En caso de que hayamos olvidado o no hayamos visto nunca las funciones valoradas en tabla en línea, empezaremos con una rápida explicación de lo que son.
Tomando la definición de lo que es una función definida por el usuario (UDF) de Books Online, una función inline con valor de tabla (iTVF) es una expresión de tabla que puede aceptar parámetros, realizar una acción y proporcionar como valor de retorno, una tabla. La definición de una iTVF se almacena permanentemente como un objeto de la base de datos, de forma similar a como lo haría una vista.
La sintaxis para crear un iTVF desde Books Online (BOL) se puede encontrar aquí y es la siguiente:
CREATE FUNCTION function_name ( parameter_data_type } ] ) RETURNS TABLE ] RETURN select_stmt
El siguiente fragmento de código es un ejemplo de un iTVF.
CREATE OR ALTER FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN (SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Comments cWHERE c.UserId = @UserId AND c.CreationDate >= @CommentDateGROUP BY c.UserId);
Algunas cosas que vale la pena mencionar en el script anterior.
DEFAULT VALUE () – Puede establecer valores por defecto para los parámetros y en nuestro ejemplo, @CommentDate tiene un valor por defecto de 01 Ene 2006.
RETURNS TABLE – Devuelve una tabla virtual basada en la definición de la función
SCHEMABINDING – Especifica que la función está vinculada a los objetos de la base de datos a los que hace referencia. Cuando se especifica schemabinding, los objetos base no pueden ser modificados de forma que afecten a la definición de la función. La propia definición de la función debe modificarse o eliminarse primero para eliminar las dependencias del objeto que se va a modificar (de BOL).
Al observar la sentencia SELECT en el ejemplo de iTVF, es similar a una consulta que se colocaría en una vista, excepto por el parámetro que se pasa en la cláusula WHERE. Esta es una diferencia crítica.
Aunque un iTVF es similar a una vista en el sentido de que la definición se almacena permanentemente en la base de datos, al tener la capacidad de pasar parámetros no sólo tenemos una forma de encapsular y reutilizar la lógica, sino también la flexibilidad de poder consultar valores específicos que querríamos pasar. En este caso, podemos imaginar que una función inline table-valued es una especie de «vista parametrizada».
¿Por qué usar una iTVF?
Antes de entrar a ver cómo usamos las iTVFs, es importante considerar por qué las usaríamos. Los iTVFs nos permiten dar soluciones en apoyo de aspectos como (pero no limitados a):
- Desarrollo modular
- Flexibilidad
- Evitar penalizaciones en el rendimiento
- Devolver la lista de columnas completa
- Devolver las columnas especificadas
- Utilizar valores por defecto pasando la palabra clave, DEFAULT
- Pasar el iTVF en la cláusula WHERE
- Utilizar el iTVF en la cláusula HAVING
- Utilizar el iTVF en la cláusula SELECT
A continuación hablaré un poco de cada uno de ellos.
Desarrollo modular
Los iTVFs pueden fomentar buenas prácticas de desarrollo, como el desarrollo modular. Esencialmente, queremos asegurarnos de que nuestro código es «DRY» y no repetir código que hemos producido previamente cada vez que se necesita en un lugar diferente.
Ignorando los casos en los que el desarrollo modular se lleva a la enésima potencia a costa de un código mantenible, los beneficios de la reutilización del código y la encapsulación con los iTVFs son una de las primeras cosas que notamos.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Users u INNER JOIN dbo.Comments c ON u.Id = c.UserIdWHERE c.CreationDate >= @CommentDateGROUP BY u.Id, u.Reputation;GO
VS
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u CROSS APPLY .(u.Id, @CommentDate) c;GO
La consulta que utiliza el iTVF es sencilla y cuando se utiliza en consultas más complicadas, puede ayudar realmente a los esfuerzos de desarrollo al ocultar la complejidad subyacente. En los escenarios en los que necesitamos retocar la lógica de la función con fines de mejora o depuración, podemos hacer el cambio en un objeto, probarlo y ese único cambio se reflejará en los demás lugares en los que se llame a la función.
Si hubiéramos repetido la lógica en varios lugares, habría que hacer el mismo cambio varias veces con el riesgo de que se produzcan errores, desviaciones u otros contratiempos cada vez. Esto significa que tenemos que entender dónde reutilizamos la lógica en los iTVFs, para poder probar que no hemos introducido esas características molestas conocidas como bugs.
Flexibilidad
Cuando se trata de flexibilidad, la idea es utilizar la capacidad de las funciones para pasar valores de parámetros y ser fáciles de interactuar. Como veremos con ejemplos más adelante, podemos interactuar con el iTFV como si estuviéramos consultando una tabla.
Si la lógica estuviera en un procedimiento almacenado, por ejemplo, probablemente tendríamos que llevar los resultados a una tabla temporal y luego consultar la tabla temporal para interactuar con los datos.
Si la lógica estuviera en una vista, no podríamos pasar un parámetro. Nuestras opciones incluirían consultar la vista y luego añadir una cláusula WHERE fuera de la definición de la vista. Aunque no es un gran problema para esta demostración, en las consultas complicadas, simplificar con un iTVF puede ser una solución más elegante.
Evitando las penalizaciones de rendimiento
Para el alcance de este artículo, no voy a ver los UDFs de Common Language Runtime (CLR).
