Nel caso in cui abbiamo dimenticato o non abbiamo mai incontrato prima le funzioni inline table-valued, cominceremo con una rapida spiegazione di cosa sono.
Prendendo la definizione di cosa sia una funzione definita dall’utente (UDF) da Books Online, una funzione inline table-valued (iTVF) è un’espressione di tabella che può accettare parametri, eseguire un’azione e fornire come valore di ritorno una tabella. La definizione di una iTVF è memorizzata in modo permanente come un oggetto del database, come farebbe una vista.
La sintassi per creare un iTVF da Books Online (BOL) può essere trovata qui ed è la seguente:
CREATE FUNCTION function_name ( parameter_data_type } ] ) RETURNS TABLE ] RETURN select_stmt
Il seguente snippet di codice è un esempio di un iTVF.
CREATE OR ALTER FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN (SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Comments cWHERE c.UserId = @UserId AND c.CreationDate >= @CommentDateGROUP BY c.UserId);
Alcune cose da menzionare nello script sopra.
VALORE DI DEFAULT () – Puoi impostare valori di default per i parametri e nel nostro esempio, @CommentDate ha un valore di default di 01 gennaio 2006.
RITORNA TABLE – Restituisce una tabella virtuale basata sulla definizione della funzione
SCHEMABINDING – Specifica che la funzione è legata agli oggetti del database a cui fa riferimento. Quando viene specificato lo schemabinding, gli oggetti base non possono essere modificati in modo da influenzare la definizione della funzione. La definizione della funzione stessa deve essere prima modificata o abbandonata per rimuovere le dipendenze dall’oggetto che deve essere modificato (da BOL).
Guardando l’istruzione SELECT nell’esempio iTVF, è simile a una query che mettereste in una vista, tranne per il parametro passato nella clausola WHERE. Questa è una differenza fondamentale.
Anche se un iTVF è simile a una vista in quanto la definizione è memorizzata in modo permanente nel database, avendo la possibilità di passare dei parametri abbiamo non solo un modo di incapsulare e riutilizzare la logica, ma anche la flessibilità di essere in grado di interrogare per valori specifici che vorremmo passare. In questo caso, possiamo immaginare una funzione inline table-valued come una sorta di “vista parametrizzata”.
Perché usare una iTVF?
Prima di addentrarci nel vedere come usare le iTVF, è importante considerare perché usarle. Gli ITVF ci permettono di fornire soluzioni a supporto di aspetti quali (ma non solo):
- Sviluppo modulare
- Flessibilità
- Evitare penalizzazioni di performance
Discuterò ognuno di questi aspetti di seguito.
Sviluppo modulare
iTFV possono incoraggiare buone pratiche di sviluppo, come lo sviluppo modulare. Essenzialmente, vogliamo assicurarci che il nostro codice sia “DRY” e non ripetere il codice che abbiamo precedentemente prodotto ogni volta che è necessario in un posto diverso.
Ignorando i casi in cui lo sviluppo modulare è portato all’ennesima potenza a costo di codice mantenibile, i benefici del riutilizzo del codice e dell’incapsulamento con gli iTVF sono una delle prime cose che notiamo.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalCommentsFROM dbo.Users u INNER JOIN dbo.Comments c ON u.Id = c.UserIdWHERE c.CreationDate >= @CommentDateGROUP BY u.Id, u.Reputation;GO
VS
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u CROSS APPLY .(u.Id, @CommentDate) c;GO
La query che utilizza l’iTVF è semplice e quando viene utilizzata in query più complicate, può davvero aiutare lo sviluppo nascondendo la complessità sottostante. Negli scenari in cui abbiamo bisogno di modificare la logica nella funzione per scopi di miglioramento o di debug, possiamo fare il cambiamento in un oggetto, testarlo e quell’unico cambiamento si rifletterà negli altri posti in cui la funzione viene chiamata.
Se avessimo ripetuto la logica in più posti, si dovrebbe fare lo stesso cambiamento più volte con il rischio di errori, deviazioni o altri contrattempi ogni volta. Questo significa che abbiamo bisogno di capire dove riutilizziamo la logica negli iTVF, in modo da poter testare di non aver introdotto quelle fastidiose caratteristiche note come bug.
Flessibilità
Quando si parla di flessibilità, l’idea è quella di utilizzare la capacità delle funzioni di passare in valori di parametro e di essere facili da interagire. Come vedremo con esempi più avanti, possiamo interagire con l’iTFV come se stessimo interrogando una tabella.
Se la logica fosse in una stored procedure per esempio, dovremmo probabilmente prendere i risultati in una tabella temporanea e poi interrogare la tabella temporanea per interagire con i dati.
Se la logica fosse in una vista, non saremmo in grado di passare un parametro. Le nostre opzioni includono l’interrogazione della vista e l’aggiunta di una clausola WHERE al di fuori della definizione della vista. Anche se non è un grosso problema per questo demo, in query complicate, semplificare con un iTVF può essere una soluzione più elegante.
Evitare le penalità sulle prestazioni
Per lo scopo di questo articolo, non guarderò le UDF del Common Language Runtime (CLR).
