Optimierung, eines der elementaren Probleme der mathematischen Physik, Wirtschaftswissenschaften, Ingenieurwesen und vielen anderen Bereichen der angewandten Mathematik, ist das Problem, den maximalen oder minimalen Wert einer Funktion, genannt Zielfunktion, sowie die Werte der Eingangsvariablen zu finden, bei denen dieser optimale Wert auftritt. In der elementaren Ein-Variablen-Rechnung ist dies ein sehr einfaches Problem, das darauf hinausläuft, die Werte von x zu finden, für die df/dx gleich Null ist.
Multivariable Optimierungsprobleme sind komplizierter, weil wir Nebenbedingungen auferlegen können. Wir betrachten Nebenbedingungen, die in der Form g(x,y,z)=c für eine Funktion g und eine Konstante c ausgedrückt werden können. Diese werden Gleichheitsbedingungen genannt, und die Menge der Punkte, die diese Bedingungen erfüllen, wird als die machbare Menge bezeichnet, die wir mit S bezeichnen. Wenn wir z. B. den Maximalwert von f(x,y) auf dem Einheitskreis finden sollen, dann ist g(x,y)=x²+y², da der Einheitskreis durch x²+y²=1 definiert ist.
Das Standardverfahren zum Lösen dieser Art von Problemen ist die Methode der Lagrange-Multiplikatoren. In diesem Artikel werde ich die Methode herleiten und einige Demonstrationen ihrer Anwendung geben.
Motivation und Herleitung
Eine Funktion f hat ein lokales Extremum (Maximum oder Minimum) in einem Punkt P, wenn die partielle Ableitung von f für jede der unabhängigen Variablen Null ist und wenn der Punkt kein Sattelpunkt ist (eine Situation, mit der wir uns hier nicht beschäftigen müssen). Wir können dies in kompakter Form als ∇f=0 schreiben, wobei ∇ den Gradientenoperator bezeichnet:
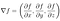
In der eingeschränkten Optimierung, folgt jedoch aus der Tatsache, dass f ein lokales Maximum oder Minimum an einem Punkt auf der machbaren Menge hat, nicht, dass f an diesem Punkt seinen optimalen Wert auf der machbaren Menge annimmt.
Betrachten wir als Beispiel das folgende Optimierungsproblem:
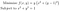
Indem wir den Gradienten ausschreiben, können wir sehen, dass f ein lokales Minimum hat, wenn x=0 und y=1 ist:

Außerdem, f(0,1)=0, aber f(0,-1)=-4. Obwohl (0,1) ein lokales Minimum von f(x,y) ist, ist es nicht das Minimum von f(x,y) auf dem Einheitskreis.
Als weiteres Beispiel wollen wir f(x,y)=y auf dem Einheitskreis maximieren. Der Gradient von f(x,y)=y ist ein konstanter Vektor, so dass f(x,y) keine lokalen Maxima oder Minima hat, aber auf dem Einheitskreis hat f einen Maximalwert von 1, der bei (0,1) auftritt.
Der Grund für diesen Fehler ist, dass der Gradient die Änderungsrate von f(x,y,z) in Bezug auf die Position im dreidimensionalen Raum misst, wir aber die Änderungsrate von f(x,y,z) in Bezug auf die Position in der machbaren Menge messen wollen. Für ein dreidimensionales Problem wird S entweder eine Kurve oder eine Fläche sein, und im Allgemeinen für Probleme mit n Variablen wird S eine Hyperfläche der Dimension streng kleiner als n sein.
Der natürlichste Ansatz ist die Betrachtung von Kurven in S. Sei P ein Punkt in S, für den f(P) einen lokal optimalen Wert in S annimmt, aber ∇f(P) nicht notwendigerweise Null ist, und sei r(t) die Parametrisierung einer beliebigen Kurve in S, die durch P geht, also:

Wenn S eine Kurve ist, dann ist r(t) nur eine Parametrisierung von S. Außerdem sei r(T)=P, r′(T)≠0, und h(t) = f(r(t)), so dass h′(T)=0. Erweitern wir h′(t) mit Hilfe der Kettenregel:

Da r(t) immer in S liegt, muss der Geschwindigkeitsvektor r′(t) immer tangential zur Oberfläche oder Kurve von S sein, denn wenn r′(t) eine Komponente senkrecht zur Oberfläche hätte, also von der Oberfläche weg gerichtet wäre, dann gäbe es Punkte, an denen r(t) S verlässt. Da dies für jede Kurve r(t) gilt, die durch P verläuft, folgt daraus, dass ∇f(P) senkrecht zu jedem Tangentenvektor an die Oberfläche in P ist. Wenn also P ein Punkt ist, an dem f einen maximalen oder minimalen Wert in Bezug auf die Position in S annimmt, dann ist ∇f(P) senkrecht zu S.
Der Umkehrschluss ist ebenfalls wahr: Da r′(T) niemals Null und immer parallel zu S ist, dann ist, wenn ∇f(P) senkrecht zu S ist, h′(T)=∇f(P)∙r′(T)=0.
Aber wie finden wir eigentlich Punkte, an denen ∇f senkrecht zu S ist? Hier ist die Antwort: Die Menge S ist die Menge aller Punkte, bei denen g(x,y,z)=c ist, d.h. S ist eine Ebenenmenge von g. Das bedeutet, dass ∇g für alle Punkte in S senkrecht auf S steht, also sind ∇f und ∇g an den Punkten in S parallel, an denen f optimale Werte annimmt. Das bedeutet, dass f seine optimalen Werte in S genau dann annimmt, wenn ∇f=λ∇g für irgendeine Konstante λ. Die Konstante λ wird der unbestimmte Lagrange-Multiplikator genannt, und daher hat die Methode ihren Namen. Das Problem der Optimierung von f kann nun gelöst werden, indem man vier Unbekannte x, y, z und λ findet, die diese vier Gleichungen lösen:
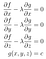
Mit anderen Worten, unser Ziel ist es nun, die Funktion f-λg in Bezug auf x, y und z ohne Nebenbedingungen zu optimieren, indem wir den Punkt finden, an dem ∇(f-λg)=0 ist.
Was ist, wenn es mehr als eine Nebenbedingung gibt? Nehmen wir nun an, dass wir f(x,y,x) in Abhängigkeit von g(x,y,z)=c und h(x,y,z)=d optimieren müssen. Wir gehen folgendermaßen vor. Um f in Abhängigkeit von g(x,y,z)=c zu optimieren, optimieren wir f-λg ohne Nebenbedingung, so dass die erste Nebenbedingung durch Ersetzen von f durch f-λg erledigt ist und es bleibt, f-λg in Abhängigkeit von der Nebenbedingung h(x,y,z)=d zu optimieren. Dies ist ein Problem mit nur einer Nebenbedingung, also fügen wir einfach einen weiteren Lagrange-Multiplikator μ hinzu, und das Problem besteht nun darin, f-λg-μh ohne Nebenbedingung zu optimieren.
Lassen Sie uns nun einige Beispiele betrachten.
Der maximale Flächeninhalt eines Rechtecks
Was ist für einen gegebenen Umfang der größtmögliche Flächeninhalt eines Rechtecks mit diesem Umfang? Wir können dies als ein Lagrange-Multiplikator-Problem formulieren. Wenn die Breite und Höhe x und y sind, dann wollen wir f(x,y)=xy für g(x,y)=2x+2y=c maximieren. Das resultierende Gleichungssystem ist:
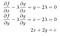
Die ersten beiden Gleichungen sagen uns gleich, dass x=y ist, also tritt die maximale Fläche auf, wenn das Rechteck ein Quadrat ist. Wenn wir dies in die dritte Gleichung einsetzen, sehen wir, dass x=y=c/4 ist, so dass der maximale Flächeninhalt eines Rechtecks mit dem Umfang c c²/16 ist.
Ein (modifiziertes) Putnam-Problem
Der mathematische Putnam-Wettbewerb ist ein Wettbewerb im Prüfungsformat, der jedes Jahr im Dezember für Studenten im Grundstudium angeboten wird. Die Studenten haben sechs Stunden Zeit, um 12 extrem anspruchsvolle Probleme zu lösen. Die Prüfung ist so schwierig, dass von einer möglichen Punktzahl von 120 in den meisten Jahren die durchschnittliche Punktzahl 0 oder 1 ist. Heute schauen wir uns eine modifizierte Version (der Einfachheit halber und um Urheberrechtsprobleme zu vermeiden) von Problem A3 aus der Prüfung 2018 an:

Es gibt zwei Probleme. Das erste ist, dass die Zielfunktion eine sehr unerwünschte Eigenschaft hat: Sie ist eine Summe von Kosinusfunktionen, und Summen von trigonometrischen Funktionen können schwer zu handhaben sein. Das zweite ist, dass es keine Möglichkeit gibt, die Zwangsbedingungsfunktion sauber und explizit in der Zielfunktion erscheinen zu lassen, auch wenn es auf den ersten Blick so aussieht, als ob dies möglich sein sollte. Bei Putnam-Problemen gibt es oft „Fallen“ wie diese, bei denen man dazu verleitet werden kann, Zeit mit einem Ansatz zu verschwenden, der nicht zu einer Lösung führt, wenn man nicht aufhört, darüber nachzudenken, was man tut. Es ist eine Falle, die besonders gefährlich für einen Teilnehmer mit Erfahrung in Mathematikwettbewerben der Oberstufe wäre, wo trigonometrische Identitäten tendenziell einen starken Schwerpunkt darstellen.
Wenn wir aber ein Problem sehen, das besagt „maximiere f in Abhängigkeit von g=0“, sollten wir sofort an Lagrange-Multiplikatoren denken. Lassen Sie uns unser Gleichungssystem aufstellen:

Jetzt können wir unsere Trigonometrie-Identitäten verwenden, um die Nebenbedingung explizit zu machen. Schreiben Sie das Gleichungssystem mit Hilfe der Doppelwinkelformel um:
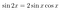
Das Ergebnis ist:

Nun heben Sie die Sinusfunktion auf jeder Seite auf, und addieren Sie die Gleichungen:
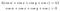
Und das bedeutet, dass λ=0, nach den Lagrange-Multiplikator-Gleichungen bedeutet dies also, dass:

Daher sind w, x, y und z alle ganzzahlige Vielfache von π/2 sind. Für gerade ganzzahlige Vielfache von π/2 sei m=2k für irgendeine ganze Zahl k:

Aber wenn m eine ungerade ganze Zahl ist, dann ist cos(mπ/2)=0. Das bedeutet, dass wir drei Möglichkeiten haben, wie wir die Zwangsbedingungsgleichung erfüllen können. Erstens können wir w, x, y und z alle auf ungerade ganzzahlige Vielfache von π/2 setzen, sagen wir k, l, m und n, dann:

Die erste Zeile zeigt, dass die Zwangsgleichung erfüllt ist, und die zweite Zeile ist das Ergebnis des Einsetzens dieser Werte in die Zielfunktion, was uns -4 ergibt.
Die zweite Möglichkeit ist, dass wir zwei der Variablen auf ungerade ganzzahlige Vielfache von π/2 setzen können, z. B. k und l, und die anderen beiden auf gerade ganze Zahlen, z. B. 2m und 2n, wobei m gerade und n ungerade ist. Das Ergebnis des Einsetzens in die Zwangsbedingungsgleichung ist:

So ist die Zwangsgleichung erfüllt. Hier ist das Ergebnis des Einsetzens in die Zielfunktion:

Die letzte Möglichkeit ist, dass wir alle Variablen auf gerade ganzzahlige Vielfache von π/2 setzen können, sagen wir 2k, 2l, 2m und 2n, wobei k und l gerade und m und n ungerade sind. Das Ergebnis des Einsetzens in die Zwangsgleichung ist:

So ist die Nebenbedingung erfüllt. Nun setzen wir diese in die Zielfunktion ein und erhalten:

Die Antwort ist also 4, was sich zufälligerweise als der globale Maximalwert der Zielfunktion herausstellt.
Schauen Sie sich diesen anderen Artikel an, den ich für eine Diskussion eines anderen Putnam-Problems geschrieben habe.
Thomson’s Theorem
Anstatt eine Funktion zu optimieren, lassen Sie uns nun die Methode der Lagrange-Multiplikatoren verwenden, um ein Funktional zu optimieren: ein Objekt, das eine Funktion annimmt und eine Zahl zurückgibt. Definite Integrale sind ein wichtiges Beispiel. Diese letzte Demonstration wird zeigen, wie die Methode der Lagrange-Multiplikatoren verwendet werden kann, um die Funktion zu finden, die den Wert eines bestimmten Integrals minimiert.
Zur Demonstration betrachten wir eine grundlegende Tatsache aus der Elektrostatik, der Untersuchung von Systemen, die elektrischen Kräften im mechanischen Gleichgewicht ausgesetzt sind, so dass keine der Ladungen in Bewegung ist. Wir werden zeigen, dass, wenn ein Leiter, ein Körper, in dem sich elektrische Ladungen frei bewegen können, mit einem beliebigen System elektrischer Kräfte im Gleichgewicht ist, dann gibt es kein elektrisches Feld innerhalb des Körpers des Leiters. Dies ist das Thomson’sche Theorem. Dieses Theorem wird üblicherweise in Bezug auf die fundamentale physikalische Tatsache formuliert, dass die Energie eines Systems im stabilen mechanischen Gleichgewicht minimal ist:
Thomson’s Theorem: Die elektrostatische Energie eines leitenden Körpers fester Größe und Form ist minimiert, wenn die Ladungen so verteilt sind, dass das Potential ϕ im Körper konstant ist, so dass E=-∇ϕ=0.
Lassen Sie ρ(r) die Ladungsverteilungsfunktion und ϕₑₓₜ das Potential aufgrund beliebiger Quellen außerhalb des leitenden Körpers sein. Die gesamte elektrostatische Energie kann als ein Funktional U von ρ(r) ausgedrückt werden:

Dies sind Volumenintegrale über den Körper des Leiters. Das erste Integral ist ein Doppelintegral, das zuerst über die grundierten Koordinaten und dann über die nicht grundierten Koordinaten geführt wird. Wir wollen U als Funktion von ρ(r) minimieren, da die Gesamtladung unabhängig von der Ladungsverteilung ist:
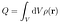
Glücklicherweise, funktioniert die Methode der Lagrange-Multiplikatoren für Funktionale mit Nebenbedingungen. Führen Sie einen unbestimmten Lagrange-Multiplikator ein, und führen Sie dann anstelle der beschränkten Optimierung auf U eine unbeschränkte Optimierung auf dem folgenden Funktional durch:
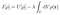
In Analogie zu den Ableitungen von Funktionen, ist es hier das Ziel, die Ladungsverteilung ρ so zu finden, dass bei einer kleinen Änderung von ρ, δρ, die Änderung von I, δI, Null ist:
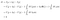
Das ist nicht ganz eine Ableitung, weil δρ eine Funktion und keine Zahl ist, so dass es nicht wirklich Sinn macht, vom Grenzwert zu sprechen, wenn δρ gegen Null geht, aber die grundlegende Intuition ist die gleiche.
Lassen Sie uns mit der Erweiterung von U beginnen:

Das mag schlecht aussehen, aber wir können dies stark vereinfachen. Zuerst, da δρ sehr klein ist, ist (δρ)² so klein, dass wir es ignorieren können, also nehmen wir an, dass δρ(r)δρ(r′)=0. Als nächstes sehen wir, indem wir die Reihenfolge der Integration ändern, dass:

Wir können auch sehen, dass U in der Expansion auftaucht. Damit haben wir genug, um U zu vereinfachen:

Nun können wir δI erweitern:

Nun können wir das Integral über δρ(r) ausrechnen:

Damit dies für jede Wahl der Variation δρ(r) gilt, muss der eingeklammerte Term Null sein, also:

Aber dieses Integral ist nur das Potential an r aufgrund der Ladungen im Inneren des Leiters, also gibt die linke Seite dieser Gleichung das Gesamtpotential an jedem Punkt r im Inneren des Leiters an, ρ(r) ist also die Verteilung, die das Gesamtpotenzial im Inneren des Leiters konstant macht. Dies vervollständigt den Beweis.
Dies würde auch gelten, wenn die elektrostatische Energie des Leiters maximiert ist, in diesem Fall ist der Leiter in einem instabilen Gleichgewicht. In der Praxis trifft man eigentlich nie auf Leiter im instabilen Gleichgewicht, weil die zufällige thermische Bewegung der Elektronen im Leiter das System schnell, in der Größenordnung von 10-¹⁴ Sekunden bei Metallleitern, aus dem instabilen Gleichgewicht in ein stabiles Gleichgewicht bringt.