L’optimisation, un des problèmes élémentaires de la physique mathématique, l’économie, l’ingénierie et de nombreux autres domaines des mathématiques appliquées, est le problème qui consiste à trouver la valeur maximale ou minimale d’une fonction, appelée fonction objectif, ainsi que les valeurs des variables d’entrée où cette valeur optimale se produit. En calcul élémentaire à une variable, c’est un problème très simple qui revient à trouver les valeurs de x pour lesquelles df/dx est nul.
Les problèmes d’optimisation multivariable sont plus compliqués car nous pouvons imposer des contraintes. Nous considérons les contraintes qui peuvent être exprimées sous la forme g(x,y,z)=c pour une certaine fonction g et une constante c. Ces contraintes sont appelées contraintes d’égalité, et l’ensemble des points satisfaisant ces contraintes est appelé ensemble réalisable, que nous désignons par S. Par exemple, si on nous demande de trouver la valeur maximale de f(x,y) sur le cercle unitaire, alors g(x,y)=x²+y² puisque le cercle unitaire est défini par x²+y²=1.
La technique standard pour résoudre ce type de problème est la méthode des multiplicateurs de Lagrange. Dans cet article, je vais dériver la méthode et donner quelques démonstrations de son utilisation.
Motivation et dérivation
Une fonction f a un extremum local (maximum ou minimum) en un point P lorsque la dérivée partielle de f est nulle pour chacune des variables indépendantes et lorsque le point n’est pas un point de selle (une situation que nous n’aurons pas besoin de traiter ici). Nous pouvons écrire cela sous forme compacte sous la forme ∇f=0, où ∇ désigne l’opérateur de gradient :
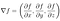
En optimisation sous contraintes, cependant, ce n’est pas parce que f a un maximum ou un minimum local en un point de l’ensemble réalisable que f prend sa valeur optimale sur l’ensemble réalisable en ce point.
À titre d’exemple, considérons le problème d’optimisation suivant :
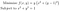
En écrivant le gradient, nous pouvons voir que f a un minimum local lorsque x=0 et y=1 :

De plus, f(0,1)=0, mais f(0,-1)=-4 donc bien que (0,1) soit un minimum local de f(x,y), il n’est pas le minimum de f(x,y) sur le cercle unitaire.
Pour un autre exemple, maximisons f(x,y)=y sur le cercle unitaire. Le gradient de f(x,y)=y est un vecteur constant, de sorte que f(x,y) n’a pas de maxima ou de minima locaux, mais sur le cercle unitaire, f a une valeur maximale de 1, survenant à (0,1).
La raison de cet échec est que le gradient mesure le taux de changement de f(x,y,z) par rapport à la position dans l’espace tridimensionnel, mais nous voulons mesurer le taux de changement de f(x,y,z) par rapport à la position dans l’ensemble réalisable. Pour un problème tridimensionnel, S sera soit une courbe, soit une surface, et en général pour les problèmes à n variables, S sera une hypersurface de dimension strictement inférieure à n.
L’approche la plus naturelle est de considérer des courbes dans S. Soit P un point dans S pour lequel f(P) prend une valeur localement optimale dans S mais ∇f(P) n’est pas nécessairement nulle, et soit r(t) la paramétrisation de toute courbe dans S qui passe par P, c’est-à-dire :

Si S est une courbe, alors r(t) est juste une paramétrisation de S. De plus, laissons r(T)=P, r′(T)≠0, et laissons h(t) = f(r(t)) de sorte que h′(T)=0. Développons h′(t) en utilisant la règle de la chaîne :

