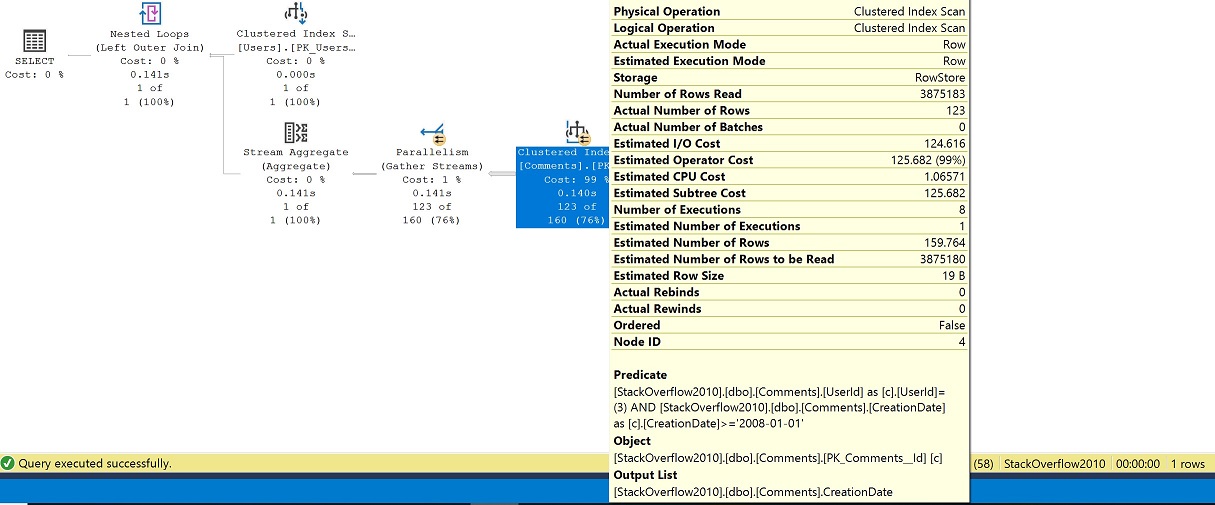
No exemplo, podemos ver que mesmo com o agrupamento de funções, a definição subjacente é alinhada e os objectos com que interagimos são os índices agrupados, dbo.Users e dbo.Comments.
No plano, sem um índice decente para suportar os nossos predicados, é realizado um scan de índice agrupado da tabela de Comentários, bem como um scan paralelo onde acabamos por obter o número de execuções como 8. Filtramos para UserId 3 a partir da tabela de Utilizadores de modo a obter uma procura na tabela de Utilizadores e depois juntamos à tabela de Comentários após o GROUP BY (agregado de fluxo) para a última data de comentários.
Using the APPLY operator
The APPLY operator offers so many creative uses, and it’s certainly an option we can apply (pun intended) to interacting with an iTVF. Para mais informações sobre o operador APLICAR, ver os seguintes documentos: https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms175156(v=sql.105) e http://www.sqlservercentral.com/articles/Stairway+Series/121318/
No exemplo seguinte queremos chamar o iTVF para todos os utilizadores e devolver o seu último ComentárioData, Comentários Totais, Id e Reputação desde 01 Jan 2008. Para tal, utilizamos o operador APPLY, onde executamos para cada linha de toda a tabela Users, passando no Id a partir da tabela Users e do CommentDate. Ao fazê-lo, mantemos os benefícios do encapsulamento da utilização do iTVF, aplicando a nossa lógica a todas as linhas da tabela Utilizadores.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
iTVFs em JOINs
Simplesmente a juntar 2 ou mais tabelas, podemos envolver o iTVFs em junções com outras tabelas. Aqui, queremos o DisplayName da tabela Users e o UserId, BadgeName e BadgeDate do iTVF, para utilizadores que obtiveram o crachá de ‘Student’ em ou após 01 Jan 2008.
DECLARE @BadgeName varchar(40)= 'Student', @BadgeDate datetime= '2008-01-01T00:00:00.000';SELECT u.DisplayName, b.UserId, b.BadgeName, b.BadgeDateFROM dbo.Users u INNER JOIN .(@BadgeName, @BadgeDate) b ON b.UserId = u.Id;GO
Alternativo a outros UDFs
Anternativo a outros UDFs
Anternativo a outros UDFs
Anternativo a outros UDFs
Anternativo a outros UDFs
Anternativo a outros UDFsAnternativo a outros UDFs Esta secção demonstrará como podemos substituir os iTVFs scalar e MSTVFs por iTVFs e a parte seguinte analisará a razão pela qual podemos optar por fazê-lo.
