Für den Fall, dass wir Inline-tabellenwertige Funktionen vergessen haben oder ihnen noch nie begegnet sind, beginnen wir mit einer kurzen Erklärung, was sie sind.
Nach der Definition einer benutzerdefinierten Funktion (UDF) von Books Online ist eine inline table-valued function (iTVF) ein Tabellenausdruck, der Parameter annehmen, eine Aktion ausführen und als Rückgabewert eine Tabelle liefern kann. Die Definition einer iTVF wird dauerhaft als Datenbankobjekt gespeichert, ähnlich wie es bei einem View der Fall wäre.
Die Syntax zum Erstellen einer iTVF von Books Online (BOL) ist hier zu finden und lautet wie folgt:
CREATE FUNCTION function_name ( parameter_data_type } ] ) RETURNS TABLE ] RETURN select_stmt
Der folgende Codeschnipsel ist ein Beispiel für eine iTVF.
CREATE OR ALTER FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN (SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Comments cWHERE c.UserId = @UserId AND c.CreationDate >= @CommentDateGROUP BY c.UserId);
Ein paar erwähnenswerte Dinge im obigen Skript.
DEFAULT VALUE () – Sie können Standardwerte für Parameter festlegen und in unserem Beispiel hat @CommentDate den Standardwert 01 Jan 2006.
RETURNS TABLE – Gibt eine virtuelle Tabelle basierend auf der Definition der Funktion zurück
SCHEMABINDING – Gibt an, dass die Funktion an die Datenbankobjekte gebunden ist, die sie referenziert. Wenn Schemabindung angegeben ist, können die Basisobjekte nicht in einer Weise geändert werden, die die Funktionsdefinition beeinflussen würde. Die Funktionsdefinition selbst muss zuerst geändert oder gelöscht werden, um die Abhängigkeiten von dem Objekt zu entfernen, das geändert werden soll (von BOL).
Betrachten Sie die SELECT-Anweisung im iTVF-Beispiel, so ähnelt sie einer Abfrage, die Sie in einem View platzieren würden, mit Ausnahme des Parameters, der in der WHERE-Klausel übergeben wird. Das ist ein entscheidender Unterschied.
Obwohl eine iTVF einem View insofern ähnelt, als die Definition permanent in der Datenbank gespeichert wird, haben wir durch die Möglichkeit, Parameter zu übergeben, nicht nur eine Möglichkeit, Logik zu kapseln und wiederzuverwenden, sondern auch die Flexibilität, nach bestimmten Werten zu suchen, die wir übergeben möchten. In diesem Fall können wir uns eine inline table-valued function als eine Art „parametrisierte Ansicht“ vorstellen.
Warum eine iTVF verwenden?
Bevor wir uns ansehen, wie wir iTVFs verwenden, ist es wichtig zu überlegen, warum wir sie verwenden. ITVFs ermöglichen es uns, Lösungen zur Unterstützung von Aspekten wie (aber nicht nur):
- Modulare Entwicklung
- Flexibilität
- Vermeidung von Leistungseinbußen
Ich werde jeden dieser Aspekte im Folgenden etwas näher erläutern.
Modulare Entwicklung
iTFVs können gute Entwicklungspraktiken wie die modulare Entwicklung fördern. Im Wesentlichen wollen wir sicherstellen, dass unser Code „DRY“ ist und nicht jedes Mal, wenn er an einer anderen Stelle benötigt wird, bereits produzierten Code wiederholen.
Ungeachtet der Fälle, in denen die modulare Entwicklung auf Kosten von wartbarem Code bis zum x-ten Grad ausgereizt wird, sind die Vorteile der Wiederverwendung von Code und der Kapselung mit iTVFs eines der ersten Dinge, die wir bemerken.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Users u INNER JOIN dbo.Comments c ON u.Id = c.UserIdWHERE c.CreationDate >= @CommentDateGROUP BY u.Id, u.Reputation;GO
VS
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u CROSS APPLY .(u.Id, @CommentDate) c;GO
Die Abfrage mit der iTVF ist einfach und kann, wenn sie in komplizierteren Abfragen verwendet wird, die Entwicklungsarbeit wirklich unterstützen, indem sie die zugrunde liegende Komplexität verbirgt. In Szenarien, in denen wir die Logik in der Funktion zu Verbesserungs- oder Debugging-Zwecken anpassen müssen, können wir die Änderung an einem Objekt vornehmen, sie testen und diese eine Änderung wird an den anderen Stellen, an denen die Funktion aufgerufen wird, reflektiert.
Wenn wir die Logik an mehreren Stellen wiederholen würden, müssten wir dieselbe Änderung mehrmals vornehmen, mit dem Risiko, dass jedes Mal Fehler, Abweichungen oder andere Missgeschicke auftreten. Das bedeutet, dass wir verstehen müssen, wo wir Logik in iTVFs wiederverwenden, damit wir testen können, dass wir nicht diese lästigen Eigenschaften, die als Bugs bekannt sind, eingeführt haben.
Flexibilität
Wenn es um Flexibilität geht, ist die Idee, die Fähigkeit von Funktionen zu nutzen, Parameterwerte zu übergeben und einfach zu interagieren. Wie wir später anhand von Beispielen sehen werden, können wir mit der iTFV interagieren, als ob wir eine Tabelle abfragen würden.
Wäre die Logik beispielsweise in einer gespeicherten Prozedur, müssten wir die Ergebnisse wahrscheinlich in eine temporäre Tabelle übernehmen und dann die temporäre Tabelle abfragen, um mit den Daten zu interagieren.
Wäre die Logik in einem View, könnten wir keinen Parameter übergeben. Unsere Optionen wären, den View abzufragen und dann eine WHERE-Klausel außerhalb der Definition des Views hinzuzufügen. Für diese Demo ist das keine große Sache, aber bei komplizierten Abfragen kann die Vereinfachung mit einer iTVF eine elegantere Lösung sein.