Dove cominciamo a vedere una divergenza tra le iTVF e altre UDF è la performance. Si può dire molto sulle prestazioni, e per la maggior parte, le altre UDF soffrono molto, in termini di prestazioni. Un’alternativa potrebbe essere quella di riscriverle come iTVFs invece, poiché le prestazioni sono un po’ diverse per le iTFVs. Non soffrono delle stesse penalità di performance che colpiscono le funzioni scalari o le Multi Statement Table-Valued Functions (MSTVFs).
iTVFs, come il loro nome suggerirebbe, vengono inserite nel piano di esecuzione. Con l’ottimizzatore che disinstalla gli elementi di query della definizione e interagisce con le tabelle sottostanti (inlining), si hanno maggiori possibilità di ottenere un piano ottimale, poiché l’ottimizzatore può considerare le statistiche delle tabelle sottostanti e ha a disposizione altre ottimizzazioni come il parallelismo, se questo è richiesto.
Per molte persone, la sola performance è stata una grande ragione per usare le iTVF al posto delle scalari o MSTVF. Anche se non vi interessa ancora la performance, le cose possono cambiare molto rapidamente con volumi maggiori o applicazioni complicate della vostra logica, quindi capire le insidie degli altri tipi di UDF è importante. Più avanti in questo articolo, mostreremo un confronto di base delle prestazioni che coinvolge le iTVF e altri tipi di UDF.
Ora che abbiamo elencato alcune ragioni per usare le iTVF, andiamo avanti e vediamo come possiamo usarle.
Impostazione della demo iTVF
In questa demo, useremo il database StackOverflow2010, che è liberamente disponibile presso le adorabili persone di StackOverflow via https://archive.org/details/stackexchange
In alternativa, potete ottenere il database tramite le altre adorabili persone di Brent Ozar Unlimited qui: https://www.brentozar.com/archive/2015/10/how-to-download-the-stack-overflow-database-via-bittorrent/
Ho ripristinato il database StackOverflow sul mio SQL Server 2016 Developer Edition locale, in un ambiente isolato. Eseguirò una rapida demo sulla mia versione installata di SQL Server Management Studio (SSMS) v18.0 Preview 5. Ho anche impostato la modalità di compatibilità su 2016 (130) e sto eseguendo la demo su una macchina con una CPU Intel i7 2.11 GHz e 16GB di RAM.
Una volta in funzione con il database StackOverflow, eseguire il T-SQL nel file risorsa 00_iTFV_Setup.sql contenuto in questo articolo per creare gli iTVF che useremo. La logica in questi iTVF è semplice e può essere ripetuta in più posti, ma qui la scriveremo una volta sola e la offriremo per il riutilizzo.
Utilizzare un iTVF come una tabella virtuale
Ricordate che gli iTVF non sono persistiti da nessuna parte nel database. Ciò che viene memorizzato è la loro definizione. Possiamo comunque interagire con gli iTVF come se fossero delle tabelle, quindi in questo senso, li trattiamo come tabelle virtuali.
I seguenti 6 esempi mostrano come possiamo trattare gli iTVF come tabelle virtuali. Con il database di StackOverflow attivo e funzionante sulla vostra macchina, sentitevi liberi di eseguire le seguenti 6 query dalla Sezione 1 per vedere da soli. Potete anche trovarle nel file 01_Demo_SSC_iTVF_Creating_Using.sql.
/**************************************************************************1. Using iTVFs in queries as if it were a table.**************************************************************************/DECLARE @UserId INT= 3, @CommentDate DATE= '2006-01-01T00:00:00.000';--1.1 Get specific columnsSELECT UserId, LatestCommentDateFROM dbo.itvfnGetRecentComment(3, '2006-01-01T00:00:00.000');--1.2 Get all columns SELECT *FROM dbo.itvfnGetRecentComment(@UserId, @CommentDate);--1.3 Use a default valueSELECT UserId, LatestCommentDate, TotalCommentsFROM dbo.itvfnGetRecentComment(@UserId, DEFAULT);--1.4 In the WHERE clauseSELECT u.DisplayName, u.Location, u.ReputationFROM dbo.Users uWHERE u.Reputation <=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(@UserId, DEFAULT));--1.5 In the HAVING clauseSELECT u.Location, SUM(u.Reputation) AS TotalRepFROM dbo.Users uGROUP BY u.LocationHAVING SUM(u.Reputation) >=( SELECT rc.TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT) rc);--1.6 In the SELECT clauseSELECT u.Location, CASE WHEN SUM(u.Reputation) >=( SELECT TotalComments FROM dbo.itvfnGetRecentComment(3, DEFAULT)) THEN 'YES' ELSE 'NO' END AS InRepLimitFROM dbo.Users uGROUP BY u.Location;
Come mostrato sopra, quando interagiamo con gli iTVF, possiamo:
- Ritornare la lista completa delle colonne
- Ritornare le colonne specificate
- Utilizzare i valori di default passando la parola chiave, DEFAULT
- Passare l’iTVF nella clausola WHERE
- utilizzare l’iTVF nella clausola HAVING
- utilizzare l’iTVF nella clausola SELECT
Per mettere questo in prospettiva, tipicamente con una stored procedure, si dovrebbe inserire il set di risultati in una tabella temporanea e poi interagire con la tabella temporanea per fare quanto sopra. Con un iTVF, non c’è bisogno di interagire con altri oggetti al di fuori della definizione della funzione per casi simili ai 6 che abbiamo appena visto.
iTVF in funzioni annidate
Anche se l’annidamento delle funzioni può portare i suoi problemi se fatto male, è qualcosa che possiamo fare all’interno di un iTVF. Al contrario, se usato in modo appropriato, può essere molto utile per nascondere la complessità.