Donde empezamos a ver una divergencia entre los iTVFs y otros UDFs es el rendimiento. Se puede decir mucho sobre el rendimiento, y en su mayor parte, otros UDFs sufren mucho, en cuanto a rendimiento. Una alternativa podría ser reescribirlos como iTVFs en su lugar, ya que el rendimiento es un poco diferente para los iTFVs. No sufren las mismas penalizaciones de rendimiento que afectan a las funciones escalares o a las funciones de valor de tabla de varias sentencias (MSTVFs).
Las iTVFs, como su nombre indica, se alinean en el plan de ejecución. Con el optimizador desanidando los elementos de consulta de la definición e interactuando con las tablas subyacentes (inlining), tiene más posibilidades de obtener un plan óptimo, ya que el optimizador puede considerar las estadísticas de las tablas subyacentes y tiene a su disposición, otras optimizaciones como el paralelismo, si esto es necesario.
Para muchas personas, el rendimiento por sí solo ha sido una gran razón para utilizar iTVFs en lugar de escalares o MSTVFs. Incluso si no le importa el rendimiento todavía, las cosas pueden cambiar muy rápidamente con mayores volúmenes o aplicaciones complicadas de su lógica, por lo que es importante entender las trampas de los otros tipos de UDFs. Más adelante en este artículo, mostraremos una comparación básica de rendimiento que involucra a los iTVFs y otros tipos de UDFs.
Ahora que hemos enumerado algunas razones para usar los iTVFs, vamos a ver cómo podemos usarlos.
Demostración de iTVFs
En esta demostración, utilizaremos la base de datos StackOverflow2010, que está disponible de forma gratuita en la encantadora gente de StackOverflow a través de https://archive.org/details/stackexchange
Alternativamente, puede obtener la base de datos a través de la otra encantadora gente de Brent Ozar Unlimited aquí : https://www.brentozar.com/archive/2015/10/how-to-download-the-stack-overflow-database-via-bittorrent/
He restaurado la base de datos de StackOverflow en mi SQL Server 2016 Developer Edition local, en un entorno aislado. Ejecutaré una demostración rápida en mi versión instalada de SQL Server Management Studio (SSMS) v18.0 Preview 5. También he configurado el modo de compatibilidad a 2016 (130) y estoy ejecutando la demostración en una máquina con una CPU Intel i7 de 2,11 GHz y 16 GB de RAM.
Una vez que esté en funcionamiento con la base de datos de StackOverflow, ejecute el T-SQL en el archivo de recursos 00_iTFV_Setup.sql contenido en este artículo para crear los iTVFs que utilizaremos. La lógica de estos iTVFs es sencilla y puede repetirse en varios lugares, pero aquí la escribiremos una vez y la ofreceremos para su reutilización.
Usando un iTVF como una Tabla Virtual
Recuerde que los iTVFs no se persisten en ningún lugar de la base de datos. Lo que se persiste es su definición. Todavía podemos interactuar con los iTVFs como si fueran tablas, así que en este sentido, los tratamos como tablas virtuales.
Los siguientes 6 ejemplos muestran formas en que podemos tratar los iTVFs como tablas virtuales. Con la base de datos de StackOverflow en funcionamiento en su máquina, no dude en ejecutar las siguientes 6 consultas de la Sección 1 para comprobarlo por sí mismo. También puedes encontrarlas en el archivo, 01_Demo_SSC_iTVF_Creating_Using.sql.
/**************************************************************************1. Using iTVFs in queries as if it were a table.**************************************************************************/DECLARE @UserId INT= 3, @CommentDate DATE= '2006-01-01T00:00:00.000';--1.1 Get specific columnsSELECT UserId, LatestCommentDateFROM dbo.itvfnGetRecentComment(3, '2006-01-01T00:00:00.000');--1.2 Get all columns SELECT *FROM dbo.itvfnGetRecentComment(@UserId, @CommentDate);--1.3 Use a default valueSELECT UserId, LatestCommentDate, TotalCommentsFROM dbo.itvfnGetRecentComment(@UserId, DEFAULT);--1.4 In the WHERE clauseSELECT u.DisplayName, u.Location, u.ReputationFROM dbo.Users uWHERE u.Reputation <=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(@UserId, DEFAULT));--1.5 In the HAVING clauseSELECT u.Location, SUM(u.Reputation) AS TotalRepFROM dbo.Users uGROUP BY u.LocationHAVING SUM(u.Reputation) >=( SELECT rc.TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT) rc);--1.6 In the SELECT clauseSELECT u.Location, CASE WHEN SUM(u.Reputation) >=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT)) THEN 'YES' ELSE 'NO' END AS InRepLimitFROM dbo.Users uGROUP BY u.Location;
Como se muestra arriba, cuando interactuamos con iTVFs, podemos:
Para poner esto en perspectiva, normalmente con un procedimiento almacenado, uno insertaría el conjunto de resultados en una tabla temporal y luego interactuaría con la tabla temporal para hacer lo anterior. Con un iTVF, no es necesario interactuar con otros objetos fuera de la definición de la función para casos similares a los 6 que acabamos de ver.
iTVFs en funciones anidadas
Aunque el anidamiento de funciones puede traer sus propios problemas si se hace mal, es algo que podemos hacer dentro de un iTVF. Por el contrario, cuando se utiliza adecuadamente, puede ser muy útil para ocultar la complejidad.