Puisque r(t) est toujours dans S, le vecteur vitesse r′(t) doit toujours être tangent à la surface ou à la courbe de S puisque si r′(t) avait une composante perpendiculaire à la surface, c’est-à-dire dirigée vers l’extérieur de la surface, alors il y aurait des points où r(t) quitte S. Puisque ceci est vrai de toute courbe r(t) qui passe par P, il s’ensuit que ∇f(P) est perpendiculaire à tout vecteur tangent à la surface en P. Ainsi, si P est un point où f prend une valeur maximale ou minimale par rapport à la position dans S, alors ∇f(P) est perpendiculaire à S.
L’inverse est également vrai : puisque r′(T) n’est jamais nul et toujours parallèle à S, alors si ∇f(P) est perpendiculaire à S, alors h′(T)=∇f(P)∙r′(T)=0.
Mais comment trouver réellement les points où ∇f est perpendiculaire à S ? Voici la réponse : L’ensemble S est l’ensemble de tous les points où g(x,y,z)=c, c’est-à-dire que S est un ensemble de niveau de g. Cela signifie que ∇g est perpendiculaire à S pour tous les points de S, donc ∇f et ∇g sont parallèles aux points de S où f prend ses valeurs optimales. Cela signifie que f prend ses valeurs optimales dans S précisément lorsque ∇f=λ∇g pour une certaine constante λ. La constante λ est appelée le multiplicateur indéterminé de Lagrange, et c’est de là que la méthode tire son nom. Le problème de l’optimisation de f peut maintenant être résolu en trouvant quatre inconnues x, y, z et λ qui résolvent ces quatre équations :
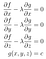
Dit autrement, notre objectif est maintenant d’optimiser la fonction f-λg par rapport à x, y et z sans contraintes en trouvant où ∇(f-λg)=0.
Qu’en est-il s’il y a plus d’une contrainte ? Supposons maintenant que nous devons optimiser f(x,y,x) sous réserve de g(x,y,z)=c et h(x,y,z)=d. Voici ce que nous faisons. Pour optimiser f soumis à g(x,y,z)=c, on optimise f-λg sans contrainte, donc la première contrainte est prise en charge en remplaçant f par f-λg, et il reste à optimiser f-λg soumis à la contrainte h(x,y,z)=d. C’est un problème avec une seule contrainte, donc nous ajoutons simplement un autre multiplicateur de Lagrange μ, et le problème consiste maintenant à optimiser f-λg-μh sans contrainte.
Voyons maintenant quelques exemples.
L’aire maximale d’un rectangle
Pour un périmètre donné, quelle est la plus grande aire possible d’un rectangle avec ce périmètre ? Nous pouvons formuler cela comme un problème de multiplicateur de Lagrange. Si la largeur et la hauteur sont x et y, alors nous souhaitons maximiser f(x,y)=xy pour g(x,y)=2x+2y=c. Le système d’équations résultant est :
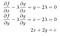
.
Les deux premières équations nous indiquent d’emblée que x=y, donc la surface maximale se produit lorsque le rectangle est un carré. En branchant cela dans la troisième équation, on voit que x=y=c/4, donc l’aire maximale d’un rectangle de périmètre c est c²/16.
Un problème de Putnam (modifié)
Le concours mathématique de Putnam est un concours sous forme d’examen proposé chaque année en décembre aux étudiants de premier cycle. Les étudiants disposent de six heures pour résoudre 12 problèmes extrêmement difficiles. L’examen est si difficile que, sur un score possible de 120, le score moyen de la plupart des années est de 0 ou 1. Aujourd’hui, nous allons étudier une version modifiée (par souci de simplicité et pour éviter les problèmes de droits d’auteur) du problème A3 de l’examen de 2018 :

Il y a deux problèmes. Le premier est que la fonction objectif a une caractéristique très indésirable : c’est une somme de cosinus, et les sommes de fonctions trigonométriques peuvent être difficiles à traiter. Le second est qu’il n’existe aucun moyen de faire apparaître la fonction de contrainte de manière nette et explicite dans la fonction objectif, même si, à première vue, cela semble possible. Les problèmes de Putnam comportent souvent des « pièges » comme celui-ci, où l’on peut être amené à perdre du temps sur une approche qui ne mènera pas à une solution si l’on ne s’arrête pas pour réfléchir à ce que l’on fait. C’est un piège qui serait particulièrement dangereux pour un concurrent ayant de l’expérience dans les concours de mathématiques du secondaire, où les identités trigonométriques ont tendance à être fortement mises en avant.
Mais lorsque nous voyons un problème qui dit « maximiser f sous réserve de g=0 », nous devrions immédiatement penser aux multiplicateurs de Lagrange. Mettons en place notre système d’équations :

.
Nous pouvons maintenant utiliser nos identités trigonométriques pour faire apparaître la contrainte de manière explicite. Réécrivez le système d’équations en utilisant la formule du double angle :
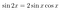
Le résultat est :

Annulez maintenant la fonction sinus de chaque côté, et ajoutez les équations :
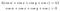
Et cela signifie que λ=0, donc selon les équations du multiplicateur de Lagrange cela signifie que :

Donc w, x, y, et z sont tous des multiplications entières de π/2. Pour les multiplications entières paires de π/2, disons m=2k pour un entier k quelconque :

Mais si m est un entier impair, alors cos(mπ/2)=0. Cela signifie que nous avons trois options pour la façon dont nous pouvons satisfaire l’équation de contrainte. Premièrement, nous pouvons définir w, x, y et z tous à des multiplications entières impaires de π/2, disons k, l, m et n, alors :

.
La première ligne montre que l’équation de contrainte est satisfaite, et la deuxième ligne est le résultat de l’insertion de ces valeurs dans la fonction objectif, ce qui nous donne -4.
La deuxième option est que nous pouvons fixer deux des variables à des multiples entiers impairs de π/2, disons k et l, et les deux autres à des entiers pairs, disons 2m et 2n où m est pair et n est impair. Le résultat de l’insertion de ceci dans l’équation de contrainte est :