Leistungseinbußen vermeiden
Im Rahmen dieses Artikels werde ich mich nicht mit UDFs der Common Language Runtime (CLR) befassen.
Wo wir anfangen, eine Divergenz zwischen iTVFs und anderen UDFs zu sehen, ist die Leistung. Man kann viel über die Leistung sagen, und zumeist leiden andere UDFs sehr unter der Leistung. Eine Alternative könnte sein, sie stattdessen als iTVFs umzuschreiben, da die Leistung bei iTFVs ein wenig anders ist. Sie leiden nicht unter den gleichen Leistungseinbußen wie skalare oder Multi Statement Table-Valued Functions (MSTVFs).
iTVFs werden, wie der Name schon sagt, in den Ausführungsplan eingefügt. Wenn der Optimierer die Abfrageelemente der Definition entschachtelt und mit den darunter liegenden Tabellen interagiert (Inlining), haben Sie eine bessere Chance, einen optimalen Plan zu erhalten, da der Optimierer die Statistiken der darunter liegenden Tabellen berücksichtigen kann und ihm andere Optimierungen wie Parallelität zur Verfügung stehen, wenn dies erforderlich ist.
Für viele Leute war allein die Leistung ein wichtiger Grund, iTVFs anstelle von skalaren oder MSTVFs zu verwenden. Auch wenn Ihnen die Leistung im Moment noch egal ist, können sich die Dinge bei größeren Mengen oder komplizierten Anwendungen Ihrer Logik sehr schnell ändern, sodass es wichtig ist, die Fallstricke der anderen UDF-Typen zu verstehen. Später in diesem Artikel zeigen wir einen grundlegenden Performance-Vergleich zwischen iTVFs und anderen UDF-Typen.
Nachdem wir nun einige Gründe für die Verwendung von iTVFs aufgelistet haben, lassen Sie uns nun sehen, wie wir sie einsetzen können.
Einrichten der iTVF-Demo
In dieser Demo verwenden wir die Datenbank StackOverflow2010, die bei den netten Leuten von StackOverflow über https://archive.org/details/stackexchange
Alternativ können Sie die Datenbank auch über die anderen netten Leute von Brent Ozar Unlimited hier bekommen: https://www.brentozar.com/archive/2015/10/how-to-download-the-stack-overflow-database-via-bittorrent/
Ich habe die StackOverflow-Datenbank auf meinem lokalen SQL Server 2016 Developer Edition wiederhergestellt, in einer isolierten Umgebung. Ich führe eine kurze Demo auf meiner installierten Version von SQL Server Management Studio (SSMS) v18.0 Preview 5 aus. Außerdem habe ich den Kompatibilitätsmodus auf 2016 (130) eingestellt und führe die Demo auf einem Rechner mit einer Intel i7 2,11 GHz CPU und 16 GB RAM aus.
Nach dem Start der StackOverflow-Datenbank führen Sie die T-SQL in der Ressourcendatei 00_iTFV_Setup.sql aus, die in diesem Artikel enthalten ist, um die iTVFs zu erstellen, die wir verwenden werden. Die Logik in diesen iTVFs ist einfach und kann an mehreren Stellen wiederholt werden, aber hier schreiben wir sie einmal und bieten sie zur Wiederverwendung an.
Verwenden einer iTVF als virtuelle Tabelle
Erinnern Sie sich, dass iTVFs nirgendwo in der Datenbank persistiert werden. Was persistiert wird, ist ihre Definition. Wir können trotzdem mit iTVFs interagieren, als ob sie Tabellen wären, also behandeln wir sie in dieser Hinsicht als virtuelle Tabellen.
Die folgenden 6 Beispiele zeigen, wie wir iTVFs als virtuelle Tabellen behandeln können. Wenn Sie die StackOverflow-Datenbank auf Ihrem Rechner eingerichtet haben, können Sie die folgenden 6 Abfragen aus Abschnitt 1 ausführen, um dies selbst zu sehen. Sie finden diese auch in der Datei 01_Demo_SSC_iTVF_Creating_Using.sql.
/**************************************************************************1. Using iTVFs in queries as if it were a table.**************************************************************************/DECLARE @UserId INT= 3, @CommentDate DATE= '2006-01-01T00:00:00.000';--1.1 Get specific columnsSELECT UserId, LatestCommentDateFROM dbo.itvfnGetRecentComment(3, '2006-01-01T00:00:00.000');--1.2 Get all columns SELECT *FROM dbo.itvfnGetRecentComment(@UserId, @CommentDate);--1.3 Use a default valueSELECT UserId, LatestCommentDate, TotalCommentsFROM dbo.itvfnGetRecentComment(@UserId, DEFAULT);--1.4 In the WHERE clauseSELECT u.DisplayName, u.Location, u.ReputationFROM dbo.Users uWHERE u.Reputation <=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(@UserId, DEFAULT));--1.5 In the HAVING clauseSELECT u.Location, SUM(u.Reputation) AS TotalRepFROM dbo.Users uGROUP BY u.LocationHAVING SUM(u.Reputation) >=( SELECT rc.TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT) rc);--1.6 In the SELECT clauseSELECT u.Location, CASE WHEN SUM(u.Reputation) >=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT)) THEN 'YES' ELSE 'NO' END AS InRepLimitFROM dbo.Users uGROUP BY u.Location;
Wie oben gezeigt, können wir bei der Interaktion mit iTVFs:
- Die vollständige Spaltenliste zurückgeben
- Angegebene Spalten zurückgeben
- Standardwerte verwenden, indem wir das Schlüsselwort, DEFAULT
- Verwenden Sie die iTVF in der WHERE-Klausel
- Verwenden Sie die iTVF in der HAVING-Klausel
- Verwenden Sie die iTVF in der SELECT-Klausel
Um dies zu verdeutlichen, typischerweise würde man mit einer gespeicherten Prozedur die Ergebnismenge in eine temporäre Tabelle einfügen und dann mit der temporären Tabelle interagieren, um das oben genannte zu tun. Bei einer iTVF ist es nicht erforderlich, mit anderen Objekten außerhalb der Funktionsdefinition zu interagieren, wie in den 6 Fällen, die wir gerade gesehen haben.
iTVFs in verschachtelten Funktionen
Obwohl die Verschachtelung von Funktionen ihre eigenen Probleme mit sich bringen kann, wenn sie schlecht ausgeführt wird, ist sie etwas, das wir innerhalb einer iTVF tun können. Umgekehrt kann sie, wenn sie richtig eingesetzt wird, sehr nützlich sein, um Komplexität zu verbergen.