Scalar UDF alternativo
Antes de continuarmos, vamos executar a seguinte consulta para criar o UDF escalar, dbo.sfnGetRecentComment que usaremos em breve.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS datetimeWITH SCHEMABINDING, RETURNS NULL ON NULL INPUTASBEGIN DECLARE @LatestCreationDate datetime; SELECT @LatestCreationDate = MAX(CreationDate) FROM dbo.Comments WHERE UserId = @UserId AND CreationDate >= @CommentDate GROUP BY UserId; RETURN @LatestCreationDate;END;GO
Após criar a função escalar, executar a seguinte consulta. Aqui queremos utilizar a lógica encapsulada na função escalar para consultar toda a tabela de Utilizadores e devolver o Id e a última data de comentário de cada utilizador desde 01 de Janeiro de 2008. Fazemos isto adicionando a função na cláusula SELECT onde, para valores de parâmetros, passaremos no Id da tabela Utilizadores e a data de comentário que acabámos de definir em 01 Jan 2008.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Uma consulta semelhante pode ser escrita usando um iTVF, que é mostrado na consulta seguinte. Aqui queremos obter o Id e a data dos últimos comentários desde 01 Jan 2008 utilizando o iTVF e conseguimos isto utilizando o operador APPLY contra todas as linhas da tabela de Utilizadores. Para cada linha passamos no Id de Utilizador e data de comentário.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
alternativaMSTVF
Executar a seguinte consulta para criar o dbo.mstvfnGetRecentComment MSTVF, que utilizaremos em breve.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS @RecentComment TABLE( int NULL, date NULL, int NULL)WITH SCHEMABINDING ASBEGIN INSERT INTO @RecentComment SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalComments FROM dbo.Comments c WHERE c.UserId = @UserId AND c.CreationDate >= @CommentDate GROUP BY c.UserId; RETURN;END;GO
Agora que criámos o MSTVF, vamos utilizá-lo para devolver a data de comentários mais recente para todas as linhas da tabela de Utilizadores desde 01 Jan 2008. Tal como o exemplo do iTVF com o operador APPLY na parte anterior deste artigo, vamos “aplicar” a nossa função a todas as linhas da tabela de Utilizadores utilizando o operador APPLY e passar no Id de utilizador para cada linha, bem como a data de comentário que definimos.
DECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Quando substituímos o MSTVF no nosso exemplo por um iTVF, o resultado é muito semelhante, espera-se para o nome da função que é chamada. No nosso caso, iremos chamar-lhevfnGetRecentComment no lugar do MSTVF no exemplo anterior, mantendo as colunas na cláusula SELECT. Fazê-lo permite-nos obter o Id e a última data de comentários desde 01 Jan 2008, utilizando o iTVF para todas as linhas da tabela Users. Isto é mostrado na consulta que se segue.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
A Preferência para iTVFs
Uma razão para escolher um iTVF em vez de uma função escalar ou MSTVF é o desempenho.
Em breve capturaremos o desempenho das 3 funções com base nas consultas de exemplo que executámos na secção anterior e não entraremos em muitos detalhes, a não ser para comparar o desempenho através de métricas tais como tempo de execução e contagem de execução para as funções. O código para estatísticas de desempenho que utilizaremos ao longo desta demonstração, é do Listing 9.3 nas amostras de código da 3ª edição dos Planos de Execução do SQL Server por Grant Fritchey https://www.red-gate.com/simple-talk/books/sql-server-execution-plans-third-edition-by-grant-fritchey/
Scalar performance
Aqui está a consulta anterior que executámos invocando a função escalar.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
É bem conhecido que as funções escalares inibem o paralelismo e que uma declaração com uma função escalar é invocada uma vez para cada linha. Se a sua tabela tiver 10 filas, pode estar OK. Alguns milhares de filas, e poderá ficar surpreendido (ou não) com a drástica queda de desempenho. Vamos ver isto em acção executando o seguinte código snippet.
