L’ottimizzazione, uno dei problemi elementari della fisica matematica, dell’economia, dell’ingegneria e di molte altre aree della matematica applicata, è il problema di trovare il valore massimo o minimo di una funzione, chiamata funzione obiettivo, così come i valori delle variabili di input in cui si verifica quel valore ottimale. Nel calcolo elementare a una sola variabile, questo è un problema molto semplice che consiste nel trovare i valori di x per i quali df/dx è zero.
I problemi di ottimizzazione a più variabili sono più complicati perché possiamo imporre dei vincoli. Consideriamo i vincoli che possono essere espressi nella forma g(x,y,z)=c per qualche funzione g e costante c. Questi sono chiamati vincoli di uguaglianza, e l’insieme dei punti che soddisfano questi vincoli è chiamato insieme fattibile, che denotiamo con S. Per esempio, se ci viene chiesto di trovare il valore massimo di f(x,y) sul cerchio unitario, allora g(x,y)=x²+y² poiché il cerchio unitario è definito da x²+y²=1.
La tecnica standard per risolvere questo tipo di problemi è il metodo dei moltiplicatori di Lagrange. In questo articolo, deriverò il metodo e darò alcune dimostrazioni del suo uso.
Motivazione e derivazione
Una funzione f ha un estremo locale (massimo o minimo) in un punto P quando la derivata parziale di f è zero per ciascuna delle variabili indipendenti e quando il punto non è un punto di sella (una situazione di cui non avremo bisogno di occuparci qui). Possiamo scrivere questo in forma compatta come ∇f=0, dove ∇ denota l’operatore del gradiente:
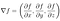
In ottimizzazione vincolata, tuttavia, solo perché f ha un massimo o un minimo locale in un punto dell’insieme fattibile, non ne consegue che f prenda il suo valore ottimale sull’insieme fattibile in quel punto.
Come esempio, consideriamo il seguente problema di ottimizzazione:
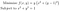
Scrivendo il gradiente, possiamo vedere che f ha un minimo locale quando x=0 e y=1:

Inoltre, f(0,1)=0, ma f(0,-1)=-4 quindi anche se (0,1) è un minimo locale di f(x,y), non è il minimo di f(x,y) sul cerchio unitario.
Come altro esempio, massimizziamo f(x,y)=y sul cerchio unitario. Il gradiente di f(x,y)=y è un vettore costante quindi f(x,y) non ha massimi o minimi locali, ma sul cerchio unitario f ha un valore massimo di 1, che si verifica a (0,1).
La ragione di questo fallimento è che il gradiente misura il tasso di cambiamento di f(x,y,z) rispetto alla posizione nello spazio tridimensionale, ma noi vogliamo misurare il tasso di cambiamento di f(x,y,z) rispetto alla posizione nel set fattibile. Per un problema tridimensionale, S sarà o una curva o una superficie, e in generale per problemi con n variabili, S sarà un’ipersuperficie di dimensione strettamente inferiore a n.
L’approccio più naturale è considerare le curve in S. Sia P un punto in S per il quale f(P) assume un valore localmente ottimale in S ma ∇f(P) non è necessariamente zero, e sia r(t) la parametrizzazione di qualsiasi curva in S che passa per P, cioè:

Se S è una curva, allora r(t) è solo una parametrizzazione di S. Inoltre, sia r(T)=P, r′(T)≠0, e sia h(t) = f(r(t)) in modo che h′(T)=0. Espandiamo h′(t) usando la regola della catena:

Poiché r(t) è sempre in S, il vettore velocità r′(t) deve essere sempre tangente alla superficie o curva di S poiché se r′(t) avesse una componente perpendicolare alla superficie, cioè diretta fuori dalla superficie, allora ci sarebbero punti in cui r(t) lascia S. Poiché questo è vero per qualsiasi curva r(t) che passa per P, ne segue che ∇f(P) è perpendicolare a qualsiasi vettore tangente alla superficie in P. Quindi se P è un punto in cui f assume un valore massimo o minimo rispetto alla posizione in S, allora ∇f(P) è perpendicolare a S.
È vero anche il contrario: poiché r′(T) non è mai zero e sempre parallelo a S, allora se ∇f(P) è perpendicolare a S, allora h′(T)=∇f(P)∙r′(T)=0.
Ma come possiamo trovare effettivamente i punti in cui ∇f è perpendicolare a S? Ecco la risposta: L’insieme S è l’insieme di tutti i punti in cui g(x,y,z)=c, cioè S è un insieme di livello di g. Questo significa che ∇g è perpendicolare a S per tutti i punti di S, quindi ∇f e ∇g sono paralleli nei punti di S dove f assume valori ottimali. Questo significa che f assume i suoi valori ottimali in S proprio quando ∇f=λ∇g per qualche costante λ. La costante λ è chiamata moltiplicatore indeterminato di Lagrange, ed è da qui che il metodo prende il suo nome. Il problema di ottimizzare f può ora essere risolto trovando quattro incognite x, y, z e λ che risolvono queste quattro equazioni:
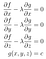
In un altro modo, il nostro obiettivo ora è quello di ottimizzare la funzione f-λg rispetto a x, y e z senza vincoli trovando dove ∇(f-λg)=0.
E se ci fosse più di un vincolo? Supponiamo ora di dover ottimizzare f(x,y,x) soggetto a g(x,y,z)=c e h(x,y,z)=d. Ecco cosa facciamo. Per ottimizzare f soggetto a g(x,y,z)=c, ottimizziamo f-λg senza vincolo, quindi il primo vincolo è curato sostituendo f con f-λg, e rimane da ottimizzare f-λg soggetto al vincolo h(x,y,z)=d. Questo è un problema con un solo vincolo, quindi aggiungiamo semplicemente un altro moltiplicatore di Lagrange μ, e il problema ora è quello di ottimizzare f-λg-μh senza vincolo.
Guardiamo ora alcuni esempi.
L’area massima di un rettangolo
Per un dato perimetro, qual è la massima area possibile di un rettangolo con quel perimetro? Possiamo formulare questo come un problema del moltiplicatore di Lagrange. Se la larghezza e l’altezza sono x e y, allora vogliamo massimizzare f(x,y)=xy per g(x,y)=2x+2y=c. Il sistema di equazioni risultante è:
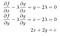
Le prime due equazioni ci dicono subito che x=y, quindi l’area massima si verifica quando il rettangolo è un quadrato. Inserendo questo nella terza equazione, vediamo che x=y=c/4, quindi l’area massima di un rettangolo con perimetro c è c²/16.
Un problema Putnam (modificato)
La competizione matematica Putnam è una competizione in formato esame offerta ogni dicembre agli studenti universitari. Gli studenti hanno sei ore per risolvere 12 problemi estremamente impegnativi. L’esame è così difficile che, su un punteggio possibile di 120, il punteggio medio nella maggior parte degli anni è 0 o 1. Oggi guarderemo una versione modificata (per semplicità e per evitare problemi di copyright) del problema A3 dell’esame del 2018:

I problemi sono due. Il primo è che la funzione obiettivo ha una caratteristica molto indesiderabile: è una somma di coseni, e le somme di funzioni trigonometriche possono essere difficili da trattare. Il secondo è che non c’è modo di far apparire la funzione di vincolo in modo pulito ed esplicito nella funzione obiettivo, anche se a prima vista potrebbe sembrare che ciò sia possibile. I problemi di Putnam spesso comportano “trappole” come questa, dove si può essere attirati a perdere tempo in un approccio che non porterà ad una soluzione se non ci si ferma a pensare a quello che si sta facendo. È una trappola che sarebbe particolarmente pericolosa per un concorrente con esperienza in competizioni matematiche al liceo, dove le identità trigonometriche tendono ad essere una forte enfasi.
Ma quando vediamo un problema che dice “massimizzare f soggetto a g=0”, dovremmo immediatamente pensare ai moltiplicatori di Lagrange. Impostiamo il nostro sistema di equazioni:

Ora possiamo usare le nostre identità trigonometriche per far apparire esplicitamente il vincolo. Riscriviamo il sistema di equazioni usando la formula del doppio angolo:
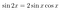
Il risultato è:

Ora annulla la funzione seno su ogni lato, e aggiungete le equazioni:
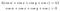
E questo significa che λ=0, quindi secondo le equazioni del moltiplicatore di Lagrange questo significa che:

Quindi w, x, y e z sono tutti multipli interi di π/2. Per i multipli interi pari di π/2, diciamo m=2k per qualche k intero:

Ma se m è un intero dispari, allora cos(mπ/2)=0. Questo significa che abbiamo tre opzioni per come possiamo soddisfare l’equazione di vincolo. In primo luogo, possiamo impostare w, x, y e z come multipli interi dispari di π/2, diciamo k, l, m e n, quindi:

La prima linea mostra che l’equazione del vincolo è soddisfatta, e la seconda linea è il risultato dell’inserimento di questi valori nella funzione obiettivo, che ci dà -4.
La seconda opzione è che possiamo impostare due delle variabili a multipli interi dispari di π/2, diciamo k e l, e le altre due a interi pari, diciamo 2m e 2n dove m è pari e n è dispari. Il risultato dell’inserimento di questo nell’equazione di vincolo è:

Quindi l’equazione del vincolo è soddisfatta. Ecco il risultato dell’inserimento di questi nella funzione obiettivo:

L’opzione finale è che possiamo impostare tutte le variabili su multipli interi pari di π/2, diciamo 2k, 2l, 2m e 2n, dove k e l sono pari e m e n sono dispari. Il risultato dell’inserimento di questo nell’equazione di vincolo è:

Quindi il vincolo è soddisfatto. Ora li inseriamo nella funzione obiettivo per ottenere:

La risposta è quindi 4, che casualmente risulta essere il valore massimo globale della funzione obiettivo.
Guarda quest’altro articolo che ho scritto per una discussione su un altro problema di Putnam.
Teorema di Thomson
Ora invece di ottimizzare una funzione, usiamo il metodo dei moltiplicatori di Lagrange per ottimizzare un funzionale: un oggetto che prende una funzione e restituisce un numero. Gli integrali definiti sono un esempio chiave. Questa dimostrazione finale mostrerà come il metodo dei moltiplicatori di Lagrange può essere usato per trovare la funzione che minimizza il valore di un integrale definito.
Come dimostrazione, consideriamo un fatto fondamentale dell’elettrostatica, lo studio dei sistemi soggetti a forze elettriche in equilibrio meccanico in modo che nessuna delle cariche sia in movimento. Mostreremo che quando un conduttore, un corpo in cui la carica elettrica può muoversi liberamente, è in equilibrio con qualsiasi sistema di forze elettriche, allora non c’è nessun campo elettrico all’interno del corpo del conduttore. Questo è il teorema di Thomson. Questo teorema viene solitamente enunciato in termini del fatto fisico fondamentale che l’energia di un sistema in equilibrio meccanico stabile è minima:
Teorema di Thomson: L’energia elettrostatica di un corpo conduttore di forma e dimensioni fisse è minimizzata quando le cariche sono distribuite in modo tale da rendere il potenziale ϕ costante nel corpo in modo che E=-∇ϕ=0.
Lasciamo che ρ(r) sia la funzione di distribuzione della carica e ϕₑₓₜ il potenziale dovuto a qualsiasi sorgente esterna al corpo conduttore. L’energia elettrostatica totale può essere espressa come un funzionale U di ρ(r):

Sono integrali di volume sul corpo del conduttore. Il primo integrale è un doppio integrale effettuato prima sulle coordinate innescate e poi sulle coordinate non innescate. Vogliamo minimizzare U come funzionale di ρ(r) dato che la carica totale è indipendente dalla distribuzione della carica:
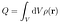
Fortunatamente, il metodo dei moltiplicatori di Lagrange funziona per le funzioni con vincoli. Introducete un moltiplicatore indeterminato di Lagrange, e poi piuttosto che l’ottimizzazione vincolata su U, eseguite l’ottimizzazione non vincolata sul seguente funzionale:
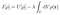
Per analogia con le derivate di funzioni, l’obiettivo qui è trovare la distribuzione di carica ρ tale che quando ρ è variato di una piccola variazione δρ, la variazione di I, δI, è zero:
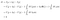
Questa non è proprio una derivata perché δρ è una funzione piuttosto che un numero quindi non ha davvero senso parlare del limite come δρ va a zero, ma l’intuizione di base è la stessa.
Iniziamo ad espandere U:

Questo può sembrare brutto, ma possiamo semplificare molto la cosa. Innanzitutto, poiché δρ è molto piccolo, (δρ)² è così piccolo che possiamo ignorarlo, quindi assumiamo che δρ(r)δρ(r′)=0. Poi, cambiando l’ordine di integrazione vediamo che:

Si può anche vedere che U appare nell’espansione. Questo ci dà abbastanza per semplificare U:

Ora possiamo espandere δI:

Ora possiamo fattorizzare l’integrale su δρ(r):

Perché questo sia vero per qualsiasi scelta della variazione δρ(r), il termine tra parentesi deve essere zero, quindi:

Ma questo integrale è solo il potenziale a r dovuto alle cariche all’interno del conduttore quindi il lato sinistro di questa equazione dà il potenziale totale in ogni punto r all’interno del conduttore, quindi ρ(r) è la distribuzione che rende costante il potenziale totale all’interno del conduttore. Questo completa la dimostrazione.
Questo sarebbe anche valido se l’energia elettrostatica del conduttore è massimizzata, nel qual caso il conduttore è in equilibrio instabile. In pratica non si incontrano mai conduttori in equilibrio instabile perché il moto termico casuale degli elettroni nel conduttore porterà rapidamente, nell’ordine di 10-¹⁴ secondi per i conduttori metallici, il sistema fuori dall’equilibrio instabile e nell’equilibrio stabile.