En nuestro ejemplo artificioso, la función, dbo.itvfnGetRecentCommentByRep, devuelve el último comentario de un usuario, el total de comentarios, etc, añadiendo un filtro adicional para la reputación.
SELECT DisplayName, LatestCommentDate, ReputationFROM .(3, DEFAULT, DEFAULT);GO
Cuando devolvemos la fecha del último comentario, esto es a través de la llamada a la otra función, dbo.itvfnGetRecentComment.
CREATE OR ALTER FUNCTION . (@UserId int, @Reputation int = 100, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN ( SELECT u.DisplayName, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) cWHERE u.Id = @UserId AND u.Reputation >= @Reputation);GO
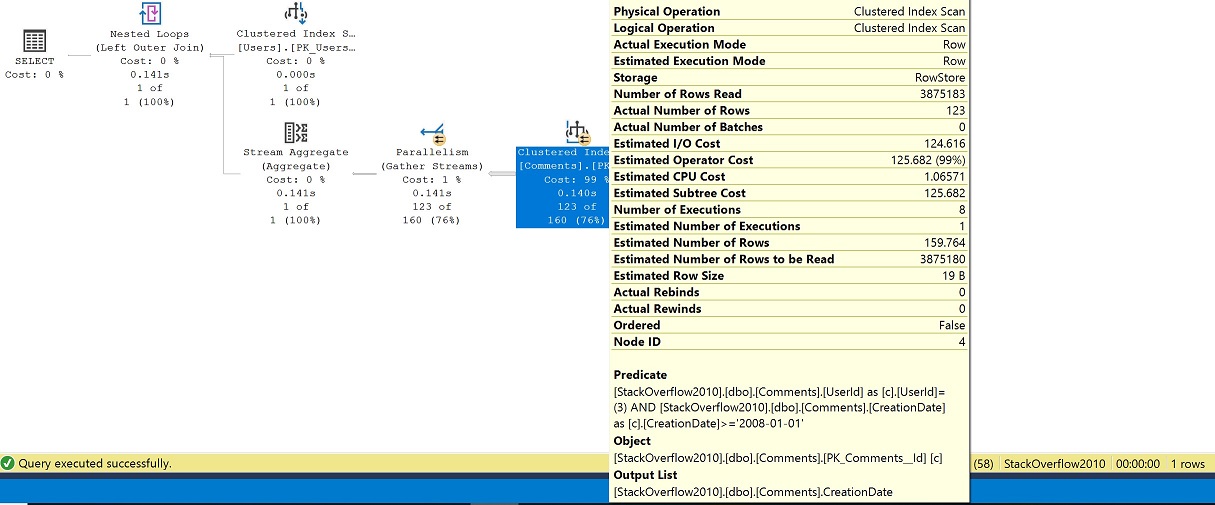
En el ejemplo, podemos ver que incluso con el anidamiento de funciones, la definición subyacente se inlinea y los objetos con los que interactuamos son los índices agrupados, dbo.Users y dbo.Comments.
En el plan, sin un índice decente para soportar nuestros predicados, se realiza un escaneo de índice agrupado de la tabla Comments, además de ir en paralelo donde terminamos el número de ejecuciones como 8. Filtramos por UserId 3 de la tabla Users por lo que obtenemos una búsqueda en la tabla Users y luego nos unimos a la tabla Comments después del GROUP BY (stream aggregate) para la última fecha del comentario.
Utilizando el operador APPLY
El operador APPLY ofrece muchos usos creativos, y es ciertamente una opción que podemos aplicar (juego de palabras) para interactuar con un iTVF. Para obtener más información sobre el operador APPLY, consulte los siguientes documentos: https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms175156(v=sql.105) y http://www.sqlservercentral.com/articles/Stairway+Series/121318/
En el siguiente ejemplo queremos llamar al iTVF para todos los usuarios y devolver su LatestCommentDate, Total Comments, Id y Reputation desde el 01 Jan 2008. Para ello utilizamos el operador APPLY, donde se ejecuta para cada fila de la tabla Users completa, pasando el Id de la tabla Users y el CommentDate. Al hacer esto, conservamos las ventajas de encapsulación de utilizar iTVF, aplicando nuestra lógica a todas las filas de la tabla Users.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
iTVFs en JOINs
De forma similar a la unión de 2 o más tablas, podemos involucrar iTVFs en joins con otras tablas. En este caso, queremos el DisplayName de la tabla Users y el UserId, BadgeName y BadgeDate del iTVF, para los usuarios que obtuvieron la insignia de ‘Estudiante’ a partir del 01 de enero de 2008.
DECLARE @BadgeName varchar(40)= 'Student', @BadgeDate datetime= '2008-01-01T00:00:00.000';SELECT u.DisplayName, b.UserId, b.BadgeName, b.BadgeDateFROM dbo.Users u INNER JOIN .(@BadgeName, @BadgeDate) b ON b.UserId = u.Id;GO
Alternativa a otros UDFs
Al principio de este artículo mencionamos que una razón para utilizar los iTVFs era evitar las penalizaciones de rendimiento que sufren otros tipos de UDFs como los escalares y los MSTVFs. Esta sección demostrará cómo podemos reemplazar las UDFs escalares y MSTVFs con las iTVFs y la siguiente parte analizará por qué podemos elegir hacerlo.