In unserem konstruierten Beispiel gibt die Funktion dbo.itvfnGetRecentCommentByRep den letzten Kommentar eines Benutzers, die Gesamtzahl der Kommentare usw. zurück, und fügt einen zusätzlichen Filter für die Reputation hinzu.
SELECT DisplayName, LatestCommentDate, ReputationFROM .(3, DEFAULT, DEFAULT);GO
Wenn wir das Datum des letzten Kommentars zurückgeben, geschieht dies über den Aufruf der anderen Funktion, dbo.itvfnGetRecentComment.
CREATE OR ALTER FUNCTION . (@UserId int, @Reputation int = 100, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN ( SELECT u.DisplayName, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) cWHERE u.Id = @UserId AND u.Reputation >= @Reputation);GO
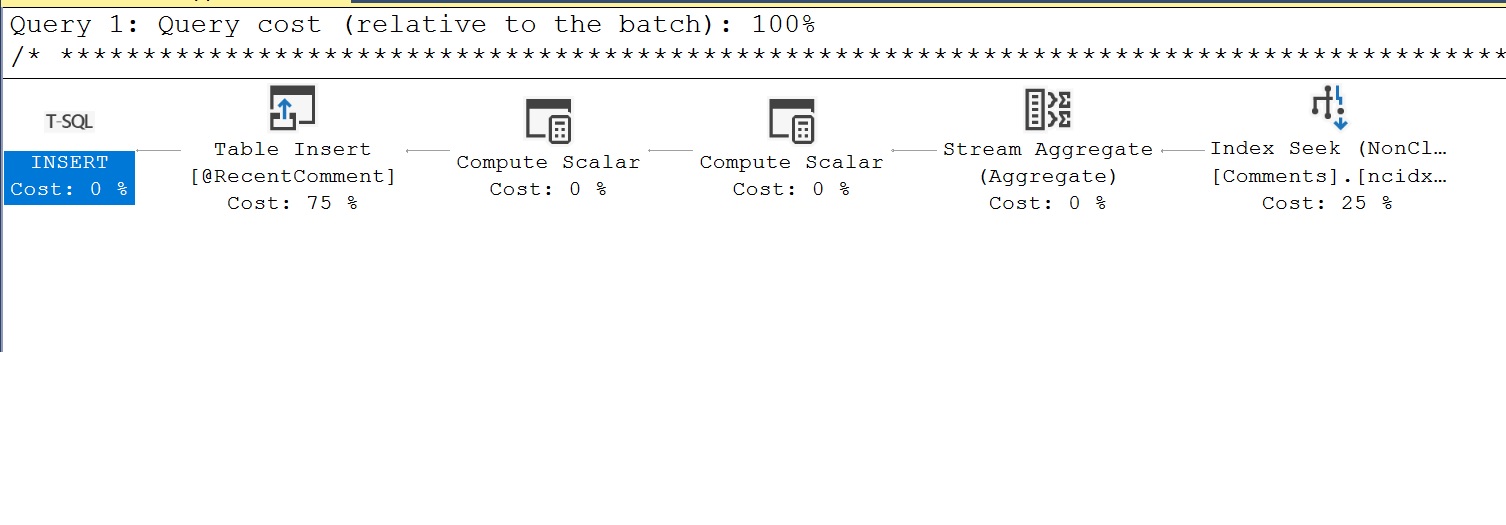
Im Beispiel sehen wir, dass selbst bei Verschachtelung von Funktionen die zugrunde liegende Definition inlined wird und die Objekte, mit denen wir interagieren, die geclusterten Indizes dbo.Users und dbo.Comments sind.
Im Plan wird ohne einen anständigen Index zur Unterstützung unserer Prädikate ein geclusterter Index-Scan der Tabelle „Comments“ durchgeführt sowie parallel, wobei die Anzahl der Ausführungen bei 8 liegt. Wir filtern nach UserId 3 aus der Tabelle „Users“, sodass wir eine Suche in der Tabelle „Users“ erhalten, und verbinden dann die Tabelle „Comments“ nach dem GROUP BY (Stream-Aggregat) mit dem neuesten Kommentar-Datum.