O que queremos fazer primeiro é limpar (num ambiente isolado) a cache do SQL Server e o plano existente que poderia ser reutilizado (FREEPROCCACHE), assegurando que obtemos primeiro os dados do disco (DROPPCLEANBUFFERS) para começar com uma cache fria. Falando vagamente, estamos a começar a partir de uma tabela limpa fazendo isto.
Depois disto, executamos a consulta SELECT na tabela Users onde retornamos o Id e o LatestCommentDate usando a função scalar. Como valores de parâmetro, passaremos no Id da tabela Utilizadores e a data do comentário que acabámos de definir para 01 Jan 2008. Um exemplo é o seguinte.
-- run in an isolated environmentCHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Embora a consulta SELECT onde utilizamos a função escalar possa parecer simples em estrutura, após 4 minutos na minha máquina, ainda estava a executar.
Rechamada que para funções escalares, executam uma vez para cada linha. O problema com isto é que as operações linha a linha são muito raramente a forma mais eficiente de recuperação de dados no SQL Server em comparação com as operações baseadas em conjuntos únicos.
Para observar execuções repetidas, podemos executar uma consulta para algumas estatísticas de desempenho. Estes são recolhidos pelo SQL Server quando executamos as nossas consultas e aqui, queremos obter a declaração de consulta, tempo de criação, contagem da execução da declaração, bem como o plano de consulta. A consulta seguinte é um exemplo de como podemos obter as estatísticas de desempenho.
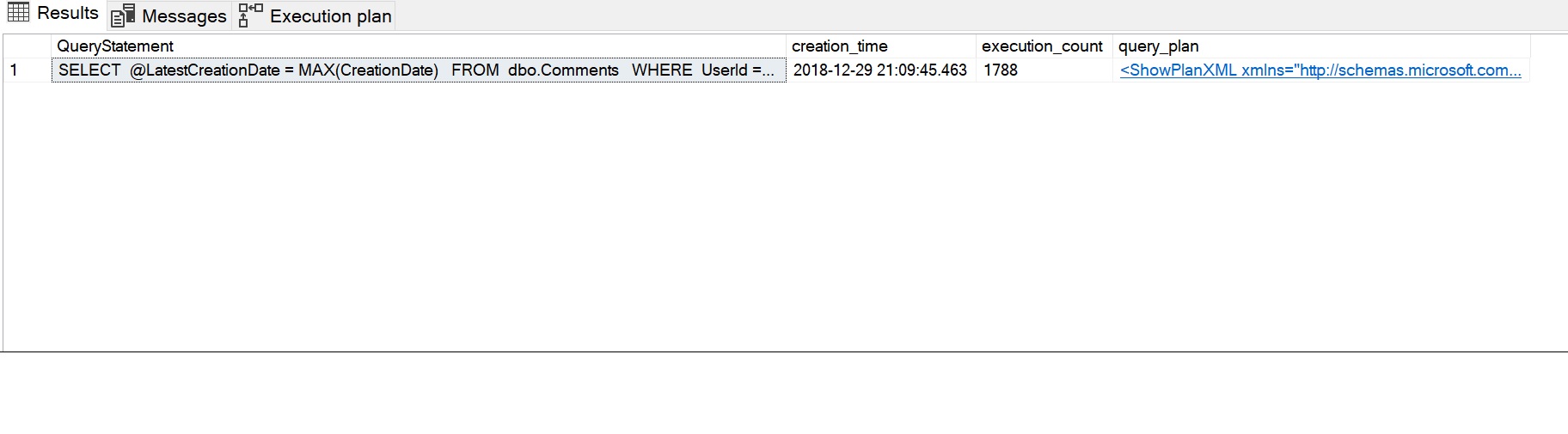
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.sfnGetRecentComment')ORDER BY deqs.last_execution_time DESC;GO
A execução resultante das estatísticas de desempenho pode ser vista na imagem seguinte. A declaração de consulta mostra a declaração SELECT utilizada pela função escalar, a contagem de execução de 1788 captou a contagem de execução repetida (uma vez para cada linha) e o plano que é utilizado pela função pode ser visualizado clicando na mensagem XML do plano de consulta.
Uma forma adicional de ver importantes métricas de desempenho é através da utilização de eventos alargados. Para mais sobre eventos alargados, clique aqui, mas para efeitos da nossa demonstração, execute a seguinte consulta para criar uma sessão de eventos alargada.