Alternativa UDF escalar
Antes de continuar, vamos a ejecutar la siguiente consulta para crear la UDF escalar, dbo.sfnGetRecentComment que utilizaremos en breve.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS datetimeWITH SCHEMABINDING, RETURNS NULL ON NULL INPUTASBEGIN DECLARE @LatestCreationDate datetime; SELECT @LatestCreationDate = MAX(CreationDate) FROM dbo.Comments WHERE UserId = @UserId AND CreationDate >= @CommentDate GROUP BY UserId; RETURN @LatestCreationDate;END;GO
Después de crear la función escalar, ejecute la siguiente consulta. Aquí queremos utilizar la usar la lógica encapsulada en la función escalar para consultar toda la tabla Usuarios y devolver el Id y la fecha del último comentario de cada usuario desde el 01 Ene 2008. Esto lo hacemos añadiendo la función en la cláusula SELECT donde para los valores de los parámetros, pasaremos el Id de la tabla Usuarios y la fecha del comentario que acabamos de establecer en el 01 Ene 2008.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Una consulta similar se puede escribir utilizando un iTVF, que se muestra en la siguiente consulta. Aquí queremos obtener el Id y la fecha del último comentario desde el 01 de enero de 2008 utilizando el iTVF y lo conseguimos utilizando el operador APPLY contra todas las filas de la tabla Usuarios. Para cada fila pasamos el Id del usuario y la fecha del comentario.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Alternativa MSTVF
Ejecuta la siguiente consulta para crear el MSTVF dbo.mstvfnGetRecentComment, que usaremos en breve.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS @RecentComment TABLE( int NULL, date NULL, int NULL)WITH SCHEMABINDING ASBEGIN INSERT INTO @RecentComment SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalComments FROM dbo.Comments c WHERE c.UserId = @UserId AND c.CreationDate >= @CommentDate GROUP BY c.UserId; RETURN;END;GO
Ahora que hemos creado el MSTVF, lo utilizaremos para devolver la fecha del último comentario de todas las filas de la tabla Usuarios desde el 01 de enero de 2008. Al igual que en el ejemplo de iTVF con el operador APPLY de la parte anterior de este artículo, «aplicaremos» nuestra función a todas las filas de la tabla Users mediante el operador APPLY y pasaremos el Id de usuario de cada fila, así como la fecha de comentario que establezcamos.
DECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Cuando sustituimos el MSTVF de nuestro ejemplo por un iTVF, el resultado es muy similar, salvo por el nombre de la función que se llama. En nuestro caso la llamaremosvfnGetRecentComment en lugar de la MSTVF del ejemplo anterior, conservando las columnas en la cláusula SELECT. Esto nos permite obtener el Id y la fecha del último comentario desde el 1 de enero de 2008 utilizando el iTVF para todas las filas de la tabla Usuarios. Esto se muestra en la consulta que sigue.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Una preferencia por las iTVF
Una razón para elegir una iTVF sobre una función escalar o MSTVF es el rendimiento.
En breve capturaremos el rendimiento de las 3 funciones basándonos en las consultas de ejemplo que ejecutamos en la sección anterior y no entraremos en mucho detalle, más que en comparar el rendimiento a través de métricas como el tiempo de ejecución y el recuento de ejecuciones de las funciones. El código para las estadísticas de rendimiento que utilizaremos a lo largo de esta demostración, es del Listado 9.3 en los ejemplos de código de la 3ª edición de SQL Server Execution Plans de Grant Fritchey https://www.red-gate.com/simple-talk/books/sql-server-execution-plans-third-edition-by-grant-fritchey/
Rendimiento escalar
Aquí está la consulta anterior que ejecutamos invocando la función escalar.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Es bien sabido que las funciones escalares inhiben el paralelismo y que una sentencia con una función escalar se invoca una vez por cada fila. Si tu tabla tiene 10 filas, puedes estar bien. Unos cuantos miles de filas, y puede que se sorprenda (o no) por la drástica caída del rendimiento. Veamos esto en acción ejecutando el siguiente fragmento de código.
Lo que queremos hacer primero es limpiar (en un entorno aislado) la caché de SQL Server y el plan existente que podría ser reutilizado(FREEPROCCACHE), asegurando que obtenemos los datos del disco primero (DROPPCLEANBUFFERS) para comenzar con una caché fría. A grandes rasgos, estamos empezando de cero al hacer esto.
Después de esto, ejecutamos la consulta SELECT sobre la tabla Users donde devolvemos el Id y LatestCommentDate usando la función escalar. Como valores de los parámetros, pasaremos el Id de la tabla Users y la fecha del comentario que acabamos de establecer en 01 Ene 2008. Un ejemplo es el siguiente.
-- run in an isolated environmentCHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Aunque la consulta SELECT en la que utilizamos la función escalar puede parecer de estructura simple, después de 4 minutos en mi máquina, todavía se estaba ejecutando.
Recordemos que para las funciones escalares, se ejecutan una vez por cada fila. El problema con esto es que las operaciones fila por fila son muy raramente la forma más eficiente de recuperar datos en SQL Server en comparación con las operaciones basadas en un solo conjunto.