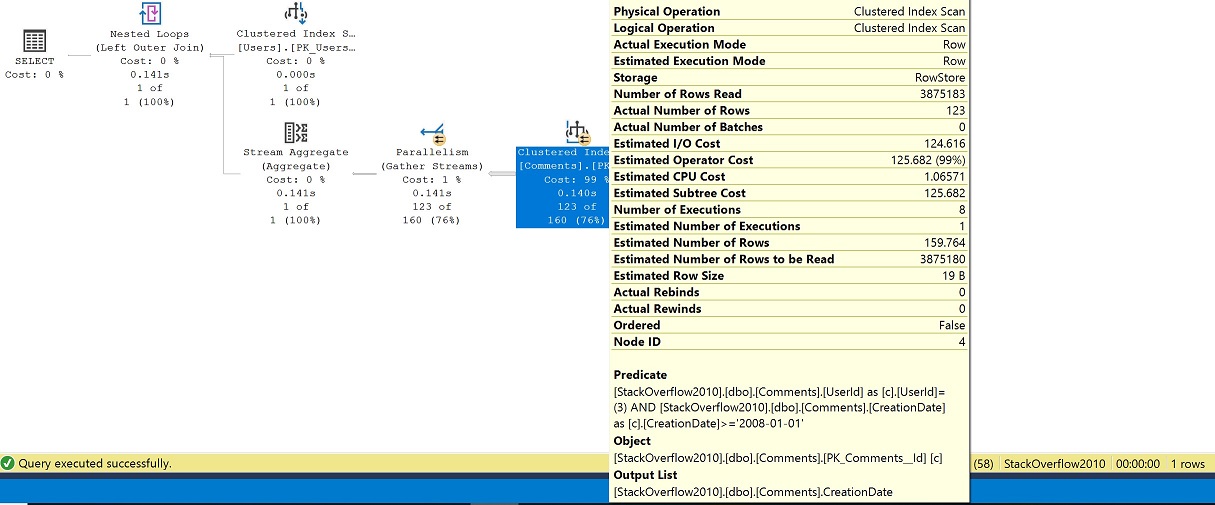
Verwendung des APPLY-Operators
Der APPLY-Operator bietet so viele kreative Verwendungsmöglichkeiten, und er ist sicherlich eine Option, die wir bei der Interaktion mit einer iTVF anwenden können (Wortspiel beabsichtigt). Mehr zum APPLY-Operator finden Sie in den folgenden Dokumenten: https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms175156(v=sql.105) und http://www.sqlservercentral.com/articles/Stairway+Series/121318/
Im folgenden Beispiel wollen wir die iTVF für alle Benutzer aufrufen und deren LatestCommentDate, Total Comments, Id und Reputation seit 01.01.2008 zurückgeben. Dazu verwenden wir den Operator APPLY, wobei wir für jede Zeile der gesamten Tabelle Users ausführen und dabei die Id aus der Tabelle Users und das CommentDate übergeben. Dabei behalten wir die Kapselungsvorteile der Verwendung von iTVF bei und wenden unsere Logik auf alle Zeilen in der Tabelle Users an.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
iTVFs in JOINs
Ähnlich wie beim Joinen von 2 oder mehr Tabellen können wir iTVFs in Joins mit anderen Tabellen einbeziehen. Hier wollen wir den DisplayName aus der Tabelle Users und die UserId, BadgeName und BadgeDate aus der iTVF, für Benutzer, die den Badge ‚Student‘ am oder nach dem 01.01.2008 erhalten haben.
DECLARE @BadgeName varchar(40)= 'Student', @BadgeDate datetime= '2008-01-01T00:00:00.000';SELECT u.DisplayName, b.UserId, b.BadgeName, b.BadgeDateFROM dbo.Users u INNER JOIN .(@BadgeName, @BadgeDate) b ON b.UserId = u.Id;GO
Alternative zu anderen UDFs
Zuvor haben wir in diesem Artikel erwähnt, dass ein Grund für die Verwendung von iTVFs darin besteht, Leistungseinbußen zu vermeiden, die andere Arten von UDFs wie skalare und MSTVFs erleiden. In diesem Abschnitt wird gezeigt, wie wir skalare und MSTVFs durch iTVFs ersetzen können, und im folgenden Teil wird untersucht, warum wir uns dafür entscheiden.
Skalare UDF-Alternative
Bevor wir weitermachen, lassen wir die folgende Abfrage laufen, um die skalare UDF, dbo.sfnGetRecentComment, zu erstellen, die wir gleich verwenden werden.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS datetimeWITH SCHEMABINDING, RETURNS NULL ON NULL INPUTASBEGIN DECLARE @LatestCreationDate datetime; SELECT @LatestCreationDate = MAX(CreationDate) FROM dbo.Comments WHERE UserId = @UserId AND CreationDate >= @CommentDate GROUP BY UserId; RETURN @LatestCreationDate;END;GO
Nach dem Erstellen der skalaren Funktion führen wir die folgende Abfrage aus. Hier wollen wir die in der skalaren Funktion gekapselte Logik verwenden, um die gesamte Tabelle Users abzufragen und die Id und das Datum des letzten Kommentars eines jeden Benutzers seit dem 01.01.2008 zurückzugeben. Dazu fügen wir die Funktion in die SELECT-Klausel ein, wobei wir als Parameterwerte die Id aus der Tabelle Users und das Kommentar-Datum, das wir gerade auf den 01.01.2008 gesetzt haben, übergeben.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Eine ähnliche Abfrage kann mit einer iTVF geschrieben werden, die in der folgenden Abfrage gezeigt wird. Hier wollen wir die Id und das Datum des letzten Kommentars seit dem 01.01.2008 mit Hilfe der iTVF ermitteln und erreichen dies, indem wir den APPLY-Operator gegen alle Zeilen der Tabelle Users verwenden. Für jede Zeile übergeben wir die Benutzer-ID und das Kommentar-Datum.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
MSTVF-Alternative
Führen Sie die folgende Abfrage aus, um die MSTVF dbo.mstvfnGetRecentComment zu erstellen, die wir gleich verwenden werden.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS @RecentComment TABLE( int NULL, date NULL, int NULL)WITH SCHEMABINDING ASBEGIN INSERT INTO @RecentComment SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalComments FROM dbo.Comments c WHERE c.UserId = @UserId AND c.CreationDate >= @CommentDate GROUP BY c.UserId; RETURN;END;GO
Nachdem wir die MSTVF erstellt haben, verwenden wir sie, um das Datum des letzten Kommentars für alle Zeilen in der Tabelle „Benutzer“ seit dem 01. Januar 2008 zurückzugeben. Wie beim iTVF-Beispiel mit dem APPLY-Operator im früheren Teil dieses Artikels werden wir unsere Funktion auf alle Zeilen in der Tabelle Users „anwenden“ und die Benutzer-ID für jede Zeile sowie das von uns festgelegte Kommentar-Datum übergeben.
DECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Wenn wir die MSTVF in unserem Beispiel durch eine iTVF ersetzen, ist das Ergebnis sehr ähnlich, abgesehen vom Namen der Funktion, die aufgerufen wird. In unserem Fall rufen wir itvfnGetRecentComment anstelle der MSTVF im vorherigen Beispiel auf, wobei wir die Spalten in der SELECT-Klausel beibehalten. Auf diese Weise können wir die Id und das Datum des letzten Kommentars seit dem 01.01.2008 mithilfe der iTVF für alle Zeilen der Tabelle „Users“ abrufen. Dies wird in der folgenden Abfrage gezeigt.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Eine Vorliebe für iTVFs
Ein Grund, eine iTVF gegenüber einer skalaren Funktion oder MSTVF zu wählen, ist die Leistung.
Wir werden die Performance der 3 Funktionen anhand der Beispielabfragen, die wir im vorherigen Abschnitt ausgeführt haben, kurz erfassen und nicht weiter ins Detail gehen, außer dass wir die Performance über Metriken wie Ausführungszeit und Ausführungsanzahl der Funktionen vergleichen. Der Code für die Leistungsstatistiken, den wir in dieser Demo verwenden werden, stammt aus Listing 9.3 in den Codebeispielen der dritten Auflage von SQL Server Execution Plans von Grant Fritchey https://www.red-gate.com/simple-talk/books/sql-server-execution-plans-third-edition-by-grant-fritchey/
Skalare Leistung
Hier ist die vorherige Abfrage, die wir ausgeführt haben und die die skalare Funktion aufgerufen hat.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Es ist bekannt, dass skalare Funktionen die Parallelität hemmen und dass eine Anweisung mit einer skalaren Funktion für jede Zeile einmal aufgerufen wird. Wenn Ihre Tabelle 10 Zeilen hat, ist das vielleicht in Ordnung. Bei ein paar tausend Zeilen werden Sie vielleicht von dem drastischen Leistungsabfall überrascht sein (oder auch nicht). Lassen Sie uns dies in Aktion sehen, indem wir den folgenden Codeschnipsel ausführen.
Was wir zuerst tun wollen, ist (in einer isolierten Umgebung) den SQL Server-Cache und den vorhandenen Plan, der wiederverwendet werden könnte, zu löschen (FREEPROCCACHE) und sicherzustellen, dass wir zuerst Daten von der Festplatte holen (DROPPCLEANBUFFERS), um mit einem kalten Cache zu beginnen. Locker ausgedrückt, fangen wir damit bei Null an.
Danach führen wir die SELECT-Abfrage auf die Tabelle Users aus, bei der wir die Id und das LatestCommentDate mit der Skalarfunktion zurückgeben. Als Parameterwerte übergeben wir die Id aus der Tabelle Users und das Kommentar-Datum, das wir gerade auf den 01.01.2008 gesetzt haben. Ein Beispiel sieht wie folgt aus.
-- run in an isolated environmentCHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Obwohl die SELECT-Abfrage, bei der wir die Skalarfunktion verwenden, von der Struktur her einfach erscheinen mag, wurde sie auf meinem Rechner nach 4 Minuten immer noch ausgeführt.
Erinnern Sie sich daran, dass Skalarfunktionen für jede Zeile einmal ausgeführt werden. Das Problem dabei ist, dass zeilenweise Operationen sehr selten die effizienteste Art sind, Daten in SQL Server abzurufen, verglichen mit Operationen, die auf einzelnen Mengen basieren.
Um wiederholte Ausführungen zu beobachten, können wir eine Abfrage für einige Leistungsstatistiken ausführen. Diese werden von SQL Server gesammelt, wenn wir unsere Abfragen ausführen, und hier wollen wir die Abfrageanweisung, die Erstellungszeit, die Ausführungsanzahl der Anweisung sowie den Abfrageplan erhalten. Die folgende Abfrage ist ein Beispiel dafür, wie wir die Leistungsstatistiken erhalten können.
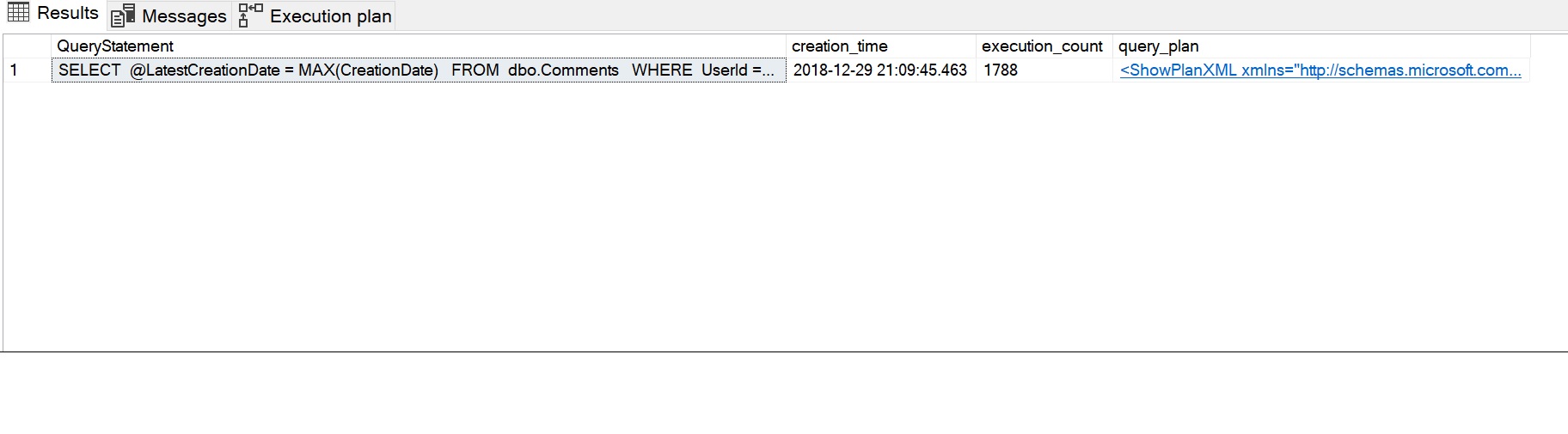
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.sfnGetRecentComment')ORDER BY deqs.last_execution_time DESC;GO
Das Ergebnis der Ausführung der Leistungsstatistiken ist im folgenden Bild zu sehen. Die Abfrageanweisung zeigt die SELECT-Anweisung, die von der skalaren Funktion verwendet wird, die Ausführungsanzahl von 1788 hat die wiederholte Ausführungsanzahl erfasst (einmal für jede Zeile) und der Plan, der von der Funktion verwendet wird, kann durch Klicken auf die Abfrageplan-XML-Nachricht eingesehen werden.