CREATE EVENT SESSION QuerySession ON SERVER ADD EVENT sqlserver.module_end( WHERE (.(.,(??)))), -- enter your Session Id ADD EVENT sqlserver.sp_statement_completed( WHERE (.(.,(??)))),-- enter your Session Id ADD EVENT sqlserver.sql_batch_completed( WHERE (.(.,(??)))); -- enter your Session IdGOALTER EVENT SESSION QuerySession ON SERVER STATE = START;GO
Após a sessão de eventos alargada ter sido criada, vá a Gestão no Explorador de Objectos, expanda sessões e abra o menu de contexto para “QuerySession” que acabámos de criar. Seleccione “Watch live data”.
Na janela recentemente aberta, observe as múltiplas linhas de declaração da função escalar como evidência das execuções repetidas.
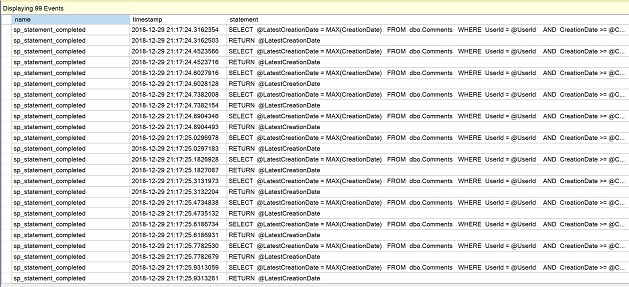
Clique no quadrado vermelho para “Stop data feed” por agora.
desempenhoMSTVF
Para MSTVFs, também pode haver penalidades de desempenho como resultado da sua utilização e isto está ligado ao SQL Server que escolhe planos de execução sub óptimos devido a estatísticas inexactas. O SQL Server depende de estatísticas capturadas internamente para compreender quantas linhas de dados uma consulta retornará para que possa produzir um plano óptimo. Este processo de é conhecido como estimativa de cardinalidade.
P>Prior para SQL Server 2014, a estimativa de cardinalidade para variáveis da tabela foi definida em 1 linha. A partir do SQL Server 2014, esta é definida em 100 filas, independentemente de estarmos a consultar 100 filas ou 1 milhão de filas. As MSTVFs retornam dados através de variáveis de tabela que são declaradas no início da definição da função. A realidade é que o optimista não procurará o melhor plano que possa encontrar, independentemente do tempo, e deve manter um equilíbrio (dito de forma muito simples). Com as MSTVFs, a falta de estatísticas precisas (causada pela estimativa inexacta da cardinalidade das variáveis da tabela dentro da sua definição) pode inibir o desempenho, fazendo com que o optimizador produza planos sub óptimos.
Na prática, a substituição das MSTVFs por iTVFs pode trazer um melhor desempenho, uma vez que as iTVFs utilizarão as estatísticas das tabelas subjacentes.
O seguinte trecho de código utiliza o operador APLICAR para executar a MSTVF contra toda a tabela de Utilizadores. Devolvemos o Id da tabela de Utilizadores e o LatestCommentDate da função para cada linha da tabela de Utilizadores, passando no Id do utilizador e a data de comentário que está definida para 01 Jan 2008. Semelhante à função escalar executada, fá-lo-emos a partir de uma cache fria. Com este teste, também temos o plano de execução real seleccionado em SSMS, clicando em Ctrl + M. Executar a consulta.
CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
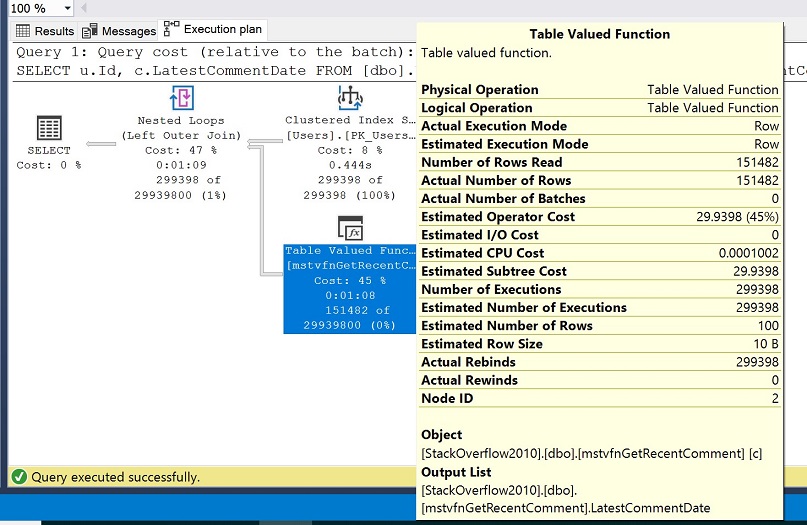
O plano de execução resultante é mostrado na imagem seguinte e na caixa de propriedades amarela, observe os valores para o número estimado de linhas vs o número real de linhas.