Para observar las ejecuciones repetidas, podemos ejecutar una consulta para algunas estadísticas de rendimiento. Estas son recogidas por SQL Server cuando ejecutamos nuestras consultas y aquí, queremos obtener la sentencia de consulta, el tiempo de creación, el recuento de ejecución de la sentencia así como el plan de consulta. La siguiente consulta es un ejemplo de cómo podemos obtener las estadísticas de rendimiento.
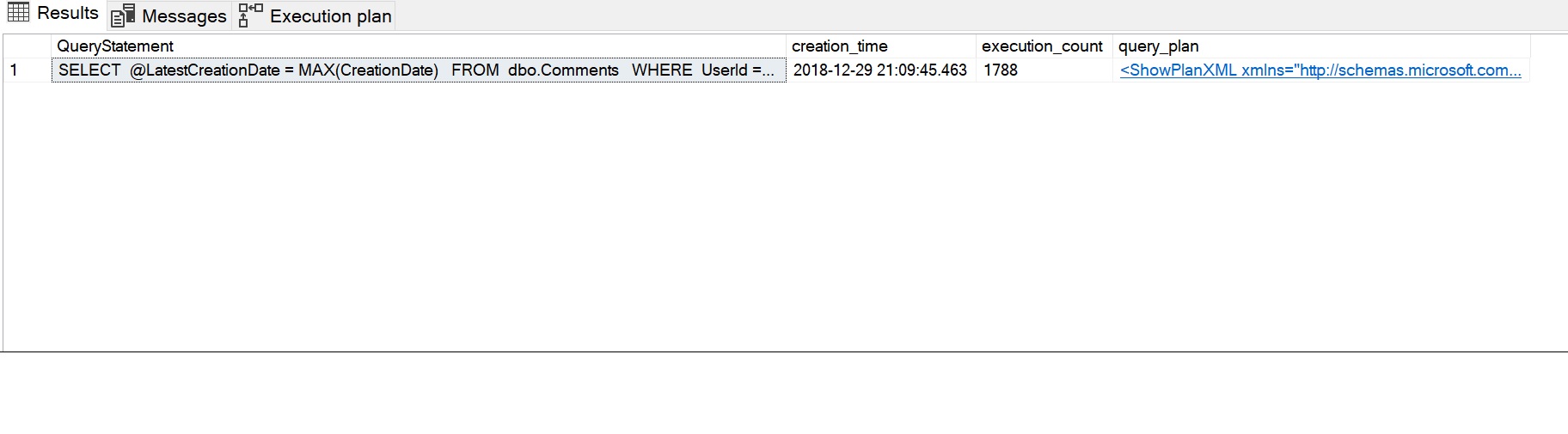
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.sfnGetRecentComment')ORDER BY deqs.last_execution_time DESC;GO
La ejecución resultante de las estadísticas de rendimiento se puede ver en la siguiente imagen. La sentencia de consulta muestra la sentencia SELECT utilizada por la función escalar, el recuento de ejecución de 1788 ha capturado el recuento de ejecución repetida (una vez por cada fila) y el plan que es utilizado por la función se puede ver haciendo clic en el mensaje XML del plan de consulta.
Una forma adicional de ver las métricas de rendimiento importantes es mediante el uso de eventos extendidos. Para obtener más información sobre los eventos extendidos, haga clic aquí, pero para los fines de nuestra demostración, ejecute la siguiente consulta para crear una sesión de eventos extendidos.
CREATE EVENT SESSION QuerySession ON SERVER ADD EVENT sqlserver.module_end( WHERE (.(.,(??)))), -- enter your Session Id ADD EVENT sqlserver.sp_statement_completed( WHERE (.(.,(??)))),-- enter your Session Id ADD EVENT sqlserver.sql_batch_completed( WHERE (.(.,(??)))); -- enter your Session IdGOALTER EVENT SESSION QuerySession ON SERVER STATE = START;GO
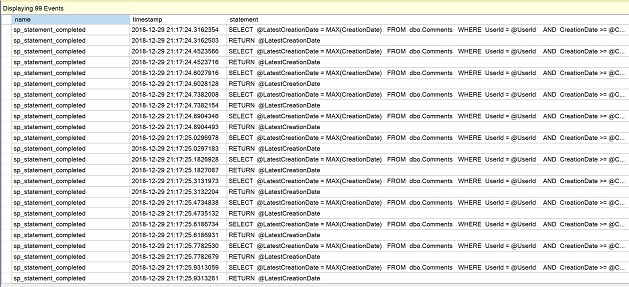
Una vez creada la sesión de eventos extendidos, vaya a Gestión en el Explorador de objetos, expanda las sesiones y abra el menú contextual de «QuerySession» que acabamos de crear. Seleccione «Watch live data».
En la ventana recién abierta, observe las múltiples líneas de sentencia de la función escalar como evidencia de las ejecuciones repetidas.
Pulse sobre el cuadrado rojo para «Detener la alimentación de datos» por ahora.
Rendimiento de MSTVF
Para los MSTVF, también puede haber penalizaciones de rendimiento como resultado de su uso y esto está vinculado a que SQL Server elige planes de ejecución subóptimos debido a estadísticas inexactas. SQL Server se basa en las estadísticas capturadas internamente para entender cuántas filas de datos devolverá una consulta y así poder producir un plan óptimo. Este proceso se conoce como estimación de cardinalidad.