Nel nostro esempio artificioso, la funzione, dbo.itvfnGetRecentCommentByRep, restituisce l’ultimo commento di un utente, i commenti totali ecc, aggiungendo un ulteriore filtro per la reputazione.
SELECT DisplayName, LatestCommentDate, ReputationFROM .(3, DEFAULT, DEFAULT);GO
Quando restituiamo la data dell’ultimo commento, questo avviene tramite la chiamata all’altra funzione, dbo.itvfnGetRecentComment.
CREATE OR ALTER FUNCTION . (@UserId int, @Reputation int = 100, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS TABLE WITH SCHEMABINDING AS RETURN ( SELECT u.DisplayName, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) cWHERE u.Id = @UserId AND u.Reputation >= @Reputation);GO
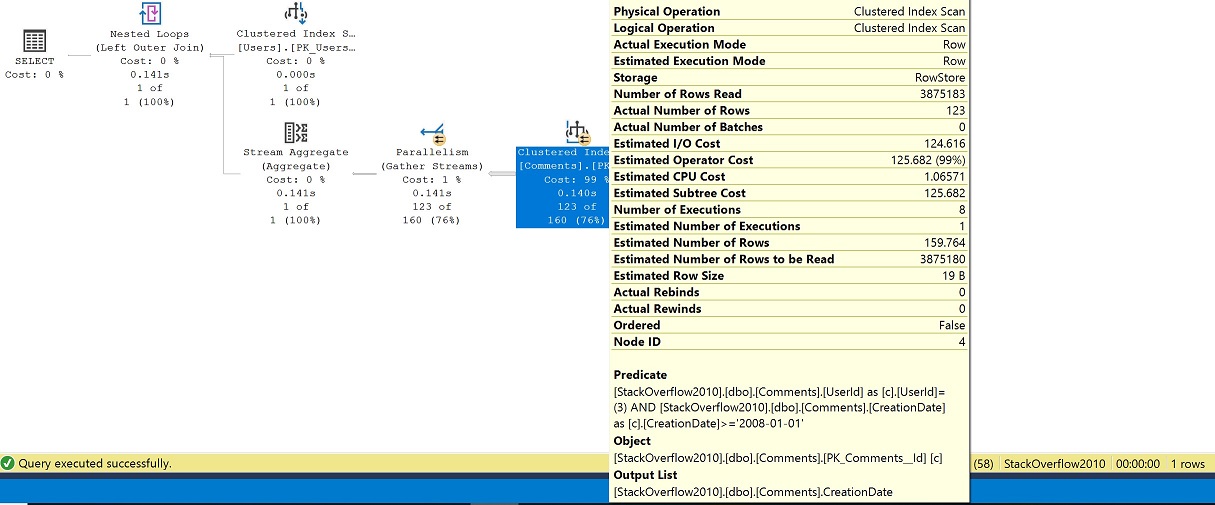
Nell’esempio, possiamo vedere che anche con l’annidamento delle funzioni, la definizione sottostante viene inlined e gli oggetti con cui interagiamo sono gli indici clustered, dbo.Users e dbo.Comments.
Nel piano, senza un indice decente per supportare i nostri predicati, viene eseguita una scansione dell’indice clustered della tabella Comments, oltre ad andare in parallelo dove finiamo per avere un numero di esecuzioni pari a 8. Filtriamo per UserId 3 dalla tabella Users così otteniamo una ricerca sulla tabella Users e poi ci uniamo alla tabella Comments dopo il GROUP BY (stream aggregate) per la data dell’ultimo commento.
Utilizzando l’operatore APPLY
L’operatore APPLY offre così tanti usi creativi, ed è certamente un’opzione che possiamo applicare (gioco di parole) all’interazione con un iTVF. Per saperne di più sull’operatore APPLY, consultate i seguenti documenti: https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms175156(v=sql.105) e http://www.sqlservercentral.com/articles/Stairway+Series/121318/
Nel seguente esempio vogliamo chiamare l’iTVF per tutti gli utenti e restituire il loro LatestCommentDate, Total Comments, Id e Reputation dal 01 gennaio 2008. Per fare questo usiamo l’operatore APPLY, dove eseguiamo per ogni riga dell’intera tabella Users, passando l’Id dalla tabella Users e il CommentDate. Così facendo, manteniamo i vantaggi dell’incapsulamento dell’uso di iTVF, applicando la nostra logica a tutte le righe della tabella Users.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, u.Reputation, c.LatestCommentDate, c.TotalCommentsFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
iTVFs in JOINs
Similmente all’unione di 2 o più tabelle, possiamo coinvolgere gli iTVFs in join con altre tabelle. Qui, vogliamo il DisplayName dalla tabella Users e UserId, BadgeName e BadgeDate dall’iTVF, per gli utenti che hanno ottenuto il badge di ‘Student’ il o dopo il 01 gennaio 2008.
DECLARE @BadgeName varchar(40)= 'Student', @BadgeDate datetime= '2008-01-01T00:00:00.000';SELECT u.DisplayName, b.UserId, b.BadgeName, b.BadgeDateFROM dbo.Users u INNER JOIN .(@BadgeName, @BadgeDate) b ON b.UserId = u.Id;GO
Alternativa ad altre UDF
Prima in questo articolo abbiamo menzionato che una ragione per usare le iTVF era quella di evitare le penalità di performance di cui soffrono altri tipi di UDF come le scalari e le MSTVF. Questa sezione dimostrerà come possiamo sostituire le scalari e le MSTVF con le iTVF e la parte seguente analizzerà il motivo per cui possiamo scegliere di farlo.