Vocês devem ver que o número estimado de linhas da função de valor da tabela está definido em 100 mas o número real de linhas está definido em 151.482. Recordando na nossa configuração, escolhemos o modo de compatibilidade do SQL Server 2016 (130) e que a partir do SQL Server 2014, a estimativa da cardinalidade está definida em 100 para as variáveis da tabela.
Tantos valores diferentes para o número estimado de linhas versus o número real de linhas prejudicam tipicamente o desempenho e podem impedir-nos de obter planos mais optimizados e, em última análise, de executar melhor as consultas.
Simplesmente semelhante à função escalar que executámos anteriormente, executaremos uma consulta contra as estatísticas de desempenho do SQL Server. Aqui também queremos obter a declaração de consulta, o tempo de criação, a contagem de execução da declaração e o plano de consulta utilizado e filtrar para o MSTVF na cláusula WHERE.
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs OUTER APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp OUTER APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.mstvfnGetRecentComment');
O plano de execução que observámos inicialmente para o MSTVF é enganador, uma vez que não reflecte o trabalho real realizado pela função. Utilizando as estatísticas de desempenho que acabámos de executar e seleccionando o Showplan XML, devemos ver um plano de consulta diferente que mostre o trabalho que está a ser feito pelo MSTVF. Um exemplo do plano diferente do que vimos inicialmente é o seguinte. Aqui podemos agora ver que o MSTVF insere dados numa variável de tabela chamada @RecentComment. Os dados na variável da tabela @RecentComment é o que é então devolvido pelo MSTVF para devolver a data do último comentário.
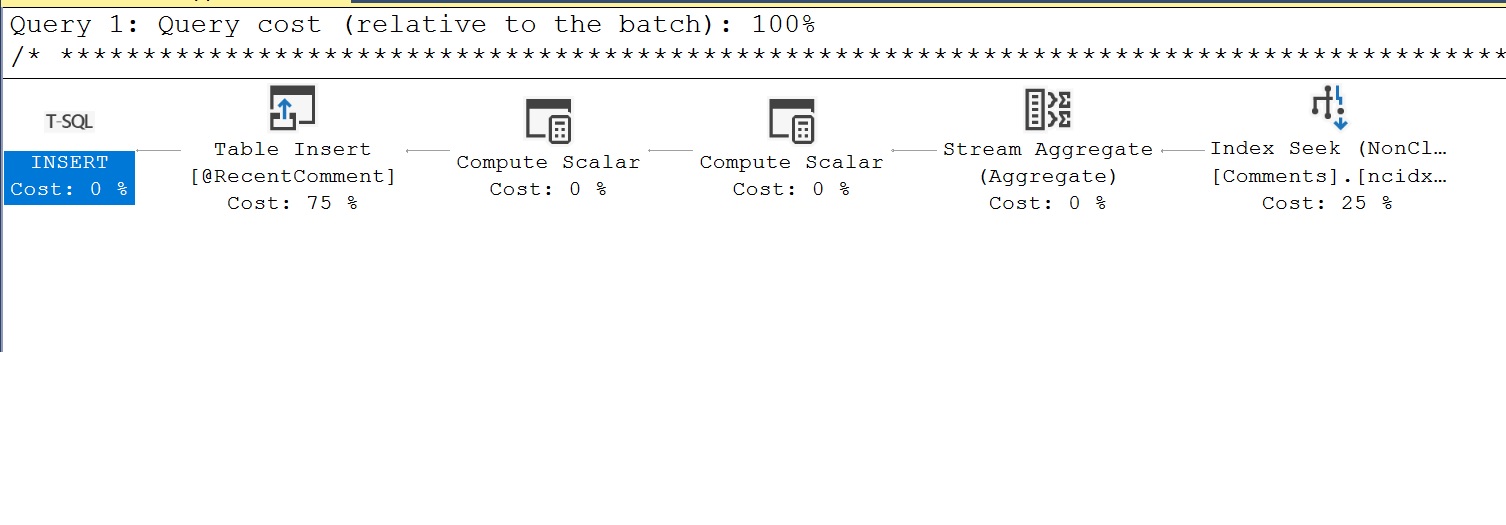
Um outro aspecto da métrica de desempenho que capturámos é a contagem da execução. Aqui queremos desconfiar da contagem de execução múltipla, pois estas são tipicamente más para o desempenho, como mencionado quando olhamos para o desempenho escalar.