Antes de SQL Server 2014, la estimación de cardinalidad para las variables de tabla se establecía en 1 fila. A partir de SQL Server 2014 se establece en 100 filas, independientemente de que estemos consultando contra 100 filas o contra 1 millón de filas. Las MSTVF devuelven datos a través de variables de tabla que se declaran al principio de la definición de la función. La realidad es que el optimizador no va a buscar el mejor plan que pueda encontrar nunca, independientemente del tiempo, y debe mantener un equilibrio ahí (dicho de forma muy sencilla). Con los MSTVF, la falta de estadísticas precisas (causada por la estimación inexacta de la cardinalidad de las variables de la tabla dentro de su definición) puede inhibir el rendimiento haciendo que el optimizador produzca planes subóptimos.
En la práctica, la sustitución de los MSTVF por los iTVF puede aportar un mejor rendimiento, ya que los iTVF utilizarán las estadísticas de las tablas subyacentes.
El siguiente fragmento de código utiliza el operador APPLY para ejecutar el MSTVF contra toda la tabla Users. Devolvemos el Id de la tabla Users y el LatestCommentDate de la función para cada fila de la tabla Users, pasando el Id del usuario y la fecha del comentario que se establece para el 01 Ene 2008. De forma similar a la ejecución de la función escalar, haremos esto desde una caché fría. Con esta prueba, ten también seleccionado el plan de ejecución Real en SSMS, pulsando Ctrl + M. Ejecuta la consulta.
CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
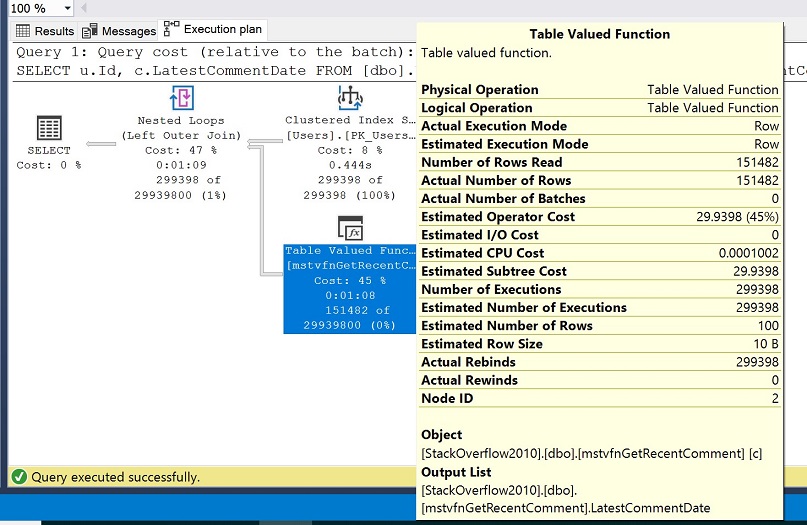
El plan de ejecución resultante se muestra en la siguiente imagen y en el cuadro de propiedades amarillo, fíjate en los valores del número de filas estimado frente al número de filas real.
Debe ver que el número estimado de filas de la función valorada de la tabla se establece en 100 pero el número real de filas se establece en 151.482. Recordemos que en nuestra configuración, elegimos el modo de compatibilidad de SQL Server 2016 (130) y que a partir de SQL Server 2014, la estimación de cardinalidad se establece en 100 para las variables de tabla.
Estos valores tan dispares para el número de filas estimadas frente al número real de filas suelen perjudicar el rendimiento y pueden impedirnos obtener planes más óptimos y, en definitiva, ejecutar mejor las consultas.
De forma similar a la función escalar que ejecutamos anteriormente, ejecutaremos una consulta contra las estadísticas de rendimiento de SQL Server. Aquí también queremos obtener la sentencia de consulta, el tiempo de creación, el recuento de ejecución de la sentencia y el plan de consulta utilizado y filtrado para la MSTVF en la cláusula WHERE.
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs OUTER APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp OUTER APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.mstvfnGetRecentComment');
El plan de ejecución que observamos inicialmente para la MSTVF es engañoso ya que no refleja el trabajo real realizado por la función. Utilizando las estadísticas de rendimiento que acabamos de ejecutar y seleccionando el XML de Showplan, deberíamos ver un plan de consulta diferente que muestre el trabajo que está realizando la MSTVF. Un ejemplo del plan diferente al que vimos inicialmente es el siguiente. Aquí podemos ver que el MSTVF inserta datos en una variable de tabla llamada @RecentComment. Los datos de la variable de tabla @RecentComment es lo que luego devuelve el MSTVF para devolver la fecha del último comentario.