Alternativa UDF scalare
Prima di continuare, eseguiamo la seguente query per creare la UDF scalare, dbo.sfnGetRecentComment che useremo tra poco.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate date = '2006-01-01T00:00:00.000')RETURNS datetimeWITH SCHEMABINDING, RETURNS NULL ON NULL INPUTASBEGIN DECLARE @LatestCreationDate datetime; SELECT @LatestCreationDate = MAX(CreationDate) FROM dbo.Comments WHERE UserId = @UserId AND CreationDate >= @CommentDate GROUP BY UserId; RETURN @LatestCreationDate;END;GO
Dopo aver creato la funzione scalare, eseguire la seguente query. Qui vogliamo usare la logica incapsulata nella funzione scalare per interrogare l’intera tabella Users e restituire l’Id e la data dell’ultimo commento di ogni utente dal 01 gennaio 2008. Lo facciamo aggiungendo la funzione nella clausola SELECT dove, come valori dei parametri, passeremo l’Id dalla tabella Users e la data dei commenti che abbiamo appena impostato al 01 gennaio 2008.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Una query simile può essere scritta usando un iTVF, che è mostrato nella seguente query. Qui vogliamo ottenere l’Id e la data dell’ultimo commento dal 01 gennaio 2008 usando l’iTVF e ci riusciamo usando l’operatore APPLY su tutte le righe della tabella Users. Per ogni riga passiamo l’Id dell’utente e la data del commento.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Alternativa MSTVF
Eseguite la seguente query per creare il MSTVF dbo.mstvfnGetRecentComment, che useremo tra poco.
USE GOCREATE FUNCTION . (@UserId int, @CommentDate datetime = '2008-01-01T00:00:00.000')RETURNS @RecentComment TABLE( int NULL, date NULL, int NULL)WITH SCHEMABINDING ASBEGIN INSERT INTO @RecentComment SELECT c.UserId, MAX(c.CreationDate) AS LatestCommentDate, COUNT(*) AS TotalComments FROM dbo.Comments c WHERE c.UserId = @UserId AND c.CreationDate >= @CommentDate GROUP BY c.UserId; RETURN;END;GO
Ora che abbiamo creato il MSTVF, lo useremo per restituire la data dell’ultimo commento per tutte le righe della tabella Users dal 01 gennaio 2008. Come l’esempio iTVF con l’operatore APPLY nella parte precedente di questo articolo, “applicheremo” la nostra funzione a tutte le righe della tabella Users usando l’operatore APPLY e passando l’ID utente per ogni riga, così come la data di commento che abbiamo impostato.
DECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Sostituendo il MSTVF del nostro esempio con un iTVF, il risultato è molto simile, a parte il nome della funzione che viene chiamata. Nel nostro caso chiameremo itvfnGetRecentComment al posto del MSTVF dell’esempio precedente, mantenendo le colonne nella clausola SELECT. Questo ci permette di ottenere l’Id e la data dell’ultimo commento dal 01 gennaio 2008 usando l’iTVF per tutte le righe della tabella Users. Questo è mostrato nella query che segue.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Una preferenza per le iTVF
Un motivo per scegliere una iTVF rispetto a una funzione scalare o MSTVF è la performance.
Cattureremo brevemente le prestazioni delle 3 funzioni sulla base delle query di esempio che abbiamo eseguito nella sezione precedente e non entreremo molto nel dettaglio, se non per confrontare le prestazioni attraverso metriche come il tempo di esecuzione e il numero di esecuzione delle funzioni. Il codice per le statistiche sulle prestazioni che useremo in questa demo è tratto dal listato 9.3 negli esempi di codice della terza edizione di SQL Server Execution Plans di Grant Fritchey https://www.red-gate.com/simple-talk/books/sql-server-execution-plans-third-edition-by-grant-fritchey/
Prestazioni scalari
Qui è la query precedente che abbiamo eseguito invocando la funzione scalare.
DECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
È noto che le funzioni scalari inibiscono il parallelismo e che una dichiarazione con una funzione scalare viene invocata una volta per ogni riga. Se la vostra tabella ha 10 righe, potreste essere a posto. Qualche migliaio di righe, e potreste essere sorpresi (o meno) dal drastico calo delle prestazioni. Vediamo questo in azione eseguendo il seguente frammento di codice.
Quello che vogliamo fare prima è cancellare (in un ambiente isolato) la cache di SQL Server e il piano esistente che potrebbe essere riutilizzato (FREEPROCCACHE), assicurandoci di ottenere prima i dati dal disco (DROPPCLEANBUFFERS) per iniziare con una cache fredda. In parole povere, partiamo da una tabula rasa facendo così.
Dopo questo, eseguiamo la query SELECT sulla tabella Users dove restituiamo l’Id e LatestCommentDate usando la funzione scalare. Come valori di parametro, passiamo l’Id della tabella Users e la data del commento che abbiamo appena impostato al 01 gennaio 2008. Un esempio è il seguente.
-- run in an isolated environmentCHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, .(u.Id, @CommentDate) AS LatestCommentDateFROM dbo.Users u;
Anche se la query SELECT in cui utilizziamo la funzione scalare può sembrare semplice nella struttura, dopo 4 minuti sulla mia macchina, era ancora in esecuzione.