Eine weitere Möglichkeit, wichtige Leistungsmetriken zu sehen, ist die Verwendung erweiterter Ereignisse. Weitere Informationen zu erweiterten Ereignissen finden Sie hier, aber für die Zwecke unserer Demo führen Sie die folgende Abfrage aus, um eine erweiterte Ereignissitzung zu erstellen.
CREATE EVENT SESSION QuerySession ON SERVER ADD EVENT sqlserver.module_end( WHERE (.(.,(??)))), -- enter your Session Id ADD EVENT sqlserver.sp_statement_completed( WHERE (.(.,(??)))),-- enter your Session Id ADD EVENT sqlserver.sql_batch_completed( WHERE (.(.,(??)))); -- enter your Session IdGOALTER EVENT SESSION QuerySession ON SERVER STATE = START;GO
Nachdem die erweiterte Ereignissitzung erstellt wurde, gehen Sie im Objekt-Explorer zu „Verwaltung“, erweitern Sie „Sitzungen“ und öffnen Sie das Kontextmenü für „QuerySession“, die wir gerade erstellt haben. Wählen Sie „Live-Daten beobachten“.
Beobachten Sie im neu geöffneten Fenster die mehrfachen Anweisungszeilen der skalaren Funktion als Beweis für die wiederholten Ausführungen.
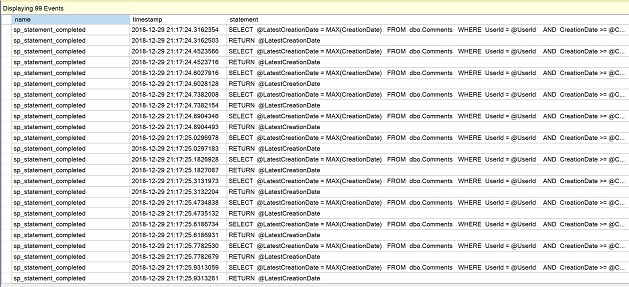
Klicken Sie auf das rote Quadrat, um die Datenzufuhr vorerst zu stoppen.
MSTVF-Performance
Auch bei MSTVFs kann es zu Performance-Einbußen durch deren Verwendung kommen, was damit zusammenhängt, dass SQL Server aufgrund ungenauer Statistiken suboptimale Ausführungspläne wählt. SQL Server verlässt sich auf intern erfasste Statistiken, um zu verstehen, wie viele Datenzeilen eine Abfrage zurückgeben wird, damit er einen optimalen Plan erstellen kann. Dieser Prozess wird als Kardinalitätsschätzung bezeichnet.
Vor SQL Server 2014 war die Kardinalitätsschätzung für Tabellenvariablen auf 1 Zeile festgelegt. Ab SQL Server 2014 ist diese auf 100 Zeilen festgelegt, unabhängig davon, ob wir eine Abfrage gegen 100 Zeilen oder 1 Million Zeilen durchführen. MSTVFs geben Daten über Tabellenvariablen zurück, die am Anfang der Funktionsdefinition deklariert werden. Die Realität ist, dass der Optimierer nicht immer den besten Plan sucht, den er finden kann, unabhängig von der Zeit, und dass er dort ein Gleichgewicht halten muss (sehr einfach ausgedrückt). Bei MSTVFs kann das Fehlen genauer Statistiken (verursacht durch ungenaue Kardinalitätsschätzungen von Tabellenvariablen innerhalb ihrer Definition) die Leistung beeinträchtigen, indem der Optimierer suboptimale Pläne erzeugt.
In der Praxis kann das Ersetzen von MSTVFs durch iTVFs eine bessere Leistung bringen, da iTVFs die Statistiken der zugrunde liegenden Tabellen verwenden.
Der folgende Codeschnipsel verwendet den APPLY-Operator, um die MSTVF gegen die gesamte Tabelle Users auszuführen. Wir geben die Id aus der Users-Tabelle und das LatestCommentDate aus der Funktion für jede Zeile in der Users-Tabelle zurück und übergeben die Id des Benutzers und das Kommentar-Datum, das auf den 01.01.2008 gesetzt ist. Ähnlich wie beim skalaren Funktionslauf werden wir dies aus einem Cold Cache tun. Führen Sie die Abfrage aus.
CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Der resultierende Ausführungsplan ist im folgenden Bild zu sehen. Beachten Sie im gelben Eigenschaftsfeld die Werte für die geschätzte Anzahl der Zeilen gegenüber der tatsächlichen Anzahl der Zeilen.
Sie sollten sehen, dass die geschätzte Anzahl der Zeilen aus der tabellenbewerteten Funktion auf 100 gesetzt ist, aber die tatsächliche Anzahl der Zeilen auf 151.482. Erinnern Sie sich daran, dass wir in unserer Einrichtung den Kompatibilitätsmodus von SQL Server 2016 (130) gewählt haben und dass ab SQL Server 2014 die Kardinalitätsschätzung für Tabellenvariablen auf 100 gesetzt ist.
Solche stark unterschiedlichen Werte für die geschätzte Anzahl von Zeilen im Vergleich zur tatsächlichen Anzahl von Zeilen schaden typischerweise der Leistung und können verhindern, dass wir optimalere Pläne und letztlich besser laufende Abfragen erhalten.