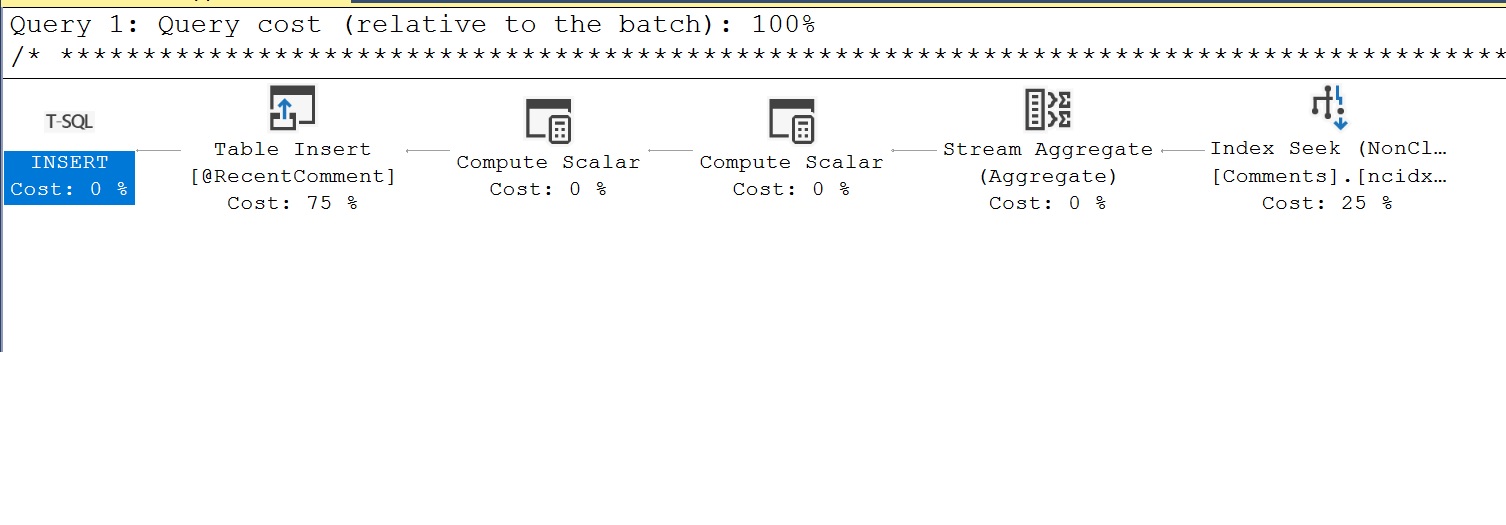
Otro aspecto de las métricas de rendimiento que capturamos es el recuento de ejecución. Aquí queremos ser cautelosos con los recuentos de ejecuciones múltiples ya que estos son típicamente malos para el rendimiento como se mencionó al mirar el rendimiento escalar.
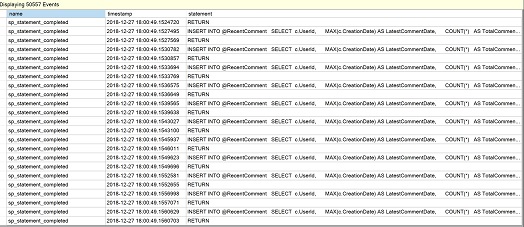
Lo que vemos en la siguiente imagen para el recuento de ejecuciones, es un valor de 76 que es evidencia de múltiples ejecuciones de nuestro MSTVF.

Volvamos a Gestión en el Explorador de Objetos, expandamos las sesiones y Seleccionemos «Watch live data» para la sesión «QuerySessions» que creamos anteriormente cuando miramos el rendimiento escalar. Pinchemos en el triángulo verde de «Iniciar alimentación de datos» en SSMS si la sesión fue detenida previamente y deberíamos ver para nuestro ejemplo, múltiples líneas de sentencias del MSTVF que representan las ejecuciones repetidas de la sentencia.
Siéntase libre de cancelar la consulta en este punto si aún no se ha completado.
Rendimiento de iTVF
Cuando sustituimos las funciones escalares o de múltiples sentencias por una iTVF, queremos hacerlo para evitar las penalizaciones de rendimiento que acabamos de ver, por ejemplo, el tiempo de ejecución, las ejecuciones múltiples. Utilizando el ejemplo anterior que sigue, consultaremos la tabla Usuarios para obtener el Id y la Fecha de Último Comentario del iTVF desde el 01 Ene 2008. utilizando el operador APPLY. También lo haremos desde una caché fría borrando la caché de SQL Server y obteniendo los datos desde el disco para empezar.
--run in an isolated environment CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
La siguiente consulta consiste en las estadísticas de rendimiento que nos ayudan a ver la sentencia que se está ejecutando, el recuento de ejecuciones y el plan de consulta de dicha sentencia.