Ricordo che le funzioni scalari vengono eseguite una volta per ogni riga. Il problema è che le operazioni riga per riga sono molto raramente il modo più efficiente di recuperare i dati in SQL Server rispetto alle operazioni basate su singoli set.
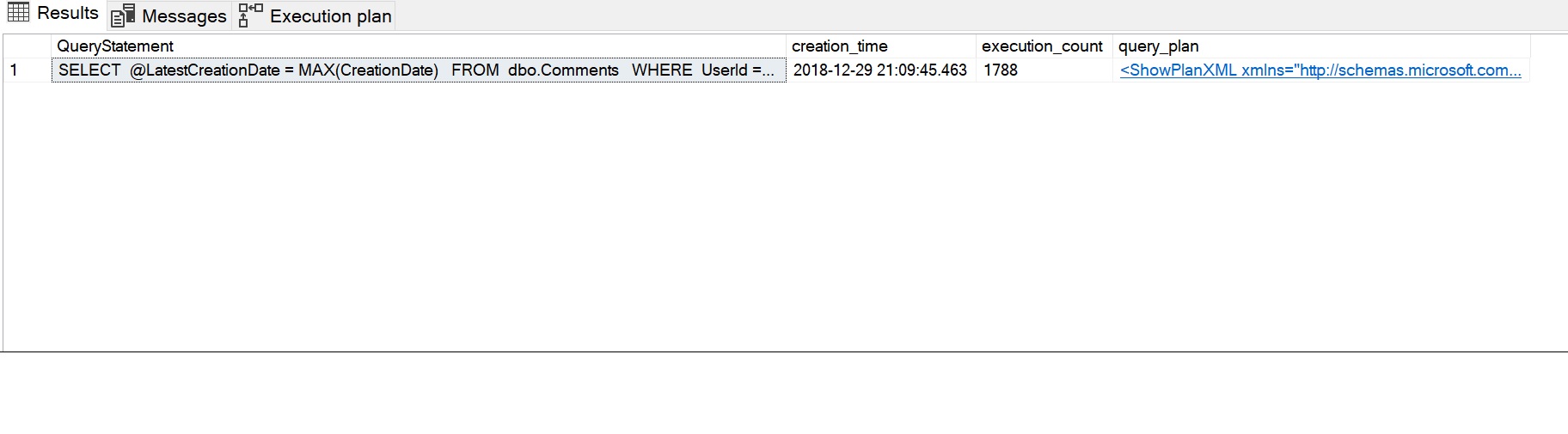
Per osservare le esecuzioni ripetute, possiamo eseguire una query per alcune statistiche di performance. Queste sono raccolte da SQL Server quando eseguiamo le nostre query e qui, vogliamo ottenere la dichiarazione della query, il tempo di creazione, il conteggio dell’esecuzione della dichiarazione e il piano della query. La seguente query è un esempio di come possiamo ottenere le statistiche di performance.
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.sfnGetRecentComment')ORDER BY deqs.last_execution_time DESC;GO
L’esecuzione risultante delle statistiche di performance può essere vista nell’immagine seguente. L’istruzione della query mostra l’istruzione SELECT usata dalla funzione scalare, il conteggio dell’esecuzione di 1788 ha catturato il conteggio dell’esecuzione ripetuta (una volta per ogni riga) e il piano usato dalla funzione può essere visualizzato cliccando sul messaggio XML del piano della query.
Un ulteriore modo di vedere importanti metriche di performance è usando gli eventi estesi. Per saperne di più sugli eventi estesi, cliccate qui, ma ai fini della nostra demo, eseguite la seguente query per creare una sessione di eventi estesi.
CREATE EVENT SESSION QuerySession ON SERVER ADD EVENT sqlserver.module_end( WHERE (.(.,(??)))), -- enter your Session Id ADD EVENT sqlserver.sp_statement_completed( WHERE (.(.,(??)))),-- enter your Session Id ADD EVENT sqlserver.sql_batch_completed( WHERE (.(.,(??)))); -- enter your Session IdGOALTER EVENT SESSION QuerySession ON SERVER STATE = START;GO
Una volta creata la sessione di eventi estesi, andate su Gestione in Esplora Oggetti, espandete le sessioni e aprite il menu contestuale per “QuerySession” che abbiamo appena creato. Selezionate “Watch live data”.
Nella finestra appena aperta, osservate le linee di dichiarazione multiple della funzione scalare come prova delle esecuzioni ripetute.
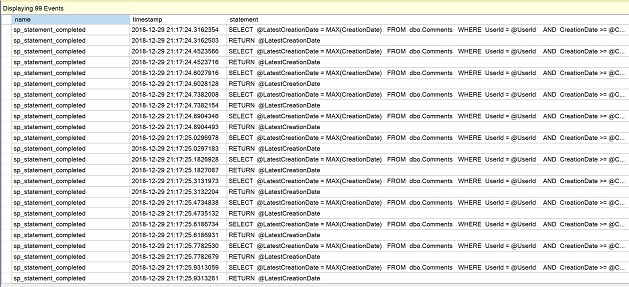
Clicca sul quadrato rosso per “Stop data feed” per ora.
Prestazioni MSTVF
Per gli MSTVF, ci possono essere anche delle penalità di prestazioni come risultato del loro uso e questo è legato a SQL Server che sceglie piani di esecuzione sub ottimali a causa di statistiche imprecise. SQL Server si basa su statistiche catturate internamente per capire quante righe di dati restituirà una query in modo da poter produrre un piano ottimale. Questo processo è noto come stima della cardinalità.