O que vemos na imagem seguinte para contagem de execução, é um valor de 76 que é a evidência de múltiplas execuções do nosso MSTVF.

Deixe-nos voltar à Gestão no Explorador de Objectos, expandir sessões e seleccionar “Ver dados ao vivo” para a sessão “QuerySessions” que criámos anteriormente quando olhámos para a performance escalar. Clique no triângulo verde “Start data feed” no SSMS se a sessão foi interrompida anteriormente e devemos ver para o nosso exemplo, múltiplas linhas de declaração do MSTVF que representam as execuções repetidas da declaração.
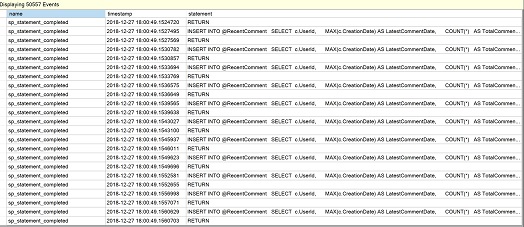
Feel free to cancel the query at this point if it has not completed yet.
iTVF performance
Quando substituímos as funções escalar ou multi declaração por um iTVF, queremos fazê-lo para evitar as penalizações de performance que acabámos de ver, por exemplo, tempo de execução, múltiplas execuções. Utilizando o exemplo anterior que se segue, consultaremos a tabela Utilizadores para obter o Id e a Última Data de Comentário do iTVF desde 01 Jan 2008. utilizando o operador APPLY. Também o faremos a partir de uma cache fria, limpando a cache do SQL Server e obtendo dados do disco para começar com.
--run in an isolated environment CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
A consulta seguinte consiste nas estatísticas de desempenho que nos ajudam a ver a declaração que está a ser executada, a contagem da execução e o plano de consulta para essa declaração.
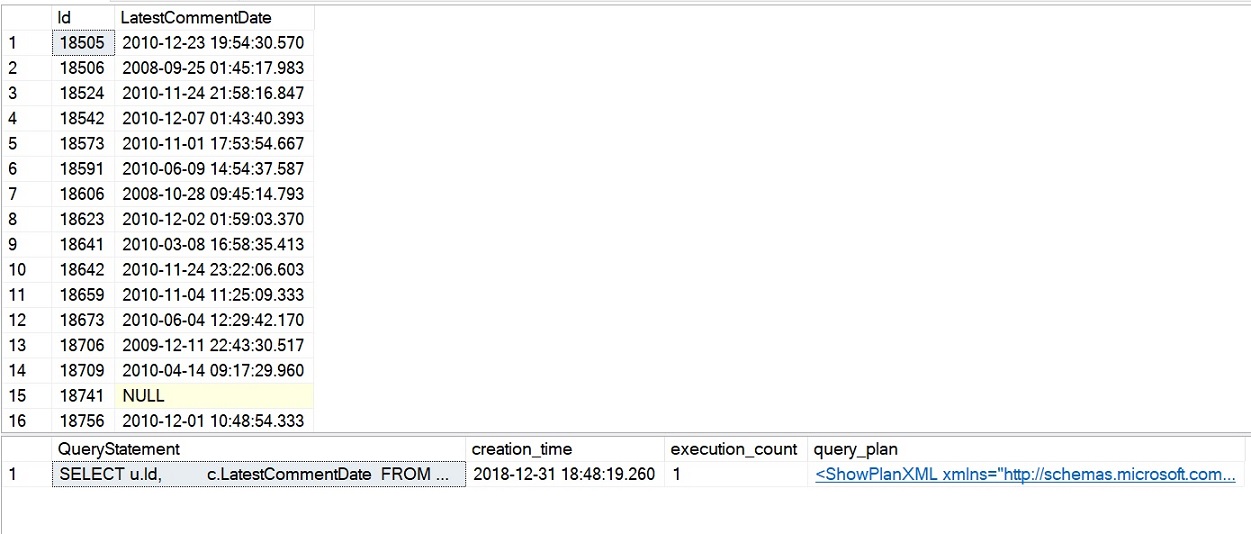
-- Query stats and execution planSELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.dbid = DB_ID('StackOverflow2010')ORDER BY deqs.last_execution_time DESC;
A consulta de exemplo para o iTVF que acabámos de executar foi concluída em pouco mais de 4 segundos e as estatísticas de desempenho que consultamos devem mostrar uma contagem de execução de 1 para o iTVF, conforme mostrado na imagem seguinte. Isto é uma melhoria marcada no desempenho em comparação com os nossos exemplos anteriores com tentativas scalar e MSTFV.