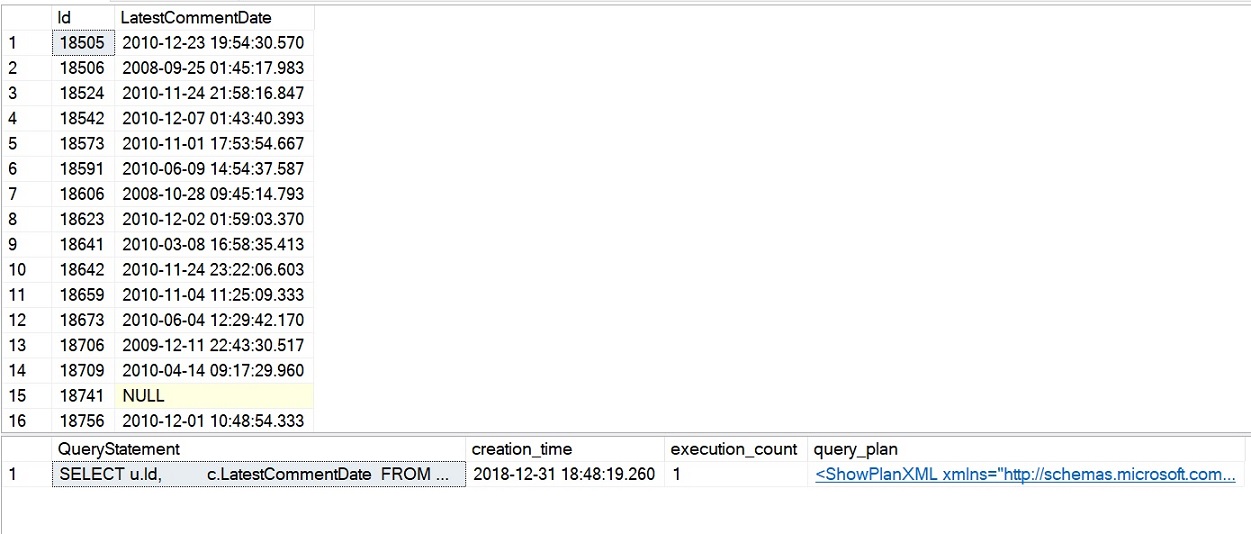
-- Query stats and execution planSELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.dbid = DB_ID('StackOverflow2010')ORDER BY deqs.last_execution_time DESC;
La consulta de ejemplo para el iTVF que acabamos de ejecutar se completó en poco más de 4 segundos y las estadísticas de rendimiento que consultamos deberían mostrar un recuento de ejecución de 1 para el iTVF, como se muestra en la siguiente imagen. Se trata de una mejora notable en el rendimiento en comparación con nuestros ejemplos anteriores con intentos de escalar y MSTFV.
Comparación del rendimiento de escalar, MSTVF e iTVF
La siguiente tabla captura la comparación de las 3 UDF que acabamos de ejecutar para mostrar cómo se comportaron en términos de tiempo de ejecución y recuento de ejecuciones.
| Escalar | MSTVF | iTVF | Tiempo de ejecución | > 5 minutos | > 5 minutos | 4 segundos |
| Cuento de ejecuciones | > 10,000 | >10,000 | 1 |
La diferencia en el tiempo de ejecución y en el recuento de ejecuciones al utilizar el iTVF es inmediatamente evidente. En nuestro ejemplo, el iTVF devolvió los mismos datos más rápido y con sólo 1 ejecución. En entornos en los que hay grandes cargas de trabajo o para escenarios en los que la lógica se utiliza en múltiples informes que son lentos debido al uso de escalares o MSTVF, un cambio a un iTVF puede ayudar a aliviar los problemas graves de rendimiento.
Limitaciones
Los iTVF realmente entran en juego cuando se necesita reutilizar la lógica sin sacrificar el rendimiento, pero no son perfectos. También tienen limitaciones.
Para una lista de limitaciones y restricciones de las funciones definidas por el usuario en general puedes visitar Books Online aquí. Fuera de esa lista y específicamente para las funciones valoradas por tablas en línea, los siguientes son puntos generales a considerar cuando se evalúa si son la herramienta adecuada para un problema que pueda tener.
Sólo una sentencia SELECT
Como la definición de una iTVF está restringida a 1 sentencia SELECT, las soluciones que requieren lógica más allá de esa 1 sentencia SELECT donde tal vez se requiere la asignación de variables, la lógica condicional o el uso de tablas temporales, probablemente no son adecuadas para implementar en una iTVF sola.
Manejo de errores
Esta es una restricción que afecta a todas las funciones definidas por el usuario donde construcciones como TRY CATCH no están permitidas.
Llamada a procedimientos almacenados
No puede llamar a procedimientos almacenados desde el cuerpo del iTVF a menos que sea un procedimiento almacenado extendido. Esto está relacionado con un principio del diseño de las UDF de SQL Server en el que no se puede alterar el estado de la base de datos, cosa que si se utilizara un procedimiento almacenado, posiblemente sí se podría.
Conclusión
Este artículo comenzó con la intención de revisar las funciones valoradas en tabla en línea (iTVF) tal y como están actualmente en 2016, mostrando la variedad de formas en las que se pueden utilizar.
Las iTVFs tienen un beneficio clave en que no sacrifican el rendimiento a diferencia de otros tipos de funciones definidas por el usuario (UDFs) y pueden fomentar buenas prácticas de desarrollo con sus capacidades de reutilización y encapsulación.
Con las recientes características de SQL Server, primero en SQL Server 2017 y en el próximo SQL Server 2019, el rendimiento de cualquiera de las funciones escalares y MSTVFs tiene alguna ayuda extra. Para más detalles, revise la ejecución intercalada que busca proporcionar una estimación precisa de cardinalidad para MSTVFs en lugar de los números fijos o 1 o 100 y el inlining de UDF escalar. Con el inlining de UDF escalares en 2019, la atención se centra en abordar la debilidad de rendimiento de los UDF escalares.
Para sus soluciones, asegúrese de probar y ser consciente de sus limitaciones. Cuando se usan bien, son una de las mejores herramientas que podríamos tener en nuestro arsenal SQL.
Gracias por leer.