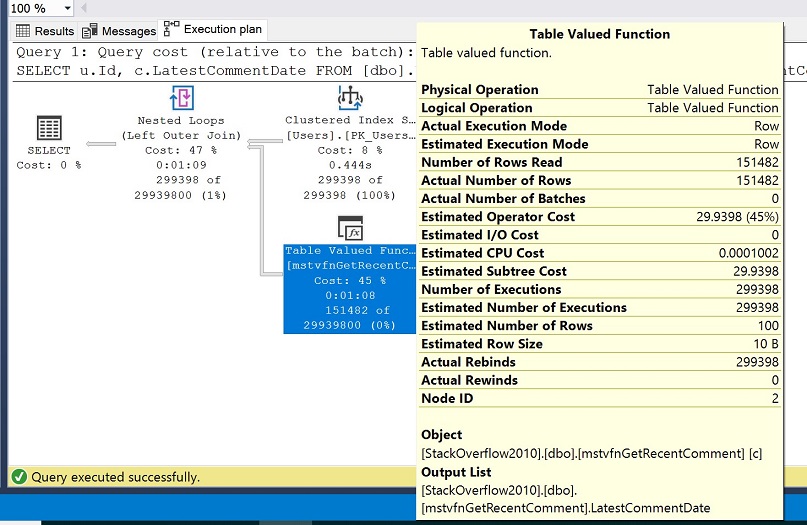
Ähnlich wie bei der skalaren Funktion, die wir zuvor ausgeführt haben, werden wir eine Abfrage gegen die Leistungsstatistiken von SQL Server laufen lassen. Auch hier wollen wir die Abfrageanweisung, die Erstellungszeit, die Ausführungsanzahl der Anweisung und den verwendeten Abfrageplan erhalten und in der WHERE-Klausel nach der MSTVF filtern.
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs OUTER APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp OUTER APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.mstvfnGetRecentComment');
Der Ausführungsplan, den wir anfangs für die MSTVF beobachtet haben, ist irreführend, da er nicht die tatsächliche Arbeit der Funktion widerspiegelt. Unter Verwendung der Leistungsstatistiken, die wir gerade ausgeführt haben, und der Auswahl der Showplan-XML sollten wir einen anderen Abfrageplan sehen, der die von der MSTVF geleistete Arbeit zeigt. Ein Beispiel für einen anderen Plan als den, den wir anfangs gesehen haben, ist der folgende. Hier können wir nun sehen, dass die MSTVF Daten in eine Tabellenvariable namens @RecentComment einfügt. Die Daten in der Tabellenvariablen @RecentComment werden dann von der MSTVF zurückgegeben, um das Datum des letzten Kommentars zu ermitteln.
Ein weiterer Aspekt der von uns erfassten Leistungsmetriken ist die Ausführungsanzahl. Hier sollten wir uns vor mehrfachen Ausführungszahlen in Acht nehmen, da diese typischerweise schlecht für die Leistung sind, wie bereits bei der Betrachtung der skalaren Leistung erwähnt.
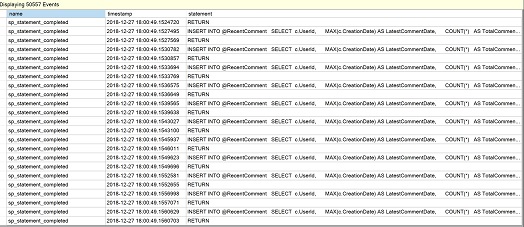
Was wir in der folgenden Abbildung für die Ausführungszahl sehen, ist ein Wert von 76, was ein Beweis für mehrfache Ausführungen unserer MSTVF ist.

Zurück zur Verwaltung im Objekt-Explorer, erweitern Sie Sitzungen und wählen Sie „Live-Daten beobachten“ für die Sitzung „QuerySessions“, die wir zuvor bei der Betrachtung der skalaren Leistung erstellt haben. Klicken Sie auf das grüne Dreieck „Start data feed“ in SSMS, wenn die Sitzung zuvor angehalten wurde, und wir sollten für unser Beispiel mehrere Anweisungszeilen der MSTVF sehen, die die wiederholten Ausführungen der Anweisung darstellen.
Sie können die Abfrage an dieser Stelle abbrechen, wenn sie noch nicht abgeschlossen ist.
iTVF-Performance
Wenn wir entweder die skalaren oder die Multi-Statement-Funktionen durch eine iTVF ersetzen, wollen wir dies tun, um die Performance-Einbußen zu vermeiden, die wir gerade gesehen haben, z.B. Ausführungszeit, Mehrfachausführungen. Anhand des folgenden Beispiels werden wir die Tabelle „Users“ abfragen, um die Id und das Datum des letzten Kommentars seit dem 01.01.2008 aus der iTVF zu erhalten. Wir werden dies auch aus einem kalten Cache tun, indem wir den SQL Server-Cache leeren und die Daten zunächst von der Festplatte beziehen.
--run in an isolated environment CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Die folgende Abfrage besteht aus den Leistungsstatistiken, die uns helfen, die ausgeführte Anweisung, die Ausführungsanzahl und den Abfrageplan für diese Anweisung zu sehen.