Prima di SQL Server 2014, la stima della cardinalità per le variabili di tabella era impostata a 1 riga. Da SQL Server 2014 in poi è impostata a 100 righe, indipendentemente dal fatto che stiamo interrogando 100 righe o 1 milione di righe. Le MSTVF restituiscono dati tramite variabili di tabella che sono dichiarate all’inizio della definizione della funzione. La realtà è che l’ottimizzatore non cercherà mai il miglior piano che può trovare indipendentemente dal tempo e deve mantenere un equilibrio (detto molto semplicemente). Con le MSTVF, la mancanza di statistiche accurate (causata da una stima imprecisa della cardinalità delle variabili di tabella all’interno della loro definizione) può inibire le prestazioni facendo produrre all’ottimizzatore dei piani non ottimali.
In pratica, sostituire le MSTVF con le iTVF può portare a migliori prestazioni poiché le iTVF useranno le statistiche delle tabelle sottostanti.
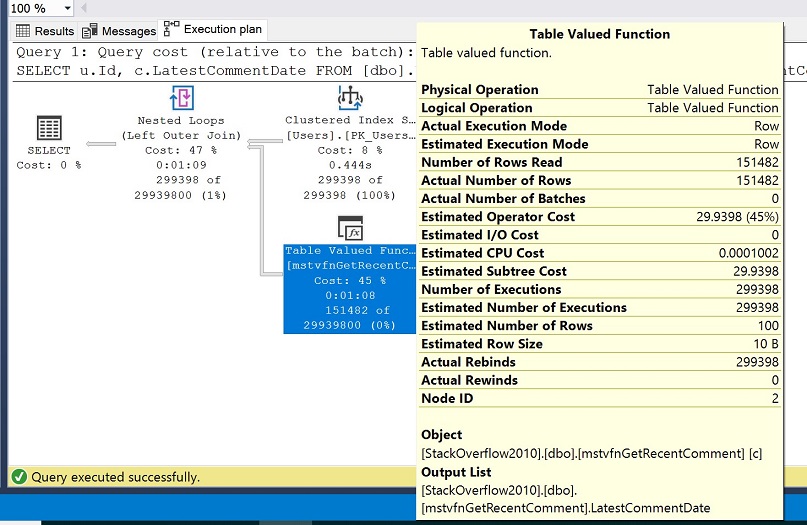
Il seguente frammento di codice usa l’operatore APPLY per eseguire la MSTVF sull’intera tabella Users. Restituiamo l’Id dalla tabella Users e il LatestCommentDate dalla funzione per ogni riga della tabella Users, passando l’Id dell’utente e la data del commento impostata al 01 gennaio 2008. Simile all’esecuzione della funzione scalare, lo faremo da una cache fredda. Con questo test, avere anche il piano di esecuzione effettivo selezionato in SSMS, cliccando Ctrl + M. Eseguire la query.
CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate date= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM .Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
Il piano di esecuzione risultante è mostrato nell’immagine seguente e nella casella gialla delle proprietà, notare i valori per il numero stimato di righe vs numero effettivo di righe.
Si dovrebbe vedere che il numero stimato di righe dalla funzione di valutazione della tabella è impostato a 100 ma il numero effettivo di righe è impostato a 151.482. Ricordiamo che nella nostra configurazione, abbiamo scelto la modalità di compatibilità di SQL Server 2016 (130) e che da SQL Server 2014 in poi, la stima della cardinalità è impostata a 100 per le variabili di tabella.
Valori così diversi per il numero stimato di righe rispetto al numero effettivo di righe tipicamente danneggiano le prestazioni e possono impedirci di ottenere piani più ottimali e, in definitiva, di eseguire meglio le query.
Similmente alla funzione scalare che abbiamo eseguito in precedenza, eseguiremo una query contro le statistiche di performance di SQL Server. Qui vogliamo anche ottenere l’istruzione della query, il tempo di creazione, il conteggio dell’esecuzione dell’istruzione e il piano di query utilizzato e filtrare per il MSTVF nella clausola WHERE.
SELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs OUTER APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp OUTER APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.objectid = OBJECT_ID('dbo.mstvfnGetRecentComment');
Il piano di esecuzione che abbiamo inizialmente osservato per il MSTVF è fuorviante in quanto non riflette il lavoro effettivo svolto dalla funzione. Usando le statistiche di performance che abbiamo appena eseguito e selezionando lo Showplan XML, dovremmo vedere un piano di query diverso che mostra il lavoro che viene fatto dal MSTVF. Un esempio del piano diverso da quello che abbiamo visto inizialmente è il seguente. Qui possiamo ora vedere che il MSTVF inserisce i dati in una tabella variabile chiamata @RecentComment. I dati nella variabile di tabella @RecentComment sono ciò che viene poi restituito dal MSTVF per restituire l’ultima data di commento.