Donc l’équation de contrainte est satisfaite. Voici le résultat en les branchant sur la fonction objectif :

.
La dernière option est que nous pouvons définir toutes les variables à des multiplications entières paires de π/2, disons 2k, 2l, 2m, et 2n, où k et l sont pairs et m et n sont impairs. Le résultat de l’insertion de ceci dans l’équation de contrainte est :

Donc la contrainte est satisfaite. Maintenant, on branche ces éléments dans la fonction objectif pour obtenir :

Donc la réponse est 4, qui, par coïncidence, s’avère être la valeur maximale globale de la fonction objectif.
Voyez cet autre article que j’ai écrit pour une discussion sur un autre problème de Putnam.
Théorème de Thomson
Maintenant, au lieu d’optimiser une fonction, utilisons la méthode des multiplicateurs de Lagrange pour optimiser une fonctionnelle : un objet qui prend une fonction et renvoie un nombre. Les intégrales définies en sont un exemple clé. Cette dernière démonstration montrera comment la méthode des multiplicateurs de Lagrange peut être utilisée pour trouver la fonction qui minimise la valeur d’une intégrale définie.
En guise de démonstration, nous considérons un fait fondamental de l’électrostatique, l’étude des systèmes soumis à des forces électriques en équilibre mécanique de sorte qu’aucune des charges ne soit en mouvement. Nous allons montrer que lorsqu’un conducteur, un corps dans lequel les charges électriques peuvent se déplacer librement, est en équilibre avec un système quelconque de forces électriques, alors il n’y a pas de champ électrique à l’intérieur du corps du conducteur. C’est le théorème de Thomson. Ce théorème est habituellement énoncé en termes du fait physique fondamental que l’énergie d’un système en équilibre mécanique stable est minimale:
Théorème de Thomson : L’énergie électrostatique d’un corps conducteur de taille et de forme fixes est minimisée lorsque les charges sont réparties de manière à rendre le potentiel ϕ constant dans le corps, de sorte que E=-∇ϕ=0.
Laissez ρ(r) être la fonction de répartition des charges et ϕₑₓₜ le potentiel dû à toute source extérieure au corps conducteur. L’énergie électrostatique totale peut être exprimée comme une fonctionnelle U de ρ(r) :

.
Il s’agit d’intégrales volumiques sur le corps du conducteur. La première intégrale est une double intégrale effectuée d’abord sur les coordonnées amorcées, puis sur les coordonnées non amorcées. Nous voulons minimiser U comme une fonction de ρ(r) étant donné que la charge totale est indépendante de la distribution de la charge :
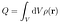
Hélas, la méthode des multiplicateurs de Lagrange fonctionne pour les fonctionnelles avec contraintes. Introduisez un multiplicateur de Lagrange indéterminé, puis plutôt qu’une optimisation sous contrainte sur U, effectuez une optimisation sans contrainte sur la fonctionnelle suivante :
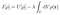
Par analogie avec les dérivées de fonctions, le but ici est de trouver la distribution de charge ρ telle que lorsque ρ varie d’une petite variation δρ, la variation de I, δI, est nulle :
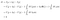
Ceci n’est pas tout à fait une dérivée car δρ est une fonction plutôt qu’un nombre, donc cela n’a pas vraiment de sens de parler de la limite lorsque δρ va vers zéro, mais l’intuition de base est la même.
Commençons par développer U :

Cela peut sembler mauvais, mais nous pouvons simplifier cela grandement. Tout d’abord, puisque δρ est très petit, (δρ)² est si petit que nous pouvons l’ignorer, donc supposons que δρ(r)δρ(r′)=0. Ensuite, en changeant l’ordre d’intégration, nous voyons que :

Nous pouvons également voir que U apparaît dans l’expansion. Cela nous donne de quoi simplifier U :

Nous pouvons maintenant développer δI :

.
Nous pouvons maintenant factoriser l’intégrale sur δρ(r) :

.
Pour que cela soit vrai pour tout choix de la variation δρ(r), le terme entre parenthèses doit être nul, donc :

Mais cette intégrale est juste le potentiel en r dû aux charges à l’intérieur du conducteur donc le côté gauche de cette équation donne le potentiel total en chaque point r à l’intérieur du conducteur, donc ρ(r) est la distribution qui rend le potentiel total à l’intérieur du conducteur constant. Ceci complète la preuve.
Ceci serait également valable si l’énergie électrostatique du conducteur est maximisée, auquel cas le conducteur est en équilibre instable. Dans la pratique, on ne rencontre jamais réellement de conducteurs en équilibre instable car le mouvement thermique aléatoire des électrons dans le conducteur va rapidement, de l’ordre de 10-¹⁴ secondes pour les conducteurs métalliques, faire sortir le système de l’équilibre instable et le faire entrer dans l’équilibre stable.
.