-- Query stats and execution planSELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.dbid = DB_ID('StackOverflow2010')ORDER BY deqs.last_execution_time DESC;
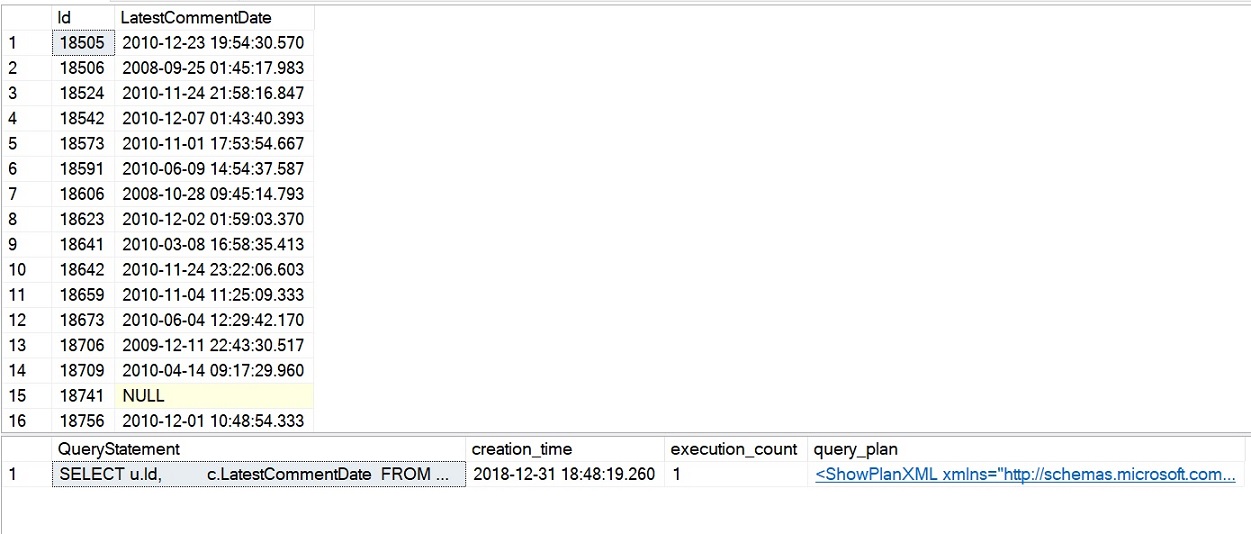
Die Beispielabfrage für die iTVF, die wir gerade ausgeführt haben, wurde in etwas mehr als 4 Sekunden abgeschlossen und die Leistungsstatistiken, die wir abgefragt haben, sollten eine Ausführungsanzahl von 1 für die iTVF zeigen, wie im folgenden Bild zu sehen ist. Dies ist eine deutliche Verbesserung der Leistung im Vergleich zu unseren früheren Beispielen mit skalaren und MSTFV-Versuchen.
Vergleich der Leistung von skalaren, MSTVF und iTVF
Die folgende Tabelle zeigt den Vergleich der 3 UDFs, die wir gerade ausgeführt haben, um zu zeigen, wie sie in Bezug auf Ausführungszeit und Ausführungsanzahl abschneiden.
| Skalar | MSTVF | iTVF | Ausführungszeit | > 5 Minuten | > 5 Minuten | 4 Sekunden | Ausführungsanzahl | > 10,000 | >10.000 | 1 |
Der Unterschied in der Ausführungszeit und der Ausführungsanzahl bei Verwendung der iTVF ist sofort ersichtlich. In unserem Beispiel lieferte die iTVF die gleichen Daten schneller und mit nur 1 Ausführung. In Umgebungen mit hoher Arbeitslast oder in Szenarien, in denen Logik in mehreren Berichten verwendet wird, die aufgrund der Verwendung von skalaren oder MSTVFs langsam sind, kann ein Wechsel zu einer iTVF helfen, schwerwiegende Performance-Probleme zu lindern.
Grenzwerte
iTVFs kommen dann ins Spiel, wenn Sie Logik wiederverwenden müssen, ohne Performance zu opfern, aber sie sind nicht perfekt. Auch sie haben ihre Grenzen.
Eine Liste der Einschränkungen und Limitierungen von benutzerdefinierten Funktionen im Allgemeinen finden Sie hier bei Books Online. Außerhalb dieser Liste und speziell für Inline-Funktionen mit Tabellenwert sind die folgenden Punkte allgemeiner Natur, die Sie berücksichtigen sollten, wenn Sie prüfen, ob sie das richtige Werkzeug für Ihr Problem sind.
Einzelne SELECT-Anweisung
Da die Definition einer iTVF auf eine SELECT-Anweisung beschränkt ist, sind Lösungen, die eine Logik über diese eine SELECT-Anweisung hinaus erfordern, bei der vielleicht eine Variablenzuweisung, bedingte Logik oder die Verwendung einer temporären Tabelle erforderlich ist, wahrscheinlich nicht für die Implementierung in einer iTVF allein geeignet.
Fehlerbehandlung
Dies ist eine Einschränkung, die alle benutzerdefinierten Funktionen betrifft, bei denen Konstrukte wie TRY CATCH nicht erlaubt sind.
Aufruf von Stored Procedures
Sie können Stored Procedures nicht aus dem Körper der iTVF aufrufen, es sei denn, es handelt sich um eine erweiterte Stored Procedure. Dies hängt mit einem Grundsatz des SQL Server UDF-Designs zusammen, wonach der Zustand der Datenbank nicht verändert werden kann, was bei der Verwendung einer Stored Procedure möglicherweise möglich wäre.
Abschluss
Dieser Artikel begann mit der Absicht, die Inline table-valued functions (iTVFs), wie sie derzeit im Jahr 2016 sind, zu überarbeiten und die Vielfalt ihrer Einsatzmöglichkeiten aufzuzeigen.
iTVFs haben den entscheidenden Vorteil, dass sie im Gegensatz zu anderen Arten von benutzerdefinierten Funktionen (UDFs) keine Leistungseinbußen haben und durch ihre Wiederverwendungs- und Kapselungsmöglichkeiten gute Entwicklungspraktiken fördern können.
Mit den neuen Funktionen in SQL Server, zunächst in SQL Server 2017 und im kommenden SQL Server 2019, wird die Leistung von skalaren und MSTVFs etwas verbessert. Weitere Details finden Sie unter „Interleaved Execution“, das eine genaue Kardinalitätsschätzung für MSTVFs anstelle der festen Zahlen 1 oder 100 bietet, und „Scalar UDF Inlining“. Beim skalaren UDF-Inlining liegt der Fokus 2019 darauf, die Performance-Schwäche von skalaren UDFs zu adressieren.
Sie sollten Ihre Lösungen unbedingt testen und sich ihrer Grenzen bewusst sein. Wenn sie gut eingesetzt werden, sind sie eines der besseren Werkzeuge, die wir in unserem SQL-Arsenal haben können.
Danke fürs Lesen.