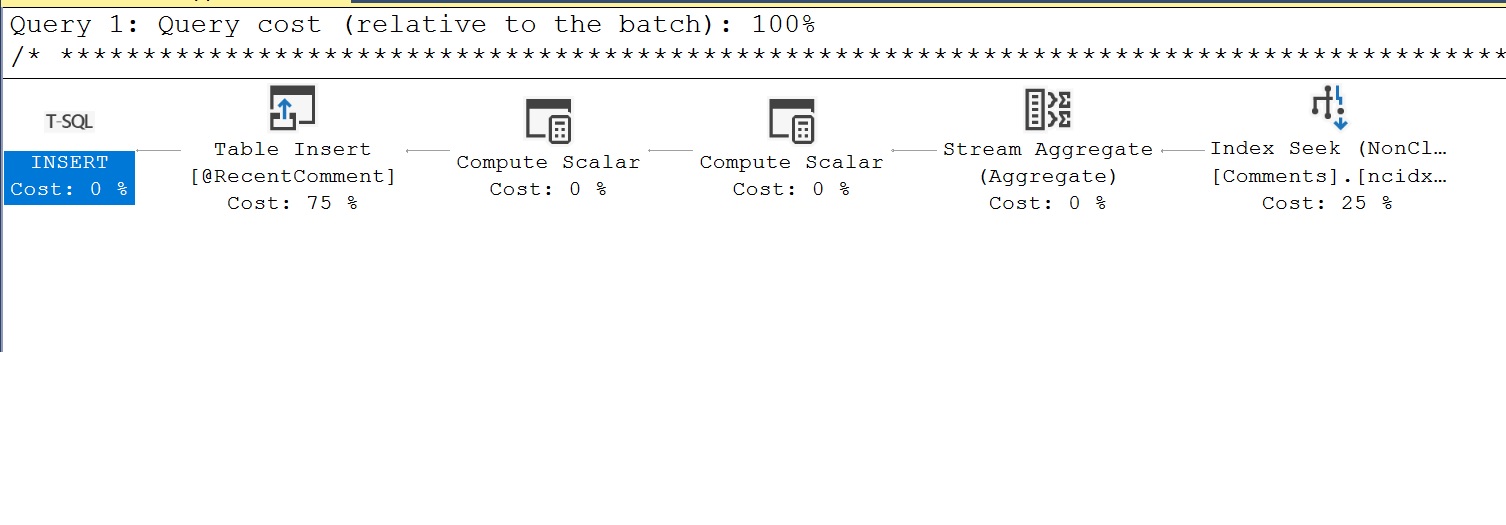
Un altro aspetto delle metriche di performance che abbiamo catturato è il conteggio dell’esecuzione. Qui vogliamo diffidare dei conteggi di esecuzioni multiple, in quanto queste sono tipicamente negative per le prestazioni, come detto quando si guardano le prestazioni scalari.
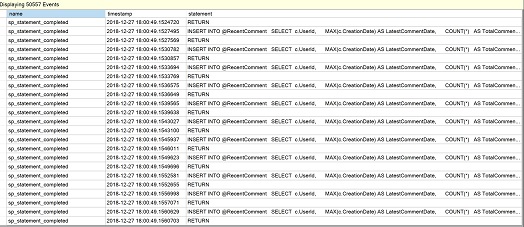
Quello che vediamo nell’immagine seguente per il conteggio delle esecuzioni, è un valore di 76 che è prova di esecuzioni multiple del nostro MSTVF.

Torniamo a Gestione in Esplora Oggetti, espandiamo le sessioni e selezioniamo “Guarda i dati in diretta” per la sessione “QuerySessions” che abbiamo creato prima quando abbiamo guardato le prestazioni scalari. Clicchiamo sul triangolo verde “Start data feed” in SSMS se la sessione è stata fermata in precedenza e dovremmo vedere, per il nostro esempio, più righe di dichiarazione del MSTVF che rappresentano le ripetute esecuzioni della dichiarazione.
Sentitevi liberi di annullare la query a questo punto se non è ancora stata completata.
performance iTVF
Quando sostituiamo le funzioni scalari o multi statement con un iTVF, vogliamo farlo per evitare le penalità di performance che abbiamo appena visto, ad esempio tempo di esecuzione, esecuzioni multiple. Usando l’esempio precedente che segue, interrogheremo la tabella Users per ottenere l’Id e la Latest Comment Date dall’iTVF dal 01 gennaio 2008. usando l’operatore APPLY. Lo faremo anche da una cache fredda, cancellando la cache di SQL Server e ottenendo i dati dal disco per cominciare.
--run in an isolated environment CHECKPOINT;DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;GODECLARE @CommentDate DATE= '2008-01-01T00:00:00.000';SELECT u.Id, c.LatestCommentDateFROM dbo.Users u OUTER APPLY .(u.Id, @CommentDate) c;GO
La seguente query consiste nelle statistiche di performance che ci aiutano a vedere l’istruzione che viene eseguita, il numero di esecuzione e il piano di query per quell’istruzione.