Comparando o desempenho scalar, MSTVF e iTVF
A tabela seguinte captura a comparação dos 3 UDFs que acabámos de executar para mostrar como eles funcionavam em termos de tempo de execução e contagem de execução.
| >/td>>>Scalar | MSTVF | iTVF | |
| Tempo de execução | > 5 minutos | > 5 minutos | 4 segundos |
| Contagem de execução | > 10,000 | >10,000 | 1 |
A diferença no tempo de execução e contagem de execução através da utilização do iTVF é imediatamente visível. No nosso exemplo, o iTVF devolveu os mesmos dados mais rapidamente e com apenas 1 execução. Em ambientes onde há cargas de trabalho pesadas ou para cenários onde a lógica é utilizada em múltiplos relatórios que são lentos devido à utilização escalar ou MSTVF, uma alteração a um iTVF pode ajudar a aliviar sérios problemas de desempenho.
Limitações
iTVFs entram realmente em jogo quando é necessário reutilizar a lógica sem sacrificar o desempenho, mas não são perfeitos. Também elas têm limitações.
Para uma lista de limitações e restrições de funções definidas pelo utilizador em geral, pode visitar Livros Online aqui. Fora dessa lista e especificamente para funções valorizadas em tabelas em linha, os seguintes são pontos gerais a ponderar ao avaliar se são a ferramenta certa para um problema que possa ter.
Declaração SELECT única
Como a definição de um iTVF é restrita a 1 declaração SELECT, as soluções que requerem lógica para além dessa 1 declaração SELECT onde talvez seja necessária a atribuição de variáveis, lógica condicional ou utilização de tabelas temporárias, provavelmente não são adequadas à implementação apenas num iTVF.
Controlo de erros
Esta é uma restrição que afecta todas as funções definidas pelo utilizador onde construções como TRY CATCH não são permitidas.
Chamar procedimentos armazenados
Não se pode chamar procedimentos armazenados a partir do corpo do iTVF, a menos que seja um procedimento armazenado alargado. Isto está ligado a um princípio do desenho UDF do SQL Server onde não pode alterar o estado da base de dados, que se utilizasse um procedimento armazenado, poderia.
Conclusion
Este artigo começou com a intenção de revisitar as funções avaliadas em tabela em linha (iTVFs) tal como estão actualmente em 2016, mostrando a variedade de formas como podem ser utilizadas.
iTVFs têm um benefício chave na medida em que não sacrificam o desempenho ao contrário de outros tipos de funções definidas pelo utilizador (UDFs) e podem encorajar boas práticas de desenvolvimento com as suas capacidades de reutilização e encapsulamento.
Com características recentes no SQL Server, primeiro no SQL Server 2017 e no próximo SQL Server 2019, o desempenho de qualquer uma das funções escalar e MSTVFs tem alguma ajuda extra. Para mais detalhes, verifique a execução intercalada que procura fornecer uma estimativa precisa da cardinalidade para MSTVFs em vez dos números fixos ou de 1 ou 100 e UDFs escalares. Com o revestimento UDF escalar em 2019, o foco está em abordar a fraqueza do desempenho dos UDFs escalares.
Para as suas soluções, certifique-se de testar e estar ciente das suas limitações. Quando bem utilizados, são uma das melhores ferramentas que poderíamos ter no nosso arsenal SQL.
Agradecimentos de leitura.