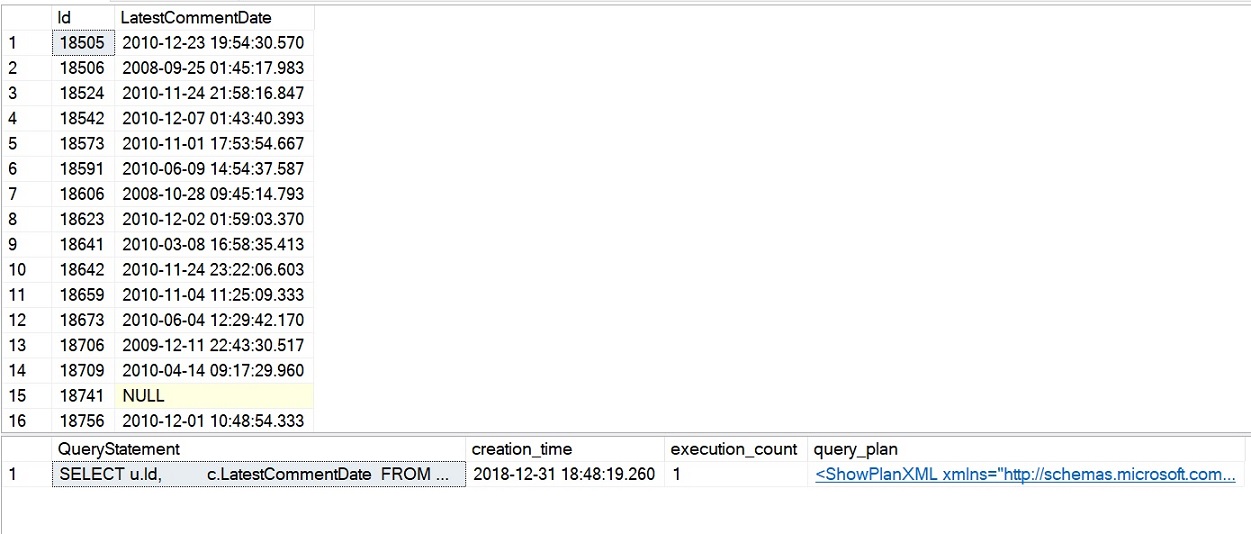
-- Query stats and execution planSELECT SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (CASE deqs.statement_end_offset WHEN-1 THEN DATALENGTH(dest.text) ELSE deqs.statement_end_offset - deqs.statement_start_offset END) / 2 + 1) AS QueryStatement, deqs.creation_time, deqs.execution_count, deqp.query_planFROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) AS destWHERE deqp.dbid = DB_ID('StackOverflow2010')ORDER BY deqs.last_execution_time DESC;
La query di esempio per l’iTVF che abbiamo appena eseguito ha completato in poco più di 4 secondi e le statistiche di performance che abbiamo interrogato dovrebbero mostrare un conteggio di esecuzione di 1 per l’iTVF come mostrato nell’immagine seguente. Questo è un netto miglioramento delle prestazioni rispetto ai nostri precedenti esempi con tentativi scalari e MSTFV.
Confronto delle prestazioni scalari, MSTVF e iTVF
La seguente tabella cattura il confronto delle 3 UDF che abbiamo appena eseguito per mostrare come si sono comportate in termini di tempo di esecuzione e numero di esecuzioni.
| Scalare | MSTVF | iTVF | |
| Tempo di esecuzione | > 5 minuti | > 5 minuti | 4 secondi |
| Conteggio delle esecuzioni | > 10,000 | > 10.000 | 1 |
La differenza nel tempo di esecuzione e nel numero di esecuzione utilizzando l’iTVF è immediatamente evidente. Nel nostro esempio, l’iTVF ha restituito gli stessi dati più velocemente e con una sola esecuzione. In ambienti in cui ci sono carichi di lavoro pesanti o per scenari in cui la logica è usata in più report che sono lenti a causa dell’uso di scalari o MSTVF, un passaggio a un iTVF può aiutare ad alleviare gravi problemi di prestazioni.
Limitazioni
iTVF entrano davvero in gioco quando è necessario riutilizzare la logica senza sacrificare le prestazioni, ma non sono perfetti. Anche loro hanno delle limitazioni.
Per una lista di limitazioni e restrizioni delle funzioni definite dall’utente in generale potete visitare Books Online qui.
Singolo statement SELECT
Poiché la definizione di una iTVF è limitata a 1 statement SELECT, le soluzioni che richiedono una logica al di là di quell’unico statement SELECT, dove forse sono richieste assegnazioni di variabili, logiche condizionali o l’uso di tabelle temporanee, probabilmente non sono adatte all’implementazione di una iTVF da sola.
Gestione degli errori
Questa è una restrizione che riguarda tutte le funzioni definite dall’utente dove costrutti come TRY CATCH non sono permessi.
Chiamare le stored procedure
Non si possono chiamare stored procedure dall’interno del corpo dell’iTVF a meno che non sia una stored procedure estesa. Questo è legato a un principio della progettazione delle UDF di SQL Server, secondo il quale non si può alterare lo stato del database, cosa che, se si usa una stored procedure, si potrebbe fare.
Conclusione
Questo articolo è iniziato con l’intenzione di rivisitare le inline table-valued functions (iTVFs) come sono attualmente nel 2016, mostrando la varietà di modi in cui possono essere usate.
Le iTVF hanno un vantaggio chiave nel fatto che non sacrificano le prestazioni a differenza di altri tipi di funzioni definite dall’utente (UDF) e possono incoraggiare buone pratiche di sviluppo con le loro capacità di riutilizzo e incapsulamento.
Con le recenti caratteristiche di SQL Server, in primo luogo in SQL Server 2017 e nel prossimo SQL Server 2019, le prestazioni sia di scalari che di MSTVFs hanno qualche aiuto in più. Per maggiori dettagli, controlla l’esecuzione interleaved che sembra fornire una stima accurata della cardinalità per le MSTVF piuttosto che i numeri fissi o 1 o 100 e l’inlining delle UDF scalari. Con l’inlining delle UDF scalari nel 2019, l’attenzione è rivolta ad affrontare la debolezza delle prestazioni delle UDF scalari.
Per le vostre soluzioni, assicuratevi di testare ed essere consapevoli dei loro limiti. Se usati bene, sono uno dei migliori strumenti che potremmo avere nel nostro arsenale SQL.
Grazie per la lettura.